Exceptions are a way for the .NET runtime to signal that a serious error condition has arisen during program execution, one that could potentially cause a program to abort. One such situation would be trying to access a nonexistent object, as in the following example:
Student s1 = new Student(); Student s2 = null; s1.Name = "Fred"; // this line is fine s2.Name = "Mary"; // this line throws an exception
Let's explore what is happening in the preceding code:
We declare two Student object references, but only instantiate one Student object; s2 is assigned the value null, indicating that it isn't presently holding onto any object:
Student s1 = new Student(); Student s2 = null;
When we subsequently attempt to assign a value to the Name property of s1, all is well:
s1.Name = "Fred"; // this line is fine
However, this next line of code throws a NullReferenceException at run time, because we are trying to access a property of a nonexistent object:
s2.Name = "Mary"; // throws an exception
Exception handling enables a programmer to gracefully anticipate and handle such exceptions by providing a way for a program to automatically transfer control from within the block of code where the exception arose—known as a try block—into a special error-handling code block known as a catch block.
The mechanics of exception handling are as follows:
We place code that is likely to throw an exception inside of a pair of braces { … }, then place the keyword try just ahead of the opening brace for that block to signal the fact that we intend to catch exceptions thrown within that block:
try {
code likely to cause problems goes in here ...
}
This is known as a try block.
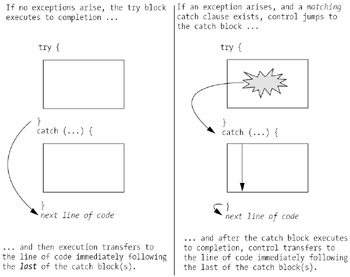
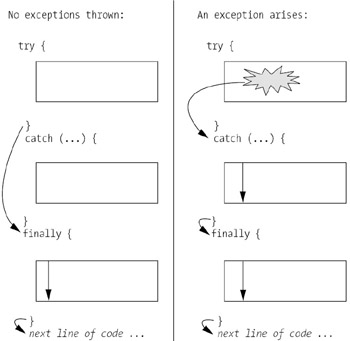
A try block must also be accompanied by either: (a) one (or more) catch blocks, (b) a finally block, or (c) a combination of (a) and (b).
Each catch block begins with a catch clause of the form
catch (exception_type variable_name)
that declares which category of exception it will catch, along with providing a reference variable name to represent the exception object being thrown so that we may manipulate the exception object from within the catch block if desired. The contents of the catch block represent the "recovery" code that is to be automatically executed upon occurrence of that exception:
We can also optionally specify a block of code that will always execute regardless of whether an exception has occurred in the try block or not. Known as a finally block, this block of code is preceded by the finally keyword, and follows the last catch block (if any are present). A finally block is typically used to perform any necessary cleanup operations, such as perhaps closing either a file or a connection to a database.
try {
code likely to cause problems goes in here ...
}
catch (exception_type_1 variable_name) {
recovery code for the first exception type goes here ...
}
catch (exception_type_2 variable_name) {
recovery code for the second exception type goes here ...
}
finally {
perform cleanup operations ...
}
Alternative paths through a try-catch block without an optional finally block are illustrated in Figure 13-8, and alternative paths through a try-catch block with an optional finally block are illustrated in Figure 13-9.
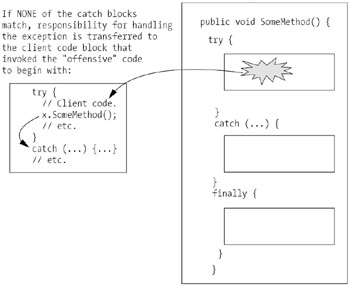
If none of the catch blocks match when an exception is thrown, responsibility for handling the exception is transferred to the client code that invoked the "offensive" code to begin with (see Figure 13-10).
Going back to our previous example involving Student objects, here's an enhanced version of the code that employs exception handling:
// We declare two Student object references, but only instantiate one
// Student object; s2 is given a value of null, indicating that it
// isn't presently holding onto any object.
Student s1 = new Student();
Student s2 = null;
// Exception handling is now in place.
try {
Console.WriteLine("Initializing students ...");
// This line executes without throwing an exception.
s1.Name = "Fred";
// This next line of code throws a NullReferenceException at run time because
// s2 was never initialized to refer to an actual Student object ...
s2.Name = "Mary";
// ... and as soon as the exception is detected by the runtime, execution
// jumps out of the try block -- none of the remaining code in
// this try block will be executed -- and into the first catch block
// below that is found to match a NullReferenceException, if any.
s1.Major = "MATH";
s2.Major = "SCIENCE";
Console.WriteLine("Initialization successfully completed");
} // end of try block
// Pseudocode.
catch (UnrelatedExceptionType e1) {
exception handling code for this type of (hypothetical) exception
goes here ... but, since our example doesn't involve throwing this
particular type of exception at run time, this catch block will be
skipped over without being executed.
Console.WriteLine("UnrelatedExceptionType was detected ...");
}
catch (NullReferenceException e2) {
// Here's where we place the code for what the program should do if
// a null reference was detected at run time.
Console.WriteLine("Whoops -- we forgot to initialize all of the students!");
}
finally {
// This code gets executed whether or not an exception occurred: that is,
// whether we made it through the try block without any exceptions being
// thrown, or whether one of the catch blocks was triggered.
Console.WriteLine("Finally!!!");
}
// After the finally block executes, control transfers to the
// line of code immediately following the finally block.
System.out.println("Continuing along our merry way ...");
When the previous code is executed, the following output would result:
Initializing students ... Whoops -- we forgot to initialize all of the students! Finally!!! Continuing along our merry way ...
because both the second catch block and the finally block will have executed.
Note that nothing needs to be done from a programming perspective to explicitly transfer control from the try block to the appropriate catch block— that is, there is no "jump" type statement required; the runtime handles this transfer automatically as needed.
The System.Exception class is the base class of all exceptions in the C# language. For example, the System.IO.IOException class is derived from System.Exception and collectively represents any of the things that can go wrong when performing IO operations; the System.IO.FileNotFoundException class is in turn a derived class of System.IO.IOException, and represents a specific IO problem.
By virtue of the "is a" nature of inheritance, a FileNotFoundException is also both an IOException and a generic Exception, all rolled into one, and so we can catch it as any one of these three exception types.
The catch clauses for a given try block are examined in order from top to bottom. The runtime compares the type of exception that has been thrown with the exception type declared to be caught for each catch clause until it finds a match—either an exact match or a match with a supertype—and then executes the code enclosed in the braces immediately following the matching catch clause; note that only the first such match is executed.
try {
// File IO operations are being performed here ... details omitted.
}
catch (FileNotFoundException e1) {
Console.WriteLine("FileNotFoundException detected!");
// Pseudocode.
recovery code would go here ...
}
catch (IOException e2) {
Console.WriteLine("IOException detected!");
// Pseudocode.
recovery code would go here ...
}
catch (Exception e3) {
// Note: "Exception" is the base class for all exception types, and hence
// a "catch (Exception e)" block is a "catch-all" for any exceptions that
// weren't a match for any of the preceding catch clauses.
Console.WriteLine("Exception detected!");
// Pseudocode.
recovery code would go here ...
}
Let's examine the output that would occur if various types of exceptions arise while the try block of this example is executing:
If a FileNotFoundException is thrown, this code would print the output:
FileNotFoundException detected!
If some other type of IOException is thrown while the try block is executing, this code would print the output:
IOException detected!
(Of course, catching an IOException could in theory take care of any FileNotFoundExceptions that arise, except for the fact that this catch clause occurs after an explicit catch of FileNotFoundException.)
And if any type of exception other than an IOException were to be thrown—say, a NullReferenceException—then the output would be
Exception detected!
Hence, the generic Exception type can be used in the last catch block of a try block (as shown in the preceding code) to literally serve as a "catch-all" if desired.
The preceding example illustrates the fact that catch blocks for derived types should precede catch blocks for base types; otherwise, the derived types' catch blocks will never get executed. For example, if we were to place an IOException catch block before a FileNotFoundException catch block as shown in the following code, any instances of FileNotFoundException would always be caught by the IOException catch block. We may have provided some really nifty exception-handling code in the FileNotFoundException catch block, but it will never get invoked.
try {
// File IO operations are being performed here ... details omitted.
}
catch (IOException e2) {
// This block will catch all types of IOExceptions, INCLUDING
// FileNotFoundExceptions specifically.
//Pseudocode.
recovery code for handling IOExceptions generally ...
}
catch (FileNotFoundException e1) {
// This block will never be executed because FileNotFoundException is a
// derived class of IOException.
//Pseudocode.
recovery code for handling FileNotFoundExceptions specifically ...
}
It's often necessary to nest one try statement within another, if the recovery code that we propose to execute in a catch block may itself be prone to generating exceptions.
For example, returning to our file IO example, let's assume that our application is going to require the user to provide the name of a file to be opened by interacting with the application's GUI. It's possible that the user-provided file name may be incorrect, such that the named file doesn't actually exist, in which case attempting to open the file will throw a FileNotFoundException. We decide to provide a default file behind the scenes, to be opened by our application in such an event.
// Pseudocode.
string filename = the name of a file provided by a user via a GUI;
try {
// Pseudocode.
attempt to open the filename file
}
catch (FileNotFoundException e1) {
// Since the user-provided filename is not valid, let's open a default
// file instead.
// Pseudocode.
attempt to open a file named "default.dat";
}
However, it's certainly possible that something may have happened to our default file—for example, it may have accidentally been deleted by a system administrator. So, to be completely rock-solid, we must also provide exception handling for code that attempts to open the default file; in the modified version that follows, we've nested an inner try–catch construct within the catch block of the outer try statement:
// Pseudocode.
string filename = the name of a file provided by a user via a GUI;
try {
// Pseudocode.
attempt to open the filename file
}
catch (FileNotFoundException e1) {
// Since the user's filename is not valid, let's open a default file instead.
try {
// Pseudocode.
attempt to open the file named "default.dat";
}
catch (IOException e2) {
// This code will execute if the default.dat cannot be opened, either.
Console.WriteLine("Unrecoverable error ...");
// etc.
} // end of inner try-catch
} // end of outer try-catch
Exception classes are like any other classes in that they define properties and methods with which to manipulate exception objects. As we've previously seen, a reference to the exception object being caught is included in the declaration of a catch clause. This reference is locally scoped to/available inside of the catch block, and provides us with a handle with which to call methods on or invoke properties of the exception object. For example, we may wish to access an exception's type-specific message via the Message property:
catch (IOException e) {
Console.WriteLine (e.Message);
}
In the preceding code snippet, an instance of the IOException class named e is declared in a catch clause. Inside the catch block, the Message property is invoked on reference variable e to write a message to the console explaining the nature of the exception; an example of such a message is
Could not find file "C:/MyDocs/default.dat"
In addition to the exception classes provided by the FCL, it's also possible in C# to declare user-defined, application-specific exception types by extending the System.Exception class or any of its derived classes. We then may explicitly instantiate and throw such exceptions to signal problems when they arise. This is analogous to shooting off a signal flare if you're lost in the wilderness and wish to call out for help! Defining and then subsequently throwing custom exception types is a popular technique for signaling that something has gone awry in an application.
As an example of creating a user-defined exception, let's define a class called InvalidStudentIdException, derived from the Exception class, to signal a problem when an attempt is made to instantiate a Student object with an invalid student ID. In deriving InvalidStudentIdException from Exception, we've added one feature—a field that represents the invalid student ID—and overridden the Message property in order to provide a class-specific message.
The code for our InvalidStudentIdException class is as follows:
// InvalidStudentIdException.cs
using System;
public class InvalidStudentIdException : Exception {
// Declare a field representing the student ID.
string id;
// A constructor that sets the value of the id field.
public InvalidStudentIdException(string id) {
this.id = id;
}
// A read-only property associated with the id field.
public string Id {
get {
return id;
}
}
// Override the Message property.
public override string Message {
get {
return "Error: Invalid student ID: "+ Id;
}
}
}
Next, we'll take advantage of our user-defined exception in the constructor of the Student class, to enforce the fact that we want a student's ID to be 11 characters long. (There are most likely other considerations that we'd also check, such as ensuring that the ID consists of only numeric characters and hyphens arranged in a certain sequence, but for this simple example we'll only test for the number of characters.) If the number of characters in the string passed as an argument to the Student constructor doesn't equal 11, we'll want the Student constructor to "send up a signal flare": i.e., to throw a new instance of an InvalidStudentIdException object using the throw keyword.
Here is the code listing of the Student class; once again, we've kept this example simple by having the Student class declare a single field named studentId and a single property to access this field.
// Student.cs
public class Student {
// Declare a field representing a student ID.
private string studentId;
// Property.
public string StudentId {
// Accessor details omitted.
}
// Constructor.
public Student(string id) {
// Test to see if the string passed to the constructor
// contains exactly 11 characters. If it doesn't, then
// we want to signal a problem by throwing an
// InvalidStudentIdException. Note that we pass in
// the value of the invalid id.
if (id.Length != 11) {
throw new InvalidStudentIdException(id);
// Execution of the constructor halts at this point, and control is
// transferred back to the client code that invoked the constructor.
}
// If we got this far in our constructor code, then the string passed
// to the constructor DOES contain 11 characters, and so we'll
// accept the proposed value.
StudentId = id;
} // end of constructor
}
We must now add the necessary exception-handling logic to our application to detect such exceptions. Because the Student constructor can now throw an InvalidStudentIdException, we place all client code logic for instantiating Student objects inside a try-catch block; the catch clause will specify the InvalidStudentIdException type.
In this first example, a valid 11-character string is passed to the Student constructor.
// Code is excerpted from an application's Main() method.
Student s;
try {
// Assign a valid student ID.
s = new Student("123-45-6789");
}
catch (InvalidStudentIdException ex) {
// Access our "customized" message.
Console.WriteLine(ex.Message);
// Create a student using a "dummy" id value instead.
s = new Student("???-??-????");
}
// Display the student's ID.
Console.WriteLine("Student ID = " + s.Id);
When this code snippet is run, an InvalidStudentIdException is not thrown, and so the output will be as follows:
Student ID = 123-45-6789
However, if we change the code snippet such that an invalid student ID is passed as an argument to the Student constructor:
Student s; try { s = new Student("123-45-"); // Oh-oh, an invalid student ID! } catch (InvalidStudentIdException ex) { // Access our "customized" message. Console.WriteLine(ex.Message); // Create a student using a "dummy" id value instead. s = new Student("???-??-????"); } // Display the student's ID. Console.WriteLine("Student ID = " + s.Id);
an InvalidStudentIdException is thrown, the catch block is executed, and the output is instead as follows:
Error: Invalid student ID: 123-45- Student ID = ???-??-????
| Note?/td> |
While we chose not to take advantage of user-defined exceptions in building the SRS, this is nonetheless an important technique to be aware of. |
Many programming languages support the notion of exception handling. In some of these languages—Java, for example—the compiler will mandate try statements in certain situations. That is, in Java, if we were to try to write the following logic without an enclosing try statement:
// Pseudocode. string filename = the name of a file provided by a user via a GUI; attempt to open the filename file;
the Java compiler would generate an error message forcing us to deal with the potential for an exception in some fashion.
In contrast, the C# compiler doesn't mandate exception handling; if we choose to write code such as that just shown in C#, it will indeed compile, but of course if an IOException arises at run time that we haven't provided recovery code for, the runtime will abruptly terminate the program's execution. So, while the use of try statements for code that can throw exceptions isn't mandatory in C#, inclusion of explicit exception-handling code is nonetheless highly desirable because it's the only mechanism with which to gracefully anticipate and handle run-time issues.