| [ Team LiB ] |
|
5.1 What Is the DOM?The DOM is an interface for manipulating XML content, structure, and style in an object-oriented fashion. It provides a standardized way of manipulating XML documents, including accessing elements and other nodes, taking actions on an object tree based on events, applying styles to documents, loading documents into object trees and saving object trees to documents, and more. The DOM is language- and platform-neutral, meaning that it can be applied to any programming language on any hardware platform or operating system. Since its start in 1997, the DOM Working Group has made it a specific goal to ensure the DOM's language- and platform-neutrality. They've been successful; you can easily find a DOM implementation in just about any modern programming language, on any modern hardware platform. The DOM represents an XML document as a tree of objects. Each object in the tree is called a node. The types of nodes that the DOM specifies are Document, DocumentFragment, DocumentType, EntityReference, Element, Attr, ProcessingInstruction, Comment, Text, CDATASection, Entity, and Notation. Some of these node types can have subnodes, and the types of subnodes that a particular node type can have are specified. To handle collections of nodes, the DOM also specifies a NodeList object and, for dictionaries of nodes (keyed by their names), the NamedNodeMap object. Figure 5-1 shows the DOM inheritance hierarchy. Figure 5-1. The DOM inheritance hierarchy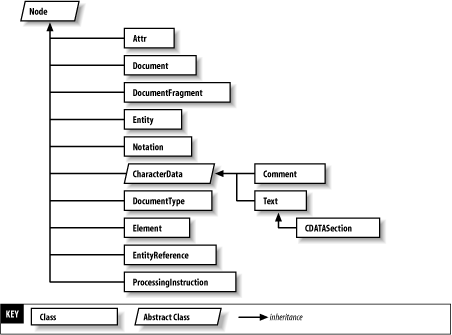 The DOM specifies a group of interfaces, not actual objects. This means that the implementation of the objects is not mandated, only the methods that must be accessible from a client of the DOM. Because the objects are specified by their interfaces, they cannot be created with traditional constructors; instead, factory methods are commonly used. The DOM also specifies a number of lower-level types, such as DOMString and DOMTimeStamp. These are used internally in the DOM recommendation, but particular language bindings are free to use their own native formats for these types. In C#, these are string and DateTime, respectively. 5.1.1 A Brief Introduction to the DOM SpecificationThe DOM architecture is divided into several modules. Although there is no real meaning to the term, a module of the DOM can be thought of simply as a group of related functionality. The modules as defined by the W3C DOM Working Group are:
In addition, the DOM Working Group has defined several levels of functionality. The requirements for each level are formally documented by the W3C at http://www.w3.org/DOM/DOMTR.
5.1.2 When to Use the DOMBecause the DOM represents an XML document as a tree in memory, it is best used for small documents or documents for which the memory footprint is known in advance, and when the application needs to manipulate the document's structure rather than just reading in the XML data. One thing to keep in mind if you are considering using the DOM is that the entire document must be read into memory before any of it is available for use. This differs from the read-only, forward-only model of XmlReader, which allows you to read a single node at a time, and thus gives you the ability to deal with very large XML documents efficiently. For this reason, the DOM is also appropriate when you need to access XML elements or attributes non-sequentially. The entire document is resident in memory, so searching for a particular node does not require disk access. |
| [ Team LiB ] |
|
