One awful thread-related bug I've faced was in a C++ ATL COM application shortly before.NET came out. Although my team and I never witnessed a problem when only a single user connected to the application, stress tests with a dozen simulated connections would often, but not always, cause a crash within a few hours. The logs indicated our crash never occurred in the same position twice, which implied memory corruption: writing off the bounds of an array or freeing memory early or something like that. (Aren't you glad developers no longer have to worry about those errors in.NET?) We suspected the problem was a race condition, but we couldn't be sure—since the bug took hours to appear even with a dozen threads, it was conceivable the problem might not be thread-related at all and could eventually happen with a single thread if we waited long enough.
| Tip |
Deadlocks are usually easy to recognize, but race conditions aren't always obvious. Just because some data in your multithreaded application became inconsistent doesn't necessarily mean threading was the culprit. Maybe your code has a simple logic error that occurs only once in a while. The bug might be a threading problem—but don't jump to conclusions. |
Try as we might, we never reproduced the bug in the debugger—in fact, even recompiling the code in Debug mode made the problem appear to go away. But that didn't prove anything. It might have indicated a threading problem that disappeared in Debug mode because the threads were switching in a different order. Or it might have indicated the bug had nothing to do with threading and was actually caused by differences between debug and release builds (for instance, an uninitialized variable—in Debug mode, Visual C++ initializes all variables to a default value, whereas Release mode doesn't). Or maybe the bug was something else and the fact it didn't happen in Debug mode was merely a coincidence. We didn't have enough data to be certain.
Various tools exist for analyzing C++ memory corruption problems. We tried them here, but unfortunately, none of them were able to identify this problem— presumably because of the same reasons we couldn't repro the bugs in the debugger. Normally, logging is a good approach for debugging problems like this, but since we didn't even know which objects and variables were responsible for the crash, we didn't know what to look for there, either. So after exhausting all other options, I finally resorted to removing huge sections of code and seeing if the bug still occurred: changing a long function to merely return a hard-coded value, cutting out code in the second half of a function, etc. I knew if the crash still occurred even after the removal of code, then that code wasn't the problem.
| Caution |
The difficulty with code removal is that you can't draw conclusions in the other direction. If you can't reproduce the bug after removing code, it doesn't necessarily prove the problem is in the code you took out. Maybe the bug lies in the remaining code, but is no longer manifesting itself because your code removal changed the order the threads switch in. |
So I gradually reduced our code down to a small loop that instantiated a few COM objects that called a simple method that immediately returned. After a lot more searching, I finally figured out the problem was in the ATL wizard–generated code, and truly hard-core COM programmers may be interested in the sidebar that follows to see what exactly the problem was. As it turns out, the bug was something that could never occur in.NET anyway, so this was purely a COM problem.
COM doesn't have automatic garbage collection like.NET does, so objects are deleted when a certain variable (called a refcount) is changed to zero. But that variable is just like any other—it can be subject to race conditions, and once that variable is messed up, the object can be deleted even while someone is using it. Our problem was caused by two threads calling AddRef and Release on the same object at the same time, because then the refcount got corrupted. But we thought we wouldn't have to worry about this problem since the wizard-generated ATL code should have automatically handled multithreading, right?
Actually, not quite. Here's the geeky, low-level details: The wizard-generated code made use of a helper class called CComObjectThreadModel. If you look at the definition, you see that's a C typedef for an object called CComMultiThreadModel, which handles multiple threads just fine. However, we failed to notice that if a certain preprocessor directive isn't set, then the typedef instead evaluates to something called CComSingleThreadModel. Explaining what those terms mean is well beyond the scope of this book, but it doesn't take an Einstein to realize that CComSingleThreadModel shouldn't be used in a multithreaded world. We didn't realize our compiler settings were missing that preprocessor directive, and that's what caused our race condition crash.
Now aren't you glad that.NET means never having to deal with memory management nonsense like that again? Things are so much easier now! But for those of you who worked in COM and remember CComObjectThreadModel and Single Threaded Apartments (STAs), it's interesting to see the legacy still continues into.NET. Use the Windows Application Wizard to generate a C# project and look at the attribute above the Main function: [STAThread]. We like to think that.NET was a fresh new start free from the legacy code baggage, and for the most part it was—but every now and then, something sneaks through.
By the way, if you don't know what a Single Threaded Apartment or an [STAThread] attribute is, then don't worry. As long as you're not dealing with COM components, then everything will automatically work fine regardless of whether that attribute is present or not.
There's a reason I picked this pre- .NET thread example rather than a more recent example. Even though .NET is immune to the specific cause of this crash, the fact remains that .NET still allows multithreaded bugs that are just as difficult to track down as they were pre- .NET. All the techniques I used to try to debug this multithreaded problem with COM are still relevant in .NET. Some parts of debugging have improved greatly since .NET was released. Debugging threads, however, is unfortunately not one of them.
As the preceding example shows, race conditions can be very difficult to solve. The key is to remember that all race conditions are caused when one thread tries to modify a variable while another thread is using it—both threads should have acquired some sort of lock before touching the variable, but clearly someone neglected to do that. To solve the bug, you must figure out which threads are involved. Sadly, there's no quick-and-easy way to do this, but there are two strategies that work better than most anything else: using the thread debugging window to control the order your threads run in, and using logging to see what each thread is doing at any given time.
Once you know which threads are involved in a race condition, you can begin looking for the variable that isn't protected by a lock, and once you know that, the rest is easy. But if the bug only appears sporadically, how can you force the system to make the bug appear? How can you make the threads run in a predictable fashion so you can verify theories? Suppose you want to see what happens if one thread yields control in a certain spot—how can you test this? There's only one way to gain complete control over which threads run and which threads sleep: Use the thread debugging window.
Manually controlling the execution of each thread is tedious, but it gets the job done. Set a breakpoint on the code that starts each new thread and run the program. As each new thread is started, freeze it with the thread debugging window. Now you control how the threads run. Select the thread you care about, and use the debugger to run that thread for as long as you like. Once it reaches a spot that seems tricky (such as just before it's about to acquire some lock or modify some variable), freeze that thread and start another. You control exactly when each threads switches, so you can theoretically reproduce any possible race condition or deadlock that your code contains.
One time I had to debug a program in which a certain variable became corrupted—we suspected a race condition where some code somewhere modified the variable without first acquiring the lock. Now how to prove that? At first I thought I could simply search for all the places where that variable was used to see if they were lock protected. But that didn't work because many of those places had deliberately not been lock protected under the theory that the calling function would already hold the lock. So instead, I froze all threads but one, ran that one thread to the point where it acquired the lock, and then froze the thread. Next I set a conditional breakpoint to alert me when the variable changed, unfroze all the other threads, and waited. Soon, my conditional breakpoint fired—but since I knew that should have been impossible when my frozen thread held the lock protecting the variable, I had my answer.
Using the thread debugging window to control the ordering of threads is great when you have a theory you want to test or when you want to run a random experiment in hopes of getting more data. But even though it lets you run the threads in whatever order you want, it doesn't advise you on what that order should be. You're on your own for that part. Still, if nothing else, this technique allows you to debug your program as if it were single threaded, and step across each line of code one at a time. Never underestimate the power of that.
Any decent developer is familiar with breakpoints, but many developers aren't so familiar with conditional breakpoints. Which is a shame, because conditional breakpoints are amazingly powerful. Have you ever encountered a bug that occurred only the 100th time a certain loop ran? You want to set a breakpoint on the relevant line of code, but you don't want to have to hit the Continue button 100 times. Conditional breakpoints solve this—you can set the breakpoint to fire only on the nth time that line of code is reached. Even more interesting is the concept of a breakpoint that fires only when a certain condition is true. Suppose you want to be alerted when x > y. A conditional breakpoint can be created to alert you to that case, too.
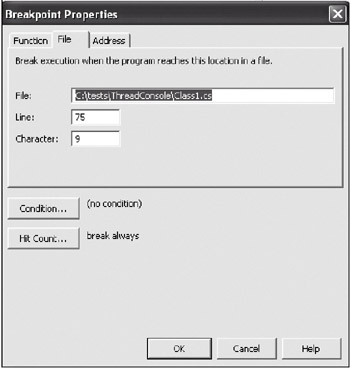
To set a conditional breakpoint, first set a regular breakpoint on the line you want. Then go to the Debug menu item, select Windows, then Breakpoints. Highlight the breakpoint you just set, right-click and select Properties. Finally, you'll see the dialog box displayed in Figure 8-2. Use the Condition and Hit count buttons to make your conditional breakpoint behave the way you want.
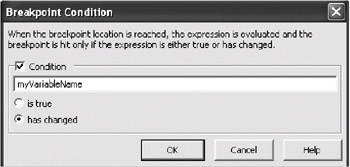
There's one final type of conditional breakpoint: fire whenever a variable changes. This is an extremely useful tool—hundreds of bugs could easily be solved if only we knew when a particular variable was being unexpectedly modified. Unfortunately, C# took a minor step backwards with this breakpoint type. In C++, you can use the Data tab of the breakpoints window, and the breakpoint will fire whenever the variable changes—you don't have to specify a line for the breakpoint to go on because the breakpoint will just stop on whatever line is appropriate. Unfortunately, the Data tab doesn't work in C#. However, you can simulate it. Set a conditional breakpoint, and for the condition, select the "has changed" option as shown in Figure 8-3.
The only problem with this approach is that you need to specify a particular line on which to stop, and if you knew the line that this variable was being changed on, then you wouldn't be fiddling with this conditional breakpoint. But there's a simple solution—set the breakpoint to stop on some other line that has nothing to do with this variable. You need to choose a line that will get hit, but it doesn't matter what the line does. The downside is that the breakpoint will be fired not immediately after the variable changes, but only on the first time this line is hit after the variable changes. But if you sprinkle several of these conditional breakpoints on different lines in your code, you should be able to quickly narrow down to the area, and eventually to the exact line of code that's changing your variable.
Product logging seems low tech compared to VS .NET's advanced debugger, but it often succeeds where the debugger can't. Logging is a great way to track down race conditions and understand the order threads are running in. Frequently, you'll notice variables with inconsistent values and you'll want to know how the threads switched to create that situation. The debugger won't be able to tell you since it slows the code down too much to reproduce the issue. But with a bunch of debug-only log statements, you can see when two threads are overlapping when they shouldn't.
Thread #2 about to read x Thread #1 about to modify x Thread #3 about to modify y Thread #1 finished with x Thread #3 finished with y Thread #2 finished with x
Reading logs like that may take some concentration, but it does reveal that thread #2 is reading x at the same time thread #1 is writing it. That shouldn't be possible—thread #2 ought to acquire a lock before reading x so that thread #1 can't get in until #2 has finished, and this is probably the key to your race condition. Anytime you see overlap of two threads with the same variable, then you should investigate because it usually means you need additional synchronization.
| Note |
Experienced developers may worry that logging in a multithreaded application may result in two threads writing to the same log at the same time with unreadable results: "ThreThread1ad2 doing wdoing ork work". No worries—the Trace.WriteLine method discussed in Chapter 5 is smart enough to avoid such problems. |
Of course, that type of logging produces hundreds of lines that get in the way when you're hunting down other bugs. Remember log levels from Chapter 5? Situations like this might be a good place to employ those so you can easily turn the multithreaded logging on and off. Alternatively, some developers prefer to add those log statements only in the debug builds as they're needed and remove them once the bug is fixed. I'd recommend the former approach, but the choice is up to you.
It's a fundamental rule of threading (and probably coding in general) that you can always trade performance for safety and vice versa. If you create a lock for every single variable in your project and consistently acquire that lock before each use of the variable, you're guaranteed no race condition will ever occur. On the other hand, that also adds a lot of overhead that will reduce your application's performance. You need to decide how aggressive you want to be in the trade-off between performance and safety.
Suppose you have a variable that you believe no two threads will ever simultaneously use. Should you wrap that variable in a lock? Yes, if you want to optimize for safety. Maybe somebody will add a new reference to that variable tomorrow so that it is used by two threads. Locking that variable may not be necessary, but it guarantees you won't have any race condition headaches later on. But if you want to optimize for performance, then you wouldn't lock that variable unless some other thread used it. Unnecessary locking will force additional overhead on your project.
In this day of ultra-fast processors, most applications are better safe than sorry, so most developers would be better off locking everything that could possibly be even remotely relevant. The performance penalty is fairly negligible, and it sure beats having to spend a week tracking down a bug.
The hardest part of debugging deadlocks is just getting them to happen. Many is the time I watched my multithreaded program run flawlessly 100 times, and then deadlock on the 101st time. But once you see that deadlock, discovering the culprit is easy. As soon as you realize some of the threads seem blocked, attach a debugger to the process and bring up the threads window. Use the threads window to switch to each thread and see which lock it's hung on. Then look at the other threads to determine which of those is holding the necessary lock and why it can't proceed. Once you've identified the relevant locks, then rewriting your code should be straightforward.
| Caution |
A bug in VS.NET makes this harder than it should be. When a thread is waiting on a lock, the VS .NET debugger may indicate the thread is actually running the line after the lock statement. Figure 8.4 shows some code that is waiting on a lock, yet the debugger makes it look like the code has already passed that point. By pushing the Step Next button, you can tell whether the code is truly past the lock or not. |
In Figure 8-4, the source of the deadlock is obvious: This thread holds the o2 lock and is waiting on the o lock, but another thread holds the o lock and is waiting on o2. It's not always that easy, though. Often, a lock was acquired not in the function you're looking at, but in the function that called the function that called the function you're looking at. You may need to traverse up the stack of each thread to see all the locks the thread is holding.
Once you've identified the relevant locks, what's the best way to fix the problem? Better yet, how can you write your code so that deadlocks never occur in the first place? That depends on the situation. But there are a few classic rules for avoiding deadlocks, and you should make sure your code follows at least one of them.
Always acquire locks in the same order.
Use only one lock.
Use multiple-reader, single-writer locks.
All the deadlock examples we've seen in this chapter have involved one thread acquiring two locks in the order A-B, while another thread acquires the locks in the order B-A. That lets both threads get hung waiting on the other.
class LockOrderTest {
static LockOrderTest A = new LockOrderTest();
static LockOrderTest B = new LockOrderTest();
//First thread runs this function
static void FirstThread() {
//Acquire locks in the order A-B
lock(A) {
lock(B) {
...
}
}
}
//Second thread runs this function
static void SecondThread() {
//Acquire locks in the order B-A
lock(B) {
lock(A) {
...
}
}
}
}
But suppose both threads acquired the locks in the order A-B? Suppose we left the FirstThread function as-is and rewrote the SecondThread function to be
static void SecondThread() {
lock(A) {
lock(B) {
...
}
}
}
Then one thread or the other would get the A lock, and the second thread would wait since the A lock was unavailable. But now nothing is blocking the first thread from also acquiring the B lock, doing its business, and then releasing both locks. As long as you're careful to always acquire all locks in the same order, then it's impossible to ever have a deadlock, no matter how many threads and locks are involved.
The main downside to this method is that it's sometimes hard to control. In sample code, all the locks are acquired in a single method, and in those cases, acquiring locks in the same order is easy. But suppose the process of acquiring locks is spread out over several methods? Function A acquires lock 1, function B acquires lock 2, and so on. You may have some difficulty keeping track of which functions call which other functions and which ones acquire which locks. As a result, you may plan to acquire locks in the order 1-2-3-4, but you might forget that a function that acquires lock 3 makes a call to a function that acquires lock 2. Always acquiring locks in the same order can solve the deadlock problem, but only if you're careful.
With normal bugs, you can see code that looks suspicious, change it without quite fully understanding why it's causing the problem, and sometimes get lucky. This isn't the same thing as randomly moving code around hoping the bug magically disappears. What I'm talking about here involves finding and fixing a legitimate problem and then testing to see if that change might have made the original problem you were hunting go away, even though you don't see an obvious connection—for instance, "Whoa, that variable shouldn't be initialized to zero. I'm not sure how that could cause the crash I'm trying to solve, but since I need to fix this variable's initialization anyway, let me do that and then see if the crash goes away."
You can't do that with threading bugs, though. Slight, meaningless changes in the code may make the threads switch in a different order, and then maybe the threading bug will appear to be gone on your machine. But it's actually still there and will reappear on a computer that switches the threads slightly faster or slower. When you're experiencing a threading bug, don't change anything in your code unless you can tell yourself a convincing story about why the thing you're changing was causing the threading problem. If you don't follow this advice, then your change may destroy your ability to reproduce the bug, and then you'll be lulled into the false belief that the bug is fixed when it's really not.
This idea is so obvious that many developers never even seriously consider it, but one extremely manageable way to eliminate deadlocks is to use only a single lock in your program. If there's only one lock, then any thread that acquires the lock is guaranteed to eventually finish its business and release the lock, which allows some other thread to grab it. There is no possible way a deadlock can ever occur in this situation.
| Tip |
Of course, the thread with the lock might conceivably have an infinite loop that prevents it from ever finishing, and then the lock will never be released. For instance, while(x != 0) {x=1;} will never terminate. But you'd have that exact same bug even in a single-threaded program, so it's not an argument against multithreading. Just be careful not to write infinitely looping code. |
This idea is far more practical than you might at first think. You never need more than one lock to guarantee proper thread synchronization; in fact, a single lock makes the development substantially easier because there are fewer things for you to track. One of the most successful multithreaded programs I've ever been involved with made use of exactly one lock, and this decision was a big part of that success. The strategy of having only a single lock is so simple that many developers may reject it, but it deserves serious, serious consideration.
The one drawback to using a single lock is that it limits the amount of multi-threading that can take place. To get the absolute maximum amount of multithreading, you would have a different lock for every single variable that the threads access. Under that approach, a dozen threads could simultaneously modify a dozen unrelated variables protected by a dozen different locks, and there would be no problem as long as no two threads tried to modify the same variable. By contrast, under the single lock approach, only one of those dozen threads could modify any variable at any given time. In the absolute worst case, a single-lock application would essentially behave almost as if it were single threaded because no two threads would ever be able to run simultaneously.
Will that worst case come about very often? It depends on your application, but usually not. If you need absolute maximum performance, then a single lock may not be the way to go. But for "good-enough" performance, single locks will very often suffice; and they'll definitely shorten your debugging cycle.
So far in this chapter, we've exclusively discussed only the lock and SyncLock methods of thread synchronization because they're the easiest. But these methods aren't as powerful as some of the other synchronization techniques. In particular, the lock and SyncLock statements allow only a single thread to access code at a time, and that may be more restrictive than you need. Many times, it's actually perfectly fine to let multiple threads access the same variable at once. But in order to do it safely, you need to use a different synchronization technique.
Think back to our example of a race condition. Two threads simultaneously ran the following code:
using System.Threading;
class MyTestClass {
public static int x = 0;
public static void DoUselessStuff() {
while (true) {
int m = x;
x++;
System.Diagnostics.Debug.Assert ( m + 1 == x );
}
}
public static void Main() {
Thread t1 = new Thread(new ThreadStart(DoUselessStuff));
Thread t2 = new Thread(new ThreadStart(DoUselessStuff));
t1.Start();
t2.Start();
}
}
This created a race condition because it let one thread write to the x variable while the other thread read from it, and that allowed one thread to work with a stale copy of the variable. But what would have happened if both threads had merely read the x variable, without writing to it? Would there have been a problem? No. As long as both threads are read-only, then the x variable never gets out of date, and there's no race condition. For truly read-only variables, you don't need synchronization at all! In fact, synchronization actually hurts in that situation, partly because it reduces the number of threads that can run simultaneously and also because the unnecessary locks provide one more opportunity for a deadlock.
Well, knowing that synchronization isn't necessary for read-only variables doesn't help us much because most real-world variables aren't read-only. However, most of them are read far more often than they're written, and we can use a different type of synchronization to take advantage of that. Recall that a standard lock allows access to only one thread at a time, but .NET also provides System.Threading.ReaderWriterLock, which allows access to an arbitrary number of threads simultaneously, but only if they are read-only. A thread that wants to write must wait for all current read-only threads to release their lock (no new reading threads will be allowed in while a thread is waiting for a write lock), and then that thread will have the variable to itself.
using System.Threading;
class ReaderWriterTest {
private ReaderWriterLock rwLock = new ReaderWriterLock();
private int x = 0;
//Any number of threads could be in this function at once
void Func1() {
rwLock.AcquireReaderLock(0);
...//Do read-only stuff with x
rwLock.ReleaseReaderLock();
}
//only one thread can get in this function at a time
void Func2() {
rwLock.AcquireWriterLock(0);
x++;
rwLock.ReleaseWriterLock();
}
}
| Caution |
Be sure to manually release the lock by calling the appropriate ReleaseLock function. If you don't do this, then deadlocks will surely happen because.NET doesn't automatically release the lock. One good practice is to use try/catch/finally blocks and release your lock in the finally clause—that will protect against deadlocks due to a thrown exception. |
The downside of ReaderWriterLock is that it's not automatic. You have to manually release the lock when you're done. On the other hand, it does provide two big advantages. The first is performance related—multiple threads don't do any good if most of the threads are waiting at any given time, and the ReaderWriterLock allows multiple read-only threads to proceed at once. Under the right circumstances, that can yield much better performance than a standard lock.
The other advantage of ReaderWriterLock is that it reduces (but doesn't completely eliminate) the likelihood of a deadlock. Any thread that acquires the reader lock could potentially cause a deadlock with a thread waiting for a writer lock— that's no better and no worse than a standard lock. But at least two reader threads can no longer deadlock each other, and that should reduce the number of opportunities for disaster. You'll still accidentally code a deadlock now and then, but the law of averages says it'll happen less often.
The ReaderWriterLock can entirely prevent deadlocks, although not for the reason you might expect. A feature of this lock class (and several other types of synchronization) is the timeout. A deadlock occurs when one thread waits forever on another thread. But by using a timeout, you can ensure each thread gives up after a reasonable period.
What your application does after giving up is up to you. You certainly shouldn't continue running the code, so you might display a debugging error message warning about the deadlock, or maybe you'll throw an exception, or perhaps you'll write code to explicitly kill the other thread that is blocking this one. Whatever you want. The point is that your thread doesn't have to wait forever—it can realize it's hung and then take charge of its destiny.
To set a timeout, just pass in the number of milliseconds you want to wait on to the AcquireReaderLock or AcquireWriterLock methods. Zero means there is no timeout, and any other value is the number of milliseconds long the timeout should be. But be careful to make sure your timeout is appropriately long! Depending on how much work your other threads are doing, it may be the case that it's normal for one thread to occasionally wait, say, 30 seconds, so any timeout below that value would cause a bug.