


Department of Computer Science, University of Chile, Casilla 2777, Santiago, Chile
Abstract
We survey several algorithms for searching a string in a text. We include theoretical and empirical results, as well as the actual code of each algorithm. An extensive bibliography is also included.
String searching is an important component of many problems, including text editing, data retrieval, and symbol manipulation. Despite the use of indices for searching large amounts of text, string searching may help in an information retrieval system. For example, it may be used for filtering of potential matches or for searching retrieval terms that will be highlighted in the output.
The string searching or string matching problem consists of finding all occurrences (or the first occurrence) of a pattern in a text, where the pattern and the text are strings over some alphabet. We are interested in reporting all the occurrences. It is well known that to search for a pattern of length m in a text of length n (where n > m) the search time is 0(n) in the worst case (for fixed m). Moreover, in the worst case, at least n - m + 1 characters must be inspected. This result is due to Rivest (1977). However, for different algorithms the constant in the linear term can be very different. For example, in the worst case, the constant multiple in the naive algorithm is m, whereas for the Knuth-Morris-Pratt (1977) algorithm it is two.
We present the most important algorithms for string matching: the naive or brute force algorithm, the Knuth-Morris-Pratt (1977) algorithm, different variants of the Boyer-Moore (1977) algorithm, the Shift-or algorithm from Baeza-Yates and Gonnet (1989), and the Karp-Rabin (1987) algorithm, which is probabilistic. Experimental results for random text and one sample of English text are included. We also survey the main theoretical results for each algorithm.
Although we only cover string searching, references for related problems are given. We use the C programming language described by Kernighan and Ritchie (1978) to present our algorithms.
We use the following notation:
Theoretical results are given for the worst case number of comparisons, and the average number of comparisons between a character in the text and a character in the pattern (text pattern comparisons) when finding all occurrences of the pattern in the text, where the average is taken uniformly with respect to strings of length n over a given finite alphabet.
Quoting Knuth et al. (1977). "It might be argued that the average case taken over random strings is of little interest, since a user rarely searches for a random string. However, this model is a reasonable approximation when we consider those pieces of text that do not contain the pattern, and the algorithm obviously must compare every character of the text in those places where the pattern does occur." Our experimental results show that this is the case.
The emperical data, for almost all algorithms, consists of results for two types of text: random text and English text. The two cost functions we measured were the number of comparisons performed between a character in the text and a character in the pattern, and the execution time. To determine the number of comparisons, 100 runs were performed. The execution time was measured while searching l,000 patterns. In each case, patterns of lengths 2 to 20 were considered.
In the case of random text, the text was of length 40,000, and both the text and the pattern were chosen uniformly and randomly from an alphabet of size c. Alphabets of size c = 4 (DNA bases) and c = 30 (approximately the number of lowercase English letters) were considered.
For the case of English text we used a document of approximately 48,000 characters, with the patterns chosen at random from words inside the text in such a way that a pattern was always a prefix of a word (typical searches). The alphabet used was the set of lowercase letters, some digits, and punctuation symbols, giving 32 characters. Unsuccessful searches were not considered, because we expect unsuccessful searches to be faster than successfu1 searches (fewer comparisons on average). The results for English text are not statistically significant because only one text sample was used. However, they show the correlation of searching patterns extracted from the same text, and we expect that other English text samples will give similar results. Our experimental results agree with those presented by Davies and Bowsher (1986) and Smit (1982).
We define a random string of length
For example, the probability of finding a match between a random text of length m and a random pattern of length m is
The expected number of matches of a random pattern of length m in a random text of length n is
The naive, or brute force, algorithm is the simplest string matching method. The idea consists of trying to match any substring of length m in the text with the pattern (see Figure 10.1).
The expected number of text pattern comparisons performed by the naive or brute force algorithm when searching with a pattern of length m in a text of length n (n
This is drastically different from the worst case mn.
The classic Knuth, Morris, and Pratt (1977) algorithm, discovered in 1970, is the first algorithm for which the constant factor in the linear term, in the worst case, does not depend on the length of the pattern. It is based on preprocessing the pattern in time O(m). In fact, the expected number of comparisons performed by this algorithm (search time only) is bounded by
The basic idea behind this algorithm is that each time a mismatch is detected, the "false start" consists of characters that we have already examined. We can take advantage of this information instead of repeating comparisons with the known characters. Moreover, it is always possible to arrange the algorithm so that the pointer in the text is never decremented. To accomplish this, the pattern is preprocessed to obtain a table that gives the next position in the pattern to be processed after a mismatch. The exact definition of this table (called next in Knuth et al. [1977]) is
next[j] = max{i|(pattern[k] = pattern [j - i + k] for k = 1, . . . , i - 1)
and pattern[i]
for j = 1, . . . , m. In other words, we consider the maximal matching prefix of the pattern such that the next character in the pattern is different from the character of the pattern that caused the mismatch. This algorithm is presented in Figure 10.2.
Example 1 The next table for the pattern abracadabra is
When the value in the next table is zero, we have to advance one position in the text and start comparing again from the beginning of the pattern. The last value of the next table (five) is used to continue the search after a match has been found.
In the worst case, the number of comparisons is 2n + O(m). Further explanation of how to preprocess the pattern in time O(m) to obtain this table can be found in the original paper or in Sedgewick (1983; see Figure 10.3).
An algorithm for searching a set of strings, similar to the KMP algorithm, was developed by Aho and Corasick (1975) . However the space used and the preprocessing time to search for one string is improved in the KMP algorithm. Variations that compute the next table "on the fly" are presented by Barth (1981) and Takaoka (1986). Variations for the Aho and Corasick algorithm are presented by Bailey and Dromey (1980) and Meyer (1985).
Also in 1977, the other classic algorithm was published by Boyer and Moore (1977). Their main idea is to search from right to left in the pattern. With this scheme, searching is faster than average.
The Boyer-Moore (BM) algorithm positions the pattern over the leftmost characters in the text and attempts to match it from right to left. If no mismatch occurs, then the pattern has been found. Otherwise, the algorithm computes a shift; that is, an amount by which the pattern is moved to the right before a new matching attempt is undertaken.
The shift can be computed using two heuristics: the match heuristic and the occurrence heuristic. The match heuristic is obtained by noting that when the pattern is moved to the right, it must
1. match all the characters previously matched, and
2. bring a different character to the position in the text that caused the mismatch.
The last condition is mentioned in the Boyer-Moore paper (1977), but was introduced into the algorithm by Knuth et al. (1977). Following the later reference, we call the original shift table dd, and the improved version
Example 2 The
The occurrence hueristic is obtained by noting that we must align the position in the text that caused the mismatch with the first character of the pattern that matches it. Formally calling this table d, we have
for every symbol x in the alphabet. See Figure 10.4 for the code to compute both tables (i.e.,
Example 3 The d table for the pattern abracadabra is
and the value for any other character is 11.
Both shifts can be precomputed based solely on the pattern and the alphabet. Hence, the space needed is m + c + O(1). Given these two shift functions, the algorithm chooses the larger one. The same shift strategy can be applied after a match. In Knuth et al. (1977) the preprocessing of the pattern is shown to be linear in the size of the pattern, as it is for the KMP algorithm. However, their algorithm is incorrect. The corrected version can be found in Rytter's paper (1980; see Figure 10.5).
Knuth et al. (1977) have shown that, in the worst case, the number of comparisons is O(n + rm), where r is the total number of matches. Hence, this algorithm can be as bad as the naive algorithm when we have many matches, namely,
To improve the worst case, Galil (1979) modifies the algorithm so that it remembers how many overlapping characters it can have between two successive matches. That is, we compute the length,
A simplified version of the Boyer-Moore algorithm (simplified-Boyer-Moore, or SBM, algorithm) is obtained by using only the occurrence heuristic. The main reason behind this simplification is that, in practice, patterns are not periodic. Also, the extra space needed decreases from O(m + c) to O(c). That is, the space depends only on the size of the alphabet (almost always fixed) and not on the length of the pattern (variable). For the same reason, it does not make sense to write a simplified version that uses Galil's improvement because we need O(m) space to compute the length of the overlapping characters. Of course, the worst case is now O(mn), but it will be faster on the average.
Horspool (1980) presented a simplification of the Boyer-Moore algorithm, and based on empirical results showed that this simpler version is as good as the original Boyer-Moore algorithm. Moreover, the same results show that for almost all pattern lengths this algorithm is better than algorithms that use a hardware instruction to find the occurrence of a designated character.
Horspool noted that when we know that the pattern either matches or does not, any of the characters from the text can be used to address the heuristic table. Based on this, Horspool (1980) improved the SBM algorithm by addressing the occurrence table with the character in the text corresponding to the last character of the pattern. We call this algorithm the Boyer-Moore-Horspool, or BMH, algorithm.
To avoid a comparison when the value in the table is zero (the last character of the pattern), we define the initial value of the entry in the occurrence table, corresponding to the last character in the pattern, as m, and then we compute the occurence heuristic table for only the first m - 1 characters of the pattern. Formally
Example 4 The d table for the pattern abracadabra is
and the value for any other character is 11.
The code for an efficient version of the Boyer-Moore-Horspool algorithm is extremely simple and is presented in Figure 10.6 where MAX_ALPHABET_SIZE is the size of the alphabet. In this algorithm, the order of the comparisons is not relevant, as noted by Baeza-Yates (1989c) and Sunday (1990). Thus, the algorithm compares the pattern from left to right. This algorithm also includes the idea of using the character of the text that corresponds to position m + 1 of the pattern, a modification due to Sunday (1990). Further improvements are due to Hume and Sunday (1990).
Based on empirical and theoretical analysis, the BMH algorithm is simpler and faster than the SBM algorithm, and is as good as the BM algorithm for alphabets of size at least 10. Also, it is not difficult to prove that the expected shift is larger for the BMH algorithm. Improvements to the BMH algorithm for searching in English text are discussed by Baeza-Yates (1989b, 1989a) and Sunday (1990). A hybrid algorithm that combines the BMH and KMP algorithms is proposed by Baeza-Yates (1989c).
Figure 10.7 shows, for the algorithms studied up to this point, the expected number of comparisons per character for random text with c = 4. The codes used are the ones given in this chapter, except that the Knuth-Morris-Pratt algorithm was implemented as suggested by their authors. (The version given here is slower but simpler.)
The main idea is to represent the state of the search as a number, and is due to Baeza-Yates and Gonnet (1989). Each search step costs a small number of arithmetic and logical operations, provided that the numbers are large enough to represent all possible states of the search. Hence, for small patterns we have an O(n) time algorithm using O(
The main properties of the shift-or algorithm are:
It is worth noting that the KMP algorithm is not a real time algorithm, and the BM algorithm needs to buffer the text. All these properties indicate that this algorithm is suitable for hardware implementation.
This algorithm is based on finite automata theory, as the KMP algorithm, and also exploits the finiteness of the alphabet, as in the BM algorithm.
Instead of trying to represent the global state of the search as previous algorithms do, we use a vector of m different states, where state i tells us the state of the search between the positions 1, . . . , i of the pattern and the positions ( j - i + 1), . . . , j of the text, where j is the current position in the text.
We use one bit to represent each individual state, where the state is 0 if the last i characters have matched, or 1 if not. We can then represent the vector state efficiently as a number in base 2 by
where the si are the individual states. We report a match if sm is 0, or equivalently, if state < 2m-1. That match ends at the current position.
To update the state after reading a new character in the text, we must:
Each search step is then:
where << denotes the shift left operation.
The definition of the table T is
for every symbol x of the alphabet, where
Example 5 Let {a, b, c, d} be the alphabet, and ababc the pattern. The entries for table T (one digit per position in the pattern) are then:
We finish the example by searching for the first occurrence of ababc in the text abdabababc. The initial state is 11111.
For example, the state 10101 means that in the current position we have two partial matches to the left, of lengths two and four, respectively. The match at the end of the text is indicated by the value 0 in the leftmost bit of the state of the search.
The complexity of the search time in both the worst and average case is
Figure 10.8 shows an efficient implementation of this algorithm. The programming is independent of the word size insofar as possible. We use the following symbolic constants:
The changes needed for a more efficient implementation of the algorithm (that is, scan the text until we see the first character of the pattern) are shown in Figure 10.9. The speed of this version depends on the frequency of the first letter of the pattern in the text. The empirical results for this code are shown in Figures 10.11 and 10.12. Another implementation is possible using the bitwise operator and instead of the or operation, and complementing the value of Tx for all x
By just changing the definition of table T we can search for patterns such that every pattern position is:
Furthermore, we can have "don't care" symbols in the text. This idea has been recently extended to string searching with errors and other variants by Wu and Manber (l991).
A different approach to string searching is to use hashing techniques, as suggested by Harrison (1971). All that is necessary is to compute the signature function of each possible m-character substring in the text and check if it is equal to the signature function of the pattern.
Karp and Rabin (1987) found an easy way to compute these signature functions efficiently for the signature function h(k) = k mod q, where q is a large prime. Their method is based on computing the signature function for position i given the value for position i - 1. The algorithm requires time proportional to n + m in almost all cases, without using extra space. Note that this algorithm finds positions in the text that have the same signature value as the pattern. To ensure that there is a match, we must make a direct comparison of the substring with the pattern. This algorithm is probabilistic, but using a large value for q makes collisions unlikely [the probability of a random collision is O(1 /q)].
Theoretically, this algorithm may still require mn steps in the worst case, if we check each potential match and have too many matches or collisions. In our empirical results we observed only 3 collisions in 107 computations of the signature function, using large alphabets.
The signature function represents a string as a base-d number, where d = c is the number of possible characters. To obtain the signature value of the next position, only a constant number of operations is needed. The code for the case d = 128 (ASCII) and q = 16647133 for a word size of 32 bits, based in Sedgewick's exposition (1983), is given in Figure 10.10 (D = log2 d and Q = q). By using a power of 2 for d (d
Thus, the period of the signature function is much larger than m for any practical case, as shown in Gonnet and Baeza-Yates (1990).
In practice, this algorithm is slow due to the multiplications and the modulus operations. However, it becomes competitive for long patterns. We can avoid the computation of the modulus function at every step by using implicit modular arithmetic given by the hardware. In other words, we use the maximum value of an integer (determined by the word size) for q. The value of d is selected such that dk mod 2r has maximal cycle length (cycle of length 2r-2), for r from 8 to 64, where r is the size, in bits, of a word. For example, an adequate value for d is 31.
With these changes, the evaluation of the signature at every step (see Figure 10.10) is
and overflow is ignored. In this way, we use two multiplications instead of one multiplication and two modulus operations.
We have presented the most important string searching algorithms. Figure 10.11 shows the execution time of searching 1000 random patterns in random text for all the algorithms considered, with c = 30. Based on the empirical results, it is clear that Horspool's variant is the best known algorithm for almost all pattern lengths and alphabet sizes. Figure 10.12 shows the same empirical results as Figure 10.11, but for English text instead of random text. The results are similar. For the shift-or algorithm, the given results are for the efficient version. The results for the Karp-Rabin algorithm are not included because in all cases the time exceeds 300 seconds.
The main drawback of the Boyer-Moore type algorithms is the preprocessing time and the space required, which depends on the alphabet size and/or the pattern size. For this reason, if the pattern is small (1 to 3 characters long) it is better to use the naive algorithm. If the alphabet size is large, then the Knuth-Morris-Pratt algorithm is a good choice. In all the other cases, in particular for long texts, the Boyer-Moore algorithm is better. Finally, the Horspool version of the Boyer-Moore algorithm is the best algorithm, according to execution time, for almost all pattern lengths.
The shift-or algorithm has a running time similar to the KMP algorithm. However, the main advantage of this algorithm is that we can search for more general patterns ("don't care" symbols, complement of a character, etc.) using exactly the same searching time (see Baeza-Yates and Gonnet [1989]); only the preprocessing is different.
The linear time worst case algorithms presented in previous sections are optimal in the worst case with respect to the number of comparisons (see Rivest [1977]). However, they are not space optimal in the worst case because they use space that depends on the size of the pattern, the size of the alphabet, or both. Galil and Seiferas (1980, 1983) show that it is possible to have linear time worst case algorithms using constant space. (See also Slisenko [1980, 1983].) They also show that the delay between reading two characters of the text is bounded by a constant, which is interesting for any real time searching algorithms (Galil 1981). Practical algorithms that achieve optimal worst case time and space are presented by Crochemore and Perrin (1988, 1989). Optimal parallel algorithms for string matching are presented by Galil (1985) and by Vishkin (1985). (See also Berkman et al. [1989] and Kedem et al. [1989].)
Many of the algorithms presented may be implemented with hardware (Haskin 1980; Hollaar 1979). For example, Aho and Corasick machines (see Aoe et al. (1985), Cheng and Fu (1987), and Wakabayashi et al. (1985).
If we allow preprocessing of the text, we can search a string in worst case time proportional to its length. This is achieved by using a Patricia tree (Morrison 1968) as an index. This solution needs O(n) extra space and O(n) preprocessing time, where n is the size of the text. See also Weiner (1973), McCreight (1976), Majster and Reiser (1980), and Kemp et al. (1987). For other kinds of indices for text, see Faloutsos (1985), Gonnet (1983), Blumer et al. (1985; 1987). For further references and problems, see Gonnet and Baeza-Yates (1991).
AHO, A. 1980. "Pattern Matching in Strings," in Formal Language Theory: Perspectives and Open Problems, ed. R. Book, pp. 325-47. London: Academic Press.
AHO, A., and M. CORASICK. 1975. "Efficient String Matching: An Aid to Bibliographic Search," Communications of the ACM, 18, pp. 333-40.
AOE, J., Y. YAMAMOTO, and R. SHIMADA. 1985. "An Efficient Implementation of Static String Pattern Matching Machines," in IEEE Int. Conf. on Supercomputing Systems, vol. 1, pp. 491-98, St. Petersburg, Fla.
APOSTOLICO, A., and R. GIANCARLO. 1986. "The Boyer-Moore-Galil String Searching Strategies Revisited." SIAM J on Computing, 15, 98-105.
BAEZA-YATES, R. 1989a. Efficient Text Searching. Ph.D. thesis, Dept. of Computer Science, University of Waterloo. Also as Research Report CS-89-17.
BAEZA-YATES, R. 1989b. "Improved String Searching." Software-Practice and Experience, 19(3), 257-71.
BAEZA-YATES, R. 1989c. "String Searching Algorithms Revisited," in Workshop in Algorithms and Data Structures, F. Dehne, J.-R. Sack, and N. Santoro, eds. pp. 75-96, Ottawa, Canada. Springer Verlag Lecture Notes on Computer Science 382.
BAEZA-YATES, R., and G. GONNET. 1989. "A New Approach to Text Searching," in Proc. of 12th ACM SIGIR, pp. 168-75, Cambridge, Mass. (To appear in Communications of ACM).
BAEZA-YATES, R., and M. REGNIER. 1990. "Fast Algorithms for Two Dimensional and Multiple Pattern Matching," in 2nd Scandinavian Workshop in Algorithmic Theory, SWAT'90, R. Karlsson and J. Gilbert. eds. Lecture Notes in Computer Science 447, pp. 332-47, Bergen, Norway: Springer-Verlag.
BAILEY, T., and R. DROMEY. 1980. "Fast String Searching by Finding Subkeys in Subtext." Inf. Proc. Letters, 11, 130-33.
BARTH, G. 1981. "An Alternative for the Implementation of Knuth-Morris-Pratt Algorithm." Inf. Proc. Letters, 13, 134-37.
BERKMAN, O., D. BRESLAUER, Z. GALIL, B. SCHIEBER, and U. VISHKIN. 1989. "Highly Parellelizable Problems," in Proc. 20th ACM Symp. on Theory of Computing, pp. 309-19, Seattle, Washington.
BLUMER, A., J. BLUMER, A. EHRENFEUCHT, D. HAUSSLER, and R. MCCONNELL. 1987. "Completed Inverted Files for Efficient Text Retrieval and Analysis". JACM, 34, 578-95.
BLUMER, A., J. BLUMER D. HAUSSLER, A. EHRENFEUCHT, M. CHEN, and J. SEIFERAS. 1985. "The Smallest Automaton Recognizing the Subwords of a Text. Theorefical Computer Science, 40, 31-55.
BOYER, R., and S. MOORE. 1977. "A Fast String Searching Algorithm." CACM, 20, 762-72.
CHENG, H., and K. FU. 1987. "Vlsi Architectures for String Matching and Pattern Matching." Pattern Recognition, 20, 125-41.
COLE, R. 1991. "Tight Bounds on the Complexity of the Boyer-Moore String Matching Algorithm, 2nd Symp. on Discrete Algorithms," pp. 224-33, SIAM, San Francisco, Cal.
COMMENTZ-WALTER, B. 1979. "A String Matching Algorithm Fast on the Average," in ICALP, Lecture Notes in Computer Science 71, pp. 118-32. Springer-Verlag.
CROCHEMORE, M. 1988. "String Matching with Constraints," in Mathematical Foundations of Computer Science, Carlesbad, Czechoslovakia. Lecture Notes in Computer Science 324. Springer-Verlag.
CROCHEMORE, M., and D. PERRIN. 1988. "Pattern Matching in Strings," in 4th Conference on Image Analysis and Processing, ed. D. Gesu. pp. 67-79. Springer-Verlag.
CROCHEMORE, M., and D. PERRIN. 1989. "Two Way Pattern Matching." Technical Report 98-8, L.I.T.P., University. Paris 7 (submitted for publication).
DAVIES, G., and S. BOWSHER. 1986. "Algorithms for Pattern Matching." Software-Practice and Experience, 16, 575-601.
FALOUTSOS, C. 1985. "Access Methods for Text." ACM C. Surveys, 17, 49-74.
GALIL, Z. 1979. "On Improving the Worst Case Running Time of the Boyer-Moore String Matching Algorithm. CACM, 22, 505-08.
GALIL, Z. 1981. "String Matching in Real Time." JACM, 28, 134-49.
GALIL, Z. 1985. "Optimal Parallel Algorithms for String Matching." Information and Control, 67, 144-57.
GALIL, Z., and J. SEIFERAS. 1980. "Saving Space in Fast String-Matching." SIAM J on Computing, 9, 417 - 38.
GALIL, Z., and J. SEIFERAS. 1983. "Time-Space-Optimal String Matching." JCSS, 26, 280-94.
GONNET, G. 1983. "Unstructured Data Bases or Very Efficient Text Searching," in ACM PODS, vol. 2, pp. 117-24, Atlanta, Ga.
GONNET, G., and R. BAEZA-YATES. 1990. "An Analysis of the Karp-Rabin String Matching Algorithm. Information Processing Letters, pp. 271-74.
GONNET, G. H., and BAEZA-YATES, R. 1991. "Handbook of Algorithms and Data Structures," 2nd Edition, Addison-Wesley.
GUIBAS, L., and A. ODLYZKO. 1980. "A New Proof of the Linearity of the Boyer-Moore String Searching Algorithm. SIAM J on Computing, 9, 672-82.
HARRISON, M. 1971. "Implementation of the Substring Test by Hashing." CACM, 14, 777-79.
HASKIN, R. 1980. "Hardware for Searching Very Large Text Databases," in Workshop Computer Architecture for Non-Numeric Processing, vol. 5, pp. 49-56, California.
HOLLAAR, L. 1979. "Text Retrieval Computers." IEEE Computer, 12, 40-50.
HORSPOOL, R. N. 1980. "Practical Fast Searching in Strings." Software - Practice and Experience, 10, 501-06.
HUME, A., and D. M. SUNDAY. 1991. "Fast String Searching." AT&T Bell Labs Computing Science Technical Report No. 156. To appear in Software-Practice and Experience.
IYENGAR, S., and V. ALIA. 1980. "A String Search Algorithm." Appl. Math. Comput., 6, 123-31.
KARP, R., and M. RABIN. 1987. "Efficient Randomized Pattern-Matching Algorithms. IBM J Res. Development, 31, 249-60.
KEDEM, Z., G. LANDAU, and K. PALEM. 1989. "Optimal Parallel Suffix-Prefix Matching Algorithm and Applications," in SPAA'89, Santa Fe, New Mexico.
KEMP, M., R. BAYER, and U. GUNTZER. 1987. "Time Optimal Left to Right Construction of Position Trees." Acta Informatica, 24, 461-74.
KERNIGHAN, B., and D. RITCHIE. 1978. The C Programming Language. Englewood Cliffs, N.J.: Prentice Hall.
KNUTH, D., J. MORRIS, and V. PRATT. 1977. "Fast Pattern Matching in Strings." SIAM J on Computing, 6, 323-50.
MAJSTER, M., and A. REISER. 1980. "Efficient On-Line Construction and Correction of Position Trees." SIAM J on Computing, 9, 785-807.
MCCREIGHT, E. 1976. "A Space-Economical Suffix Tree Construction Algorithm." JACM, 23, 262-72.
MEYER, B. 1985. "Incremental String Matching." Inf. Proc. Letters, 21, 219-27.
MOLLER-NIELSEN, P., and J. STAUNSTRUP. 1984. "Experiments with a Fast String Searching Algorithm." Inf . Proc . Letters, 18, 129-35.
MORRIS, J., and V. PRATT. 1970. "A Linear Pattern Matching Algorithm." Technical Report 40, Computing Center, University of California, Berkeley.
MORRISON, D. 1968. "PATRICIA-Practical Algorithm to Retrieve Information Coded in Alphanumeric." JACM, 15, 514-34.
RIVEST, R. 1977. "On the Worst-Case Behavior of String-Searching Algorithms." SIAM J on Computing, 6, 669-74.
RYTTER, W. 1980. "A Correct Preprocessing Algorithm for Boyer-Moore String-Searching." SIAM J on Computing, 9, 509-12.
SCHABACK, R. 1988. "On the Expected Sublinearity of the Boyer-Moore Algorithm." SIAM J on Computing, 17, 548-658.
SEDGEWICK, R. 1983. Algorithms. Reading, Mass.: Addison-Wesley.
SLISENKO, A. 1980. "Determination in Real Time of all the Periodicities in a Word." Sov. Math. Dokl., 21, 392-95.
SLISENKO, A. 1983. "Detection of Periodicities and String-Matching in Real Time." J. Sov. Math., 22, 1316-86.
SMIT, G. 1982. "A Comparison of Three String Matching Algorithms." Software-Practice and Experience, 12, 57-66.
SUNDAY, D. 1990. "A Very Fast Substring Search Algorithm." Communications of the ACM, 33(8), 132-42.
TAKAOKA, T. 1986. "An On-Line Pattern Matching Algorithm." Inf. Proc. Letters, 22, 329-30.
VISHKIN, U. 1985. "Optimal Parallel Pattern Matching in Strings." Information and Control, 67, 91-113.
WAKABAYASHI, S., T. KIKUNO, and N. YOSHIDA. 1985. "Design of Hardware Algorithms by Recurrence Relations." Systems and Computers in Japan, 8, 10-17.
WEINER, P. 1973. "Linear Pattern Matching Algorithm," in FOCS, vol. 14, pp. 1-11.
WU, S., and U. MANBER. 1991. "Fast Text Searching With Errors." Technical Report TR-91-11, Department of Computer Science, University of Arizona. To appear in Proceedings of USENIX Winter 1992 Conference, San Francisco, January, 1992.
10.2 PRELIMINARIES
 n: the length of the text m: the length of the pattern (string) c: the size of the alphabet *
n: the length of the text m: the length of the pattern (string) c: the size of the alphabet * 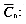 the expected number of comparisons performed by an algorithm while searching the pattern in a text of length n
the expected number of comparisons performed by an algorithm while searching the pattern in a text of length n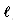 as a string built as the concatenation of
as a string built as the concatenation of 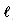 characters chosen independently and uniformly from
characters chosen independently and uniformly from 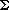 . That is, the probability of two characters being equal is 1/c. Our random text model is similar to the one used in Knuth et al. (1977) and Schaback (1988).
. That is, the probability of two characters being equal is 1/c. Our random text model is similar to the one used in Knuth et al. (1977) and Schaback (1988).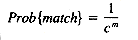
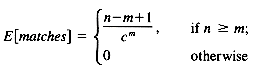
10.3 THE NAIVE ALGORITHM
naivesearch( text, n, pat, m ) /* Search pat[1..m] in text[1..n] */
char text[], pat[];
int n, m;
{int i, j, k, lim;
lim = n-m+1;
for( i = 1; i<= lim; i++ ) /* Search */
{k = i;
for( j=1; j<=m && text[k] == pat[j]; j++ ) k++;
if( j > m ) Report_match_at_position( i-j+1 );
}
}
Figure 10.1: The naive or brute force string matching algorithm
 m) is given by Baeza-Yates (1989c) as
m) is given by Baeza-Yates (1989c) as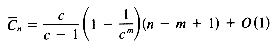
10.4 THE KNUTH-MORRIS-PRATT ALGORITHM

 pattern[j]}
pattern[j]} a b r a c a d a b r a
next[j] 0 1 1 0 2 0 2 0 1 1 0 5
kmpsearch( text, n, pat, m ) /* Search pat[1..m] in text[1..n] */
char text[], pat[];
int n, m;
{int j, k, resume;
int next[MAX_PATTERN_SIZE];
pat[m+1] = CHARACTER_NOT_IN_THE_TEXT;
initnext( pat, m+1, next ); /* Preprocess pattern */
resume = next[m+1];
j = k = 1;
do { /* Search */if( j==0 || text[k]==pat[j] )
{k++; j++;
}
else j = next[j];
if( j > m )
{Report_match_at_position( k-m );
J = resume;
}
} while( k <= n );
pat[m+1] = END_OF_STRING;
}
Figure 10.2: The Knuth-Morris-Pratt algorithm
initnext( pat, m, next ) /* Preprocess pattern of length m */
char pat[];
int m, next[];
{int i, j;
i = 1; j = next[1] = 0;
do
{if( j == 0 || pat[i] == pat[j] )
{i++; j++;
if( pat[i] != pat[j] ) next[i] = j;
else next[i] = next[j];
}
else j = next[j];
}
while( i <= m ) ;
}
Figure 10.3: Pattern preprocessing in the Knuth-Morris-Pratt algorithm
10.5 THE BOYER-MOORE ALGORITHM
 . The formal definitions are
. The formal definitions are
 table for the pattern abracadabra is
table for the pattern abracadabra is a b r a c a d a b r a
ddhat [j] 17 16 15 14 13 12 11 13 12 4 1
d[x] = min{s|s = m or (0  s < m and pattern [m - s] = x)}
s < m and pattern [m - s] = x)} and d) from the pattern.
and d) from the pattern.bmsearch( text, n, pat, m ) /* Search pat[1..m] in text[1..n] */
char text[], pat[];
int n, m;
{int k, j, skip;
int dd[MAX_PATTERN_SIZE], d[MAX_ALPHABET_SIZE];
initd( pat, m, d ); /* Preprocess the pattern */
initdd( pat, m, dd );
k = m; skip = dd[1] + 1;
while( k <= n ) /* Search */
{j = m;
while( j>0 && text[k] == pat[j] )
{j--; k--;
}
if( j == 0 )
{Report_match_at_position( k+1 );
k += skip;
}
else k += max( d[text[k]], dd[j] );
}
}
Figure 10.4: The Boyer-Moore algorithm
d['a'] = 0 d['b'] = 2 d['c'] = 6 d['d'] = 4 d['r'] = 1
initd( pat, m, d ) /* Preprocess pattern of length m : d table */
char pat[];
int m, d[];
{int k;
for( k=0; k = MAX_ALPHABET_SIZE; k++ ) d[k] = m;
for( k=1; k<=m; k++ ) d[pat[k]] = m-k;
}
initdd( pat, m, dd ) /* Preprocess pattern of length m : dd hat table */
char pat[];
int m, dd[];
{int j, k, t, t1, q, q1;
int f[MAX_PATTERN_SIZE+1];
for( k=1; k<=m; k++ ) dd[k] = 2*m-k;
for( j=m, t=m+1; j > 0; j--, t-- ) /* setup the dd hat table */
{f[j] = t;
while( t <= m && pat[j] != pat[t] )
{dd[t] = min( dd[t], m-j );
t = f[t];
}
}
q = t; t = m + 1 - q; q1 = 1; /* Rytter's correction */
for( j=1, t1=0; j <= t; t1++, j++ )
{f[j] = t1;
while( t1 >= 1 && pat[j] != pat[t1] ) t1 = f[t1];
}
while( q < m )
{for( k=q1; k<=q; k++ ) dd[k] = min( dd[k], m+q-k );
q1 = q + 1; q = q + t - f[t]; t = f[t];
}
}
Figure 10.5: Preprocessing of the pattern in the Boyer-Moore algorithm
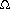 (n) matches. A simpler alternative proof can be found in a paper by Guibas and Odlyzko (1980). In the best case Cn = n/m. Our simulation results agree well with the emprical and theoretical results in the original Boyer-Moore paper (1977). Some experiments in a distributed environment are presented by Moller-Nielsen and Straunstrup (1984). A variant of the BM algorithm when m is similar to n is given by Iyengar and Alia (1980). Boyer-Moore type algorithms to search a set of strings are presented by Commentz-Walter (1979) and Baeza-Yates and Regnier (1990).
(n) matches. A simpler alternative proof can be found in a paper by Guibas and Odlyzko (1980). In the best case Cn = n/m. Our simulation results agree well with the emprical and theoretical results in the original Boyer-Moore paper (1977). Some experiments in a distributed environment are presented by Moller-Nielsen and Straunstrup (1984). A variant of the BM algorithm when m is similar to n is given by Iyengar and Alia (1980). Boyer-Moore type algorithms to search a set of strings are presented by Commentz-Walter (1979) and Baeza-Yates and Regnier (1990).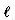 , of the longest proper prefix that is also a suffix of the pattern. Then, instead of going from m to 1 in the comparison loop, the algorithm goes from m to k, where
, of the longest proper prefix that is also a suffix of the pattern. Then, instead of going from m to 1 in the comparison loop, the algorithm goes from m to k, where  if the last event was a match, or k = 1 otherwise. For example,
if the last event was a match, or k = 1 otherwise. For example, 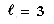 for the pattern ababa. This algorithm is truly linear, with a worst case of O(n + m) comparisons. Recently, Cole (1991) proved that the exact worst case is 3n + O(m) comparisons. However, according to empirical results, as expected, it only improves the average case for small alphabets, at the cost of using more instructions. Recently, Apostolico and Giancarco (1986) improved this algorithm to a worst case of 2n - m + 1 comparisons.
for the pattern ababa. This algorithm is truly linear, with a worst case of O(n + m) comparisons. Recently, Cole (1991) proved that the exact worst case is 3n + O(m) comparisons. However, according to empirical results, as expected, it only improves the average case for small alphabets, at the cost of using more instructions. Recently, Apostolico and Giancarco (1986) improved this algorithm to a worst case of 2n - m + 1 comparisons.10.5.1 The Simplified Boyer-Moore Algorithm
10.5.2 The Boyer-Moore-Horspool Algorithm
d[x] = min{s|s = m or (1 s < m and pattern[m - s] = x)}d['a'] = 3 d['b'] = 2 d['c'] = 6 d['d'] = 4 d['r'] = 1
bmhsearch( text, n, pat, m ) /* Search pat[1 . . m] in text[1..n] */
char text[], pat[];
int n, m;
{int d[MAX_ALPHABET_SIZE], i, j, k, lim;
for( k=0; k<MAX_ALPHABET_SIZE; k++ ) d[k] = m+1; /* Preprocessing */
for( k=1; k<=m; k++ ) d[pat[k]] = m+1-k;
pat[m+1] = CHARACTER_NOT_IN_THE_TEXT; /* To avoid having code */
/* for special case n-k+1=m */
lim = n-m+1;
for( k=1; k <= lim; k += d[text[k+m]] ) /* Searching */
{i=k;
for( j=1; text[i] == pat[j]; j++ ) i++;
if( j == m+1 ) Report_match_at_position( k );
}
/* restore pat[m+1] if necessary */
}
Figure 10.6: The Boyer-Moore-Horspool-Sunday algorithm
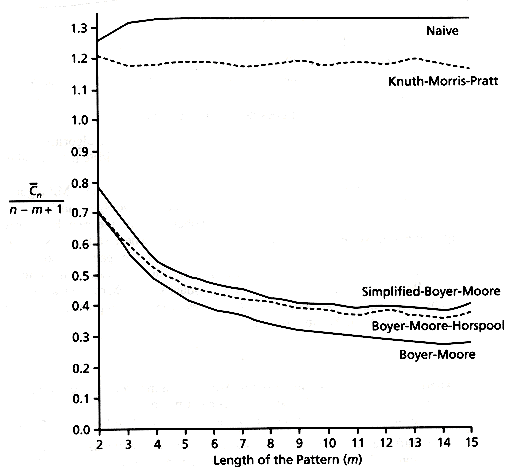
Figure 10.7: Expected number of comparisons for random text (c = 4)
10.6 THE SHIFT-OR ALGORITHM
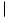 ) extra space and O(m + ) preprocessing time, where denotes the alphabet. Simplicity: the preprocessing and the search are very simple, and only bitwise logical operations, shifts, and additions are used. Real time: the time delay to process one text character is bounded by a constant. No buffering: the text does not need to be stored.
) extra space and O(m + ) preprocessing time, where denotes the alphabet. Simplicity: the preprocessing and the search are very simple, and only bitwise logical operations, shifts, and additions are used. Real time: the time delay to process one text character is bounded by a constant. No buffering: the text does not need to be stored.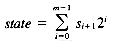 shift the vector state 1 bit to the left to reflect that we have advanced one position in the text. In practice, this sets the initial state of s1 to be 0 by default. update the individual states according to the new character. For this we use a table T that is defined by preprocessing the pattern with one entry per alphabet symbol, and the bitwise operator or that, given the old vector state and the table value, gives the new state.
shift the vector state 1 bit to the left to reflect that we have advanced one position in the text. In practice, this sets the initial state of s1 to be 0 by default. update the individual states according to the new character. For this we use a table T that is defined by preprocessing the pattern with one entry per alphabet symbol, and the bitwise operator or that, given the old vector state and the table value, gives the new state.state = (state << 1) or T [curr char]
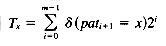
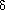 (C) is 0 if the condition C is true, and 1 otherwise. Therefore, we need m
(C) is 0 if the condition C is true, and 1 otherwise. Therefore, we need m  bits of extra memory, but if the word size is at least m, only words are needed. We set up the table by preprocessing the pattern before the search. This can be done in
bits of extra memory, but if the word size is at least m, only words are needed. We set up the table by preprocessing the pattern before the search. This can be done in  time.
time.T[a] = 11010 T[b] = 10101 T[c] = 01111 T[d] = 11111
text : a b d a b a b a b c
T[x] : 11010 10101 11111 11010 10101 11010 10101 11010 10101 01111
state: 11110 11101 11111 11110 11101 11010 10101 11010 10101 01111
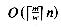 , where
, where  is the time to compute a shift or other simple operation on numbers of m bits using a word size of w bits. In practice, for small patterns (word size 32 or 64 bits), we have O(n) time for the worst and the average case. MAXSYM: size of the alphabet. For example, 128 for ASCII code. WORD: word size in bits (32 in our case). B: number of bits per individual state; in this case, one.
is the time to compute a shift or other simple operation on numbers of m bits using a word size of w bits. In practice, for small patterns (word size 32 or 64 bits), we have O(n) time for the worst and the average case. MAXSYM: size of the alphabet. For example, 128 for ASCII code. WORD: word size in bits (32 in our case). B: number of bits per individual state; in this case, one.sosearch( text, n, pat, m ) /* Search pat[1..m] in text[1..n] */
register char *text;
char pat[];
int n, m;
{register char *end;
register unsigned int state, lim;
unsigned int T[MAXSYM], i, j;
char *start;
if( m > WORD )
Abort( "Use pat size <= word size" );
for( i=0; i<MAXSYM; i++ ) T[i] = ~0; /* Preprocessing */
for( lim=0, j=1, i=1; i<=m; lim |= j, j <<= B, i++ )
T[pat[i]] &= ~j;
lim = ~(lim >>B);
text++; end = text+n+1; /* Search */
state = ~0; /* Initial state */
for( start=text; text end; text++ )
{state = (state <<B) | T[*text]; /* Next state */
if( state < lim ) Report_match_at_position( text-start-m+2 );
}
}
Figure 10.8: Shift-Or algorithm for string matching (simpler version)
 .
.initial = ~0; first = pat[1]; start = text; /* Search */
do {state = initial;
do {state = (state << B) | T[*text]; /* Next state */
if( state < lim ) Report_match_at_position( text-start-m+2 );
text++;
} while( state != initial );
while( text < end && *text != first ) /* Scan */
text++;
} while( text < end );
Figure 10.9: Shift-Or algorithm for string matching
*Based on implementation of Knuth, Morris, and Pratt (1977).
a set of characters (for example, match a vowel), a "don't care" symbol (match any character), or the complement of a set of characters.10.7 THE KARP-RABIN ALGORITHM
c ), the multiplications by d can be computed as shifts. The prime q is chosen as large as possible, such that (d + 1 )q does not cause overflow. We also impose the condition that d is a primitive root mod q. This implies that the signature function has maximal cycle; that is
rksearch( text, n, pat, m ) /* Search pat[1..m] in text[1..n] */
char text[], pat[]; /* (0 m = n) */
int n, m;
{int h1, h2, dM, i, j;
dM = 1;
for( i=1; i<m; i++ ) dM = (dM << D) % Q; /* Compute the signature */
h1 = h2 = O; /* of the pattern and of */
for( i=1; i<=m; i++ ) /* the beginning of the */
{ /* text */h1 = ((h1 << D) + pat[i] ) % Q;
h2 = ((h2 << D) + text[i] ) % Q;
}
for( i = 1; i <= n-m+1; i++ ) /* Search */
{if( h1 == h2 ) /* Potential match */
{for(j=1; j<=m && text[i-1+j] == pat[j]; j++ ); /* check */
if( j > m ) /* true match */
Report_match_at_position( i );
}
h2 = (h2 + (Q << D) - text[i]*dM ) % Q; /* update the signature */
h2 = ((h2 << D) + text[i+m] ) % Q; /* of the text */
}
}
Figure 10.10: The Karp-Rabin algorithm
h2 = h2*D - text[j-m]*dM + text[i+m]; /* update the signature value */
10.8 CONCLUSIONS

Figure 10.11: Simulation results for all the algorithms in random text (c = 30)
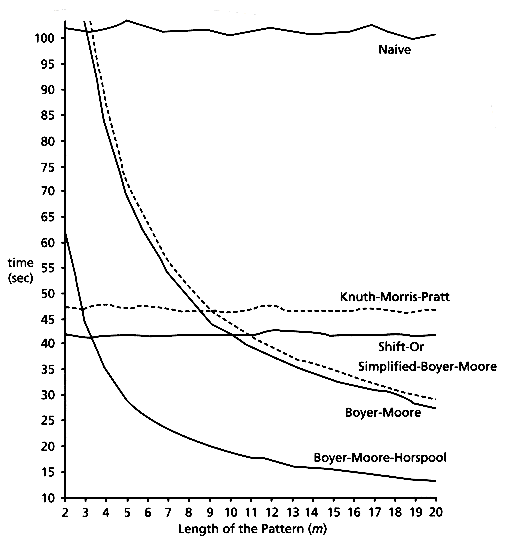
Figure 10.12: Simulation results for all the algorithms in English text
REFERENCES