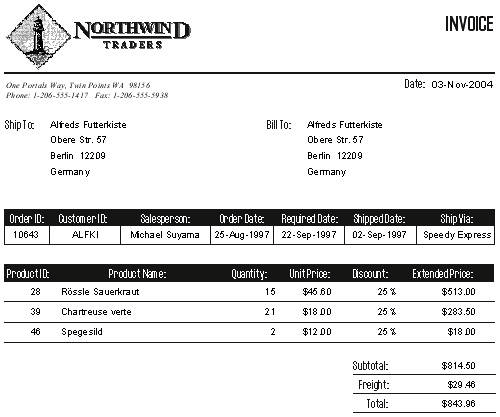
Identifying the Data ObjectsIn the earlier phases of the analysis, you will have gathered or created a set of source documents. These include both the documents provided by the clientsample input forms, reports, and so forthand the work process documentation you prepared. The first step in creating the data model is to review these sources and make a list of all the bits of data the system needs to deal with. Start with a work process. It doesn't really matter which one, but I usually choose one of the central ones for the project, since the core processes usually involve the majority of the entities. Most work processes are triggered by some piece of paper, like when a salesperson hands the order entry clerk a sales order. Sometimes they're triggered by some other kind of an event, in which case one of the first tasks is usually filling out a form. Continuing our order-processing example from Chapter 11, a sample Sales Order form might look like the one shown in Figure 12-1. Figure 12-1. Most Work Processes Are Triggered by a Piece of Paper Such as This Sales Order
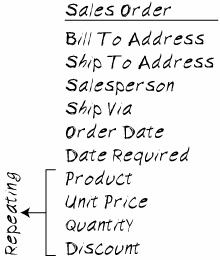
Find a sample of this first chunk of data, and write down all the bits of information it contains. Don't worry about classifying these bits as entities or attributes yet, just write them down. Do make a note of any repeating groups, and you'll also want to include any data items that your work process analysis has identified as missing. Your initial list of data items might look like the one in Figure 12-2. Figure 12-2. This Initial List of the Sales Order Form's Data Items
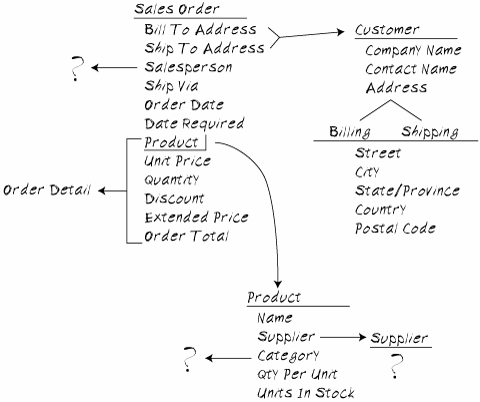
Now that you've compiled the list, you can start to extract the entities, attributes, and relationships. For each item on the list, you identify whether the item is an object or some fact about an object. Objects become entities, and the facts become attributes of the entity. The results of this analysis will probably look something like Figure 12-3. Figure 12-3. The Initial Definition of the Entities and Attributes in the Sales Order Form
As you can see, the Bill To and Ship To items have been identified as facts belonging to the added Customer entity. It's not, however, immediately apparent whether the two addresses belong only in the Customer entity, only in the Sales Order entity, or in both. The principle at work is the same as that for including the Unit Price in an Order Detail item. Just as the current selling price for a product is logically different from the price at which a specific product was sold, the current billing and shipping addresses for a client are logically different from the addresses to which this invoice and order were sent. Whether the shipping and billing addresses are also attributes of the Customer entity is something of a judgment call, based on the nature of the system and its users. Including these attributes in the Customer entity allows defaults to be set during the order entry process, which reduces the time required to enter the order and the opportunities for making data entry mistakes. It does, however, add the overhead of maintaining these values in the Customer entity. If the organization's customers typically have many shipping addresses (retail chains, for example), this overhead might be onerous, and a better solution is simply to enter the shipping address as part of the order entry process. Sometimes it makes sense to walk a middle ground. You can add multiple shipping address attributes to the Customer entity, for example, but not require that users fill them out. If there is a single address, the system can use that as a default. If there are multiple addresses, the system could present users with a list and allow them to choose. Or you might implement some conditional processing that uses the most recent address entered as a default but allows users to choose another from the list as required. You might also consider having the Customer entity updated by the order entry process. If there is no address, or if a user enters a new address, the system could ask whether it should be added to the customer record. These are user interface issues, not really data model issues, but the two are sometimes so closely tied that it's impossible to separate them entirely. The Salesperson data item also seems to indicate that an Employee entity exists somewhere, but we don't yet know what that needs to look like, hence the question mark. Chances are that other documents or processes will use this entity. If so, we can add the required attributes. If not, you might decide to leave Salesperson as an attribute of a Sales Order entity. Remember, these decisions must always be based on the semantics of the system. There's absolutely no value to be gained from creating an Employee input screen with managers, departments, and phone extensions if the data is only going to be used to list a name on a Sales Order. The Product item has been identified as an entity, and the group of items identified as repeating in the first diagram (Product, Unit Price, Quantity, and Discount) is identified as an Order Details entity. An initial set of attributes has been identified for the Product entity, presumably from another source document, and from this list the Supplier and (Product) Category entities have been identified, although again no details are yet available. Because we're defining the entities on a conceptual level, we don't care at this point whether attributes such as the Extended Price of an Order Detail entity or the Units In Stock of a Product entity are stored as values or calculated when required. We don't yet know whether they can in fact be calculated. That will come later. One interesting bit of data is the Ship Via attribute. Many order forms have a couple of check boxes for the shipping method, listing the values "Parcel Post", "FedEx", and "2nd Day Air", perhaps. Are these entities or attributes? It depends. (You guessed, didn't you?) How many options are there? If there are more than two, you won't be able to conveniently model this as a single attribute. How stable are the options? The chances are that you're dealing with external service providers here. Is the organization likely to change providers or add additional ones? How responsive does the organization need to be to special delivery methods? Will they turn down a sale that requires sending the goods by Sherpa to the top of Mount Everest? If not, your model needs to be able to account for all these options. Modeling the shipping method as a separate entity allows the items to be changed or added at any time, but at the cost of more complexity in both the data model and the user interface. The difference might be only a matter of a few keystrokes, selecting an item from a ComboBox rather than clicking in a check box with the mouse. But those extra keystrokes can, if you're not careful, add up to a clunky, slow interface. If the company must allow for special delivery methods, you'll need to consider carefully how to account for this. You must walk a fine line between allowing sufficient flexibility to handle all reasonable cases and imposing unnecessary overhead on users. In this example, the best solution would probably be the addition of an optional Special Instructions attribute, but this must also be accounted for in the data model and in any system processes. These decisions can affect the system constraints in unexpected ways. In this instance, although the organization clearly needs to know how to send the goods to the customer, it's no longer simply a question of requiring that a shipping method be specified. The system must specify that the Shipping Method and Special Instructions attributes cannot both be empty, a slightly more complex rule that must be implemented at a different level in the model. If the actual shipping of goods is within the scope of the system, treating the Shipping Method as a distinct entity might be a good idea and might in fact be required, but allowing for exceptional methods can add significant overhead to the system. How does one capture the shipping details for a shipping method one can't know about in advance? You can either create a generic shipping entity containing the attributes most methods provide, such as a docket number and pickup time, or you can specify the known methods and leave special handling as just thatan exceptional case to be dealt with outside the system. The danger here is in overcomplicating the system and placing unnecessary overhead on users. It's far too easy to get excited about the functionality the system is capable of providing and lose track of the overhead involved. Yes, providing default values is a good thing, provided they can be easily maintained and the maintenance is done regularly (preferably as a by-product of some other task). Making it possible for the receptionist to handle delivery inquiries is good, but is it worth the effort to enter shipping details for a thousand orders just so that they're available for the five customers who inquire? These decisions only require thinking through the implications of the design decisions you make. But this is easy to overlook when you're in the first flush of thinking, "Isn't this cool? It will save us so much time." When you capture a piece of data anywhere in the system, consider whether it can be used elsewhere in the system, either to provide a default or as a constraint. If you're entering the shipping details anyway, why not make them available to the receptionist? Conversely, whenever you use a piece of data, consider where it will be created and how it will be maintained. As a general rule, it's better to present users with a list of choices than with a text box. But there's a cost in creating and maintaining the list, and in building the maintenance interface. All of these things must be balanced when you're making decisions about the structure of your data model. Certainly, your goal is never to require that a piece of data be entered twice. But by the same token, you don't want to force users to go somewhere out of their way to enter a piece of data just so that it can be used for the task they want to do. We'll talk about this issue a great deal in Part IV, but identifying where bits of data are created and where they're used is the crucial first step in the process. |