SnowflakingThere's one final thing to notice about the structure of the dimensions shown in Tables 8-1 and 8-2: They aren't normalized. The one-to-many relationships in the dimension are not extracted into separate tables as they would be in a normalized database. For example, in the dimension represented by Table 8-2 and Figure 8-1, there are almost certainly multiple Products in the Category "Bedding"; there is a one-to-many relationship between these two attributes. There is another one-to-many between Product and Style, and two more between Style and Size and between Style and Color. Figure 8-1. A Product Dimension
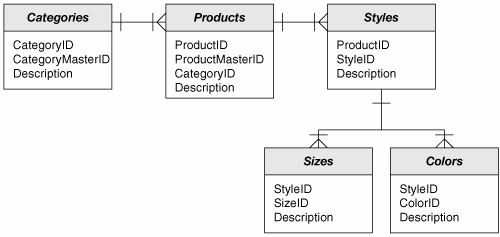
A normalized database would require that each of these one-to-many relationships be modeled as a separate table, as shown in Figure 8-2. This schema makes more efficient use of space, and reduces the likelihood of data entry errors. Figure 8-2. A Normalized Version of the Product Dimension Shown in Figure 8-1
But as I've said repeatedly, neither of those concerns applies to dimensional databases. (I do realize that I'm nagging, but the urge to normalize really is a difficult habit to break.) The goal of a dimensional database schema is to make it easy for the analyst to understand and browse. Normalizing a dimension, called snowflaking in dimensional design, fails to achieve either of these goals. There is one situation in which snowflaking is appropriate: when there is a many-to-many relationship between the dimension and the fact table. This situation is fairly rare in dimensional databases. The majority of many-to-many relationships are between dimensions, and of course in that situation the fact table is the junction table that resolves them. But many-to-many relationships between dimensions and facts do occasionally occur, and like any many-to-many relationship in a relational database, they must be resolved using a junction table. The classic example of this situation is between a fact table that models a visit to a doctor's office, and the dimension that models diagnoses. Obviously, a doctor might diagnose multiple problems in a single visit, so the many-to-many relationship between the dimension and the fact table must be modeled as shown in Figure 8-3. Figure 8-3. The Many-to-Many Relationship between the Diagnosis Dimension and a Visits Fact Table
This solution is very similar to the schema in a normalized database, but notice that the junction table contains an attribute called "Weight", which typically isn't present in a normalized database. The Weight attribute is a numeric value used to allocate the numeric facts when the Diagnoses dimension is used to restrict a query. The sum of the Weight values for each visit must equal 100. So, for example, if Ms. Bloggs visited Dr. Jones because she has a head cold, but while she was there the doctor also adjusted her blood pressure medication, there would be two records added to the VisitDiagnoses table with, say, 80 percent of the weight given to the cold, and 20 percent to the hypertension. If, then, an analyst asks for the total charges of all visits with a diagnosis of hypertension (e.g., the Diagnoses dimension is used to restrict the query), 20 percent of the cost of Ms. Bloggs' visit would be included in the result. If, on the other hand, the total charges of some group to which Ms. Bloggs belongsfemales under 20, saywere requested, then 100 percent of the cost would be included. Now the problem with this approach is probably clear: It's unlikely in the extreme that the required weight allocation is going to be available in the source system. If it isn't, you must either derive an artificial weighting (most often assigning each item an equal weight) or you must alter the source system. In our example, that would mean asking physicians to add the allocation to their charts. Yeah, right. What might not be so obvious is that the many-to-many relationship between dimensions and fact tables can sometimes be eliminated by adjusting the grain of the fact table. In our example, if we changed the grain from office visit to diagnosis, the many-to-many relationship would go away. Unfortunately, this doesn't eliminate the problem of allocation, it just moves it. Instead of assigning weights to dimension groups, you'd allocate costs to a fact table, with all the inherent problems we discussed in the last chapter. It doesn't follow, however, that changing the fact table grain to eliminate a many-to-many relationship isn't worth considering. Occasionally thinking about the problem in a different way really can make it go away, or at least can be the prompt needed to solve the most intractable of allocation problems. Only occasionally, I'm afraid, but it's still worth a try. When designing the schema of a traditional normalized database, the design process is most often a relatively simple matter of determining what the data means and then applying logically straight-forward rules to structure it. But the design of a dimensional database, despite its simple, predictable physical structure, is often a complex process of balancing fact table grain against the grain of the available data and the development of viable and politically acceptable allocation formulas. I'm tempted to say something about the equality of net complexity, but perhaps such discussions are a wee bit too metaphysical to be germane. |