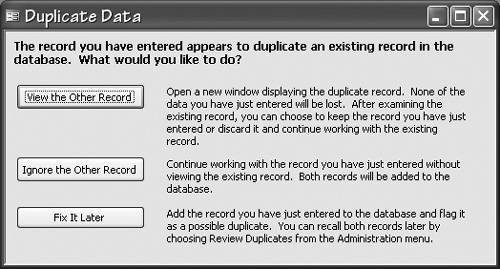
Intrinsic ConstraintsThe class of validation rules I'm referring to as intrinsic constraints controls the physical structure of the database. This class includes the rules governing the type, format, and length of data; the acceptability of null values; range constraints; and entity integrity and referential integrity. Data TypeProvided you've chosen appropriate control types, users normally don't run afoul of data type constraints. I've never known anyone to intentionally try to enter a date in the Amount Due field or enter text in a check box. Someone might, however, try to enter "eleven" into a text box that was expecting a numeric value, which is why the choice of data entry controls is so important, as we saw in the last chapter. FormatFormatting doesn't usually pose a problem, particularly if you can re-format the entry as users leave the field (Microsoft Access and Visual Studio both make this easy to do) or provide an input mask to guide user input. Be careful not to impose data formats too rigidly, however. If the data entered doesn't quite fit the format you've defined, you might be better off to match the data to the format as best you can and allow the users to fix it as they see fit. You don't want to do this if the invalid format indicates invalid data, but this situation is rare. A user who enters a telephone number as 9-9999-99999-99 could simply be dealing with a funky new phone system. LengthLength constraintsparticularly those on character fieldsconsistently cause problems. No matter how generous you've been, a perfectly valid entry that's too long to fit always seems to come along. You can sometimes avoid the length constraint problem by using Character fields, allocating the maximum field length (255 characters) and setting the field to a variable length type. In Microsoft Access, all text fields are variable length. In SQL Server, you must explicitly set the field type to VARCHAR. Both engines will allocate space only for the characters stored, so no space is wasted. Variable-length character fields aren't appropriate in all situations, of course. First, a certain length might be required. For example, Social Security Numbers are always nine characters long. If a user has a 10-character Social Security Number, length isn't the problem; the data is invalid. Allowing it to be entered would be unwise. Second, because of the way SQL Server handles updates of records containing variable-length character fields, using them can result in slower performance. In most situations, the performance hit is negligible, but in performance-critical applications that require updating the data frequently using fixed length fields is preferable. (There's no performance difference in adding data, only in updating it.) Finally, although allowing very long field lengths can improve usability, this isn't always the case. Sometimes, in fact, it can wreak havoc with usability. Screen and report formats can get ugly (especially reports, because it isn't possible to scroll the data), and finding records that contain particular information can be a nightmare. When it isn't appropriate to allow long data values, try to provide conventions or policies for handling data that doesn't fit. If a customer name really is longer than the allotted space, you might work with users to establish reasonable conventions for shortening it, such as eliminating articles such as "The", always abbreviating "Company" to "Co", and truncating all the characters after the word "Company." This will help ensurebut not guaranteethat "The Really, Really Long Name Company, Incorporated" will always be entered as "Really, Really Long Name Co" and not as "Really, Really Long, Inc" one time and "Really Long Name Company" the next. NullsMissing values is the next area in which users often have trouble with intrinsic constraints. We've discussed null values at great length elsewhere, and I've tried to make it clear that I believe nulls should be allowed wherever values can reasonably be unknown in the real world, at least where doing so won't make the data completely irrelevant to the system. If you choose to ignore this sage advice, however, you must consider how the system can assist the poor user who is trying to create a new record without all the data being available. The issue here is when the data is needed. You know from analyzing the system's work processes that certain bits of information are required before a given task is completed. But that doesn't mean all the data required by all the tasks is required when the record is first created. You need new employees' bank details before you can pay them. So bank detail fields can't be null come payday. But just because the employee doesn't have the information handy when a user first creates the record, the database system shouldn't prevent a user from entering the rest of the employee's details or from performing other tasks. The user might need to produce a security card so that the person can get into the building. The bank details aren't needed for that task. The bank details will be needed eventually, just not necessarily on the first day of work. Don't let your system throw a tantrum; everything will be fixed up in timethe employee will see to that! If you're unwilling to accept null values, even temporarily, the easiest way to handle this constraint is to provide some reasonable default value. One possibility is for the system to declare a single value as a default in the database schema. Alternatively, the system can present a selection of values to the userperhaps "UNKNOWN", "NOT APPLICABLE", and "YET TO COME". Sometimes the system can calculate a reasonable default value on the fly. RangesSpecified ranges are the other attribute-level constraintsin addition to Null valueswith which users often have trouble. Some range constraints are explicit in the data type255 is the largest value that can be stored in a short integer, for example. When a data type determines a range constraint, you can't do much beyond explaining the constraint to users. If larger values are required, you must identify a data type with a higher range in the database schema. I do not recommend trying to have your application do this on the fly. If, however, you have defined the range constraint as a validation rule or CHECK constraint in the schema, or you have implemented the constraint in the application instead of in the schema, chances are that it's a business rule rather than an intrinsic constraint and you have a lot more room to maneuver. (We'll examine business rules in the next section.) Entity and Referential Integrity ConstraintsYou'll remember that entity constraints ensure that each record in a table can be uniquely identified, while referential integrity constraints prohibit records from referencing records that don't exist in the same or another table. You must consider how to handle entity constraints and referential constraints without unnecessarily imposing on the user. They are most commonly handled by allowing users to select from a list of valid items. However, as we saw in the last chapter, this isn't always possible, usually because the list would be too long to be practicable. When constraining users' entries in a list isn't possible or appropriate, check the data as soon as possible after it's been entered and notify the user of any problems. A record entry that appears to duplicate an existing record in the database is an entity constraint problem. The system's best response is to offer to display the existing recordor just the pertinent fieldsto the user and allow the user to decide whether the new record really is a duplicate, as shown in Figure 19-1. Figure 19-1. This Dialog Box Allows the User to Decide Whether the New Record Is a Duplicate
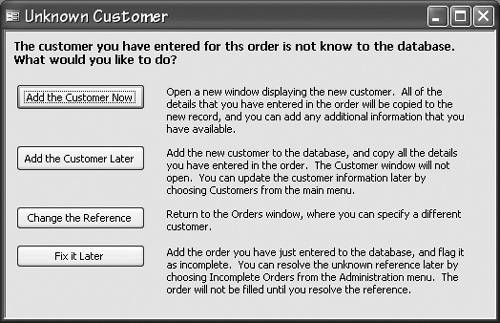
Be careful not to overwrite the data the user has entered for the new record when you display the existing record. Display the existing record in a separate window, and allow the user to decide whether to overwrite the new record. Notice, too, that the dialog box in Figure 19-1 allows the user to continue entering data without viewing the suspected duplicate. The user might already know about the other record, and you don't want to disrupt him any more than absolutely necessary. (Repeat after me: "The computer does not know best, the computer does not know best, the computer....") The user who is trying to leave a primary key field blank presents a slightly different problem. That a primary key field value can't be empty is the best argument I know for using a system-assigned primary key. Using an AutoNumber field (an Identity field in SQL Server) ensures that users can do anything they require to the natural primary key fields without compromising entity or referential integrity. If using AutoNumber (or Identity) fields isn't appropriate in your system, you must ensure that users enter some value into each primary key field. Simple default values can't be used, obviously, because the default would be accepted only once for each table. You could have the system calculate a value on the fly, but if you're going to use an arbitrary value you might as well use an AutoNumber field. Your only other choice is to query users for an acceptable value. When a referential integrity problem occurs, a user is usually trying to reference a record that doesn't exist. This can be accidentalthe user might have misspelled a name, for exampleor it can be more or less intentional. The user might not realize that the referenced record doesn't exist or might not have gotten around to entering the data yet. The dialog box shown in Figure 19-2 shows one way of handling this situation. This dialog box gives users four options: They can have the system add a new record and add the details now, they can have the system add a new record and update the record later, they can change the reference, or they can fix the reference later. Figure 19-2. This Dialog Box Allows the User to Choose How to Handle a Referenced Record that Doesn't (Yet) Exist
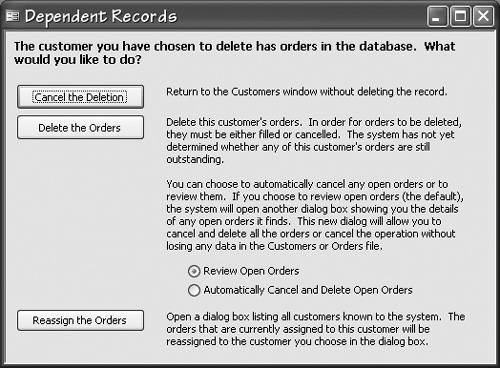
Note that overriding the constraint is not an option for the user. This constraint can't be overridden because doing so can make the database unstable, as we've seen. If you are unable to have the dialog box present a complete list of valid items to users because the list would be too long, your dialog box can instead display a list of items that are close matches to the entered data. Any number of algorithms for performing these searches exists, from a simple SQL LIKE statement to a SOUNDEX search. In some situations, it is not necessary to display a referential integrity validation dialog box at all. In fact, it's generally better to avoid doing so and thereby avoid disrupting users' work. If you can predict with reasonable certainty that users will want to add the new records and update the details later, and you have provided adequate facilities for undoing the system's actions if you've guessed wrong, the system can simply add the new record quietly, in the background, without making a fuss. After the user completes the record, you might want to display a message in the status bar that the record has been added or display the message in a dialog box if you want the information to be more obvious. But whatever you do, don't interrupt users while they're entering the records if you can avoid it; it's unnecessarily rude and is scary for users. The flip side of users trying to reference a record that doesn't exist is users trying to delete or change a referenced record. A user might be trying to delete a record for a customer that has outstanding orders, for example, or change the ProductID value for a product that is referenced in the OrderItems table. The Microsoft Jet database engine supports cascading updates and cascading deletes that allow updates and deletes of referenced records to be handled without user intervention. You can implement the same functionality in SQL Server using triggers. If cascading updates and deletes make sense in your application, using them is by far the best solution. However, if only the users can decide the best course of action, be sure to explain to them the implications of their choice, as shown in Figure 19-3. Figure 19-3. This Dialog Box Explains the Implications of Each Option and Allows Users to Choose
The dialog box in Figure 19-3 lets users cancel the deletion, cascade the deletion, or reassign the dependent records to a different customer. Notice the dialog box warns users that open orders can't be deleted (which is a business rule) and provides the option of canceling the orders (essentially overriding the rule) or reviewing them. You might also display the open orders, or all the customer's orders, in the validation dialog box. Your goal is to provide users with as much information as you can to allow them to make an informed decision. |