When using ADO, you frequently will want to code a SQL statement when setting properties or calling methods for connections, recordsets, and commands. Therefore, to fully exploit the potential of these ADO and Access objects, you need some knowledge of SQL. This section details the use of Jet SQL for select queries. Because applications frequently rely on select queries to provide record sources for forms, reports, and Web pages, learning the syntax of these queries can be very helpful.
| Note |
It is common in Access to create queries graphically with the help of the Query Designer. You can then copy the SQL view of a query and paste it into your code. While this technique works, it makes your code-based application development dependent on a graphical tool. If you learn a few basic SQL design principles, however, you will be able to manually code most or all of your queries without the help of the Query Designer. |
This section systematically examines nearly all the Jet SQL clauses that assist in returning rows from record sources. By mastering the samples in this section, you will gain two benefits. First, you'll learn to rapidly design the types of select queries that you're most likely to use. Second, you'll gain the confidence needed to easily understand select queries that are not explicitly covered in this section.
Perhaps the best place to start learning SQL is with the most basic statement, which returns all the columns from all the rows of a record source. This record source can be a table, another query, or a combination of two or more tables and queries. In its most basic format, the source for a select query is a table. The statement's general form is:
SELECT * FROM <table-name>
Traditionally, SQL developers express keywords in uppercase, such as SELECT and FROM, but Jet SQL and many other SQL dialects do not require you to use uppercase for keywords. The asterisk (*) is a shortcut that denotes all the fields in a record source. The <table-name> placeholder appearing directly after the FROM keyword denotes the record source for the query.
While select queries have uses in several ADO contexts, one of their most typical uses is as the source argument for a recordset. This is because select queries return a virtual table that Recordset objects are especially equipped to process. For example, recordsets have navigation methods and collections for passing through the data values in the virtual table returned by a select query.
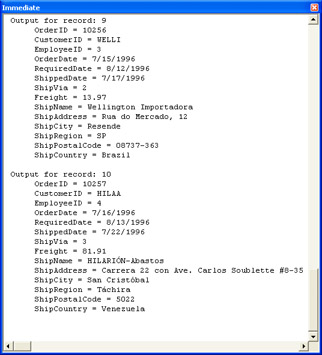
This chapter's first code sample, which follows, demonstrates the most basic SQL select query. It returns all the columns from all the rows of the Orders table in the Northwind database. The first procedure, SelectAllFields, assigns values to as many as two string variables. The application requires a first string of strSQL. This variable contains a Jet SQL statement that can generate a recordset. The second string, strSrc, is optional. This second string points at the connection string for a Jet data source. The first procedure concludes by invoking PreviewRecordsetSource, the second procedure. The code sample shows only the designation of the required argument. This syntax passes an empty string ("") as the value of the optional second argument, strSrc. By removing the comment markers from the assignment statement for strSrc at the top of the procedure and inserting the path to the database file you want to use, you can ready strSrc for passing to PreviewRecordsetSource. Then, when you invoke the second procedure, insert a comma after strSQL and type strSrc.
The basic design of this first sample will be the standard format I'll use to demonstrate all select query samples in this section of the chapter. In fact, all the subsequent code samples in this section reuse the PreviewRecordsetSource procedure, which enumerates all the columns for the first 10 rows of the result set returned by the SQL statement. It organizes and labels the results by record. As we move on to more complex select queries, this procedure will help you understand the effects of alternate SQL syntax formulations. In addition, you can use the second procedure to explore your own design changes to the samples in this chapter.
Sub SelectAllFields() Dim strSrc As String Dim strSQL As String 'Remove comment markers to test optional source 'strSrc = "Provider=Microsoft.Jet.OLEDB.4.0;" & _ ' "Data Source=C:\Program Files\Microsoft Office\" & _ ' "Office11\Samples\Northwind_backup.mdb" 'Query, selecting all fields from the Orders table strSQL = "SELECT * FROM Orders" 'Pass arguments to PreviewRecordsetSource, including 'strSQL, and, optionally, strSrc. PreviewRecordsetSource strSQL End Sub Sub PreviewRecordsetSource(strSQL As String, _ Optional strSrc As String) Dim rst1 As ADODB.Recordset Dim fld1 As Field Dim int1 As Integer 'Assign a default data source if none is designated. If strSrc = "" Then strSrc = "Provider=Microsoft.Jet.OLEDB.4.0;" & _ "Data Source=C:\Program Files\Microsoft " & _ "Office\Office11\Samples\Northwind.mdb" End If 'Open recordset on passed SQL string (strSQL) 'from the designated data source (strSrc) Set rst1 = New ADODB.Recordset rst1.ActiveConnection = strSrc rst1.Open strSQL 'Loop through first 10 records, 'and print all non-OLE object fields to the 'Immediate window. int1 = 1 Do Until rst1.EOF Debug.Print "Output for record: " & int1 For Each fld1 In rst1.Fields If Not (fld1.Type = adLongVarBinary) Then _ Debug.Print String(5, " ") & _ fld1.Name & " = " & fld1.Value Next fld1 rst1.MoveNext If int1 >= 10 Then Exit Do Else int1 = int1 + 1 Debug.Print End If Loop 'Clean up objects. rst1.Close Set rst1 = Nothing End Sub
Figure 4-1 presents an excerpt from the output generated by running this code sample. This screen shot of the Immediate window shows the output from the last two records. The Northwind database contains 830 records in its Orders table, but the second procedure limits the rows processed to the first 10 rows. However, the procedure does print values for all the columns available on each row. Each row's output starts with a header label. Then, the procedure shows each column's name and value separated by an equal sign (=).
Instead of displaying all fields from a record source, a select query can return a subset of the columns. To achieve this, you list individual field names within the SELECT statement in the order that you want them to appear. The following sample prints values from just two columns in the Products table to the Immediate window:
Sub SelectSomeFields() Dim strSrc As String Dim strSQL As String 'Query returning selected fields from the Products table strSQL = "SELECT ProductName, Discontinued FROM Products" PreviewRecordsetSource strSQL End Sub
In general, you should return only the subset of columns that your application needs. This improves performance. If your application needs all the columns in a record source, you can list them in the SELECT statement. However, using the asterisk wildcard symbol (*) to indicate that you want all the columns eliminates the need to update your code if a column is added, deleted, or renamed in the table.
Many applications require a subset of both the columns and rows from an original record source. When you need to filter the rows, add a WHERE clause to your select query. This clause should have at least one character, such as a blank space or carriage return, between its start and the FROM keyword argument. The WHERE clause arguments correspond to the Criteria row of the Query Designer. The following code sample returns rows that represent all currently active inventory items in the Products table. The WHERE clause excludes selected rows based on their Discontinued column values. Whenever the expression in the WHERE clause is true, the corresponding row from the original source appears in the result set. This code sample differs from the preceding one, which showed products regardless of whether they were still being sold.
Sub SelectSomeFieldsAndRows() Dim strSrc As String Dim strSQL As String Dim bol1 as Boolean 'Query demonstrates use of Boolean variable in WHERE clause 'to return a list of discontinued products. bol1 = False strSQL = "SELECT ProductName, Discontinued FROM Products " & _ "WHERE Discontinued = " & bol1 PreviewRecordsetSource strSQL End Sub
WHERE clause arguments frequently have the form <columnname> <operator> <expression>, such as Discontinued = False. You can also write compound expressions by using the AND and OR operators. In addition, you can use parentheses to designate the order in which operators compute. Enclose terms and operators in parentheses when you want the operator between them to compute before adjacent operators.
Your expressions for WHERE clauses can draw on the full extent of SQL. For example, you can use the IN keyword as an operator. Using the IN keyword enables you to easily specify values for any column that qualify a record for inclusion in a select query's result set. The following sample shows only customers from the United Kingdom and the United States:
Wildcard symbols in expressions expand the flexibility with which you can designate rows for inclusion in a select query's result set. However, some traditional wildcard symbols used with the Query Designer need modification before you can use them in SQL WHERE clauses with ADO. This can be confusing because it means you cannot simply cut and paste code from the Query Designer's SQL windows into the source argument for a recordset's Open method; before the copied code can run, you must translate wildcard symbols for use with ADO. Table 4-1 compares traditional Access wildcard parameters with those suitable for use in SQL WHERE clauses with ADO.
You can use the percent symbol (%) at either the beginning or the end of an expression for a LIKE argument. You can also use % in combination with the other symbols shown in Table 4-1. The pattern-matching code samples, which appear after the % and underscore (_) samples in this section, show how to use the exclamation point (!) and % symbols together. One of the most common uses of the % symbol is for extracting all records with a particular prefix. The following sample shows the syntax for extracting all customers from countries beginning with the letter U. In the Access Northwind database, this code would return only customers from the United Kingdom and the United States—the same results you just saw in the IN keyword sample. However, adding the % symbol might return more results, depending on the table's contents. If the source table included customers from Uruguay, the LIKE 'U%' expression would include these customers in its result set, but the IN ('UK', 'USA') expression would not.
Sub SelectWithMultiCharacterWildcard() Dim strSrc As String Dim strSQL As String 'Use % instead of * with multicharacter wildcard searches. 'Query returns customers from any country beginning with U. strSQL = "SELECT CompanyName, ContactName, Country FROM Customers " & _ "WHERE Country LIKE 'U%'" PreviewRecordsetSource strSQL End Sub
The next sample shows the use of the _ wildcard symbol. This symbol matches any single character in a string. You use the _ symbol to develop more restrictive criteria than the % symbol allows. In this sample, the TRA_H argument for the LIKE operator extracts records with CustomerID column values of TRADH and TRAIH. Any customer record will match the expression, as long as the first three characters for CustomerID are TRA and the fifth character is H.
Sub SelectWithSingleCharacterWildcard() Dim strSrc As String Dim strSQL As String 'Use _ instead of ? with single-character wildcard searches. 'Query returns any customer starting with TRA and ending 'with H (CustomerID is always 5 characters long). strSQL = "SELECT CustomerID, CompanyName, ContactName, " & _ "Country FROM Customers " & _ "WHERE CustomerID LIKE 'TRA_H'" PreviewRecordsetSource strSQL End Sub
You can use the wildcard symbols with [ ] delimiters to denote lists and ranges of characters that satisfy a criterion. The expression [ACEH-M] indicates a match with the letters A, C, E, or any letter from H through M. The expression A[A-M]% in the following sample specifies a CustomerID field value with A as its first character and any letter from A through M as its second character, with no restrictions on the remaining CustomerID characters. For the Customers table, this criterion expression returns a single record whose CustomerID field value is ALFKI.
Sub SelectWithPatternMatch() Dim strSrc As String Dim strSQL As String 'Use traditional [begin-end] syntax for pattern matches. 'Query returns customer IDs beginning with A and containing 'any of the first 13 letters of the alphabet in their 'second character. strSQL = "SELECT CustomerID, CompanyName, ContactName, " & _ "Country FROM Customers " & _ "WHERE CustomerID LIKE 'A[A-M]%'" PreviewRecordsetSource strSQL End Sub
The next two samples reinforce the use of [ ] delimiters in LIKE arguments while introducing the ! symbol. When used within brackets, the ! symbol serves as a NOT operator. The first of these two samples has an argument of A[N-Z]%. This argument specifies all records with a customer ID that begins with A and is followed by any letter from N through Z. The expression places no restrictions on the remaining customer ID characters. For the Customers table in the Northwind database, this criterion expression returns records with customer ID values of ANATR, ANTON, and AROUT.
The second sample places a ! symbol in front of the range N through Z for the second character. Here, the ! symbol specifies that this character cannot fall in the range of N through Z; in other words, the letters A through M—as well as numbers, punctuation characters, and so forth—satisfy the criterion. This second sample returns a record with a CustomerID value of ALFKI. Because of a constraint (or validation rule) for the CustomerID field in the Customers table, only letters are legitimate characters for CustomerID field values.
Sub SelectWithPatternMatch2() Dim strSrc As String Dim strSQL As String 'Query returns CustomerIDs beginning with A and any of the 'last thirteen letters of the alphabet in their second character strSQL = "SELECT CustomerID, CompanyName, ContactName, " & _ "Country FROM Customers " & _ "WHERE CustomerID LIKE 'A[N-Z]%'" PreviewRecordsetSource strSQL End Sub Sub SelectWithPatternMatch3() Dim strSrc As String Dim strSQL As String 'Query returns CustomerIDs beginning with A and not any of the 'last thirteen letters of the alphabet in their second character strSQL = "SELECT CustomerID, CompanyName, ContactName, " & _ "Country FROM Customers " & _ "WHERE CustomerID LIKE 'A[!N-Z]%'" PreviewRecordsetSource strSQL End Sub
As noted in the previous discussion, traditional Access wildcard symbols differ from the wildcard symbols in ADO SQL expressions. An alternate set of Access wildcard symbols is available, however. The traditional symbols are the default symbols in the Query Designer, but the setting can be changed from the wildcard symbols in the first column of Table 4-1 to those in the second column. To change the default setting in Access, choose Options on the Tools menu. Then, select the Tables/Queries tab in the Options dialog box. The first check box in the SQL Server Compatible Syntax (ANSI 92) area on the Tables/Queries tab permits you to invoke the alternate set of wildcard symbols for the current database. An additional check box lets you select the alternate set of wildcard symbols as the default when creating a new database. However, you cannot affect the wildcard setting for other existing databases. Also, changing the wildcard setting can break existing query expressions that use the traditional wildcard symbols in the current database.
The Help display for these controls says they ensure SQL Server compatibility. This is true for the * and ? wildcard symbols. However, when working with a Jet database, the traditional ! symbol applies rather than the caret symbol (^) that SQL Server uses. For example, the following SQL statement returns one record with a CustomerID value of ALFKI when run from a Query Designer SQL window against the Access Northwind database. The same statement run from the SQL Server Query Analyzer against the SQL Server Northwind database returns three records with CustomerID field values of ANATR, ANTON, and AROUT because SQL Server interprets an ! as a regular character in the character list instead of as a wildcard.
SELECT CustomerID, CompanyName, ContactName, Country FROM Customers WHERE CustomerID LIKE 'A[!N-Z]%'
By changing the ! to a ^ in the SQL Server Query Analyzer (as shown in the following code), you can return a single record whose CustomerID is ALFKI. However, this same expression returns three rows with CustomerID values of ANATR, ANTON, and AROUT when run from the Query Designer SQL window against the Access Northwind database. That's because Access interprets the ^ character as a regular character instead of as a wildcard.
SELECT CustomerID, CompanyName, ContactName, Country FROM Customers WHERE CustomerID LIKE 'A[^N-Z]%'
When working with imported data from legacy systems, you will commonly encounter situations where values in fields are repeated. Many applications working with this kind of data will nevertheless require a list of unique column values in a result set. For example, when working with a combo box, you do not want the items in the drop-down box to be repeated, even if they are repeated in the original record source.
The Order Details table in the Northwind database repeats values in an important field named OrderID. This field occurs once for each line item within an order. The Northwind database contains a separate Orders table that has OrderID as its primary key; however, legacy databases do not always offer this convenience. Even if the legacy database you're using does have this feature, a copy of it might not be available when you need it.
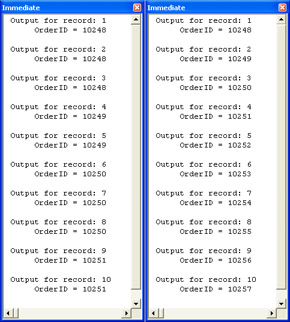
The next two procedures provide a listing of OrderID field values from the Order Details table. The procedure named SelectNotDistinctOrderDetails defines a basic select query against the Order Details table with OrderID as the sole field returned. The first 10 rows from this query—see the list on the left in Figure 4-2—repeats OrderID whenever an order has more than one line item. For example, in the first three rows OrderID is equal to 10248. The SelectDistinctOrderDetails procedure adds the DISTINCT keyword to the basic select query syntax. The addition of the DISTINCT keyword eliminates duplicates in the result set from the query. The list on the right in Figure 4-2 shows each OrderID on just one row. In the following code, note the brackets around Order Details. These are necessary because the table name contains an internal blank character.
Sub SelectNotDistinctOrderDetails() Dim strSrc As String Dim strSQL As String 'Query returns order IDs from line items even if they repeat strSQL = "SELECT OrderID FROM [Order Details] " PreviewRecordsetSource strSQL End Sub Sub SelectDistinctOrderDetails() Dim strSrc As String Dim strSQL As String 'Query returns unique order IDs from table of order line 'items (Order Details) strSQL = "SELECT DISTINCT OrderID FROM [Order Details] " PreviewRecordsetSource strSQL End Sub
The DISTINCT keyword is a predicate for a SELECT statement in SQL. As you can see, it modifies the behavior of the SELECT keyword. Jet SQL supports other predicates that you might find useful, including TOP, DISTINCTROW, and ALL. Access Help for Jet SQL contains discussions and samples of these predicate terms. Table 4-2 lists the SELECT keyword predicates and brief descriptions of their behavior.
A calculated field is a field that your SQL code computes for each row in a record source. The calculation can be for string, date, integer, currency, or floating-point values. A calculated field unites two or more independent column values into a new column within the virtual table that a SELECT statement defines.
Use the ORDER BY clause in a SELECT statement to override the default order of rows in a result set. The ORDER BY clause should be the last clause in a select query's SQL statement. The arguments within an ORDER BY clause specify on which fields to sort rows in the result set. When you have more than one field on which to sort records, separate them by commas. When you have multiple sort fields, records are sorted according to the order of the field names in the ORDER BY clause. The default sort order for individual fields in an ORDER BY clause is ascending. You can explicitly specify to sort records in an ascending order by following the column name with a space and the keyword ASC. If you want rows to appear in descending order, use the keyword DESC.
If you do not designate an ORDER BY clause, Jet arranges rows in the order of the primary key. When a select query joins two or more tables, Jet's default order is determined by the primary key of the table that participates on the one-side of a one-to-many relationship at the top-level join in the record source. If no primary key exists, Jet arranges the records in the order of entry.
SQL does not require any special correspondence between the ORDER BY clause and calculated fields. However, using calculated fields when ordering the rows of a virtual table can lead to several special issues, which I'll discuss here.
The next sample demonstrates the syntax for combining two columns with string values into a calculated column. The input columns are FirstName and LastName; they originate from the Employees table in the Northwind database. The expression for the calculated field creates a new column by combining the FirstName and LastName columns with a blank space between them.
Sub SelectWithCalculatedField() Dim strSrc As String Dim strSQL As String 'A calculated field (Full name) based on text columns strSQL = "SELECT FirstName & ' ' & LastName AS [Full name], " & _ "City FROM Employees" PreviewRecordsetSource strSQL End Sub
Although the EmployeeID field does not appear in the SQL statement in the SelectWithCalculatedField procedure, the records appear sorted according to the value of this field because EmployeeID is the primary key for the Employees table. You can override this default order by appending an ORDER BY clause to the SQL statement. You can force a sort on any original field or on a field calculated from within the SQL statement. The following sample sorts the result set. The result set from the next SQL statement shows the calculated Full name field sorted by the LastName column from the Employees table.
Sub SelectWithCalculatedFieldAndOrderLastNames() Dim strSrc As String Dim strSQL As String 'A calculated field (Full name) based on text columns 'with a sort on an original text column (LastName) strSQL = "SELECT FirstName & ' ' & LastName AS [Full name], " & _ "City FROM Employees ORDER BY LastName" PreviewRecordsetSource strSQL End Sub
The next sample includes a SQL statement that returns all rows from the Orders table with an OrderDate field value less than or equal to the last day in 1997. The ORDER BY clause sorts the rows, using the most recent date as the first record. This SQL statement shows the syntax for including a date as a criterion. Notice that the date appears within two pound signs (#). Recall that Access represents dates as floating numbers internally. The larger the number's value, the more recent the date. Therefore, you use DESC to sort records with the most recent date appearing first.
Sub SelectForDateCriterionAndDescendingOrder() Dim strSrc As String Dim strSQL As String Dim strDate As String strDate = "#12/31/97#" 'Query returns orders through end of 1997 sorted 'with most recent dates first strSQL = "SELECT OrderID, OrderDate FROM Orders " & _ "WHERE OrderDate <= " & strDate & _ " ORDER BY OrderDate DESC" PreviewRecordsetSource strSQL End Sub
The two samples you just saw illustrate how to use the ORDER BY clause with columns that already exist in a record source. However, the syntax changes slightly if you use the ORDER BY clause with a calculated field. In such an instance, you cannot use the name of the calculated field; instead your SQL statement must restate the expression for the calculated field in the ORDER BY field list. The following sample sorts its rows by a calculated field named Total Revenue, which is the product of the UnitPrice and Quantity columns multiplied by 1 minus the value of the Discount column. Notice that the ORDER BY clause repeats the full expression for the calculated Total Revenue field rather than using just the field name, as in the two samples we just looked at. The SQL statement in the next sample uses the FORMATCURRENCY function to apply a currency format to a calculated field. Notice that you can designate the number of places that appear after the decimal point. The sample shows Total Revenue to the nearest penny for line items in the Order Details table.
Sub SelectDescendingOnACalculatedField() Dim strSrc As String Dim strSQL As String 'Query returns order line items with formatted, calculated 'field (Total Revenue) and sorts in descending order on the 'same field strSQL = "SELECT OrderID, " & _ "FORMATCURRENCY(UnitPrice*Quantity*(1-Discount),2) " & _ "AS [Total Revenue] FROM [Order Details] " & _ "ORDER BY UnitPrice*Quantity*(1-Discount) DESC" PreviewRecordsetSource strSQL End Sub
An aggregated field is a calculated field that computes a result across multiple rows instead of within a single row. In addition, an aggregated field relies on SQL aggregate functions. The obvious SQL functions are SUM, AVG, and COUNT. The other SQL functions an aggregated field might use include those for computing standard deviation and variance, finding minimum or maximum values, and returning the first or last row in a result set.
You will frequently invoke an aggregate function in a SQL statement that includes a GROUP BY clause. The GROUP BY clause collapses multiple records with the same field values into a single row within the result set. If you specify an aggregate function for a column in the collapsed rows, that function reflects the aggregated field value for the rows that are collapsed. If you use an aggregate function without a GROUP BY clause, the function computes its aggregated results across all the records in the recordset; that is, all the records denoted by the arguments of the FROM clause.
The following sample demonstrates the use of the SUM, AVG, and COUNT functions to compute aggregated results across all the records in the Order Details table. The SQL statement returns a single row with three fields labeled Total Revenue, Total Order Line Items, and Avg Revenue/Item. The SUM function aggregates the extended price, UnitPrice*Quantity*(1-Discount), across all line items to generate Total Revenue. The Total Order Line Items column value reflects the number of line item rows in the Order Details table through the application of the Count function to OrderID. The Avg Revenue/Item column value is the average extended price for all line items—again across every row in the Order Details table. This last column demonstrates the use of the AVG aggregate function.
Sub SelectWithAggregatedFunctions() Dim strSrc As String Dim strSQL As String 'Selected aggregate function results strSQL = "SELECT " & _ "FORMATCURRENCY(SUM(UnitPrice*Quantity*(1-Discount)),2) " & _ "AS [Total Revenue], " & _ "COUNT(OrderID) AS [Total Order Line Items], " & _ "FORMATCURRENCY(AVG(UnitPrice*Quantity*(1-Discount)),2) " & _ "AS [Avg Revenue/Item] " & _ "FROM [Order Details]" PreviewRecordsetSource strSQL End Sub
Many applications require aggregated results across subsets of the records in a record source instead of across the whole recordset. Adding a GROUP BY clause to a SQL statement with an aggregate function satisfies this need. You can invoke the GROUP BY clause with one or more fields in its list, just as you can with the ORDER BY clause. If you have more than one field in the list for a GROUP BY clause, the records will group in a nested fashion (the second field nesting within the first field, the third field nesting within the second, and so forth).
The following sample computes the units in stock from the Products table of the Northwind database for product groupings defined by whether they have been discontinued and by their category. Figure 4-3 presents an excerpt from the sample's output. The first five records in the result set all represent discontinued products. All the remaining records in the result set (of which the excerpt shows three) denote current products. This ordering of records occurs because the Discontinued column appears before CategoryID in the GROUP BY list. Notice also that the output does not contain output for discontinued items with CategoryID values of 3 and 4. This is because the Products table has no rows with discontinued products for these categories. Finally, observe that the second record's output has no units in stock. This record appears in the result set because there is a discontinued product with a value of 0 representing the units in stock. The alias for the UnitsInStock column provides for a nicer label in the output.
Sub SelectGroupBy() Dim strSrc As String Dim strSQL As String 'Query returns sum of units in stock by category, 'regardless of whether the product is discontinued strSQL = "SELECT Discontinued , CategoryID, SUM(UnitsInStock) " & _ "AS [Units In Stock]" & _ "FROM Products " & _ "GROUP BY Discontinued , CategoryID" PreviewRecordsetSource strSQL End Sub
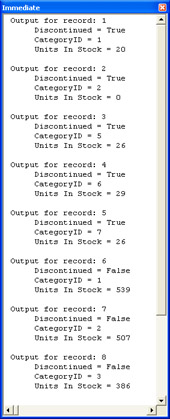
By adding a HAVING clause to a SQL statement with a GROUP BY clause, you can filter the result set from the SQL statement. The HAVING clause operates like a WHERE clause, except that the HAVING clause filters results from a GROUP BY clause. For example, the SelectGroupByWithHaving procedure shown next returns only four records. These four records denote products that are discontinued, because the expression in the HAVING clause filters for just these records from the GROUP BY clause. In addition, the result set excludes the row containing a value of 0 for units in stock. The second term in the HAVING clause filters such records from the result set.
Sub SelectGroupByWithHaving() Dim strSrc As String Dim strSQL As String 'Query returns sum of units in stock by category 'for discontinued products only strSQL = "SELECT Discontinued , CategoryID, SUM(UnitsInStock) " & _ "AS [Units In Stock]" & _ "FROM Products " & _ "GROUP BY Discontinued , CategoryID " & _ "HAVING Discontinued =True and SUM(UnitsInStock)>0" PreviewRecordsetSource strSQL End Sub
One of the most powerful features of select queries is their ability to combine two or more tables into one virtual table. An inner join offers one way to accomplish this. This technique permits only the merger of two tables. But you can join two merged tables with a third record source, and you can merge that result with yet another, and so on. These nested inner joins can occur in a single SELECT statement. The result set from the select query can include fields from any record sources that it merges.
You can join two record sources on any field or fields with the same data type (other than Memo or OLEObject data types). Designate the tables to join as arguments of the FROM keyword in a select query. Separate the table names with the INNER JOIN keywords. Follow the second record source with the ON keyword, which signals the subsequent identification of the fields on which to join the record sources. Typically, you merge record sources when the corresponding fields from each record source are equal (called an equijoin), but you can use any equality operator, including <, >, <=, >=, and <>.
The following code sample, the SelectInnerJoin procedure, demonstrates the syntax for an inner join between the Categories and Products tables in the Northwind database. The SQL statement merges the two record sources with an equijoin of the CategoryID field in each table. The SELECT statement has a field list that extracts the CategoryName column from the Categories table and the ProductName and Discontinued columns from the Products table. Notice that table names serve as prefixes to field names. Using table names as prefixes is optional, unless two or more tables in the SQL statement contain fields with the same name.
Sub SelectInnerJoin() Dim strSrc As String Dim strSQL As String 'Query returns products with their category names strSQL = "SELECT Categories.CategoryName, Products.ProductName, " & _ "Products.Discontinued " & _ "FROM Categories INNER JOIN Products " & _ "ON Categories.CategoryID = Products.CategoryID" PreviewRecordsetSource strSQL End Sub
The SelectInnerJoinWithAliases procedure performs an identical join to the sample you just saw. However, it uses aliases to designate record sources. The letter c represents the Categories table name, and the letter p denotes the Products table. The syntax shows how you define the table aliases as arguments for the FROM keyword. You can use the aliases in place of record source names both in the SELECT statement field list and as prefixes for the fields listed as ON keyword arguments for merging the two record sources. The following code sample illustrates this concept:
Sub SelectInnerJoinWithAliases() Dim strSrc As String Dim strSQL As String 'Query returns products with their category names strSQL = "SELECT c.CategoryName, p.ProductName, " & _ "p.Discontinued " & _ "FROM Categories c INNER JOIN Products p " & _ "ON c.CategoryID = p.CategoryID" PreviewRecordsetSource strSQL End Sub
The final inner join sample we'll look at demonstrates the integration of several design elements of select queries. This next sample shows the syntax for joining three tables in a single SELECT statement. The first join is between the Customers and Orders tables. The merge occurs on the CustomerID field in both tables. The result set from that merger joins with the Order Details table on the OrderID field. This field exists in the merger of the Customers and Orders tables as well as in the Order Details table.
The SQL statement for this final inner join sample groups records by the CompanyName field in the Customers table, and it computes the revenue for each customer. The code uses a SUM function to aggregate revenue. The GROUP BY clause causes SUM to aggregate revenue by customer, or more specifically, by the CompanyName field. Nesting the SUM function within a FORMATCURRENCY function makes the aggregated revenue easy to read. The SQL statement's closing ORDER BY clause arranges the records so that the company with the largest revenue appears first.
Sub SelectThreeTableJoin()
Dim strSrc As String
Dim strSQL As String
'Compute revenue from each customer and return orders by revenue
strSQL = "SELECT c.CompanyName, " & _
"FORMATCURRENCY(" & _
"SUM(od.[UnitPrice]*od.[Quantity]*(1-od.[Discount])),2) " & _
"AS Revenue " & _
"FROM (Customers c " & _
"INNER JOIN Orders o ON c.CustomerID = o.CustomerID) " & _
"INNER JOIN [Order Details] od " & _
"ON o.OrderID = od.OrderID " & _
"GROUP BY c.CompanyName " & _
"ORDER BY " & _
"SUM(od.[UnitPrice]*od.[Quantity]*(1-od.[Discount])) DESC"
PreviewRecordsetSource strSQL
End Sub
Inner joins merge records from two tables when the records satisfy join criteria, such as having equal values for a designated field. Access permits other kinds of joins as well. For example, you can force all the records from one table into a result set regardless of whether they satisfy a matching criterion. This is called an outer join. You can also merge the records of a table with themselves; SQL calls this a self join. This type of join can be useful when you have two fields in the same table that denote related concepts with the same data type.
| Note |
A type of join not explicitly considered in this book is the cross join. This type of join, which has limited practical applications, merges all the rows in one record source, such as a table, with all the rows in another record source. |
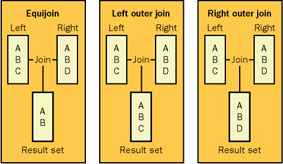
As we've discussed, a join takes place between two record sources. SQL designates these sources as left and right sources depending on their order in the FROM argument list. The first record source is the left source, and the second record source is the right. A right outer join forces all records from the second source into the result set even when no match for them exists in the left source. Entries from the left source can enter the result set only when they satisfy a matching criterion with a record from the right source.
Figure 4-4 contrasts three join types: equijoins, left outer joins, and right outer joins. All three joins in the table join the same left and right tables. The left and right tables have two records with matching join field values: A and B. The left table has a join field value, C, that does not match any join field value in the right table. Similarly, the right table has a join field value, D, that does not match any join field value in the left table. The equijoin generates a result set with just two records having join field values of A and B. The left outer join includes three records in the result set whose join field values are A, B, and C. The right outer join also includes three records in its result set, but the join field values for this result are A, B, and D.
In the SelectRightOuterJoin procedure below, the SQL statement for a right outer join appears as the assignment for the strSQL string. The keywords RIGHT OUTER JOIN denote the type of join. Because the Products table appears to the right of the keywords, it is the right record source. Therefore, the join unconditionally selects each record from the Products table for inclusion in the query's result set. Rows from the Categories table enter the select query's result set only when they match join criteria specified by the ON keyword. In addition, a WHERE clause further filters the result set. The argument for the WHERE clause specifies that records must have a Null CategoryID value in the Products table.
To ensure that there is at least one record from the Products table that doesn't have a matching CategoryID value in the Categories table, the SelectRightOuterJoin procedure adds a record to the Products table by specifying just its ProductName. The procedure uses the recordset AddNew method to accomplish the task. If you work with a freshly installed version of the Northwind database, SelectRightOuterJoin returns just the newly added record when it invokes the PreviewRecordsetSource procedure. After printing the newly added record to the Immediate window with the PreviewRecordsetSource procedure, the sample restores the Products table by deleting the newly added record.
Sub SelectRightOuterJoin()
Dim rst1 As ADODB.Recordset
Dim strSrc As String
Dim strSQL As String
'Create strings for connection (strSrc) and right outer join (strSQL).
'Inclusion of OUTER in RIGHT OUTER JOIN is optional.
'Query returns data on Products rows with a Null CategoryID.
strSrc = "Provider=Microsoft.Jet.OLEDB.4.0;" & _
"Data Source=C:\Program Files\Microsoft Office\" & _
"Office11\Samples\Northwind.mdb"
strSQL = "SELECT c.CategoryName, p.ProductName, " & _
"p.Discontinued " & _
"FROM Categories c RIGHT OUTER JOIN Products p " & _
"ON c.CategoryID = p.CategoryID " & _
"WHERE IsNull(p.CategoryID)"
'Open recordset on Products table in the connection
'that permits adding a record to the recordset
Set rst1 = New ADODB.Recordset
rst1.ActiveConnection = strSrc
rst1.Open "Products", , adOpenKeyset, adLockOptimistic, adCmdTable
'Add a record with a ProductName of foo, but no CategoryID value.
'Close recordset and set to Nothing to flush the change through.
rst1.AddNew
rst1("ProductName") = "foo"
rst1.Update
rst1.Close
Set rst1 = Nothing
'Preview right outer join with newly added record.
PreviewRecordsetSource strSQL
'Reopen the rst1 recordset to find a record
'with a ProductName of foo and delete it.
Set rst1 = New ADODB.Recordset
rst1.ActiveConnection = strSrc
rst1.Open "Products", , adOpenKeyset, adLockOptimistic, adCmdTable
rst1.Find "ProductName = 'foo'"
rst1.Delete
'Clean up objects.
rst1.Close
Set rst1 = Nothing
End Sub
The classic self join sample from the Northwind database finds the managers from the Employees table. This table uses two separate columns to represent two related concepts. First, each employee has a unique EmployeeID value; this is the table's primary key. Second, all employees except one have a ReportsTo column value. This value denotes the EmployeeID for an employee's immediate manager. The top-level manager, Andrew Fuller, does not have a value in the ReportsTo column because he does not report to another employee in the table.
A handy SQL trick when joining a table with itself is to assign the table two different aliases. The SelectSelfJoinForManagers procedure shown next demonstrates the syntax for this. The two aliases for the Employees table are eMgr and eInfo. The procedure's logic uses eMgr to refer to managers found in any employee's ReportsTo column and eInfo to refer to the information for each manager. The arguments for the ON keyword specify the joining of these two tables. The sample seeks to generate a list of managers, so it prefixes the EmployeeID, FirstName, and LastName fields in the Select field list with eInfo because each manager's ID and name are contained in eInfo. (If the sample used the ID and name from eMgr, it would print the information for the employee who reports to that manager.) And because managers can have more than one direct report, we eliminate identical rows using the DISTINCT predicate.
Sub SelectSelfJoinForManagers() Dim strSrc As String Dim strSQL As String 'Select employees whose EmployeeID is in the ReportsTo column strSQL = "SELECT DISTINCT eInfo.EmployeeID, eInfo.FirstName, " & _ "eInfo.LastName " & _ "FROM Employees AS eMgr INNER JOIN Employees AS eInfo " & _ "ON eMgr.ReportsTo = eInfo.EmployeeID" PreviewRecordsetSource strSQL End Sub
The next sample lists orders placed during 1998 that shipped after the required date. The Orders table contains ShippedDate and RequiredDate columns, making it possible to perform the task with a self join. The o1 alias refers to the columns associated with the ShippedDate; the o2 alias designates columns associated with the RequiredDate.
The arguments for the ON keyword include two join criteria. First, the OrderID column value must match between the two aliases. Second, the ShippedDate column value must be greater than (temporally later than) the RequiredDate column value.
The SELECT field list in this instance can use either alias for its prefixes. In addition, you don't need a DISTINCT predicate because the OrderID requirement in the ON argument removes duplicates. Let's take a look at the code now:
Sub SelectSelfJoinForMissed1998Dates() Dim strSrc As String Dim strSQL As String 'Select orders with matching OrderIDs where the ShippedDate 'is later than the RequiredDate in 1998 strSQL = "SELECT o1.OrderID, o1.ShippedDate, " & _ "o2.RequiredDate " & _ "FROM Orders AS o1 " & _ "INNER JOIN Orders AS o2 " & _ "ON (o1.OrderID = o2.OrderID) " & _ "AND (o1.ShippedDate > o2.RequiredDate)" & _ "WHERE Year(o1.OrderDate) = 1998" PreviewRecordsetSource strSQL End Sub
A subquery is a SELECT statement that is nested within another SELECT statement. The nested query is sometimes called an inner query, and the query that surrounds the inner query is sometimes called an outer query. There are two types of subqueries. First, you can express the subquery so that the inner query computes just once for the outer query. SQL terminology uses the term subquery for this scenario. Second, you can write a subquery that computes the inner query for each row in the outer query's result set. SQL terminology refers to this second scenario as a correlated subquery.
Often, you can also express a basic subquery either as an inner join or a self join. These alternative formulations can sometimes lead to faster performance. Explore them when you are working with a record source large enough that performance matters substantially.
Expressing a select query with a subquery can be a more natural approach than creating a join to obtain a result set. The following sample shows a query of the Northwind Employees table that returns all employees who are managers. The query returns the EmployeeID, FirstName, and LastName column values for any employee whose EmployeeID field value is in the ReportsTo column. The inner query computes just once for the outer query in this sample. If you are like me, the subquery formulation will be a more natural approach to finding managers in the table than the SelectSelfJoinForManagers sample query given earlier, which demonstrated a self join. Unless performance issues are substantial, deciding whether to use a subquery or a join might simply be a matter of personal preference.
Sub SelectSubQuery() Dim strSrc As String Dim strSQL As String 'Select employees with another employee reporting to them strSQL = "SELECT DISTINCT EmployeeID, " & _ "FirstName, LastName " & _ "FROM Employees " & _ "WHERE EmployeeID IN (SELECT ReportsTo FROM Employees)" PreviewRecordsetSource strSQL End Sub
This next code sample demonstrates the use of a correlated subquery to find the OrderID with the largest extended price for each ProductID. The outer query specifies the return of OrderID, ProductID, and the following calculated field for computing extended price: UnitPrice*Quantity*(1-Discount). The query displays extended price with a currency format. For each row, the outer query looks in the inner query to see whether there is a match for its calculated field value. The inner query computes the maximum extended price for a ProductID in the Order Details table for rows in which the inner query's ProductID (odsub.ProductID) matches the outer query's ProductID (od.ProductID). The WHERE clause for the inner query causes the code to recompute each row of the outer query.
Sub SelectCorrelatedSubQuery() Dim strSrc As String Dim strSQL As String 'Find OrderIDs with the maximum price for a ProductID strSQL = "SELECT od.OrderID, od.ProductID, " & _ "FORMATCURRENCY(od.UnitPrice*od.Quantity*od.Quantity" & _ "*(1-od.Discount), 2) AS Price " & _ "FROM [Order Details] od " & _ "WHERE od.UnitPrice*od.Quantity*(1-od.Discount) IN " & _ "(SELECT " & _ "MAX(odsub.UnitPrice*odsub.Quantity*(1-odsub.Discount)) " & _ "FROM [Order Details] odsub " & _ "WHERE od.ProductID = odsub.ProductID)" PreviewRecordsetSource strSQL End Sub
All the ways to merge record sources we've discussed so far focused on joining two or more sources on one or more common fields. Think of this as a side-by-side linking of record sources. A union query, on the other hand, merges record sources in a very different way. It stacks one record source on top of another. Fields from different record sources participating in a union query must have matching data types for at least those fields involved in the query. If the data types or the data itself among record sources that you want to combine with a union query do not exactly correspond, you might be able to compute calculated fields that are compatible between record sources. For example, the Customers table has a ContactName column that contains first and last names. The Employees table has two separate columns for first and last names. By creating a calculated field to concatenate the FirstName and LastName columns in the Employees table within the union query, you can merge the Employees table with the Customers table.
The syntax for a union query reflects the design of the record sources that it merges. A union query merges multiple record sources, and it builds its syntax much like a multidecker sandwich. SELECT statements layer between UNION keywords. Each SELECT statement points at one of the record sources for the union query to merge. The field list for the SELECT statements must have matching data types.
The SelectThreeTableUnion procedure merges three record sources from the Northwind database: the Customers, Suppliers, and Employees tables. The field list for the SELECT statements of the Customers and Suppliers tables each include CompanyName, ContactName, and Phone from their record sources. The SELECT statement for the Employees table differs from the Customers and Suppliers tables in several respects. First, it uses a string constant, "Northwind", for the CompanyName field. Second, it creates a calculated field, called ContactName, to match a column from the other two tables. The calculated field combines the FirstName and LastName column values from the Employees table. Third, it uses HomePhone as the field to match Phone in the preceding SELECT statements. Let's take a look at the syntax now:
Sub SelectThreeTableUnion() Dim strSrc As String Dim strSQL As String 'Concatenate Supplier contact info after employees contact info. 'Sorts by default on first column. strSQL = "SELECT CompanyName, ContactName, Phone " & _ "FROM Customers " & _ "UNION " & _ "SELECT CompanyName, ContactName, Phone " & _ "FROM Suppliers " & _ "UNION " & _ "SELECT 'Northwind', " & _ "FirstName & ' ' & LastName AS ContactName, HomePhone " & _ "FROM EMPLOYEES" PreviewRecordsetSource strSQL End Sub
This procedure offers one considerable advantage over working with the three tables independently. It provides a common interface for all the contact information for customers, suppliers, and employees. But the procedure has at least two weaknesses. First, it does not specify the source for a contact. Second, it sorts records by default order according to the first column. However, your application might require a different sort (for example, sorting by ContactName values instead of CompanyName values). The SelectSortedUnion procedure shows how easy it is to adapt the union query to meet these requirements:
Sub SelectSortedUnion() Dim strSrc As String Dim strSQL As String 'A single ORDER BY clause for the last SELECT can 'apply to all preceding SELECT statements in the UNION. 'You can add columns (like Source in this example) inside 'UNION queries. strSQL = "SELECT CompanyName, ContactName, Phone, " & _ "'Customers' AS Source " & _ "FROM Customers " & _ "UNION " & _ "SELECT CompanyName, ContactName, Phone, " & _ "'Suppliers' AS Source " & _ "FROM Suppliers " & _ "UNION " & _ "SELECT 'Northwind' AS CompanyName, " & _ "FirstName & ' ' & LastName AS ContactName, HomePhone, " & _ "'Employees' AS Source " & _ "FROM EMPLOYEES " & _ "ORDER BY ContactName" PreviewRecordsetSource strSQL End Sub
Figure 4-5 shows an excerpt from the SelectSortedUnion procedure's output. Notice that the output contains four fields for each record; one of these denotes the source for a record. The first five records come from the Customers table, but the sixth record comes from the Employees table. Also, the records sort according to ContactName—not CompanyName, which is the default. The sort order reflects the ORDER BY clause at the end of the SelectSortedUnion procedure.