The .NET Framework is a platform for building and running applications. Its chief components are the common language runtime (CLR, or simply 鈥渢he runtime鈥? and the .NET Framework class library (FCL). The CLR abstracts operating system services and serves as an execution engine for managed applications鈥?/span>applications whose every action is subject to approval by the CLR. The FCL provides the object-oriented API that managed applications write to. When you write .NET Framework applications, you leave behind the Windows API, MFC, ATL, COM, and other tools and technologies you鈥檙e familiar with, and you use the FCL instead. Sure, you can call a Windows API function or a COM object if you want to, but you don鈥檛 want to because doing so requires transitioning from managed code (code run by the CLR) to unmanaged code (native machine code that runs without the runtime鈥檚 help). Such transitions impede performance and can even be vetoed by a system administrator.
Microsoft .NET is chiefly about XML Web services, but the .NET Framework supports other programming models as well. In addition to writing Web services, you can write console applications, GUI applications (鈥淲indows Forms鈥?, Web applications (鈥淲eb Forms鈥?, and even Windows services, better known as NT services. The framework also helps you consume Web services鈥攖hat is, write Web service clients. Applications built on the .NET Framework are not, however, required to use Web services.
Next to XML Web services, the portion of the framework with the greatest potential to change the world is ASP.NET. The name comes from Active Server Pages (ASP), which revolutionized Web programming in the 1990s by providing an easy-to-use model for dynamically producing HTML content on Web servers using server-side script. ASP.NET is the next version of ASP, and it provides a compelling new way to write Web applications that鈥檚 unlike anything that has preceded it. Because ASP.NET is such an important part of the framework, and because the number one question asked by developers in the software industry today is 鈥淗ow do I write applications that run on the Web?,鈥?a large portion of this book鈥攁ll of Part 2, in fact鈥攊s devoted to it.
But first things first. The key to understanding the .NET Framework and the various programming models it supports is to understand the common language runtime and the FCL. The next several sections discuss both and introduce other important concepts that are vital for learning how to write Web services and other managed applications.
If the .NET Framework were a living, breathing human being, the common language runtime would be its heart and soul. Every byte of code that you write for the framework either runs in the CLR or is given permission by the CLR to run outside the CLR. Nothing happens without the CLR鈥檚 involvement.
The CLR sits atop the operating system and provides a virtual environment for hosting managed applications. When you run a managed executable, the CLR loads the module containing the executable and executes the code inside it. Code that targets the CLR is called managed code, and it consists of instructions written in a pseudo-machine language called common intermediate language, or CIL. CIL instructions are just-in-time (JIT) compiled into native machine code (typically x86 code) at run time. In most cases, a given method is JIT compiled only one time鈥攖he first time it鈥檚 called鈥攁nd thereafter cached in memory so that it can be executed again without delay. Code that isn鈥檛 called is never JIT compiled. While JIT compilation undeniably impacts performance, its negative effects are mitigated by the fact that a method is compiled only once during the application鈥檚 lifetime and also by the fact that the CLR team at Microsoft has gone to extraordinary lengths to make the JIT compiler as fast and efficient as possible. In theory, JIT compiled code can outperform ordinary code because the JIT compiler can optimize the native code that it generates for the particular version of the host processor that it finds itself running on. JIT compiled code is not the same as interpreted code; don鈥檛 let anyone tell you otherwise.
The benefits of running code in the managed environment of the CLR are legion. For starters, as the JIT compiler converts CIL instructions into native code, it enacts a code verification process that ensures the code is type safe. It鈥檚 practically impossible to execute an instruction that accesses memory that the instruction isn鈥檛 authorized to access. You鈥檒l never have problems with stray pointers in a managed application because the CLR throws an exception before the stray pointer is used. You can鈥檛 cast a type to something it鈥檚 not because that operation isn鈥檛 type safe. And you can鈥檛 call a method with a malformed stack frame because the CLR simply won鈥檛 allow it to happen. In addition to eliminating some of the most common bugs that afflict application programs, code verification security makes it eminently more difficult to write malicious code that intentionally inflicts harm on the host system. In the unlikely event that you don鈥檛 want code verification security, you can have it turned off by a system administrator.
Code verification security is also the chief enabling technology behind the CLR鈥檚 ability to host multiple applications in a single process鈥攁 feat of magic that it works by dividing the process into virtualized compartments called application domains. Windows isolates applications from one another by hosting them in separate processes. An unfortunate side effect of the one-process-per-application model is higher memory consumption. Memory efficiency isn鈥檛 vital on a stand-alone system that serves one user, but it鈥檚 paramount on servers set up to handle thousands of users at once. In certain cases (ASP.NET applications and Web services being the prime examples), the CLR doesn鈥檛 launch a new process for every application; instead, it launches one process or a handful of processes and hosts individual applications in application domains. Application domains are secure like processes because they form boundaries that managed applications can鈥檛 violate. But application domains are more efficient than processes because one process can host multiple application domains and because libraries can be loaded into application domains and shared by all occupants.
Another benefit of running in a managed environment comes from the fact that resources allocated by managed code are garbage collected. In other words, you allocate memory, but you don鈥檛 free it; the system frees it for you. The CLR includes a sophisticated garbage collector that tracks references to the objects your code creates and destroys those objects when the memory they occupy is needed elsewhere. The precise algorithms employed by the garbage collector are beyond the scope of this book, but they are documented in detail in Jeffrey Richter鈥檚 book Applied Microsoft .NET Framework Programming (Microsoft Press, 2002).
Thanks to the garbage collector, applications that consist solely of managed code don鈥檛 leak memory. Garbage collection even improves performance because the memory allocation algorithm employed by the CLR is fast鈥攎uch faster than the equivalent memory allocation routines in the C runtime. The downside is that when a collection does occur, everything else in that process stops momentarily. Fortunately, garbage collections occur relatively infrequently, dramatically lessening their impact on performance.
Yet another benefit of running applications in a CLR-hosted environment is that all code reduces to CIL, so the programming language that you choose is little more than a lifestyle choice. The 鈥渃ommon鈥?in common language runtime alludes to the fact that the CLR is language-agnostic. In other environments, the language you use to implement an application inevitably affects the application鈥檚 design and operation. Code written in Visual Basic 6, for example, can鈥檛 easily spawn threads. To make matters worse, modern programming languages such as Visual Basic and Visual C++ use vastly different APIs, meaning that the knowledge you gain programming Windows with Visual Basic is only marginally helpful if your boss asks you to write a DLL in C++.
With the .NET Framework, all that changes. A language is merely a syntactic device for producing CIL, and with very few exceptions, anything you can do in one language, you can do in all the others, too. Moreover, regardless of what language they鈥檙e written in, all managed applications use the same API: that of the .NET Framework class library. Porting a Visual Basic 6 application to Visual C++ is only slightly easier than rewriting the application from scratch. But porting a Visual Basic .NET application to C# (or vice versa) is much more reasonable. In the past, language conversion tools have been so imperfect as to be practically useless. In the era of the .NET Framework, someone might write a language converter that really works. Because high-level code ultimately compiles to CIL, the framework even lets you write a class in one language and use it (or derive from it) in another. Now that鈥檚 language independence!
Microsoft provides CIL compilers for five languages: C#, J#, C++, Visual Basic, and JScript. The .NET Framework Software Development Kit (SDK) even includes a CIL assembler called ILASM, so you can write code in raw CIL if you want to. Third parties provide compilers for other languages, including Perl, Python, Eiffel, and, yes, even COBOL. No matter what language you鈥檙e most comfortable with, chances are there鈥檚 a CIL compiler that supports it. And you can sleep better knowing that even if you prefer COBOL, you can do almost anything those snobby C# programmers can do. That, of course, won鈥檛 prevent them from ribbing you for being a COBOL person, but that鈥檚 another story.
When you build a program with the C# compiler, the Visual Basic .NET compiler, or any other compiler capable of generating CIL, the compiler produces a managed module. A managed module is simply an executable designed to be run by the CLR. It typically, but not always, has the file name extension EXE, DLL, or NETMODULE. Inside a managed module are four important elements:
-
A Windows Portable Executable (PE) file header
-
A CLR header containing important information about the module, such as the location of its CIL and metadata
-
Metadata describing everything inside the module and its external dependencies
-
The CIL instructions generated from the source code
Every managed module contains metadata describing the module鈥檚 contents. Metadata is not optional; every CLR-compliant compiler must produce it. That鈥檚 important, because it means every managed module is self-describing. Think about it this way. If someone hands you an ordinary EXE or DLL today, can you easily crack it open and figure out what classes are inside and what members those classes contain? No way! If it鈥檚 a managed module, however, no problem. Metadata is like a COM type library, but with two important differences:
-
Type libraries are optional; metadata is not
-
Metadata fully describes a module; type libraries sometimes do not
Metadata is important because the CLR must be able to determine what types are present in each managed module that it loads. But it鈥檚 also important to compilers and other tools that deal with managed executables. Thanks to metadata, Visual Studio .NET can display a context-sensitive list of the methods and properties available when you type the name of a class instance into the program editor, a feature known as IntelliSense. And thanks to metadata, the C# compiler can look inside a DLL containing a class written in Visual Basic .NET and use it as the base class for a derived class written in C#.
A module鈥檚 core metadata is stored in a collection of tables. One table, the TypeDef table, lists all the types defined in the module. (鈥淭ype鈥?is a generic term for classes, structs, enumerations, and other forms of data understood by the CLR.) Another table lists the methods implemented by those types, another lists the fields, another lists the properties, and so on. By reading these tables, it鈥檚 possible to enumerate all the data types defined in the module as well as the members each type includes. Additional tables list external type references (types and type members in other modules that are used by this module), the assemblies containing the external types, and more.
Additional metadata information is stored outside the tables in heaps containing items referenced by table entries. For example, class names and method names are stored in the string heap; string literals are stored in a separate heap called the user-string heap. Together, metadata tables and heaps define everything you (or the CLR) could possibly want to know about a module鈥檚 contents and external dependencies.
The portion of a managed module that holds the module鈥檚 CIL is sprinkled with metadata tokens that refer to entries in the metadata tables. Each row in each table is identified by a 32-bit metadata token consisting of an 8-bit table index and a 24-bit row index. When a compiler emits the CIL for a method, it also emits a metadata token identifying the row containing information about the method. When the CLR encounters the token, it can consult the table to discover the method鈥檚 name, visibility, signature, and even its address in memory.
The metadata format is interesting from an academic point of view, but it鈥檚 rare that an application developer finds use for such knowledge. Most applications don鈥檛 manipulate metadata directly; they leave that to the CLR and to compilers. Applications that need to read and write metadata can do so by using either of two APIs provided by the .NET Framework. Called the reflection APIs, these APIs insulate the developer from the binary metadata format. One is an unmanaged API exposed through COM interfaces. The other is a managed API exposed through classes in the FCL鈥檚 System.Reflection namespace.
Using the reflection APIs to write a tool that lists the types and type members in a managed module is relatively easy. But if inspecting metadata is your goal, you don鈥檛 have to write a tool because the .NET Framework SDK has one already. Called ILDASM, it uses reflection to reveal the contents of managed executables. Figure 1-1 shows ILDASM displaying ImageView.exe, one of the sample programs in Chapter 4. The tree depicts the one class defined in the module (MyForm) and all the members of that class. But here鈥檚 the cool part. If you start ILDASM with a /ADV (for 鈥淎dvanced鈥? switch and select the View/MetaInfo/Show command (or press Ctrl+M, which works regardless of whether you started ILDASM with a /ADV switch), a window pops up detailing all the rows in all the metadata tables (Figure 1-2). By checking and unchecking items in the View/MetaInfo menu, you can configure ILDASM to display metadata in different ways.
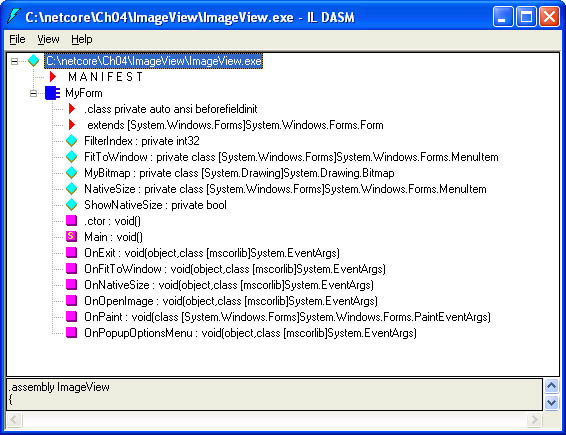 Figure 1-1
Figure 1-1
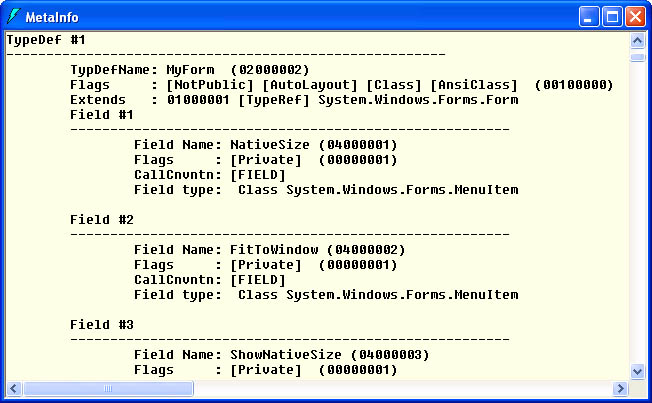 Figure 1-2
Figure 1-2
CIL is often described as a pseudo-assembly language because it defines a native instruction set for a processor. In this case, however, the processor is the CLR, not a piece of silicon. You don鈥檛 have to know CIL to program the .NET Framework any more than you have to know x86 assembly language to program Windows. But a rudimentary knowledge of CIL can really pay off when a method in the FCL doesn鈥檛 behave the way you expect it to and you want to know why. You don鈥檛 have the source code for the FCL, but you do have the CIL.
In all, CIL includes about 100 different instructions. Some are the typical low-level instructions found in silicon instruction sets, like instructions to add two values together (ADD) and to branch if two values are equal (BEQ). Other instructions work at a higher level and are atypical of those found in hardware instruction sets. For example, NEWOBJ instantiates an object, and THROW throws an exception. Because the CIL instruction set is so rich, code written in high-level languages such as C# and Visual Basic .NET frequently compiles to a surprisingly small number of instructions.
CIL uses a stack-based execution model. Whereas x86 processors load values into registers to manipulate them, the CLR loads values onto an evaluation stack. To add two numbers together, you copy them to the stack, call ADD, and retrieve the result from the stack. Copying a value from memory to the stack is called loading, and copying from the stack to memory is called storing. CIL has several instructions for loading and storing. LDLOC, for example, loads a value onto the stack from a memory location, and STLOC copies it from the stack to memory and removes it from the stack.
For an example of CIL at work, consider the following C# source code, which declares and initializes two variables, adds them together, and stores the sum in a third variable:
int聽a聽=聽3; int聽b聽=聽7; int聽c聽=聽a聽+聽b;
Here鈥檚 the CIL that Microsoft鈥檚 C# compiler produces, with comments added by hand:
ldc.i4.3聽聽//聽Load聽a聽32-bit聽(i4)聽3聽onto聽the聽stack stloc.0聽聽聽//聽Store聽it聽in聽local聽variable聽0聽(a) ldc.i4.7聽聽//聽Load聽a聽32-bit聽(i4)聽7聽onto聽the聽stack stloc.1聽聽聽//聽Store聽it聽in聽local聽variable聽1聽(b) ldloc.0聽聽聽//聽Load聽local聽variable聽0聽onto聽the聽stack ldloc.1聽聽聽//聽Load聽local聽variable聽1聽onto聽the聽stack add聽聽聽聽聽聽聽//聽Add聽the聽two聽and聽leave聽the聽sum聽on聽the聽stack stloc.2聽聽聽//聽Store聽the聽sum聽in聽local聽variable聽2聽(c)
As you can see, the CIL is pretty straightforward. What鈥檚 not obvious, however, is how the local variables a, b, and c (locals 0, 1, and 2 to the CLR) get allocated. The answer is through metadata. The compiler writes information into the method鈥檚 metadata noting that three local 32-bit integers are declared. The CLR retrieves the information and allocates memory for the locals before executing the method. If you disassemble the method with ILDASM, the metadata shows up as a compiler directive:
.locals聽init聽(int32聽V_0,聽//聽Local聽variable聽0聽(a) 聽聽聽聽聽聽聽聽聽聽聽聽聽聽int32聽V_1,聽//聽Local聽variable聽1聽(b) 聽聽聽聽聽聽聽聽聽聽聽聽聽聽int32聽V_2)聽//聽Local聽variable聽2聽(c)
This is a great example of why metadata is so important to the CLR. It鈥檚 used not only to verify type safety, but also to prepare execution contexts. Incidentally, if a C# executable is compiled with a /DEBUG switch, ILDASM will display real variable names instead of placeholders such as V_0.
The .NET Framework SDK contains a document that describes the entire CIL instruction set in excruciating detail. I won鈥檛 clutter this chapter with a list of all the CIL instructions, but I will provide a table that lists some of the most commonly used instructions and describes them briefly.
|
Instruction |
Description |
|
BOX |
Converts a value type into a reference type |
|
CALL |
Calls a method; if the method is virtual, virtualness is ignored |
|
CALLVIRT |
Calls a method; if the method is virtual, virtualness is honored |
|
CASTCLASS |
Casts an object to another type |
|
LDC |
Loads a numeric constant onto the stack |
|
LDARG[A] |
Loads an argument or argument address [A] onto the stack |
|
LDELEM |
Loads an array element onto the stack |
|
LDLOC[A] |
Loads a local variable or local variable address [A] onto the stack |
|
LDSTR |
Loads a string literal onto the stack |
|
NEWARR |
Creates a new array |
|
NEWOBJ |
Creates a new object |
|
RET |
Returns from a method call |
|
STARG |
Copies a value from the stack to an argument |
|
STELEM |
Copies a value from the stack to an array element |
|
STLOC |
Transfers a value from the stack to a local variable |
|
THROW |
Throws an exception |
|
UNBOX |
Converts a reference type into a value type |
The same ILDASM utility that lets you view metadata is also a fine CIL disassembler. For a demonstration, start ILDASM and use it to open one of the System.*.dll DLLs in the \%SystemRoot%\Microsoft.NET\Framework\v1.0.nnnn directory. These DLLs belong to the .NET Framework class library. After opening the DLL, drill down into its namespaces and classes until you find a method you want to disassemble. Methods are easy to spot because they鈥檙e marked with magenta rectangles. Double-click the method and you鈥檒l see its CIL, complete with compiler directives generated from the method鈥檚 metadata. Better still, ILDASM is a round-trip disassembler, meaning that you can pass the disassembled code to ILASM and reproduce the CIL that you started with.
When speaking to groups of developers about CIL, I鈥檓 often asked about intellectual property issues. If you and I can disassemble the FCL, what鈥檚 to prevent a competitor from disassembling your company鈥檚 product? Reverse-engineering CIL isn鈥檛 trivial, but it鈥檚 easier than reverse-engineering x86 code. And decompilers that generate C# source code from CIL are freely available on the Internet. So how do you protect your IP?
The short answer is鈥攊t depends. Code that runs only on servers鈥擷ML Web services, for example鈥攊sn鈥檛 exposed to users, so it can鈥檛 be disassembled unless someone breaches your firewall. Code distributed to end users can be scrambled with third-party code obfuscation utilities. Obfuscators can鈥檛 guarantee that no one can read your code, but they can make doing so harder. In the final analysis, someone who has physical access to your CIL and wants to reverse-engineer it badly enough will find a way to do it. If it鈥檚 any consolation, the Java community has grappled with this problem for years. There is no perfect solution other than sticking strictly to server-side apps.
You now know that compilers that target the .NET Framework produce managed modules and that managed modules contain CIL and metadata. But you might be surprised to learn that the CLR is incapable of using managed modules directly. That鈥檚 because the fundamental unit of security, versioning, and deployment in the .NET Framework is not the managed module but the assembly.
An assembly is a collection of one or more files grouped together to form a logical unit. The term 鈥渇iles鈥?in this context generally refers to managed modules, but assemblies can include files that are not managed modules. Most assemblies contain just one file, but assemblies can and sometimes do include multiple files. All the files that make up a multifile assembly must reside in the same directory. When you use the C# compiler to produce a simple EXE, that EXE is not only a managed module, it鈥檚 an assembly. Most compilers are capable of producing managed modules that aren鈥檛 assemblies and also of adding other files to the assemblies that they create. The .NET Framework SDK also includes a tool named AL (Assembly Linker) that joins files into assemblies.
Multifile assemblies are commonly used to glue together modules written in different languages and to combine managed modules with ordinary files containing JPEGs and other resources. Multifile assemblies are also used to partition applications into discrete downloadable units, which can be beneficial for code deployed on the Internet. Imagine, for example, that someone with a dial-up connection wants to download a multi-megabyte application housed in a single-file assembly. Downloading the code could take forever. To mitigate the problem, you could divide the code into multiple files and make the files part of the same assembly. Because a module isn鈥檛 loaded unless it鈥檚 needed, the user won鈥檛 incur the cost of downloading the portions of the application that aren鈥檛 used. If you鈥檙e smart about how you partition the code, the bulk of the application might not have to be downloaded at all.
How does the CLR know which files belong to an assembly? One of the files in the assembly contains a manifest. Physically, the manifest is just more metadata; when a compiler creates a managed module that also happens to be an assembly, it simply writes the manifest into the module鈥檚 metadata. Logically, the manifest is a road map to the assembly鈥檚 contents. Its most important elements are
-
The assembly鈥檚 name
-
A list of the other files in the assembly, complete with cryptographic hashes of the files鈥?contents
-
A list of the data types exported from other files in the assembly and information mapping those data types to the files in which they鈥檙e defined
-
A version number in the format major.minor.build.revision (for example, 1.0.3705.0)
The manifest can also include other information such as a company name, description, requested security permissions, and culture string. The latter identifies the assembly鈥檚 targeted culture (for example, 鈥渆n-US鈥?for 鈥淯nited States English鈥? and is typically used with so-called 鈥渟atellite assemblies鈥?that contain only resources. Figure 1-3 depicts a multifile assembly that consists of three managed modules and a JPEG file. Main.exe holds the manifest, and the manifest contains references to the other files. In the eyes of the file system, these are still separate files. But to the CLR, they鈥檙e one logical entity.
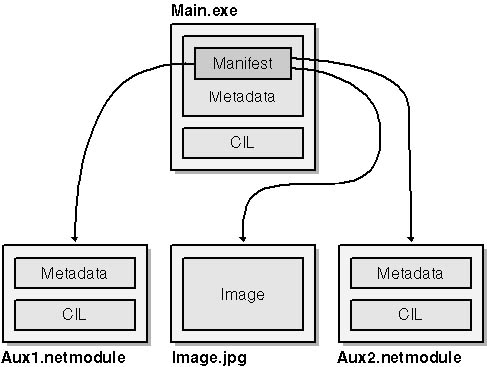 Figure 1-3
Figure 1-3
In the absence of information directing them to do otherwise, compilers produce assemblies that are weakly named. 鈥淲eakly named鈥?means that the assembly is not cryptographically signed and that the CLR uses only the name stored in the assembly manifest (which is nothing more than the assembly鈥檚 file name without the file name extension) to identify the assembly. But assemblies can be strongly named. A strongly named assembly contains the publisher鈥檚 public key and a digital signature that鈥檚 actually a hash of the assembly manifest where the public key is stored.
The digital signature, which is generated with the publisher鈥檚 private key and can be verified with the public key, makes the assembly鈥檚 manifest (and, by extension, the assembly itself) tamperproof. A strongly named assembly鈥檚 identity derives from the assembly name, the public key, the version number, and the culture string, if present. Any difference, no matter how small, is sufficient to distinguish two otherwise identical assemblies.
The SDK鈥檚 AL utility can be used to create strongly named assemblies. Most language compilers, including the C# and Visual Basic .NET compilers, can also emit strongly named assemblies. It鈥檚 up to you whether to deploy weakly or strongly named assemblies. The right choice is dictated by the assemblies鈥?intended use. If an assembly is to be deployed in the global assembly cache (GAC)鈥攁 global repository used by assemblies designed to be shared by multiple applications鈥攊t must be strongly named.
An assembly must also be strongly named if you want to take advantage of version checking. When the CLR loads a weakly named assembly, it does no version checking. That can be good or bad. It鈥檚 good if you replace an old version of the assembly with a new one (perhaps one that has undergone bug fixes) and want applications that use the assembly to automatically use the new one. It鈥檚 bad if you鈥檝e thoroughly tested the application against a specific version of the assembly and someone replaces the old assembly with a new one that鈥檚 riddled with bugs. That鈥檚 one symptom of the DLL Hell that Windows developers are all too familiar with. Strong naming can fix that. When the CLR loads a strongly named assembly, it compares the version number in the assembly to the version number that the application doing the loading was compiled against. (That information, not surprisingly, is recorded in the module鈥檚 metadata.) If the numbers don鈥檛 match up, the CLR throws an exception.
Strict version checking, of course, has pitfalls of its own. Suppose you elect to use strong naming, but later you find a bug in your assembly. You fix the bug and deploy the revised assembly. But guess what? Applications that use the assembly won鈥檛 load the new version unless you rebuild them. They鈥檒l still load the old version, and if you delete the old version, the applications won鈥檛 run at all. The solution is to modify the CLR鈥檚 binding policy. It鈥檚 relatively simple for an administrator to point the CLR to a new version of a strongly named assembly by editing a configuration file. Of course, if the newer version has bugs, you鈥檙e right back to square one. That鈥檚 why you don鈥檛 let just anyone have administrator privileges.
Working with assemblies sounds pretty complicated鈥攁nd at times, it is. Fortunately, if you鈥檙e not building shared assemblies or assemblies that link to other assemblies (other than the FCL, which, by the way, is a set of shared assemblies), most of the issues surrounding naming and binding fall by the wayside. You just run your compiler, copy the resulting assembly to a directory, and run it. Couldn鈥檛 be much simpler than that.
Windows programmers who code in C tend to rely on the Windows API and functions in third-party DLLs to get their job done. C++ programmers often use class libraries of their own creation or standard class libraries such as MFC. Visual Basic programmers use the Visual Basic API, which is an abstraction of the underlying operating system API.
Using the .NET Framework means you can forget about all these anachronistic APIs. You have a brand new API to learn, that of the .NET Framework class library, which is a library of more than 7,000 types鈥攃lasses, structs, interfaces, enumerations, and delegates (type-safe wrappers around callback functions)鈥攖hat are an integral part of the .NET Framework. Some FCL classes contain upward of 100 methods, properties, and other members, so learning the FCL isn鈥檛 a chore to be taken lightly. The bad news is that it鈥檚 like learning a brand new operating system. The good news is that every language uses the same API, so if your company decides to switch from Visual Basic to C++ or vice versa, the investment you make in learning the FCL isn鈥檛 lost.
To make learning and using the FCL more manageable, Microsoft divided the FCL into hierarchical namespaces. The FCL has about 100 namespaces in all. Each namespace holds classes and other types that share a common purpose. For example, much of the window manager portion of the Windows API is encapsulated in the System.Windows.Forms namespace. In that namespace you鈥檒l find classes that represent windows, dialog boxes, menus, and other elements commonly used in GUI applications. A separate namespace called System.Collections holds classes representing hash tables, resizable arrays, and other data containers. Yet another namespace, System.IO, contains classes for doing file I/O. You鈥檒l find a list of all the namespaces present in the FCL in the .NET Framework SDK鈥檚 online documentation. Your job as a budding .NET programmer is to learn about those namespaces. Fortunately, the FCL is so vast and so comprehensive that most developers will never have to tackle it all.
The following table lists a few of the FCL鈥檚 namespaces and briefly describes their contents. The term 鈥渆t al鈥?refers to a namespace鈥檚 descendants. For example, System.Data et al refers to System.Data, System.Data.Common, System.Data.OleDb, System.Data.SqlClient, and System.Data.SqlTypes.
|
Namespace |
Contents |
|
System |
Core data types and auxiliary classes |
|
System.Collections |
Hash tables, resizable arrays, and other containers |
|
System.Data et al |
ADO.NET data access classes |
|
System.Drawing |
Classes for generating graphical output (GDI+) |
|
System.IO |
Classes for performing file and stream I/O |
|
System.Net |
Classes that wrap network protocols such as HTTP |
|
System.Reflection et al |
Classes for reading and writing metadata |
|
System.Runtime.Remoting et al |
Classes for writing distributed applications |
|
System.ServiceProcess |
Classes for writing Windows services |
|
System.Threading |
Classes for creating and managing threads |
|
System.Web |
HTTP support classes |
|
System.Web.Services |
Classes for writing Web services |
|
System.Web.Services.Protocols |
Classes for writing Web service clients |
|
System.Web.UI |
Core classes used by ASP.NET |
|
System.Web.UI.WebControls |
ASP.NET server controls |
|
System.Windows.Forms |
Classes for GUI applications |
|
System.Xml et al |
Classes for reading and writing XML data |
The first and most important namespace in the FCL鈥攖he one that every application uses鈥攊s System. Among other things, the System namespace defines the core data types employed by managed applications: bytes, integers, strings, and so on. When you declare an int in C#, you鈥檙e actually declaring an instance of System.Int32. The C# compiler recognizes int as a shortcut simply because it鈥檚 easier to write
int聽a聽=聽7;
than it is to write
System.Int32聽a聽=聽7;
The System namespace is also home for many of the exception types defined in the FCL (for example, InvalidCastException) and for useful classes such as Math, which contains methods for performing complex mathematical operations; Random, which implements a pseudo-random number generator; and GC, which provides a programmatic interface to the garbage collector.
Physically, the FCL is housed in a set of DLLs in the \%SystemRoot%\Microsoft.NET\Framework\v1.0.nnnn directory. Each DLL is an assembly that can be loaded on demand by the CLR. Core data types such as Int32 are implemented in Mscorlib.dll; other types are spread among the FCL DLLs. The documentation for each type lists the assembly in which it鈥檚 defined. That鈥檚 important, because if a compiler complains about an FCL class being an undefined type, you must point the compiler to the specific assembly that implements the class for you. The C# compiler uses /r[eference] switches to identify referenced assemblies.
Obviously, no one chapter (or even one book) can hope to cover the FCL in its entirety. You鈥檒l become acquainted with many FCL classes as you work your way through this book. Chapter 3 kicks things off by introducing some of the FCL鈥檚 coolest classes and namespaces. For now, realize that the FCL is the .NET Framework API and that it鈥檚 an extraordinarily comprehensive class library. The more you use it, the more you鈥檒l like it, and the more you鈥檒l come to appreciate the sheer effort that went into putting it together.