|
|
< Free Open Study > |
|
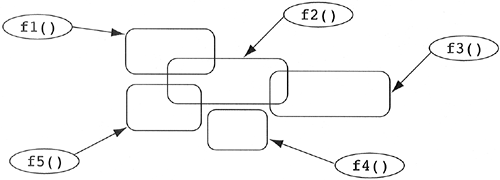
3.1 Differences in Application TopologiesIt is very helpful to think of object-oriented software development as the next logical step in removing the details of the machine away from software developers. However, a learning curve is associated with this removal of details, due mostly to the different topology that the object-oriented paradigm enforces on the software development process. While action-oriented software development is involved with functional decomposition through a very centralized control mechanism, the object-oriented paradigm focuses more on the decomposition of data with its corresponding functionality in a very decentralized setting. It is this decentralization of software that gives the object-oriented paradigm its ability to control essential complexity. It is also the cause for much of the learning curve. When the object-oriented community talks about the need for designers to undergo a paradigm shift, it is this decentralization to which they refer. In the following examples we will discuss the worst-case action-oriented topology contrasted with the best-case object-oriented topology. We will then examine what happens when the action-oriented paradigm goes right and when the object-oriented paradigm goes wrong. In any event, many developers believe that the average action-oriented development leans toward the worst-case scenario while the average object-oriented development tends toward the best-case result (especially in the presence of important design heuristics). Consider the symbolic functional decomposition displayed in Figure 3.1. Figure 3.1. A typical action-oriented topology.
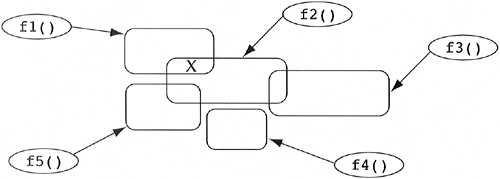
As the figure shows, an application has been broken down into five functions. As an afterthought, underlying data structures are created as part of the implementation of these functions. The developers of these data structures have realized that some functions can share parts of their underlying data (e.g., f1() and f2() are sharing part of the data structure). In the action-oriented world, it is easy to find data dependencies simply by examining the implementation of functions. Given the union of the formal parameter types, local variable types, and any accessed global variable types, the developer knows exactly the data on which code is dependent. However, we have a problem if we wish to know the functional dependencies on a piece of data in the system. In the action-oriented paradigm, there is not an explicit relationship between data and functionality. Consider a change to the data structure marked X in Figure 3.2. Figure 3.2. A typical action-oriented topology.
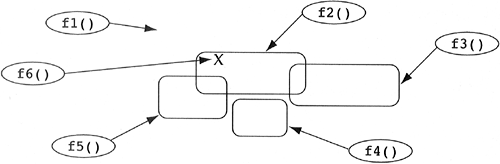
Based on the diagram, we can state that only the functions f1() and f2() will require modification if the data marked X is modified. However, last weekend another developer created f6() without your knowledge (see Figure 3.3). It is also dependent on the data marked X. You make all of your changes to the data X and the functions f1() and f2(). You compile, link, and run the resultant executable, and things do not work properly. You spend the next n days trying to find out what went wrong. Anyone who has developed any application of reasonable size has undoubtedly run into this problem. Most action-oriented systems have these undocumented data/behavior dependencies due to their unidirectional relationship between code and data. Most action-oriented systems have a spaghetti-like underlying data structure on which all developers hang their code. If version 1 of a system does not have it, version 2 will be likely to have it (read Frederick Brook's Mythical Man-Month book for an interesting discussion on the dangers of version 2 of a system). Figure 3.3. A typical action-oriented topology.
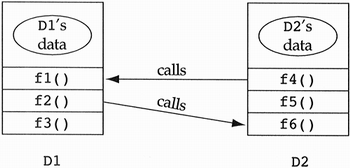
How does object-oriented programming control this complexity? Consider an object-oriented solution to the above problem (see Figure 3.4). Many developers correctly claim that the action-oriented paradigm focuses only on the functionality of a system and typically ignores the data until it is required. They then claim that the object-oriented paradigm focuses exclusively on the data, ignoring the functionality of the system until it is required. This is not possible, because the behavior of a system often drives the decomposition of data. It is preferable to think of the object-oriented paradigm as keeping data in the front of a developer's mind while keeping functionality in the back of his or her mind. The result of this process is the decomposition of our system into a collection of decentralized clumps of data with well-defined public interfaces. The only dependencies of functionality on data are that the operations of the well-defined public interfaces are dependent on their associated data (i.e., implementation). In Figure 3.4, the classes D1 and D2 use one another to carry out the functionality. The action-oriented picture is not always so bleak, nor the object-oriented picture so rosy. Figure 3.4. A typical object-oriented topology.
|
|
|
< Free Open Study > |
|