This section orients you to some of the table design issues you can expect to encounter as you move from Access database files to SQL Server files. The presentation pays particular attention to the SQL Server data types. It also introduces you to the CREATE TABLE statement so that you can design your own custom tables programmatically. A pair of code samples demonstrates how to use one or more INSERT statements after a CREATE TABLE statement to populate a new table with values. These samples demonstrate techniques for working with contact data and graphic images in SQL Server databases. The section concludes with a brief introduction to database diagrams. The examples you'll see convey the simplicity and power of this graphical data definition tool.
Because the basics of designing a database are similar in Access and SQL Server, experienced Access developers will easily grasp the basics of designing SQL Server solutions. However, the data type names for table columns vary substantially in these two applications. In some cases, the same names point to different data types. In other cases, data types available in SQL Server are missing in Access. There's even one Access data type that's missing in SQL Server.
As Access developers migrate to SQL Server, specifying the right data type grows in importance. This is because SQL Server tables often have many more rows than Access tables. In fact, expanding tables are a big motivation for moving from an Access database solution to one based on SQL Server. Therefore, as you design your SQL database, specifying the column data type so that it is the smallest size possible can dramatically improve performance. Make your data types just large enough to hold the largest value possible for a column. If your numbers do not have fractional values, use one of the data types for whole numbers. Look for opportunities to take advantage of the Smalldatetime and Smallmoney data types if a column's values fall within their ranges. These data types require 4 bytes less per column value than their siblings, Datetime and Money. When working with character data, use a fixed-length data type if all column values are the same length. This saves SQL Server from having to look for the end of the string.
Table 11-3 summarizes the SQL Server data types along with the closest matching Access data types. When a SQL Server data type is missing from Access, the corresponding Access data type column reads "Not applicable."
The Access data type for table columns that's missing from SQL Server is the Hyperlink data type. Recall that this data type permits you to link to different parts of the same or a different Office document as well as Web pages. The Hyperlink data type is a text string comprised of up to four separate components: the link's display, main URL address, subaddress, and appearance when a mouse moves over it. Access projects enable the functions for this data type through form fields.
The visual Table Designer in Access 2003 offers a Lookup tab in Table Design view. Although Access project files do not offer an explicit Lookup data type like Access database files do, Access projects provide a Lookup tab. You can use this tab to set the parameters for a lookup field. This graphical process mirrors the settings you make for a combo box but causes the table to display the lookup value. Any forms you base on the table will show the lookup value and can offer a drop-down list for changing existing values as well as inputting new ones.
| Note |
The sample files for this chapter include the Orders_with_lookup table, which demonstrates one way to make the lookup column settings. You can show Help for the Lookup tab in the visual Table Designer by resting your cursor in the Display Control box and pressing F1. |
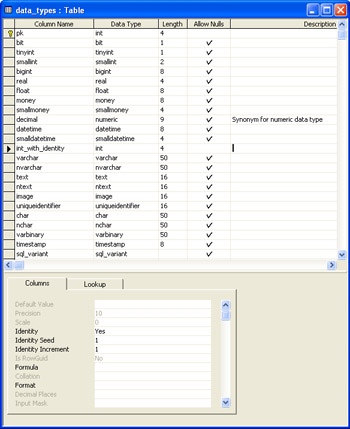
When you first work with SQL Server, the easiest way to start creating table columns is with the visual Table Designer. Even experienced developers frequently use a designer to create tables. You can invoke the Access 2003 Table Designer from the Database window. Just select Tables from the Objects bar and then click New. Figure 11-10 shows a table in the designer with a column named after each of the SQL Server column data types. I constructed this table by typing data type names into the Column Name column. You can populate the Data Type column by making a selection from its drop-down list. I chose the data type corresponding to the entry to the Column Name column. The only SQL Server column data type the table fails to include is the Numeric data type, which is synonymous with the Decimal data type.
The specification for the data_types table shown in Figure 11-10 accepts the defaults for Length and Allow Nulls settings, with two exceptions. The first exception is the pk column. This column does not allow nulls. You can make a column the primary key (as you can with the pk column) by clicking the Primary Key button with the cursor resting on the row containing the column specification. The second exception is the column named int_with_identity. This column also does not accept nulls. Figure 11-10 shows the cursor resting on the row containing the specification for this column. As a result, the Columns tab offers additional column properties. In this case, you see the Identity setting equals Yes, and the default values of 1 for both the Identity Seed and Identity Increment settings. You can override these defaults by entering new values for the settings.
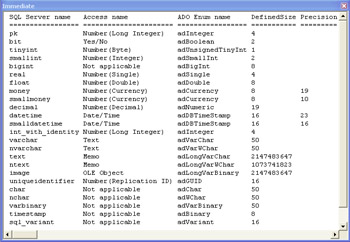
Mapping between data types for different data stores can help you understand when to use which data type in which context. This kind of information is critical when migrating data from one database to another. The following code sample takes each of the columns in the data_types table shown in Figure 11-10 and prints their SQL Server, Access, and ADO data type names, as well as their defined size. The Access and ADO data type names and the DefinedSize property uniquely distinguish most SQL Server data types. However, the SQL Server Money, Smallmoney, Datetime, and Smalldatetime data types require you to provide more information to distinguish them. Although the SQL Server Datetime and Smalldatetime data types have identical ADO DefinedSize settings, their Precision properties are different. This is because Datetime column values have more precision that Smalldatetime column values.
The following three procedures map the SQL Server data types in the data_types table to their Access data type names and ADO enum names. The report also prints the DefinedSize property for each column in the table. In the case of the Money, Smallmoney, Datetime, and Smalldatetime data types, the report also includes the precision of the columns. This helps to differentiate between data types that are otherwise identical in the report's other columns.
The main routine, ReportDataTypes, starts by printing a heading and setting it off with a line of equal signs below the report's column headings. Next, it opens a recordset for the data_types table. Then it loops through all the fields in the recordset. Within the loop, an If…Then…Else statement directs the reporting to one of two Debug.Print statements. The Then clause prints results for the two sets of fields that require Precision to distinguish between them. The Else clause processes all the remaining data types. The two other procedures are function procedures that return the name of the Access data type and the enum name for the ADO data type value corresponding to the SQL Server data type. ADO automatically maps the SQL Server data types into its own data types to create a field Type property value.
Sub ReportDataTypes() Dim rst1 As ADODB.Recordset Dim fld1 As ADODB.Field 'Print and separate column headings from the rest 'of the report Debug.Print "SQL Server name" & String(3, " ") & _ "Access name" & String(12, " ") & _ "ADO Enum name" & String(5, " ") & _ "DefinedSize" & " " & "Precision" Debug.Print String(17, "=") & " " & String(22, "=") & " " & _ String(17, "=") & " " & String(11, "=") & " " & _ String(9, "=") 'Base a recordset on the data_types table Set rst1 = New ADODB.Recordset rst1.Open "data_types", CurrentProject.Connection 'Loop through the columns in the data_types table and 'report their name, Access data type, ADO data type, 'DefinedSize, and Precision, if appropriate For Each fld1 In rst1.Fields If (fld1.Type = adCurrency Or _ fld1.Type = adDBTimeStamp) Then Debug.Print fld1.Name & _ String(18 - Len(fld1.Name), " ") & _ AccessDataTypeName(fld1.Type) & _ String(23 - Len(AccessDataTypeName(fld1.Type)), " ") & _ ADODataTypeName(fld1.Type) & _ String(18 - Len(ADODataTypeName(fld1.Type)), " ") & _ fld1.DefinedSize, fld1.Precision Else Debug.Print fld1.Name & _ String(18 - Len(fld1.Name), " ") & _ AccessDataTypeName(fld1.Type) & _ String(23 - Len(AccessDataTypeName(fld1.Type)), " ") & _ ADODataTypeName(fld1.Type) & _ String(18 - Len(ADODataTypeName(fld1.Type)), " ") & _ fld1.DefinedSize End If Next fld1 'Clean up objects rst1.Close Set rst1 = Nothing End Sub Function AccessDataTypeName(DataTypeEnum As Integer) As String 'Decodes SQL Server data type to Access data type 'based on the ADO enum value for the data type Select Case DataTypeEnum Case 2 AccessDataTypeName = "Number(Integer)" Case 3 AccessDataTypeName = "Number(Long Integer)" Case 4 AccessDataTypeName = "Number(Single)" Case 5 AccessDataTypeName = "Number(Double)" Case 6 AccessDataTypeName = "Number(Currency)" Case 11 AccessDataTypeName = "Yes/No" Case 12 AccessDataTypeName = "Not applicable" Case 17 AccessDataTypeName = "Number(Byte)" Case 20 AccessDataTypeName = "Not applicable" Case 72 AccessDataTypeName = "Number(Replication ID)" Case 128 AccessDataTypeName = "Not applicable" Case 129 AccessDataTypeName = "Not applicable" Case 130 AccessDataTypeName = "Not applicable" Case 131 AccessDataTypeName = "Number(Decimal)" Case 135 AccessDataTypeName = "Date/Time" Case 200 AccessDataTypeName = "Text" Case 201 AccessDataTypeName = "Memo" Case 202 AccessDataTypeName = "Text" Case 203 AccessDataTypeName = "Memo" Case 204 AccessDataTypeName = "Not applicable" Case 205 AccessDataTypeName = "OLE Object" Case Else AccessDataTypeName = "Data Type Not Decoded" End Select End Function Function ADODataTypeName(DataTypeEnum As Integer) As String 'Decodes SQL Server data type to ADO data type 'based on the ADO enum value for the data type Select Case DataTypeEnum Case 2 ADODataTypeName = "adSmallInt" Case 3 ADODataTypeName = "adInteger" Case 4 ADODataTypeName = "adSingle" Case 5 ADODataTypeName = "adDouble" Case 6 ADODataTypeName = "adCurrency" Case 11 ADODataTypeName = "adBoolean" Case 12 ADODataTypeName = "adVariant" Case 17 ADODataTypeName = "adUnsignedTinyInt" Case 20 ADODataTypeName = "adBigInt" Case 72 ADODataTypeName = "adGUID" Case 128 ADODataTypeName = "adBinary" Case 129 ADODataTypeName = "adChar" Case 130 ADODataTypeName = "adWChar" Case 131 ADODataTypeName = "adNumeric" Case 135 ADODataTypeName = "adDBTimeStamp" Case 200 ADODataTypeName = "adVarChar" Case 201 ADODataTypeName = "adLongVarChar" Case 202 ADODataTypeName = "adVarWChar" Case 203 ADODataTypeName = "adLongVarWChar" Case 204 ADODataTypeName = "adVarBinary" Case 205 ADODataTypeName = "adLongVarBinary" Case Else ADODataTypeName = "Data Type Not Decoded" End Select End Function
Figure 11-11 shows the output from the ReportDataTypes procedure. It includes a row for each column in the data_types table. You can use this printout as a convenient mapping tool for naming data types. The DefinedSize property values are the default settings for the data types when the number of bytes used to store an entry varies according to each entry's content, as it does for Nvarchar and Nchar. As you can see, the Money and Smallmoney SQL Server data types have the same ADO enum name, adCurrency. They differ only in their Precision property. The same pattern holds for Datetime and Smalldatetime. In addition, the SQL Server Datetime and Smalldatetime data types translate into the same ADO enum name, adDBTimeStamp. However, neither data type is related to the SQL Server Timestamp data type, which is a binary value.
One typical application for column data types is to create the columns in a table. To create a table, use the T-SQL CREATE TABLE statement. This statement lets you specify the table name and then declare each of the columns within the table. You must specify a data type for each table column. You can optionally specify various constraints, such as one for a table's primary key. Although SQL Server doesn't require a primary key, you should always declare one when migrating to SQL Server from Access because SQL Server doesn't allow manual input to tables without a primary key. Another special feature of primary keys in SQL Server is that they can be clustered. A clustered primary key orders the records on a storage device according to the primary key values. A clustered index can dramatically improve sort and search activities for a clustered key versus columns without a clustered primary key or index. Primary keys are unclustered unless you explicitly declare them as clustered.
After you create a table, you probably will want to populate it with values. You can do this programmatically with the INSERT statement. This statement lets you populate all or a subset of the fields in a target table. You can specify the column values for each new row with a new INSERT statement. The source of the records can be individual values, another SQL Server table in the same or a different database, or data based on a legacy Access database file.
The next sample demonstrates the correct syntax for the CREATE TABLE and INSERT statements. Before using these statements, the sample removes any table, if one exists, that has the same name as the table it's about to create in a database. The sample demonstrates the use of an InformationSchema view to determine whether a prior version of a table exists. You can use the system-defined sysobjects table to determine whether a table or other database object exists already, but Microsoft recommends using InformationSchema views instead. Using InformationSchema views enables your applications to work properly, even if Microsoft changes the design of system-defined tables such as sysobjects.
The MyExtensions table name and the EmployeeID, FirstName, LastName, and Extension column names are hardcoded in the sample. Hardcoding is more typical when working with a table's design than with other coding tasks. This is because your application is likely to have custom requirements. However, if you plan to use one procedure to create many tables with the same basic design, it's trivial to generalize the procedure. Again, what to leave fixed and what to make variable will depend on the requirements of your custom applications.
After setting a Connection object for the current project, the CreateMyExtensions procedure features three main sections. Each of these sections demonstrates the use of T-SQL code to perform an independent task for creating and populating the MyExtensions table. The procedure repeatedly invokes the Execute method of the Connection object to run each of the sample's T-SQL code segments.
The first T-SQL segment uses an IF statement with an EXISTS keyword. This keyword permits the IF statement to conditionally execute a DROP TABLE statement if a prior version of the table exists. The sample uses an InformationSchema view to detect whether a table already exists in the database. If the table exists, the application simply drops the old version of it. In a production environment with critical operations or financial data, you might want to archive the table's data before dropping it. I'll illustrate a data archiving strategy later in the chapter in the "Triggers" section.
The second code segment invokes the CREATE TABLE statement to create the MyExtensions table. Because the column serves as the primary key, its declaration explicitly excludes nulls. In addition, the EmployeeID declaration includes an IDENTITY setting with a default value of 1 for its seed and 1 for its increment. The other three table columns permit nulls.
The third code segment invokes the INSERT statement three times. The first two instances of the statement populate all three nonidentity columns. SQL Server automatically populates the identity column value based on the last identity column value and the incremental value for the IDENTITY setting. Because the first two invocations of the INSERT statement specify values for all three nonidentity columns, the INSERT statements do not require a field list before the VALUES keyword. (This list indicates the fields for which the VALUES keyword designates values.) However, the third instance of the INSERT statement specifies only the LastName and Extension column values. Therefore, this instance of INSERT requires a field list before the VALUES keyword.
The procedure closes by invoking the RefreshDatabaseWindow method. This method refreshes the Database window so that the user can immediately see the newly added table. If the procedure did not include this method, the user might not see the new table in the Database window.
Sub CreateMyExtensions() Dim str1 As String Dim cnn1 As ADODB.Connection 'Point a Connection object at the current project Set cnn1 = CurrentProject.Connection 'Delete the MyExtensions table if it exists already str1 = "IF EXISTS(SELECT TABLE_NAME " & _ "FROM INFORMATION_SCHEMA.TABLES " & _ "WHERE TABLE_NAME = 'MyExtensions') " & _ "DROP TABLE MyExtensions" cnn1.Execute str1 'Create the MyExtensions table with an unclustered primary key str1 = "CREATE TABLE MyExtensions " & _ "( " & _ "EmployeeID int IDENTITY(1,1) NOT NULL PRIMARY KEY, " & _ "FirstName nvarchar(10) NULL, " & _ "LastName nvarchar(20) NULL, " & _ "Extension nvarchar(4) NULL " & _ ")" cnn1.Execute str1 'Populate the MyExtensions table with data; populate one record 'with a subset of the input fields str1 = "INSERT INTO MyExtensions Values('Rick', 'Dobson', '8629')" & _ "INSERT INTO MyExtensions Values('Virginia', 'Dobson', '9294')" & _ "INSERT INTO MyExtensions (LastName, Extension) Values('Hill','3743')" cnn1.Execute str1 'Refresh Database window to show new table RefreshDatabaseWindow End Sub
The next sample uses a nearly identical approach to create and populate a table of picture descriptions and file addresses for picture images. You can use this kind of table to display photographs, diagrams, or any graphically formatted file. By storing the file address instead of the image, you speed up the image retrieval time and shorten the image processing time. In Chapter 12, you'll see a sample that illustrates how to use this kind of table to populate controls on a form that contain photos.
The sample table in this next application is structurally unique from the one in the preceding sample because it uses a clustered primary key. Access database files do not support this kind of primary key. Recall that when an application specifies this type of primary key, SQL Server orders the records on the storage medium according to their primary key values. Each table can have just one clustered index, and it doesn't have to be the primary key. Because a clustered index substantially expedites record retrieval, you should reserve the clustered index setting for the key that users are most likely to work with.
The following code sample contains the same three main phases as the preceding sample, but the column names are different. In addition, this sample conditionally drops any prior version of the table by calling a sub procedure. Although table designs and data tend to be unique from one table to the next, the process of dropping a table doesn't vary much. Therefore, the main procedure calls the Drop_a_table procedure by passing a connection argument and a string representing the table name.
When working with image files, it's common to store them with the operating system and store only their locations in the database. You can maintain the security of your image files by placing them on a read-only file share. This allows users to query the table, but prevents them from adding, updating, and deleting image files. Some images are included with this chapter's sample materials so that you can experiment with displaying them. See Chapter 12 for a code sample that demonstrates how to display the images from an Access form.
Sub CreatPic_Addresses() Dim str1 As String Dim cnn1 As ADODB.Connection Dim TableName As String 'Point a connection object at the current project Set cnn1 = CurrentProject.Connection 'Delete the Pic_Addresses table if it exists already TableName = "Pic_Addresses" Drop_a_table cnn1, TableName 'Create the Pic_Addresses table with a clustered primary key str1 = "CREATE TABLE " & TableName & " " & _ "( " & _ "PictureID int IDENTITY NOT NULL PRIMARY KEY CLUSTERED, " & _ "Pic_description nvarchar(50), " & _ "Pic_address nvarchar(256) " & _ ") " cnn1.Execute str1 'Insert descriptions and addresses for four pictures str1 = "INSERT INTO " & TableName & " " & _ "Values('Rick munches glasses', " & _ "'C:\Access11Files\Picture1.jpg')" & _ "INSERT INTO Pic_Addresses " & _ "Values('Rick not working at computer', " & _ "'C:\Access11Files\Picture2.jpg')" & _ "INSERT INTO Pic_Addresses " & _ "Values('Rick finally working at computer', " & _ "'C:\Access11Files\Picture3.jpg')" & _ "INSERT INTO Pic_Addresses " & _ "Values('Rick gets reward for working', " & _ "'C:\Access11Files\Picture4.jpg')" cnn1.Execute str1 'Refresh Database window to show new table RefreshDatabaseWindow End Sub Sub Drop_a_table(cnn1 As ADODB.Connection, TableName As String) Dim str1 As String 'Delete the table if it exists already str1 = "IF EXISTS (SELECT TABLE_NAME " & _ "FROM INFORMATION_SCHEMA.TABLES " & _ "WHERE TABLE_NAME = '" & TableName & "') " & _ "DROP TABLE " & TableName cnn1.Execute str1 End Sub