5-1 Counting 1-Bits
The IBM Stretch computer (ca. 1960) had a means of counting the number of 1-bits in a word as well as the number of leading 0's. It produced these two quantities as a by-product of all logical operations! The former function is sometimes called population count (e.g., on Stretch and the SPARCv9).
For machines that don't have this instruction, a good way to count the number of 1-bits is to first set each 2-bit field equal to the sum of the two single bits that were originally in the field, and then sum adjacent 2-bit fields, putting the results in each 4-bit field, and so on. A more complete discussion of this trick is in [RND]. The method is illustrated in Figure 5-1, in which the first row shows a computer word whose 1-bits are to be summed, and the last row shows the result (23 decimal).
Figure 5-1. Counting 1-bits, "divide and conquer" strategy.

This is an example of the "divide and conquer" strategy, in which the original problem (summing 32 bits) is divided into two problems (summing 16 bits), which are solved separately, and the results are combined (added, in this case). The strategy is applied recursively, breaking the 16-bit fields into 8-bit fields, and so on.
In the case at hand, the ultimate small problems (summing adjacent bits) can all be done in parallel, and combining adjacent sums can also be done in parallel in a fixed number of steps at each stage. The result is an algorithm that can be executed in log2(32) = 5 steps.
Other examples of divide and conquer are the well-known technique of binary search, a sorting method known as quicksort, and a method for reversing the bits of a word, discussed on page 101.
The method illustrated in Figure 5-1 may be committed to C code as
x = (x & 0x55555555) + ((x >> 1) & 0x55555555); x = (x & 0x33333333) + ((x >> 2) & 0x33333333); x = (x & 0x0F0F0F0F) + ((x >> 4) & 0x0F0F0F0F); x = (x & 0x00FF00FF) + ((x >> 8) & 0x00FF00FF); x = (x & 0x0000FFFF) + ((x >>16) & 0x0000FFFF);
The first line uses (x >> 1) & 0x55555555 rather than the perhaps more natural (x & 0xAAAAAAAA) >> 1 because the code shown avoids generating two large constants in a register. This would cost an instruction if the machine lacks the and not instruction. A similar remark applies to the other lines.
Clearly, the last and is unnecessary, and other and's may be omitted when there is no danger that a field's sum will carry over into the adjacent field. Furthermore, there is a way to code the first line that uses one fewer instruction. This leads to the simplification shown in Figure 5-2, which executes in 21 instructions and is branch-free.
Figure 5-2 Counting 1-bits in a word.
int pop(unsigned x) {牋 x = x - ((x >> 1) & 0x55555555); 牋爔 = (x & 0x33333333) + ((x >> 2) & 0x33333333); 牋爔 = (x + (x >> 4)) & 0x0F0F0F0F; 牋爔 = x + (x >> 8); 牋爔 = x + (x >> 16); 牋爎eturn x & 0x0000003F; }
The first assignment to x is based on the first two terms of the rather surprising formula
![]()
In Equation (1), we
must have x ![]() 0. By treating x as an unsigned integer, Equation (1) can be
implemented with a sequence of 31 shift right
immediate's of 1, and 31 subtract's. The
procedure of Figure 5-2 uses
the first two terms of this on each 2-bit field, in parallel.
0. By treating x as an unsigned integer, Equation (1) can be
implemented with a sequence of 31 shift right
immediate's of 1, and 31 subtract's. The
procedure of Figure 5-2 uses
the first two terms of this on each 2-bit field, in parallel.
There is a simple proof of Equation (1), which is shown below for the case of a 4-bit word. Let the word be b3b2b1b0, where each bi = 0 or 1. Then,
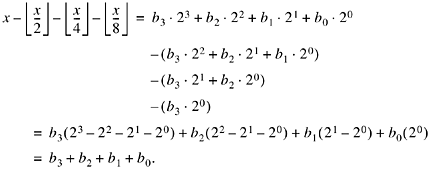
Alternatively, Equation (1) can be derived by noting that bit i of the binary representation of a nonnegative integer x is given by
![]()
and summing this for i = 0 to 31. Work it out梩he last term is 0 because x < 232.
Equation (1) generalizes to other bases. For base ten it is
![]()
where the terms are carried out until they are 0. This can be proved by essentially the same technique used above.
A variation of the above algorithm is to use a base four analogue of Equation (1) as a substitute for the second executable line of Figure 5-2:
x = x - 3*((x >> 2) & 0x33333333)
This code, however, uses the same number of instructions as the line it replaces (six), and requires a fast multiply-by-3 instruction.
An algorithm in HAKMEM memo [HAK, item 169] counts the number of 1-bits in a word by using the first three terms of (1) to produce a word of 3-bit fields, each of which contains the number of 1-bits that were in it. It then adds adjacent 3-bit fields to form 6-bit field sums, and then adds the 6-bit fields by computing the value of the word modulo 63. Expressed in C, the algorithm is (the long constants are in octal)
int pop(unsigned x) {牋 unsigned n;
牋 n = (x >> 1) & 033333333333;牋牋牋 // Count bits in
牋爔 = x - n;牋牋牋牋牋牋牋牋牋牋牋牋 // each 3-bit
牋爊 = (n >> 1) & 033333333333;牋牋牋 // field.
牋爔 = x - n;
牋爔 = (x + (x >> 3)) & 030707070707; // 6-bit sums.
牋爔 = modu(x, 63);牋牋牋牋牋牋牋牋牋 // Add 6-bit sums.
牋爎eturn x;
}
The last line uses the unsigned
modulus function. (It could be either signed or unsigned if the word
length were a multiple of 3). That the modulus function sums the 6-bit fields
becomes clear by regarding the word x
as an integer written in base 64. The remainder upon dividing a base b integer by b - 1
is, for b ![]() 3, congruent mod b
to the sum of the digits and, of course, is less than b.
Because the sum of the digits in this case must be less than or equal to 32,
mod(x, 63) must be equal to the sum of the
digits of x, which is to say equal to the
number of 1-bits in the original x.
3, congruent mod b
to the sum of the digits and, of course, is less than b.
Because the sum of the digits in this case must be less than or equal to 32,
mod(x, 63) must be equal to the sum of the
digits of x, which is to say equal to the
number of 1-bits in the original x.
This algorithm requires only ten instructions on the DEC PDP-10, because that machine has an instruction for computing the remainder with its second operand directly referencing a fullword in memory. On a basic RISC, it requires about 13 instructions, assuming the machine has unsigned modulus as one instruction (but not directly referencing a fullword immediate or memory operand). But it is probably not very fast, because division is almost always a slow operation. Also, it doesn't apply to 64-bit word lengths by simply extending the constants, although it does work for word lengths up to 62.
A variation on the HAKMEM algorithm is to use Equation (1) to count the number of 1's in each 4-bit field, working on all eight 4-bit fields in parallel [Hay1]. Then, the 4-bit sums may be converted to 8-bit sums in a straightforward way, and the four bytes can be added with a multiplication by 0x01010101. This gives
int pop(unsigned x) {牋 unsigned n;
牋 n = (x >> 1) & 0x77777777;牋牋牋?// Count bits in
牋爔 = x - n;牋牋牋牋牋牋牋牋牋牋牋?// each 4-bit
牋爊 = (n >> 1) & 0x77777777;牋牋牋?// field.
牋爔 = x - n;
牋爊 = (n >> 1) & 0x77777777;
牋爔 = x - n;
牋爔 = (x + (x >> 4)) & 0x0F0F0F0F;?// Get byte sums.
牋爔 = x*0x01010101;牋牋牋牋牋牋牋牋 // Add the bytes.
牋爎eturn x >> 24;
}
This is 19 instructions on the basic RISC. It works well if the machine is two-address, because the first six lines can be done with only one move register instruction. Also, the repeated use of the mask 0x77777777 permits loading it into a register and referencing it with register-to-register instructions. Furthermore, most of the shifts are of only one position.
A quite different bit-counting method, illustrated in Figure 5-3, is to turn off the rightmost 1-bit repeatedly [Weg, RND], until the result is 0. It is very fast if the number of 1-bits is small, taking 2 + 5pop(x) instructions.
Figure 5-3 Counting 1-bits in a sparsely populated word.
int pop(unsigned x) {牋 int n;
牋 n = 0;
牋爓hile (x != 0) {牋牋?n = n + 1;
牋牋牋x = x & (x - 1);
牋爙
牋爎eturn n;
}
This has a dual algorithm that is applicable if the number of 1-bits is expected to be large. The dual algorithm keeps turning on the rightmost 0-bit with x = x | (x + 1), until the result is all 1's (-1). Then, it returns 32 - n. (Alternatively, the original number x can be complemented, or n can be initialized to 32 and counted down).
A rather amazing algorithm is to rotate x left one position, 31 times, adding the 32 terms [MM]. The sum is the negative of pop(x)! That is,
![]()
where the additions are done modulo the word size, and the final sum is interpreted as a two's-complement integer. This is just a novelty; it would not be useful on most machines because the loop is executed 31 times and thus it requires 63 instructions plus the loop-control overhead.
To see why Equation (2) works, consider what happens to a single 1-bit of x. It gets rotated to all positions, and when these 32 numbers are added, a word of all 1-bits results. But this is -1. To illustrate, consider a 6-bit word size and x = 001001 (binary):

Of course, rotate-right would work just as well.
The method of Equation (1) is very similar to this "rotate and sum" method, which becomes clear by rewriting (1) as
![]()
This gives a slightly better algorithm than Equation (2) provides. It is better because it uses shift right, which is more commonly available than rotate, and because the loop can be terminated when the shifted quantity becomes 0. This reduces the loop-control code and may save a few iterations. The two algorithms are contrasted in Figure 5-4.
Figure 5-4 Two similar bit-counting algorithms.
int pop(unsigned x) {牋 int i, sum;
// Rotate and sum method牋牋牋?// Shift right & subtract
牋 sum = x;牋牋牋牋牋牋牋牋牋牋 // sum = x;
牋爁or (i = 1; i <= 31; i++) {?// while (x != 0) {牋牋?x = rotatel(x, 1);牋牋牋?//牋?x = x >> 1;
牋牋牋sum = sum + x;牋牋牋牋牋?//牋?sum = sum - x;
牋爙牋牋牋牋牋牋牋牋牋牋牋牋牋?// }
牋爎eturn -sum;牋牋牋牋牋牋牋牋 // return sum;
}
A less interesting algorithm that may be competitive with all the algorithms for pop(x) in this section is to have a table that contains pop(x) for, say, x in the range 0 to 255. The table can be accessed four times, adding the four numbers obtained. A branch-free version of the algorithm looks like this:
int pop(unsigned x) {牋?牋牋牋牋牋?/ Table lookup. 牋爏tatic char table[256] = {牋牋?0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
牋牋牋...
牋牋牋4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8};
牋 return table[x牋牋牋牋 & 0xFF] +
牋牋牋牋牋table[(x >>?8) & 0xFF] +
牋牋牋牋牋table[(x >> 16) & 0xFF] +
牋牋牋牋牋table[(x >> 24)];
}
Item 167 in [HAK] contains a short algorithm for counting the number of 1-bits in a 9-bit quantity that is right-adjusted and isolated in a register. It works only on machines with registers of 36 or more bits. Below is a version of that algorithm that works on 32-bit machines, but only for 8-bit quantities.
x = x * 0x08040201;?// Make 4 copies.
x = x >> 3;牋牋牋牋?// So next step hits proper bits.
x = x & 0x11111111;?// Every 4th bit.
x = x * 0x11111111;?// Sum the digits (each 0 or 1).
x = x >> 28;牋牋牋牋 // Position the result.
A version for 7-bit quantities is
x = x * 0x02040810;?// Make 4 copies, left-adjusted.
x = x & 0x11111111;?// Every 4th bit.
x = x * 0x11111111;?// Sum the digits (each 0 or 1).
x = x >> 28;牋牋牋牋 // Position the result.
In these, the last two steps may be replaced with steps to compute the remainder of x modulo 15.
These are not particularly good; most programmers would probably prefer to use table lookup. The latter algorithm above, however, has a version that uses 64-bit arithmetic, which might be useful for a 64-bit machine that has fast multiplication. Its argument is a 15-bit quantity. (I don't believe there is a similar algorithm that deals with 16-bit quantities, unless it is known that not all 16 bits are 1.) The data type long long is a GNU C extension [Stall], meaning twice as long as an int, in our case 64 bits. The suffix ULL makes unsigned long long constants.
int pop(unsigned x) {牋 unsigned long long y;
牋爕 = x * 0x0002000400080010ULL;
牋爕 = y & 0x1111111111111111ULL;
牋爕 = y * 0x1111111111111111ULL;
牋爕 = y >> 60;
牋爎eturn y;
}
Counting 1-Bits in an Array
The simplest way to count the number of 1-bits in an array of fullwords, in the absence of the population count instruction, is to use a procedure such as that of Figure 5-2 on page 66 on each word of the array, and simply add the results.
Another way, which may be faster, is to use the first two executable lines of that procedure on groups of three words of the array, adding the three partial results. Because each partial result has a maximum value of 4 in each 4-bit field, adding three of these partial results gives a word with at most 12 in each 4-bit field, so no sum overflows into the field to its left. Next, each of these partial results may be converted into a word having four 8-bit fields with a maximum value of 24 in each field, using
x = (x & 0x0F0F0F0F) + ((x >> 4) & 0x0F0F0F0F);
As these words are produced, they may be added until the
maximum value is just less than 255; this would allow summing ten such words ![]() When ten such words have been added, the result may
be converted into a word having two 16-bit fields, with a maximum value of 240
in each, with
When ten such words have been added, the result may
be converted into a word having two 16-bit fields, with a maximum value of 240
in each, with
x = (x & 0x00FF00FF) + ((x >> 8) & 0x00FF00FF);
Lastly, 273 such words ![]() can be added together
until it is necessary to convert the sum to a word consisting of just one
32-bit field, with
can be added together
until it is necessary to convert the sum to a word consisting of just one
32-bit field, with
x = (x & 0x0000FFFF) + (x >> 16);
In practice, the instructions added for loop control
significantly detract from what is saved, so it is probably overkill to follow
this procedure to the extent described. The code of Figure 5-5 applies the idea with only one
intermediate level. First, it produces words containing four 8-bit partial
sums. Then, after these are added together as much as possible, a fullword sum
is produced. The number of words of 8-bit fields that can be added with no
danger of overflow is ![]()
Figure 5-5 Counting 1-bits in an array.
int pop_array(unsigned A[], int n) {牋 int i, j, lim;
牋爑nsigned s, s8, x;
牋 s = 0;
牋爁or (i = 0; i < n; i = i + 31) {牋牋?lim = min(n, i + 31);
牋牋牋s8 = 0;
牋牋牋for (j = i; j < lim; j++) {牋牋牋牋 x = A[j];
牋牋牋牋爔 = x - ((x >> 1) & 0x55555555);
牋牋牋牋爔 = (x & 0x33333333) + ((x >> 2) & 0x33333333);
牋牋牋牋爔 = (x + (x >> 4)) & 0x0F0F0F0F;
牋牋牋牋爏8 = s8 + x;
牋牋牋}
牋牋牋x = (s8 & 0x00FF00FF) + ((s8 >> 8) & 0x00FF00FF);
牋牋牋x = (x & 0x0000ffff) + (x >> 16);
牋牋牋s = s + x;
牋爙
牋爎eturn s;
}
This algorithm was compared to the simple loop method by compiling the two procedures with GCC to a target machine that is very similar to the basic RISC. The result is 22 instructions per word for the simple method, and 17.6 instructions per word for the method of Figure 5-5, a savings of 20%.
Applications
An application of the population count function is in computing the "Hamming distance" between two bit vectors, a concept from the theory of error-correcting codes. The Hamming distance is simply the number of places where the vectors differ; that is,
![]()
See, for example, the chapter on error-correcting codes in [Dewd].
Another application is to allow reasonably fast direct-indexed access to a moderately sparse array A that is represented in a certain compact way. In the compact representation, only the defined, or nonzero, elements of the array are stored. There is an auxiliary bit string array bits of 32-bit words, which has a 1-bit for each index i for which A[i] is defined. As a speedup device, there is also an array of words bitsum such that bitsum[j] is the total number of 1-bits in all the words of bits that precede entry j. This is illustrated below for an array in which elements 0, 2, 32, 47, 48, and 95 are defined.

Given an index i,
0 ![]() i
i ![]() 95,
the corresponding index sparse_i into the data
array is given by the number of 1-bits in array bits
that precede the bit corresponding to i. This
may be calculated as follows:
95,
the corresponding index sparse_i into the data
array is given by the number of 1-bits in array bits
that precede the bit corresponding to i. This
may be calculated as follows:
j = i >> 5;牋牋牋牋牋牋牋?牋// j = i/32.
k = i & 31;牋牋牋牋牋牋牋牋?// k = rem(i, 32);
mask = 1 << k;牋牋牋牋牋牋牋 // A "1" at position k. if ((bits[j] & mask) == 0) goto no_such_element; mask = mask - 1;牋牋牋牋牋牋 // 1's to right of k. sparse_i = bitsum[j] + pop(bits[j] & mask);
The cost of this representation is two bits per element of the full array.
Still another application of the population function is in computing the number of trailing 0's in a word (see "Counting Trailing 0's" on page 84).