| [ Team LiB ] |
|
5.2 Content CachingOne of the best ways to increase scalability is through caching. Caching static pages is a well established practice on the web, and dedicated web caches are taking their place with routers and switches as standard equipment in the data center. A web cache maintains copies of the most frequently requested files, which allows it to serve those requests quickly, without involving the real web server. Most caches rightly ignore dynamically generated pages, as there's no way to efficiently determine whether any two requests should receive the same response (or, for that matter, whether the web server needs to process the request for other reasons). To create a high performance J2EE environment, we need to bring the benefits of caching to the dynamic components of the presentation tier. In this section, we'll look at two approaches to this problem: caching the input used to generate the dynamic content, and caching the generated content itself. 5.2.1 Caching Content ComponentsThe traditional communication model for web applications is synchronous. In other words, clients make requests for URLs and wait until they receive a web page in response. Given the nature of this exchange, it is easy to see why most application logic is implemented in a synchronous manner. As requests come in, the various parts of the response are calculated and correlated, and then the final response is generated. The problem with this approach is that it can be quite inefficient. In Chapter 4 we discussed a method of adding remote news feeds to a page by building a simple RSS parsing mechanism. Our approach was synchronous: when a request came in for a page containing a news feed, a JSP custom tag read and parsed the remote data and then formatted it for display. If we scale this approach up to the point where we have multiple servers each talking to multiple feeds, we might end up with something like the situation shown in Figure 5-1. Figure 5-1. Reading multiple news feeds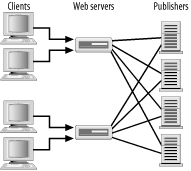 This approach is inefficient for a number of reasons. Contacting every publisher on every request wastes bandwidth and saturates the publishers' servers. Requests would also be quite expensive in computer resources, since the feed needs to be parsed and translated into HTML on every request. Caching the data on each server should significantly increase the number of clients that can be supported. While caching represents a significant win for scalability, it does not exploit the fact that news feeds only update intermittently. Having a cache requires a caching policy; for instance, the data could be updated on every tenth request, or every ten minutes. Keeping the data up-to-date still requires each web server to contact the publisher frequently, wasting bandwidth and potentially CPU time. It also means rereading and reparsing the data separately on each server. A better solution would be one where the data was only transmitted when it changed. Figure 5-2 shows the same system using a publish-subscribe model. A single machine, the application server, subscribes to a number of news feeds. When new data becomes available from a particular feed, the data is parsed and sent to all the individual web servers.[2] Because the data is only sent from the publisher to the subscriber as needed, we say this solution is asynchronous. Often, an asynchronous solution requires far less bandwidth than a synchronous one, since data is only sent to the many web servers as needed.
Figure 5-2. A publish-subscribe model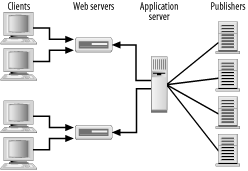 5.2.2 The Asynchronous Page PatternThe benefits of asynchronous communication are not new. Messaging in particular has been a major component of enterprise backends for a long time. The Java Message APIs and the recent addition of message-driven JavaBeans have solidified the place of asynchronous communication in the Java enterprise architecture. While no standard is currently in place, asynchronous web services are starting to crop up. However, with the exception of a few "push-based" (another term for publish-subscribe) content providers, asynchronous communication has never taken off at the client tier because the standard clients梬eb browsers梔o not support publish-subscribe systems. The lack of browser support for push-based systems does not mean asynchronous communication has no place in a web-based world. It can still be a powerful tool for improving scalability by reducing the work required to handle each transaction. The Asynchronous Page pattern takes advantage of asynchronous retrieval of remote resources to improve scalability and performance. Rather than waiting for a request for a stock quote, for example, a server may accept all stock quotes as they are generated. When a request comes in for a particular quote, the server simply replies with the data it has already received. Figure 5-3 shows the interactions in the Asynchronous Page pattern. In general, there is a single subscriber that listens to feeds from a number of publishers. As data is updated, the subscriber updates the models of the dependent web applications. When requests come in, the responses incorporate the latest values that have been published. Figure 5-3. Asynchronous Page interactions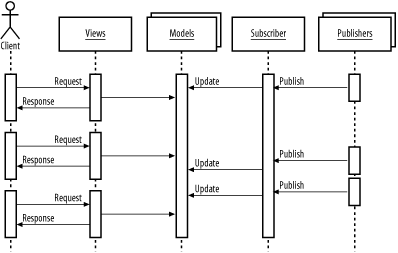 It's important to note that the interface between the publisher and the subscriber does not need to be push-based. Although it is ideal for the publisher to directly notify the subscriber when there are changes to the data, it is also reasonable to have the subscriber poll the publisher at regular intervals. The amount of work involved in updating the model can also vary. In some cases, the raw data read from the publisher may be inserted directly into the model unmodified. The pattern is more beneficial, however, when the subscriber processes the data, reducing the work for all the various models. A common tactic is to remove the dynamic page altogether, replacing it with a static page that is simply rewritten each time data is published. 5.2.2.1 Implementing the Asynchronous Page patternLet's update our earlier RSS-parsing example to use the Asynchronous Page pattern. Remember, RSS is a standard for sharing news feeds between web sites. It's an XML-based format, and we want to present it as HTML. Originally, we created a class and two custom tags to flexibly parse RSS. The RSSInfo class reads and parses the RSS from a given URL. Based on this class, we created two tags. The first, RSSChannel, takes a URL as an argument and reads the remote data. Within the RSSChannel tag, two scripting variables store the name of the channel and its link. The RSSItems tag may be nested in an RSSChannel tag. The RSSItems tag iterates through each item in the channel, storing its title and link in scripting variables. Our problem is that the RSSChannel tag is actually reading the data from the remote source. It would be more efficient if the data were stored locally, and only updated as needed. Unfortunately, RSS does not provide a subscription mechanism, so we must poll the remote data. Rather than go through that process at each read, we want a dedicated mechanism to do the polling and update the local copy. The dedicated mechanism will allow us to read the data from a single, central source, and then distribute it to the actual request processors if it is changed. In this example, we will add a single class, the RSSSubscriber. RSSSubscriber allows subscriptions to be added to different RSS URLs. Once a subscription is added, a separate thread polls the URL at a specified interval. If the URL is changed, the new data is added to a local cache. All requests after the original are served from this cache. An implementation of the RSSSubscriber class is shown in Example 5-1. Example 5-1. The RSSSubscriber classimport java.util.*;
import java.io.IOException;
public class RSSSubscriber extends Thread {
private static final int UPDATE_FREQ = 30 * 1000;
// internal representation of a subscription
class RSSSubscription implements Comparable {
private String url;
private long nextUpdate;
private long updateFreq;
// sort based on next update time
public int compareTo(Object obj) {
RSSSubscription rObj = (RSSSubscription)obj;
if (rObj.nextUpdate > this.nextUpdate) {
return -1;
} else if (rObj.nextUpdate < this.nextUpdate) {
return 1;
} else {
// if update time is the same, sort on URL
return url.compareToIgnoreCase(rObj.url);
}
}
}
// a set of subscriptions, sorted by next update time
private SortedSet subscriptions;
private Map cache;
private boolean quit = false;
// singelton subscriber
private static RSSSubscriber subscriber;
// get a reference to the singleton
public static RSSSubscriber getInstance( ) {
if (subscriber == null) {
subscriber = new RSSSubscriber( );
subscriber.start( );
}
return subscriber;
}
RSSSubscriber( ) {
subscriptions = new TreeSet( );
cache = Collections.synchronizedMap(new HashMap( ));
setDaemon(true);
}
// get an RSSInfo object from cache, or create a new
// subscription if it's not in the cache
public RSSInfo getInfo(String url) throws Exception {
if (cache.containsKey(url)) {
return (RSSInfo)cache.get(url);
}
// add to cache
RSSInfo rInfo = new RSSInfo( );
rInfo.parse(url);
cache.put(url, rInfo);
// create new subscription
RSSSubscription newSub = new RSSSubscription( );
newSub.url = url;
newSub.updateFreq = UPDATE_FREQ;
putSubscription(newSub);
return rInfo;
}
// add a subscription
private synchronized void putSubscription(RSSSubscription subs)
{
subs.nextUpdate = System.currentTimeMillis( ) +
subs.updateFreq;
subscriptions.add(subs);
notify( );
}
// wait for next subscription that needs updating
private synchronized RSSSubscription getSubscription( ) {
while(!quit) {
while(subscriptions.size( ) == 0) {
try { wait( ); } catch(InterruptedException ie) {}
}
// get the first subscritpion in the queue
RSSSubscription nextSub =
(RSSSubscription)subscriptions.first( );
// determine if it is time to update yet
long curTime = System.currentTimeMillis( );
if(curTime >= nextSub.nextUpdate) {
subscriptions.remove(nextSub);
return nextSub;
}
// sleep until the next update time
// this will be interrupted if a subscription is added
try {
wait(nextSub.nextUpdate - curTime);
} catch(InterruptedException ie) {}
}
}
// update subscriptions as they become available
public void run( ) {
while(!quit) {
RSSSubscription subs = getSubscription( );
try {
RSSInfo rInfo = new RSSInfo( );
rInfo.parse(subs.url);
cache.put(subs.url, rInfo);
} catch(Exception ex) {
ex.printStackTrace( );
}
putSubscription(subs);
}
}
public synchronized void quit( ) {
quit = true;
notify( );
}
}
Our new RSS subscription mechanism runs on a single host, but it is easy to see how it could be extended to multiple servers. In any case, it supports more simultaneous requests by having a dedicated thread for updating and parsing requests. Except for the initial request for a given subscription, no thread ever has to block on reading or parsing the remote data. It is effectively done in the background. To use the RSSSubscriber, our custom tag simply calls getRSSInfo( ) for the URL it is passed. getRSSInfo( ) will read the data from the cache when possible and create a new subscription when it is not. Example 5-2 shows the custom tag class. Example 5-2. The RSSChannelTag classimport javax.servlet.*;
import javax.servlet.jsp.*;
import javax.servlet.jsp.tagext.*;
public class RSSChannelTag extends BodyTagSupport {
private static final String NAME_ATTR = "channelName";
private static final String LINK_ATTR = "channelLink";
private String url;
private RSSSubscriber rssSubs;
public RSSChannelTag( ) {
rssSubs = RSSSubscriber.getInstance( );
}
public void setURL(String url) {
this.url = url;
}
// get the latest RSSInfo object from the subscriber
// this method is called by the RSSItems tag as well
protected RSSInfo getRSSInfo( ) {
try {
return rssSubs.getInfo(url);
} catch(Exception ex) {
ex.printStackTrace( );
}
return null;
}
// use the updated RSSInfo object
public int doStartTag( ) throws JspException {
try {
RSSInfo rssInfo = getRSSInfo( );
pageContext.setAttribute(NAME_ATTR,
rssInfo.getChannelTitle( ));
pageContext.setAttribute(LINK_ATTR,
rssInfo.getChannelLink( ));
} catch (Exception ex) {
throw new JspException("Unable to parse " + url, ex);
}
return Tag.EVAL_BODY_INCLUDE;
}
}
Although the RSS reading example is simple, it shows one of the many opportunities for asynchronous communication in a request-driven environment. The opportunity, of course, depends on how the data is accessed. Imagine accepting, parsing, and storing a quote for every stock on the NYSE, and only getting one or two requests for quotes before it is all updated again. The time and memory expended receiving these values asynchronously would be wasted. Of course, in some applications it's not acceptable to have any out-of-date data條ike when you're transferring money at an ATM. In evaluating asynchronous methods, it is important to take into account the costs in terms of data staleness, network use, and memory use, as balanced against the benefits of speed and scalability. 5.2.3 Dynamic Content CachingThere is another class of dynamic data that is amenable to caching. Imagine an online car dealership where users go through a few pages selecting various options and then view the resulting car's price. The price computation could be a lengthy process, possibly accessing an external system that's also used by dealers, or even one that keeps track of dealer stock. Certain cars and options梩he sport package, a sunroof梐re far more common than others. Since the same set of options always yields the same price, it's inefficient to recalculate it every time. Even worse for the efficiency of the site is all the overhead of generating the page dynamically: querying prices in the database and assembling multiple views into a composite. We would like to cache the page with the price calculated and the HTML generated. In a perfect world, the application itself would not have to worry about caching at all. HTTP 1.1 allows caching dynamic GET requests, as long as we set the correct HTTP header fields.[3] Once these fields are set, the client, an intermediate cache, or even the HTTP server can do the caching. In practice, however, we frequently have to do it ourselves.
5.2.4 The Caching Filter PatternThe Caching Filter pattern uses a servlet filter to cache dynamically generated pages. We talked a fair bit about filters, including their capabilities and implementation, when we talked about the Decorator pattern in Chapter 3. The caching filter is a specific implementation of a decorator. When applied to the front controller, it caches fully generated dynamic pages. The classes in the Caching Filter pattern are shown in Figure 5-4. Figure 5-4. Classes in the Caching Filter pattern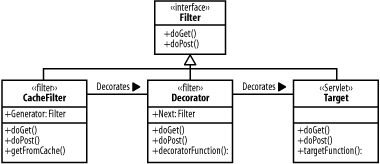 The CacheFilter itself works just like any other filter: it presents the API of its one child. It also provides extra methods to read pages from the cache as well as to add the results of executing a particular request to the cache. When a request comes in, the cached page is simply returned if it exists. If the page is not cached, the rest of the chain must be executed and the result stored in the cache. The process of handling a request is shown in Figure 5-5. Figure 5-5. Interactions in the Caching Filter pattern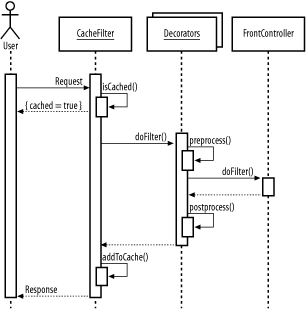 It is important to think about where caching filters are positioned in the filter chain. In principle, a caching filter can be added anywhere in the chain, caching the results from all the filters after it. There can even be multiple caches at different levels in the chain, perhaps caching part of the processing while still doing some of it dynamically.
5.2.5 Implementing a Caching FilterIn order to cache the data, we need to change how data is communicated to the server. In many cases, the client simply requests the next page without passing all relevant parameters. The controller uses a combination of the requested page and parameters stored in the session to generate the final output. The client's request might look like: GET /pages/finalPrice.jsp HTTP/1.1 To which the server would add its stored entries about the selected options. Unfortunately, the GET request looks exactly the same, regardless of the options selected. The fact that the user wants electric blue paint and alloy wheels is not reflected in the request at all. To find a cached page, the session variables would have to be read, sacrificing some of the speed gained by caching. Instead, the URL should contain all the options in the query string. By including the options, our request might look like: GET /pages/finalPrice.jsp?paint=Electric+Blue&Wheels=Alloy We can implement the most efficient caching when the query string fully specifies the page (see the sidebar "GET, POST, and Idempotence").
To implement a caching filter, we will use the servlet's filter API. As we did in Chapter 3, we will decorate the response object we pass down the filter chain with one that stores the results of processing the rest of the chain. This wrapper is implemented in the CacheResponseWrapper class, shown in Example 5-3. Example 5-3. The CacheResponseWrapperpublic class CacheResponseWrapper extends HttpServletResponseWrapper {
// the replacement OutputStream
private CacheOutputStream replaceStream;
// the replacement writer
private PrintWriter replaceWriter;
// a simple implementation of ServletOutputStream
// that stores the data written to it
class CacheOutputStream extends ServletOutputStream {
private ByteArrayOutputStream bos;
CacheOutputStream( ) {
bos = new ByteArrayOutputStream( );
}
public void write(int param) throws IOException {
bos.write(param);
}
// read back the stored data
protected byte[] getBytes( ) {
return bos.toByteArray( );
}
}
public CacheResponseWrapper(HttpServletResponse original) {
super(original);
}
public ServletOutputStream getOutputStream( )
throws IOException {
if (replaceStream != null)
return replaceStream;
// make sure we have only one OutputStream or Writer
if (replaceWriter != null)
throw new IOException("Writer already in use");
replaceStream = new CacheOutputStream( );
return replaceStream;
}
public PrintWriter getWriter( ) throws IOException {
if (replaceWriter != null)
return replaceWriter;
// make sure we have only one OutputStream or Writer
if (replaceStream != null)
throw new IOException("OutputStream already in use");
replaceWriter = new PrintWriter(
new OutputStreamWriter(new CacheOutputStream( )));
return replaceWriter;
}
// read back the stored data
protected byte[] getBytes( ) {
if (replaceStream == null)
return null;
return replaceStream.getBytes( );
}
}
By passing a CacheResponseWrapper to the next filter in the chain, we can store the output in a byte array, which can then be cached in memory or to disk. The actual caching filter is fairly simple. When a request comes in, it determines if the page can be cached or not. If it can, the filter checks to see if it is in the cache and either returns the cached version or generates a new page and adds that to the cache. The filter code is shown in Example 5-4. Example 5-4. The CacheFilter classpublic class CacheFilter implements Filter {
private FilterConfig filterConfig;
// the data cache
private HashMap cache;
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException
{
HttpServletRequest req = (HttpServletRequest)request;
HttpServletResponse res = (HttpServletResponse)response;
// the cache key is the URI + query string
String key = req.getRequestURI() + "?" + req.getQueryString( );
// only cache GET requests which contain cacheable data
if (req.getMethod( ).equalsIgnoreCase("get") && isCacheable(key))
{
// try to retrieve the data from the cache
byte[] data = (byte[]) cache.get(key);
// on a cache miss, generate the result normally and
// add it to the cache
if (data == null) {
CacheResponseWrapper crw = new CacheResponseWrapper(res);
chain.doFilter(request, crw);
data = crw.getBytes( );
cache.put(key, data);
}
// if the data was found or added to the cache,
// generate the result from the cached data
if (data != null) {
res.setContentType("text/html");
res.setContentLength(data.length);
try {
OutputStream os = res.getOutputStream( );
os.write(data);
os.close( );
return;
} catch(Exception ex) {
...
}
}
}
// generate the data normally if it was not cacheable
// or the cache failed for any reason
chain.doFilter(request, response);
}
// determine if the data is cacheable
private boolean isCacheable(String key) {
...
}
// initialize the cache
public void init(FilterConfig filterConfig) {
this.filterConfig = filterConfig;
cache = new HashMap( );
}
}
Notice that we haven't made the cache variable static. According to the filter specification, only one filter instance will be created for each filter element in the deployment descriptor. We can therefore keep separate caches in each filter, allowing multiple caches at different points in the filter chain, without worrying about spreading the same data across multiple cache objects. Our simple filter avoids two of the difficult parts of caching. The first is determining if a page can be cached at all. In most environments, there will be a mix of cacheable and uncachable pages. In our car dealership example, the various configurations of cars may be cacheable, but a user's credit card information certainly isn't! A typical solution is to provide a mapping, like a servlet or filter mapping in an XML file, to determine which pages can be cached. The second difficulty this filter avoids is cache coherency. Our model assumes the generated page will never change. If the prices for certain options change, users will still see the old, cached copy of the page. Many coherency strategies are possible, depending on the nature of the generated pages; at the minimum, pages should expire from the cache after some predefined period. If they don't, the cache grows without bounds, a situation discussed in Chapter 12, when we cover the Leak Collection antipattern. |
| [ Team LiB ] |
|