|
|
< Day Day Up > |
|
5.1. Characters and UnicodeOne of the watershed events in computing was the introduction of the ASCII 7-bit character set in 1968 as a standardized encoding scheme to uniquely identify alphanumeric characters and other common symbols. It was largely based on the Latin alphabet and contained 128 characters. The subsequent ANSI standard doubled the number of characters梡rimarily to include symbols for European alphabets and currencies. However, because it was still based on Latin characters, a number of incompatible encoding schemes sprang up to represent non-Latin alphabets such as the Greek and Arabic languages. Recognizing the need for a universal encoding scheme, an international consortium devised the Unicode specification. It is now a standard, accepted worldwide, that defines a unique number for every character "no matter what the platform, no matter what the program, no matter what the language."[1]
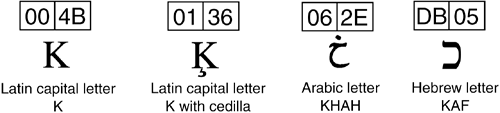
UnicodeNET fully supports the Unicode standard. Its internal representation of a character is an unsigned 16-bit number that conforms to the Unicode encoding scheme. Two bytes enable a character to represent up to 65,536 values. Figure 5-1 illustrates why two bytes are needed. Figure 5-1. Unicode memory layout of a character
The uppercase character on the left is a member of the Basic Latin character set that consists of the original 128 ASCII characters. Its decimal value of 75 can be depicted in 8 bits; the unneeded bits are set to zero. However, the other three characters have values that range from 310 (0x0136) to 56,609 (0xDB05), which can be represented by no less than two bytes. Unicode characters have a unique identifier made up of a name and value, referred to as a code point. The current version 4.0 defines identifiers for 96,382 characters. These characters are grouped in over 130 character sets that include language scripts, symbols for math, music, OCR, geometric shapes, Braille, and many other uses. Because 16 bits cannot represent the nearly 100,000 characters supported worldwide, more bytes are required for some character sets. The Unicode solution is a mechanism by which two sets of 16-bit units define a character. This pair of code units is known as a surrogate pair. Together, this high surrogate and low surrogate represent a single 32-bit abstract character into which characters are mapped. This approach supports over 1,000,000 characters. The surrogates are constructed from values that reside in a reserved area at the high end of the Unicode code space so that they are not mistaken for actual characters. As a developer, you can pretty much ignore the details of whether a character requires 16 or 32 bits because the .NET API and classes handle the underlying details of representing Unicode characters. One exception to this梔iscussed later in this section梠ccurs if you parse individual bytes in a stream and need to recognize the surrogates. For this, .NET provides a special object to iterate through the bytes. Core Note
Working with CharactersA single character is represented in .NET as a char (or Char) structure. The char structure defines a small set of members (see char in Chapter 2, "C# Language Fundamentals") that can be used to inspect and transform its value. Here is a brief review of some standard character operations. Assigning a Value to a Char TypeThe most obvious way to assign a value to a char variable is with a literal value. However, because a char value is represented internally as a number, you can also assign it a numeric value. Here are examples of each: string klm = "KLM"; byte b = 75; char k; // Different ways to assign 'K' to variable K k = 'K'; k = klm[0]; // Assign "K" from first value in klm k = (char) 75; // Cast decimal k = (char) b; // cast byte k = Convert.ToChar(75); // Converts value to a char Converting a Char Value to a Numeric ValueWhen a character is converted to a number, the result is the underlying Unicode (ordinal) value of the character. Casting is the most efficient way to do this, although Convert methods can also be used. In the special case where the char is a digit and you want to assign the linguistic value梤ather than the Unicode value梪se the static GetNumericValue method.
// '7' has Unicode value of 55
char k = '7';
int n = (int) k; // n = 55
n = (int) char.GetNumericValue(k); // n = 7
Characters and LocalizationOne of the most important features of .NET is the capability to automatically recognize and incorporate culture-specific rules of a language or country into an application. This process, known as localization, may affect how a date or number is formatted, which currency symbol appears in a report, or how string comparisons are carried out. In practical terms, localization means a single application would display the date May 9, 2004 as 9/5/2004 to a user in Paris, France and as 5/9/2004 to a user in Paris, Texas. The Common Language Runtime (CLR) automatically recognizes the local computer's culture and makes the adjustments. The .NET Framework provides more than a hundred culture names and identifiers that are used with the CultureInfo class to designate the language/country to be used with culture sensitive operations in a program. Although localization has a greater impact when working with strings, the Char.ToUpper method in this example is a useful way to demonstrate the concept.
// Include the System.Globalization namespace
// Using CultureInfo ?Azerbaijan
char i = 'i';
// Second parameter is false to use default culture settings
// associated with selected culture
CultureInfo myCI = new CultureInfo("az", false );
i = Char.ToUpper(i,myCI);
An overload of ToUpper() accepts a CultureInfo object that specifies the culture (language and country) to be used in executing the method. In this case, az stands for the Azeri language of the country Azerbaijan (more about this follows). When the Common Language Runtime sees the CultureInfo parameter, it takes into account any aspects of the culture that might affect the operation. When no parameter is provided, the CLR uses the system's default culture. Core Note
So why choose Azerbaijan, a small nation on the Caspian Sea, to demonstrate localization? Among all the countries in the world that use the Latin character set, only Azerbaijan and Turkey capitalize the letter i not with I (U+0049), but with an I that has a dot above it (U+0130). To ensure that ToUpper() performs this operation correctly, we must create an instance of the CultureInfo class with the Azeri culture name梤epresented by az梐nd pass it to the method. This results in the correct Unicode character梐nd a satisfied population of 8.3 million Azerbaijani. Characters and Their Unicode CategoriesThe Unicode Standard classifies Unicode characters into one of 30 categories. .NET provides a UnicodeCategory enumeration that represents each of these categories and a Char.GetUnicodecategory() method to return a character's category. Here is an example: Char k = 'K'; int iCat = (int) char.GetUnicodeCategory(k); // 0 Console.WriteLine(char.GetUnicodeCategory(k)); // UppercaseLetter char cr = (Char)13; iCat = (int) char.GetUnicodeCategory(cr); // 14 Console.WriteLine(char.GetUnicodeCategory(cr)); // Control The method correctly identifies K as an UppercaseLetter and the carriage return as a Control character. As an alternative to the unwieldy GetUnicodeCategory, char includes a set of static methods as a shortcut for identifying a character's Unicode category. They are nothing more than wrappers that return a TRue or false value based on an internal call to GetUnicodeCategory. Table 5-1 lists these methods.
Using these methods is straightforward. The main point of interest is that they have overloads that accept a single char parameter, or two parameters specifying a string and index to the character within the string.
Console.WriteLine(Char.IsSymbol('+')); // true
Console.WriteLine(Char.IsPunctuation('+')): // false
string str = "black magic";
Console.WriteLine(Char.IsWhiteSpace(str, 5)); // true
char p = '.';
Console.WriteLine(Char.IsPunctuation(p)); // true
Int iCat = (int) char.GetUnicodeCategory(p); // 24
Char p = '(';
Console.WriteLine(Char.IsPunctuation(p)); // true
int iCat = (int) char.GetUnicodeCategory(p); // 20
|
|
|
< Day Day Up > |
|