|
|
< Day Day Up > |
|
21.4 Databases Explained (in Five Minutes or Less)Simply put, databases store information. You encounter them every day in one way or another, whether charging a dinner on a credit card or calling Moviefone to get local movie listings. A database is like an electronic filing cabinet that stores related information. At home, you might have a filing cabinet to store the bits and pieces of your life. For instance, you might have a filing folder labeled Insurance, in which you keep information about the various insurance policies you carry. Other folders might contain information on phone bills, car service records, and so on. 21.4.1 Tables and RecordsDatabases have an electronic equivalent to filing folders: tables. A table is a container for information about a set of similar items. For example, in the Exapserater's online store database, a table stores information on all of the products for sale on the site. The table tracks certain information梚n the Products table, the name of the product for sale, its price, a short description, and a few other items. Each piece of information, like price, is stored in a column. All the information for each product (all the columns taken together, in other words) make up a single record, which is stored in a row (see Figure 21-6). If you were designing a database, you'd try to model a table on some real-world item you needed to track. If your database was used for generating invoices for your business, you might have a table called Invoices in which you'd store information such as the invoice number, date, and so on. Since your customers are another source of data that needs tracking, you'd also create a table called Customers to store the information about them. This diagram shows the structure of the Products table, in which four records are stored. Each row in a table represents a single record or item, while each piece of information for a record is stored in a single field or column.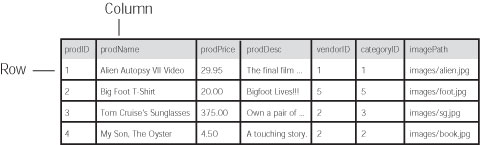
NOTE
If you're designing a database to track a business process that you already track on paper, a good place to start is with the forms you use. For example, if your company uses a personnel form for collecting information on each employee in the business, you've got a ready-made table. Each box on the form is the equivalent to a category column in a table. In addition to the Products table, the National Exasperater also tracks the vendors who manufactured the products. (After all, after they run out of inventory, the online store staff will need to order more products from their vendors.) Because a product and a vendor are really two different things, the database has a second table, called Vendors, that lists all the companies that make the products for sale on the Web site. You might think, "Hey, let's just put all that information into the first table." After all, you could consider the vendor's information as part of the information for each product. While it seems like this might simplify things (because you'd have one table instead of two), it can actually create a lot of problems. Imagine this scenario: The National Exasperater begins selling a hot new item, Alien Autopsy VII, produced by Area 51 Films. All the product information, including the name and price of the film, as well as the phone number and mailing address for Area 51 Films, are stored in a single table row. Next month, Area 51 Films releases another film. But, in the meantime, having to stay one step ahead of certain government agencies, Area 51 has changed its phone number and moved to another state. So when someone at the National Exasperater adds the new film to the Products database, she adds the new phone number and address as part of the new film's record. Now the database contains two sets of contact information for Area 51 Films - one for each film. Not only does this redundant data take up extra space, but the contact information in one record is now wrong. An even worse problem could happen when deleting a record. Suppose that the online store decides to discontinue the two videos from Area 51 Films. If an Exasperater staffer removes those two records from the database, she also deletes any contact information for Area 51 Films. If the Exasperater staff ever decide to stock up on videos again, they have no way of contacting the vendor. Now you can see why it's prudent to keep separate classes of information in different tables. With two tables, when Area 51 Films moves, you only have to update the information in the Vendors table, without touching the Products table at all. This way, if the staff deletes a product, they'll still have a way of contacting the vendor to learn about new products. You may be wondering, with a setup like this, how to tell which vendor makes which product. All you have are two distinct tables梠ne with just product information and one with just vendor information. How do you make the connection? NOTE
For a great book on database design check out Database Design for Mere Mortals, by Michael J. Hernandez. 21.4.2 Relational DatabasesTo connect information between tables, you create a relationship between them. In fact, databases that use multiple related tables are called relational databases. The most common way to connect tables is by using what's called a primary key梐 serial number or some other unique identifying flag for each record in the table. In the case of the Exasperater database, the Products table includes a field named prodID, the product's ID (see Figure 21-7). Whenever a product is added to the database, it's assigned a new number. If you're building a database that contains a table about employees, for example, you might use an employee's social security number as a primary key. Each table should have a primary key梐 column that contains a unique identifier for each record in a table. To relate information from one table to another, it's common to add an additional column with information pertaining to another table. In this case, a column called vendorID in the Products table contains a primary key from the Vendors table. To determine which vendor produces the Big Foot T-Shirt, say, look at the fifth column in the Products table, which identifies the vendor's ID number as 4. When you check the Vendors table, you see that vendor 4 is Strange Stuff, Inc. A column that contains the primary key of another tableis called a foreign key.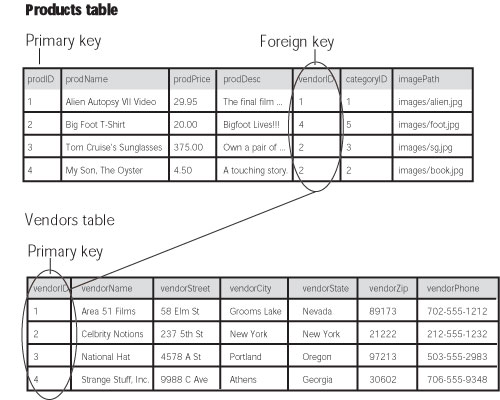
The Vendors table has a primary key named, not so creatively, vendorID. This key, too, is generated automatically whenever a new vendor is added to the database. To join these two tables, you'd add another column to the Products table called vendorID (see Figure 21-7). Instead of storing all the contact information for a vendor within the Products table, you simply store the vendor's ID number. To find out which vendor makes which product, you can look up the product in the Products table, find the vendor's ID number in the vendorID column, and use that information to look up the vendor in the Vendors table. While this hopscotch approach of accessing database tables is a bit confusing at first, it has many benefits. Not only does it prevent the kinds of errors mentioned earlier, it also simplifies the process of adding a new product from a vendor. For example, when Area 51 Films adds yet a third title to their video collection, a store staff person determines if any of Area 51 Films' info has changed (by checking it against the Vendors table). If not, she simply adds the information for the new product and leaves the vendor's contact info untouched. Thus, relational databases not only prevent errors, but also make data entry faster. Databases, of course, can be much more complicated than this simple example. It can take many tables to accurately hold the data needed to run a complex e-commerce site such as Amazon.com. In some cases, you may already be working with a previously created database, so you won't have to worry about creating one, or even learning more than what's described above. For the tutorials in this section of the book, you'll use the already created National Exasperater Database. |
|
|
< Day Day Up > |
|