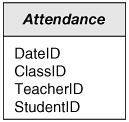
The Characteristics of a Fact AttributeIn addition to dimension keys, fact tables contain fact attributes. (There is one exception to this rule; we'll examine it later in this chapter.) An ideal fact should have two characteristics: It should be both numeric and fully additive. Remember that dimensional databases are used for analysis. As a result, users will rarely be examining rows in the fact table individually. If a fact is not numericif it is a date or a text field, for exampleit becomes more difficult to combine records. Non-numeric attributes can be counted or listed, but they cannot be totaled or averaged. For example, it's possible to determine the total number of blue size 13 widgets sold on the 1st of October by simply returning the SQL Sum of the Quantity fact. But if the value returned were CustomerName, you could only reasonably return a count: 325 customers placed orders on the 1st of October. In theory, you could return a list of all 325 of them, but since in a non-trivial application the number returned could just as easily be 325,000 or even 325,000,000, lists of facts are not likely to be useful. Textual facts are an example of non-additive factsthe values cannot be added together. Obviously, non-numeric attributes are, by definition, also non-additive. This doesn't mean that they should never be included in fact tables, but it does mean that you should do so with caution. Before you add a non-additive attribute to a fact table, be very sure that you can't more effectively treat it as a dimension. I've never run across a non-additive numeric fact, but I'm not prepared to say they don't exist. (I've been in this business too long to make that particular mistake!) It's not at all unusual, however, for numeric facts to be semi-additive. A semi-additive fact is additive across some, but not all, dimensions. The classic example of a semi-additive fact is a daily account balance. It's perfectly legitimate to add the balances of every account on a specific daythe fact is additive across the Account dimensionbut the end-of-month balance of my savings account is not (unfortunately) the sum of the balances for the past monththe fact is non-additive across the dimension of time. Semi-additive facts are less likely to be dimensions in disguise than non-additive facts, but they're not without problems. They don't impose any particular constraints on the schema design of database implementation, but the front end should warn the user who tries to perform operations that require summarizing data across a semi-additive dimension. One of the things we haven't yet discussed about dimensional databases is that, unlike normalized databases, their structures are always remarkably similar. The number of dimensions and the facts and attributes vary, of course, but the overall structure is always a single fact table surrounded by its dimensions. This makes it possible to build generic front ends to dimensional databases. Of course, it's possible to build generic front ends to normalized databases as well; Microsoft Access is one. What I mean to say is that it's possible to build generic front ends to dimensional databases that are far less complicated for end users. The Analysis Manager that is part of SQL Server Analysis Services is a good example. The problem here, of course, is that while it's possible for the front end to predict the general structure of the database in advance and to determine the specific schema at runtime, it isn't possible for the front end (or anyone or anything else, for that matter) to determine whether a numeric fact is semi- or fully additive by inspection. This information must be stored as meta-data. The growth of XML notwithstanding, meta-data formats remain largely proprietary. What this means, ultimately, is that if you include semi-additive facts in a dimensional database, you should ideally use a customer front end that can read the meta-data and warn users if they attempt to summarize across a semi-additive dimension. You should also warn users that if they use a third-party front end (and there's no particular reason to prevent them from doing so) they're on their own in this regard. Notice, by the way, that I said your front end should warn the user about summarizing data across a non-additive dimension. I didn't say "prevent." If someone wants to divide the sum of the daily balances for the month of January 1953 by the inches of rain in Tashkent, Uzbekistan in March 2003, you can only assume the person has a perfectly rational reason for doing so. The results might not make much sense, of course, and it's okay to point that out. It's not okay for the front end to prevent somebody doing it. After all, for many years the strongest indicator for the trend of the U.S. stock market was the length of women's skirts. No, that doesn't make sense. Yes, it was a fact. Might still be, for all I know. GrainThe facts about an organization's operations can be measured at many levels of detail. At the lowest level of a sales organization, for example, is the individual line item on a sales order. At the highest level is the net operating profit of the organization as a whole. All of the facts in a fact table must be at the same level of detail, known as the fact table's grain. As a general rule, you should build the fact table at the lowest level of detail for which data is available. For the majority of organizations, this will be at the level of an individual transaction: the line item of a sales order or an individual deposit into or withdrawal from an accountwhatever is the smallest action for which information is available. The reason for this is probably obvious: You can always summarize data, but it's almost impossible to go the other direction and allocate already summarized data into more discrete units. Retail operations are a good example of the problem. Until quite recently, most point-of-sale systems sent summary data to head office after the close of business each day: "We sold 16 green widgets, 36 blue widgets, 42 large gadgets, and 1 partridge in a pear tree." This is useful information, as far as it goes, but it doesn't really go far enough. If the only sales information available is by-product-by-day, you can't perform what's generally called "market basket analysis"answering questions like "how many of the people who bought milk also bought bread?", which is terribly important to marketing types. Incidentally, the answer to that particular question is the reason your local grocery store places milk and bread as far apart as it's physically possible to get them. Since most people who buy one also buy the other, the store separates them so that you'll walk past as many other items as possible. The theory being that the more you see, the more likely you are to make an impulse purchase. (And honestly, grocery shopping was much more fun before I did those projects for one of Australia's largest grocery chains.) But back to the subject. The principle is that the greater the detail, the more ways it can be analyzed, and thus the more useful it is. But that said, you can only capture detail that exists somewhere. In our example, the information required for market basket analysis simply isn't possibleunfortunate, but not negotiable. This may seem obvious to the point of banality, but if you do enough of this, I can almost guarantee that at some point some Marketing exec for whom it's not obvious is going to hold you personally responsible. Grain can also become an issue when you're drawing facts from multiple systems, a common situation. Say, for example, that you're building a fact table at the grain of the individual order line item, and that the item selling price and order discount are available from the order entry system. So far so good, but wouldn't it be useful to include the cost of each item, so that analysts can perform net profit calculations? Great idea, but take my word for it: You will never be able to obtain a complete picture of costs at the item level. After all, a complete picture would have to include things like the CEO's expense account, and even if that information were available, it would be all but impossible to allocate it sensibly. Given that a complete picture is impossible, you'll have to decide (in conjunction with your end users, of course) on a reasonable picture. Most sales organizations have some method of determining Cost of Goods Sold (COGS) for accounting purposes, and that's a good place to start. But you'll probably find that COGS is calculated at the order level, and it won't be acceptable to simply allocate the costs by dividing total COGS by the number of items. Sometimes you get lucky, of course. I once worked with an organization that calculated COGS as 50 percent of the sale price. They weren't in business long, but it was pleasant relief to build simple (sloppy) systems for them. You'll probably also find that the end users want to include (and allocate) costs beyond those included in COGSshipping and advertising costs, for example. As an analyst, you must be very clear about your position: In order for a fact to be included in the dimensional database, the formula for allocating it at the necessary grain must be agreed upon by all interested parties. If it can't be agreed upon, it can't be included. End of discussion. I recommend that you stay as far away as possible from the allocation discussions. I find it truly astonishing how emotional people get over these things. I was actually present at a meeting during which the VP of Sales threatened to throw the VP of Marketing out a 15th floor window over how to amortize the cost of an advertising campaign over time. (It was the only time in my career that a coffee break became a matter of self-defense.) Fortunately, the arguments don't often go to such ridiculous extremes, but do be prepared for the occasional, shall we say, "heated discussion"? Once the users have agreed on an allocation formula (or thrown the fact out on the basis of intractability), it's important that the formula be fully documented, either in meta-data or (preferably) as an attribute of the relevant dimension. This is particularly true if you're working with multiple data marts. Remember that I define a data mart as a single dimension database, and that it's common for multiple dimensional databases to be used together. For this to work, the same allocation formulas must be applied throughout, and that's only going to happen if they're documented within the data marts themselves. Types of Fact TablesSo far we've concentrated on the most common type of fact table, one that models a transaction. Generically, we'll call this structure a transaction table. But there are a few other important types of which you should be aware. Earlier I mentioned daily account balances as an example of semi-additive facts. Facts that represent balances are almost always part of the second important type of fact table: a snapshot table. Snapshot tables represent, as you might expect, periodic snapshots of the state of the organization. This type of table is used whenever you are measuring a single value that varies over time. In addition to account balances, you would use a snapshot table to measure, for example, inventory levels, stock selling prices, student enrollments, even the temperature of a room. Notice that some, but not all, of these facts are affected by transactionsinventory levels are, temperatures are not. When they are, it is customary for the data warehouse to include both a snapshot table and a transaction table. You could, of course, calculate the balance based on a starting balance and recorded transactions; this is what accounting systems do. Maintaining balance snapshots uses storage, potentially quite a lot of it, but calculating can be a complicated and time-consuming process, requiring hundredspotentially millionsof individual operations. Remember, storage is cheap; time is expensive. A special type of transaction/snapshot pair is used to model accrual operations such as magazines, insurance, the operations of a cable television, or certain types of financial transactions such as loans. It is customary for these businesses to receive payment for their services in advance, but they don't actually accrue the revenue until the month the service (or product) is rendered. So, for example, if I subscribe to a magazine, 12 issues for $24.00, the publishing company receives $24.00 of revenue when I subscribe, but can only book $2.00 of income as they send me each issue. Until that time, the subscription revenue is accounted as a liability, not an asset. (Isn't that fun? No, I don't think so either.) In situations like this, you really don't want to try to perform income calculations at runtime. Even if you're working with a comparatively small number of rows in the dataset, the calculations require date arithmetic, which is notoriously slow and error-prone. And if you're working with an international company, things can get positively scary. If the client is in California, but the home office is in New South Wales, Australia, on the far side of the International Date Line, is the income accrued on the first of the month in California or in New South Wales (the previous day)? Better by far to let the Accounting department deal with this stuff. It is, after all, their job. In addition to snapshot and transaction tables, there is one final type of fact table that you're likely to run across: the coverage table. Sometimes the mere existence of a row with a particular set of dimension identifiers tells you everything you need to know, or even everything you can knowthere simply are no other facts. Coverage tables, sometimes called "factless fact tables," are most often used to indicate that something occurred. The various dimension identifiers fully define the event, and the existence of the row is sufficient to indicate that the event occurred. For example, the fact table shown in Figure 7-2 could be used to model class attendance. Figure 7-2. A Coverage Table that Models Class Attendance
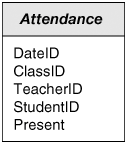
Some analysts add an additional Boolean fact, always True, to the canonical structure, as shown in Figure 7-3. The theory here is that the fact makes the table easier for users to understand and manipulate. Figure 7-3. A Coverage Table with an Artificial Boolean Fact
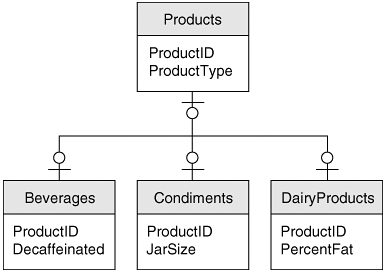
Personally I'm not a great fan of the practice. In the first place, a Boolean is neither numeric nor fully additive. In fact, it's not additive at all, which makes it a fairly ugly fact. In the second place, the existence of a True value implies that a value of False is possible, which is not the case. Remember that fact tables are always sparse. You should never add a row to indicate that something didn't happen. It's like trying to prove a negative proposition, and that way lies madness. The judgment is, admittedly, subjective and somewhat aesthetic, however. Best practice is probably to check with your end users. After all, what's important is that the schema make sense to them, not to you. But I'll warn you, you may find it somewhat difficult to explain the issue. Heterogeneous FactsIn Chapter 3, we talked about sub-classing entities in a normalized database as a method for modeling entities that must be handled both generically and as distinct types. The same issue arises in dimensional databases, of course, and the solution is similar, but not precisely the same. By convention, in dimensional database design these are referred to as heterogeneous facts. Figure 7-4, adapted from our example in Chapter 3, shows the general approach in a normalized database. The Products entity contains all of the attributes common to every product, while the individual product type entitiesBeverages, Condiments, and so forthcontain the attributes specific to that type. Including a ProductType attribute at the Product level makes it a fairly simple matter to treat any specific record, or group of records, as either a generic Product or an instance of a specific class. Figure 7-4. A Sub-Classed Entity from a Normalized Database
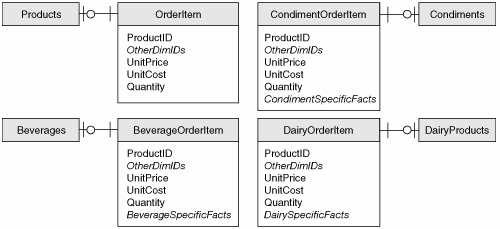
The applications supported by normalized databases often treat entities at both levels simultaneously in this way. A product detail screen, for example, would need to display generic and category-specific fields for each record in the Products table. This requirement is rare in dimensional databases. In practice, users will be analyzing data either at the generic level or at the category level, but not both. To continue our product example, the analyst would want to be able to analyze sales of all products by product type, but that analysis would not require any product-specific details. Similarly, an analyst exploring sales of products in the Condiments category would be concentrating on that category and not require details about Beverages or DairyProducts. Because of this different pattern of use, it's better to avoid table joins by creating separate fact tables for the generic type and for each category, as shown in Figure 7-5. Figure 7-5. A Set of Fact Tables Representing a Heterogeneous Fact
There are two things to notice here. First, the facts most likely to be used in analysis are repeated in both the generic and category-specific fact tables. Duplicating these facts requires some additional storage space, but it avoids the necessity of joining the tables, which generally results in a large improvement in performance. The second thing to notice is that there are separate tables not just for facts, but also for the dimensions. This isn't strictly necessary. It is sometimes the case that there are no dimensional attributes specific to the category dimensions, and all the dimensional attributes can reasonably exist at the generic level. In this case, there is no value in duplicating the dimension. More often, however, each category does have dimensional attributes that are not shared by the other categories. In this case, multiple tables are more efficient because they avoid wide, largely empty, dimensional records. Whatever you do, avoid trying to define attributes at runtime, such that "If ProductType = 'Beverage', then Att1 = Decaffeinated; if ProductType = 'Condiment' then Att1 = JarSize" and so forth. I have occasionally seen this kind of indirect schema definition work in transactional systemswhen the systems had been designed and were maintained by really smart people. More often, the systems collapse in a burning heap the minute the requirements change or the original designer leaves the project. It's unlikely an indirect schema like this would last even that long in an analytical system. Remember that one of the primary goals of the star schema is that it be comprehensible to the end user. An indirect schema will never meet that goal. |