Hack 28. Separate Alphabetically Sorted Records into Letter Groups
Tap the Prefix Characters property to gain new layout possibilities. Sorting alphabetically is nothing new; in fact, it's rather oldone of the standard practices we take for granted. When you've got dozens or hundreds of printed records, though, it can be tedious to flip through report pages looking for a particular line item, even though they're in alphabetical order. A neat thing to do is to segregate the records on a report alphabetically. Figure 4-1 shows a page from a report in which sorted records list repeatedly with no such segregation or break. The records are sortedno question on that scorebut the layout makes it challenging to flip to the approximate area you need to find. Figure 4-1. A report with a repetitive layout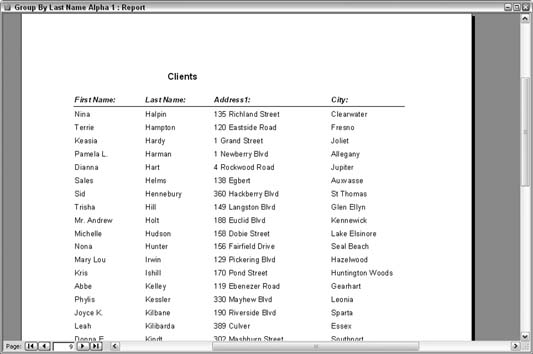
The report's design is straightforward. The details section contains the fields that become the line items. The report in this format doesn't use groups, and that is why it is monotonous to look at. Figure 4-2 shows the design of the report. 4.2.1. Segregating by LetterA way to break up the endless line-item listing is to add a group to the report. Figure 4-3 shows how the report's design has been altered to include a group. The group is based on the ClientLastName field, which, of course, is the field being sorted on. Here are a few key points about how this group is being used: Figure 4-2. A report that doesn't use grouping and sorting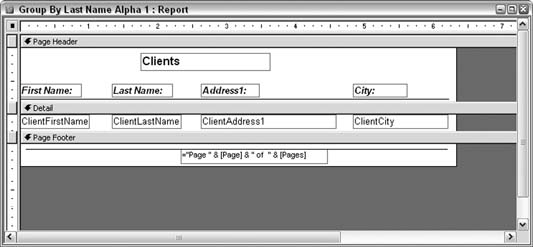
Figure 4-3. A report that uses grouping and sorting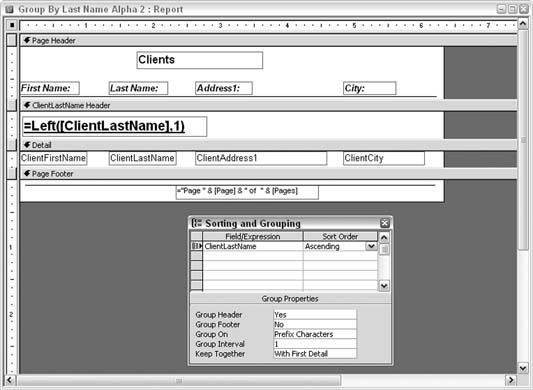
When the report runs, the expression in the unbound text box forces the group break to occur on the letters of the alphabet, instead of on each occurrence of a last name. As a result, all the As are together, all the Bs are together, and so on. You accomplish this by using the Left function to return the first letter: =Left([ClientLastName],1) Figure 4-4 shows how the report segregates by letter. Figure 4-4. Clients broken out by first letter
The larger font, bold, and underline settings make the distinctions visually clear when thumbing through a report. 4.2.2. Hacking the HackNote that on the report page shown in Figure 4-4, none of the clients' last names start with the letter J. The fact that some records don't exist could be vital news to someone. I can just hear the boss yelling, "What happened to the Johnson account?" Such a reaction is based on expecting to see something that isn't there. The flip side to this is that missing records might be identified only by pointing out that no records have met a condition. In particular, it would be useful if the report stated that no records were found for the letter J. We need a way to still display the alphabetic letter on the report, but in the current design, this won't ever happen. Any alphabetic letters that currently appear on the report are there because records in which the last name starts with the letter J do exist. To get all letters to appear on the report, regardless of whether records beginning with those letters exist, include somewhere in the design a list of all the letters to be compared against. The approach used here is to relate the client table with a table of the letters, instead of basing the report on just the client table. A table is added to the database with just one field: Letter. The table contains 26 records, for the letters A through Z. Figure 4-5 shows the table, named tblLetters. Figure 4-5. A table filled with letters of the alphabet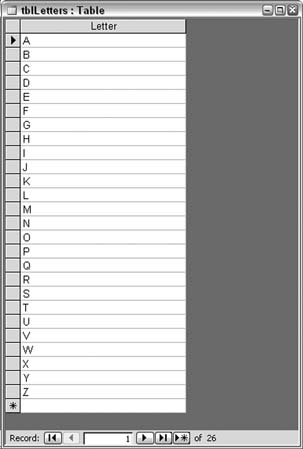
It's not a bad idea to include the digits 09 in the table as well, especially if you're working with the names of companies. The report's Record Source property was previously set to the client table (tblClients). Now, though, the report's record source will be based on a query. Here is the SQL statement: SELECT tblClients.ClientFirstName, tblClients.ClientLastName, tblClients.ClientAddress1, tblClients.ClientCity, tblLetters.Letter FROM tblClients RIGHT JOIN tblLetters ON left(tblClients.ClientLastName,1) = tblLetters.Letter; A key point about this statement is that a RIGHT JOIN is used to relate the tables. This ensures that all records from the letters table (tblLetters) will be present. In other words, every letter will be available to the report, even when no last names start with that letter. The report's design also needs a slight change. The group is no longer based on the last name; instead, it's based on the Letter field. Also, a new expression is used in the unbound text box. Figure 4-6 shows these changes. Figure 4-6. Grouping on the alphabet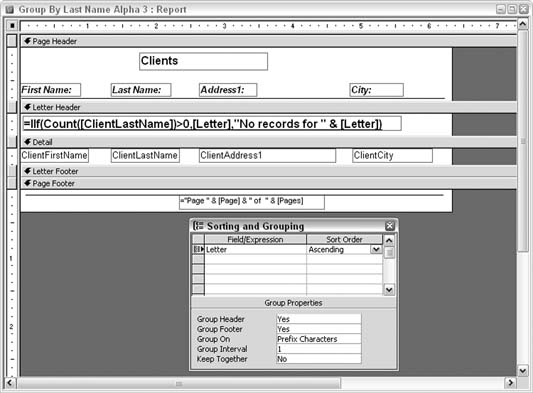
The expression in the text box returns one of two possible statements. When at least one record contains a last name starting with a given letter, the letter is displayed. When no records contain a last name starting with the given letter, a message is displayed that no records were found for that letter. You accomplish this using the IIF and Count functions: =IIf(Count([ClientLastName])>0,[Letter],"No records for " & [Letter]) As a result, this report has all the alphabetical letters as group headers, regardless of whether any records match, as shown in Figure 4-7. Figure 4-7. Reporting that no records exist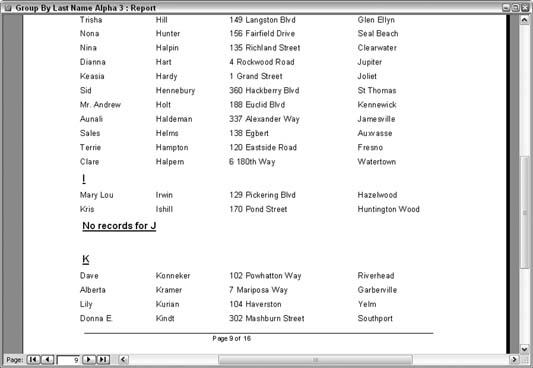
You can adapt this hack in a number of ways. For example, you can hide the details section, and you can alter the expression in the header to print a line only when no records exist. This alters the report to list exceptions only. |