


C++ does not have a string type per se, but instead provides library support for null-terminated character arrays, where the last character is a '\0' to signal the end of the array. Compared to strings in languages such as BASIC, null-terminated strings in C++ are quite primitive:
 You must deal with arrays that hopefully have enough memory allocated for them, and you must ensure the last character has the value '\0'. This is, to say the least, quite error prone.
You must deal with arrays that hopefully have enough memory allocated for them, and you must ensure the last character has the value '\0'. This is, to say the least, quite error prone.
It's not possible to store arbitrary binary data in a null-terminated string, since '\0', a valid binary number, would end the string prematurely. A better way would be to store the length of the string in a string header. Figure 6.1 contrasts these two approaches.
There's no high-level way to assign one string to another, nor to do efficient substring and concatenation operations. For example, to add one string to another, you must scan completely down the first string to find the point of concatenation.


As you might expect, you can get around the problems of null-terminated strings by defining your own strings. As always, you want a design that's efficient enough to be practical, yet at the same time high-level enough to be easily used. Toward this end, the String class given in this chapter has the following features:
The last feature is perhaps the most critical in the design of the String class. With lazy copying, it's possible to define substring and concatenation operations, safely and efficiently.
Lazy copying implies that aliasing is occurring, which of course is something to be handled carefully. As we did with the smart pointers in Chapter 5, we can handle this aliasing by using reference counting. But instead of reference counting each array element, the elements of a string will be reference counted as a unit.
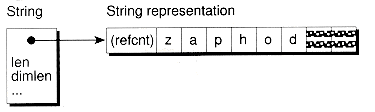
Strings can be defined with the same letter-envelope technique that we used for smart pointers, with two classes involved. The first class, StrRep, holds the string text and its associated reference count. The second class, String, provides the high-level interface and keeps track of which portion of the string text is used by a particular string. This layout of reference-counted strings is shown in Figure 6.2.
The StrRep class is defined as follows:
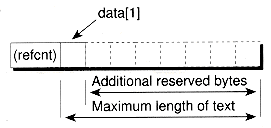
The peculiar thing about this class is that data, which is the start of the string text, appears to have room for only one character! However, the StrRep structure is actually meant to be allocated dynamically and, during that time, enough additional memory will be reserved to handle the desired maximum string length. This additional memory follows immediately after data. Figure 6.3 illustrates this layout.
We achieve this kind of dynamic allocation by overloading the new and delete operators for the StrRep class. Here is the new operator:
Normally, new takes just one argument: the size of the object to be allocated, in this case sizeof(StrRep). We've added a second argument, d, that indicates how long the text should be. The overloaded new operator then uses d to determine how much memory to actually allocate. The memory is allocated as though it were a simple array of characters. Keep in mind that the first portion of this memory will be occupied by the reference count. Here's how a call to new is made for StrRep objects:
Note the call to the constructor for StrRep after the new operator. The lexical ordering in this statement suggests what actually happens: first, new is called to allocate space for the object, then the object is constructed. The StrRep constructor is quite simple--it initializes the reference count to one. The text is left uninitialized, however:
Because of their special memory allocation scheme, StrRep objects must always be allocated dynamically. Otherwise, how would you allocate a text size greater than one? The exception to this rule is for the unique StrRep object, null_rep, that we've incorporated into our design. This object is a static member of the StrRep class and is thus statically allocated. As such, null_rep can hold only one byte of text. The purpose of null_rep is the same as used for the smart pointers in Chapter 5: to guarantee that a string will have somewhere to point to. Null strings always point to null_rep. You'll see later that this allows the String functions to quite elegantly handle null strings without doing any explicit testing.
The delete operator is responsible for deleting a StrRep object, which is pointed to by argument p in the delete( ) function.
Note that we delete the object as though it were a character array, which is exactly how it was allocated in the first place by new. Also, note that delete( ) won't ever be called for null_rep because, supposedly, its reference count will never go to zero. Because all StrRep objects besides null_rep are dynamically allocated, we don't need to explicitly declare a destructor for StrRep. The overloaded delete operator handles everything.
The StrRep class doesn't actually handle many of the reference counting chores. As was true with smart pointers, the envelope class (in this case String) handles the binding and unbinding.
With the StrRep class defined, we can show the definition for the String class:
The complete code for the String class--and it's associated StrRep class--is given on disk in the files strobj.h and strobj.cpp. A test program is given in the file strtst.cpp.
The String class is quite large, having more than 60 members. This is typical for a concrete data type. Ordinarily, you should try to avoid large classes, but many of the member functions here are used to make strings appear built-in to the language. Not all of the functions are strictly necessary, being mainly "convenience functions" that make it easier to work with strings. As a saving grace, many of these functions are simple enough to be inlined.
The String class has five data members: rep, text, len, dimlen, and grow_by. The most important is rep, which points to the associated StrRep object. Note that StrRep only keeps track of the actual text and the reference count for that text. It doesn't store the logical and dimensioned lengths, which is the reponsibility of the String class. Since the strings are to be resizable, we have members such as len, dimlen, and grow_by, which are used exactly as they were in the RVarray class of Chapter 4.
This brings up an important point. Since strings are to be resizable, why not implement them using an RVarray<char> class? In fact, we could. For instance, StrRep could be defined as:
We chose to use a more direct representation for several reasons: First, if we were to use an RVarray object, the memory layout for strings would be more complicated than necessary. It would be composed of the String object, the StrRep object, and the RVarray object inside of the Strep object, which has a pointer to the actual text. That's three separate pieces to be allocated on the heap, rather than just two with the more direct implementation. Also, the RVarray class is more general than we need, since it calls constructors and destructors for array elements, which in this case are characters that don't have constructors or destructors. (We can circumvent the latter problem by overriding the appropriate placement constructor and destructor templates to do nothing.)
Thus, even though the RVarray class could be used, it's probably better to implement a more direct design for strings. The code will be smaller and easier to understand, and the resulting String objects will be more compact. Having made these points, we should also tell you that the String class was implemented originally using an RVarray<char> class, and then this code was optimized specifically for character arrays. You'll notice that some of the member functions of String are similar, if not identical, to their RVarray counterparts. These functions include Realloc( ), InsReplAt( ), DeleteAt( ), Grow( ), GrowBy( ), FreeExtra( ), Length( ), and DimLength( ). Most of these functions will not be repeated here.
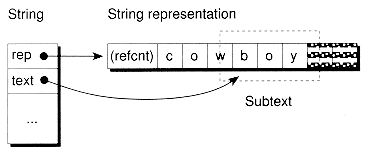
The last data member of the String class, text, is a character pointer to the start of the actual data for the string. Normally, text is set to point to the beginning of the data member of the corresponding StrRep object. However, for substrings, text will actually point to some offset from data. It wouldn't be strictly necessary to store a pointer here. We could use an integer representing the offset. However, pointing directly using text makes operations such as subscripting simpler and faster. Contrast these two logically equivalent functions:
The idea is to initialize text once when the string is built, with a statement such as:
Then, subsequent string operations don't have to keep adding the offset to find the start of the text. Figure 6.4 shows how to use the text pointer for a substring.
The String class has functions such as Bind( ), Unbind( ), and NewBinding( ) to handle the reference counting needed when binding and unbinding text to a string. These functions are similar to those used with the smart pointers of Chapter 5, and are called by the higher-level constructor, destructor, and assignment functions.
A full complement of constructors is defined for the String class. You can create strings with a specified starting size and growth increment, create strings that copy data from null-terminated strings, and create strings from raw memory bytes. Here are a few of the constructors:
The first constructor can actually be used as a default constructor, since both its arguments have defaults. An enumerated type, defined in String, holds a default initial size and growth increment:
You'll notice that this enumerated type has no name (that is, it's an anonymous enumerated type). You can use anonymous enumerated types like this to conveniently define and initialize integer-based constants in a class.
All three of the constructors shown call an auxiliary function, Alloc( ), which handles the initial allocation of the string object. Note the call to the overloaded StrRep new operator:
If Alloc( ) isn't able to allocate space for the string, a null string is constructed by first referencing the null_rep object (handled by the call to the overloaded new operator), and then setting the grow-by increment to zero. This prevents the null string from growing, and also allows other string operations (such as concatenation and subscripting) to behave properly without any explicit checks for a null string.
Note the logical length is always set to zero--regardless of whether the memory was allocated or not. Thus, to use a string, you must explicitly add text to it. Two of the constructors do this by calling the CopyN( ) function, (given later).
The destructor is responsible for unbinding the string from its possibly shared text, and deleting the text if necessary. The Unbind( ) function does all the work:
Here are some examples of constructing strings:
Unlike the other constructors, the following copy constructor doesn't actually do any copying of string data. Instead, the new string is bound to the same data as the old string by calling Bind( ). In other words, the copy constructor uses share semantics:
What isn't shared between two strings are the bookkeeping variables len, dimlen, grow_by, and text. Separate copies are maintained for them. This keeps the strings independent in terms of the way they interpret the length of the text, the text's starting location, and how the strings may be resized. This independence is useful in creating substrings, as you are about to see.
The assignment operator is defined with the same share semantics as the copy constructor:
To illustrate how two or more strings can have different interpretations of the same shared text, we'll look at how substrings are defined. The following constructor is at the heart of substring creation. Like the copy constructor, it uses share semantics. However, the substring's variables len, dimlen, grow_by, and text all have different values than the source string:
The only differences between a string and a substring is that the text pointer may start at some offset from data, and that dimlen doesn't have quite the same meaning for substrings as it does for normal strings. In normal strings, dimlen is the actual number of characters allocated in the corresponding StrRep object. For substrings, dimlen gives the maximum extent that the substring is allowed to cover over the underlying shared text.
Rather than call the substring constructor directly, the following convenience functions are defined to return left, mid, and right substrings of another string:
The substring functions call the substring constructor to do most of the work. Note that the gb parameter, which defines the grow_by increment, has a default value of String::definc for the substring constructor. The default is used because the substring functions don't specify this parameter.
In each substring function, the newly created substring is returned by value, which causes the object's copy constructor to be called. In the case here, this means two identical substrings are created, the second to be the one actually returned by the function. However, since the String copy constructor uses share semantics, very little is actually copied. The initially constructed substring is destroyed upon the function return, but because of the reference counting, the shared text lives on. Both the original source string and the returned substring have references to it.
These examples illustrate how to use the substring functions:
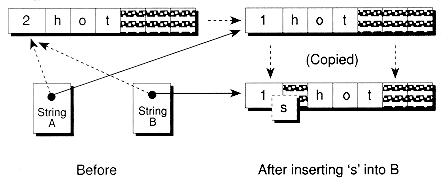
You might wonder what happens if you modify a substring. Do both the substring and original string get modified? Also, what happens if you make substrings overlap, as shown in Figure 6.5? Won't things get confused? The answer to all of these questions is "No," as we'll explain in the next section.
Lazy copying allows strings that have been copied to share their text, until one of the strings gets modified. Only then does the text actually get copied. We'll use the term unique string for a string that has data with a reference count of one. Thus, we want to ensure a string is unique before modifying it. If it's not unique, a copy of its data is made. Figure 6.6 illustrates this process.
The following functions allow us to take a string and make it unique:
The EnsureUnique( ) function returns one if it was able to guarantee a unique string. Otherwise, it returns zero, which means it was unable to allocate enough space to make a copy of the string. The following InsReplAt( ) function shows how the EnsureUnique( ) function can be used:
The InsReplAt( ) function is essentially the same as the InsertNAt( ) function used in the RVarray class, except this one also allows text replacement as well as insertions. Note how a check is made to ensure that the string is unique before modifying it. If the string can't be made unique, the function exits and returns a failure code of zero. The DeleteAt( ) function (not shown) uses a similar technique.
By placing calls to EnsureUnique( ) judiciously, it's possible to make the check for uniqueness in only a few places. For instance, InsReplAt( ) is a workhorse function called by many of the other string functions. To illustrate, the following CopyN( ) function copies raw bytes of data into a string. The CopyN( ) function in turn is called by two Copy( ) functions, and another form of overloaded assignment:
Unlike the standard assignment operator (which assigns one String to another), this operator assigns a null-terminated string to a String object, and uses copy semantics rather than share semantics. (The latter would make no sense in this case). Here is an example:
When using subscripts, we must be careful when we modify a string. We've defined an overloaded subscripting operator that allows us to treat a String like any other subscripted array. Since the returned element may be an lvalue(on the left-side of an assignment), the subscripting operation may modify the string. Thus, we must be careful to make the String unique before returning the element:
What do we do if we can't make the string unique? The way operator[] is defined, we must return a reference to something. That something might be modified, so we reference the lone data byte in null_rep and allow it to be modified. This may not be the best approach. Instead, we might want to print an error message and exit the program. Note the call to the CHECK( ) macro. This is the same macro used by the Array class to invoke range checking on subscripts.
Here's an example showing the use of the subscript operator:
When the last statement is executed, EnsureUnique( ) is called to ensure that the string data is unique before we modify the eleventh element. Note that EnsureUnique( ) is called even when the content of the string element is only being read, as in:
This situation is unfortunate, because it means an unnecessary copy of the string is made. Unfortunately, there's no way to detect it. About the only thing we can do is declare the string as a constant, and then provide a second operator[]( ) function meant for constant strings. This operator doesn't have to ensure that the string is unique. For instance:
The critical part of this design is that the operator[ ]( ) function passes back a constant reference to the element, not just a reference. This is what disallows the updating.
String concatenation is another form of string updating, where you add a copy of one string to the end of another. The '+=' operator is overloaded to implement string concatenation. Three versions are supplied to allow you to add one String object to another, add a null-terminated string, or add a single character. The string grows in size if necessary:
All of these functions call the following Concatenate( ) function, which in turn calls the InsReplAt( ) function to do all the work (including ensuring uniqueness):
The '+' operator is also overloaded to add two strings together, resulting in a third string. The following overloaded '+' operator cleverly lets the '+=' operator do most of the work:
Note how a string is constructed to be big enough to hold the result, and how this result is returned from the function by value. (That's the only way we can do it.) Again, because of lazy copying, only a minimum amount of data is actually moved during the function return process.
Here are some examples of string concatenation and string addition:
To make strings look as much as possible like built-in types, all of the comparison operators are overloaded. Here's how two of them are defined:
The other comparison operators are defined similarly. They all call the following Compare( ) function, which does the actual work:
These examples show the use of string comparisons:
Three Find( ) functions are defined to search for the starting index of a pattern in a string. The pattern can be another String object, a null-terminated string, or a sequence of raw bytes of a specified length. Here's how Find( ) is defined for null-terminated pattern strings. The others are defined similarly:
Note that a value of 0xffff is returned if no match is found. (We can't use a flag such as -1 since the indexes are unsigned.)
An optional ofs parameter (which defaults to zero) can be defined to specify where to start the search in the string. The algorithm used to search for a pattern in a string is implemented in a brute force way. Other, more sophisticated methods are available to search for patterns in a string, as given in the companion volume [Flamig 93]. You could incorporate those algorithms into the Find( ) functions.
Here's an example that shows how to use Find( ) to locate all occurrences of the pattern "the" in a string:
Also defined are four Fill( ) functions, which can fill a string--up to the dimensioned length--with a pattern that can be either another string, a null-terminated string, a single characer, or a pattern of raw bytes of a specified length. The latter function is used as the workhorse function for the others:
As is true for all functions that modify a string, we must ensure the uniqueness of the string before filling it. Here's an example where we fill a string with a pattern up to the maximum length of the string:
It's difficult to imagine how the String class could be implemented more robustly or efficiently. It successfuly defines strings as concrete data types and provides a lot more versatility and flexibility than null-terminated strings. At the same time, String objects are quite safe, due to the use of reference counting and the incorporation of a special null_rep object. (Although, as with anything in C++, it's possible to compromise that safety through typecasting trickery.)
At what cost does this versatility come? Analyzing the data structures, we see that each string has one StrRep pointer, a character pointer, and three integers to keep track of string lengths and resizability. In addition, each string has an associated StrRep object, which contains one integer and then the data itself.
In contrast, a null-terminated string has just the text and an extra null byte at the end. We see a net difference, then, of two pointers--and three integers minus a character. Don't forget that a StrRep object consumes heap space whether we want it to or not, while a null-terminated string does not require heap space. Partially offsetting this disadvantage is the fact that multiple String objects can share the same StrRep heap space. This makes heap usage less of a factor when a lot of substring operations take place.
The extra space requirement is the price paid for speed: String objects can be copied, concatenated, and made into substrings much more efficiently than null-terminated strings. In addition, finding the length of a String object involves a simple member reference, not a scan down the array as is the case for null-terminated strings. Once again, we see the almost inevitable speed versus space tradeoff. Here, the tradeoff is more than worth it. The String class is certainly efficient and robust enough for routine use.
Strings are implemented as a concrete data type, with the appropriate constructors, destructors, and overloaded operators defined. Resizable, variable-length strings of arbitrary binary data are supported. Concatenation, substring, pattern matching and filling operations are supported. The strings use lazy copying. When doing string assignments or creating substrings, string text is shared. No copying takes place until one of the strings is modified. REFERENCE COUNTING REVISITED
THE STRREP CLASS
class StrRep {private:
friend class String;
unsigned refcnt; // Reference count for the text of the string
char data[1]; // Start of the string text
StrRep( );
void *operator new(size_t n, unsigned d);
void operator delete(void *p);
static StrRep null_rep; // For null strings
};
void *StrRep::operator new(size_t n, unsigned d)
// Here, n is sizeof(StrRep) and d is the desired
Figure 6.2 The layout of reference-counted strings.
// number of allocated characters in the string.
// If allocation fails, we reference null_rep.
{// Note: n already accounts for one of the characters
void *p = new char[n+d-1];
if (p == 0) {p = &null_rep;
((StrRep *)p)->refcnt++;
}
return p;
}
// Allocate enough room for 10 characters
StrRep *p = new(10) StrRep;
StrRep::StrRep( )
{refcnt = 1;
}
Figure 6.3 Dynamic allocation of a StrRep object.
void StrRep::operator delete(void *p)
{delete[] (char *)p;
}
THE STRING CLASS
class String {private:
StrRep *rep;
char *text; // Pointer to start of string text
unsigned dimlen; // Maximum length of text without reallocation
unsigned len; // Logical length of text
int grow_by; // Minimum resizing increment
enum { defsize = 16, definc = 16 };int Alloc(unsigned n, int gb);
void Bind(const String &s);
void Unbind( );
void NewBinding(const String &s);
public:
String(unsigned n = String::defsize, int gb = String::definc);
String(const String &s);
String(const String &s,
unsigned ofs, unsigned n, int gb = String::definc);
String(const char *s, int gb = String::definc);
String(const char *s, unsigned n, int gb = String::definc);
~String();
int IsNull() const;
int IsUnique() const;
String Clone() const;
int EnsureUnique();
String &operator=(const String &s);
void Copy(const char *s);
void Copy(const String &s);
String &operator=(const char *s);
#ifndef NO_RANGE_CHECK
unsigned CheckIndx(unsigned i) const;
#endif
char &operator[](unsigned i);
const char &operator[](unsigned i) const;
unsigned DimLength() const;
unsigned Length() const;
int GrowBy(unsigned amt);
int Grow();
int FreeExtra();
void ChgGrowByInc(int gb);
void SetLength(unsigned n);
int Realloc(unsigned new_dimlen, int keep=1);
void CopyN(const char *s, unsigned n);
unsigned InsReplAt
(unsigned p, const char *s, unsigned n, int ins=1);
unsigned DeleteAt(unsigned p, unsigned n);
char *Text();
const char *Text() const;
unsigned InsertAt(unsigned p, const char *s, unsigned n);
unsigned InsertAt(unsigned p, const char *s);
unsigned InsertAt(unsigned p, const String &s);
unsigned ReplaceAt(unsigned p, const char *s, unsigned n);
unsigned ReplaceAt(unsigned p, const char *s);
unsigned ReplaceAt(unsigned p, const String &s);
void Fill(const char c, unsigned ofs = 0, unsigned m = 0);
void Fill(const char *p, unsigned n, unsigned ofs=0, unsigned m=0);
void Fill(const char *s, unsigned ofs = 0, unsigned m = 0);
void Fill(const String &s, unsigned ofs = 0, unsigned m = 0);
const char *String::NullTermStr();
String Mid(unsigned p, unsigned n) const;
String Left(unsigned n) const;
String Right(unsigned n) const;
unsigned Find(char *s, unsigned ofs=0) const;
unsigned Find(unsigned n, char *s, unsigned ofs=0) const;
unsigned Find(const String &s, unsigned ofs=0) const;
void Concatenate(const char *s, unsigned n);
void operator+=(const String &s);
void operator+=(const char *s);
void operator+=(const char c);
friend String operator+(const String &a, const String &b);
friend int Compare(const String &a, const String &b);
friend int operator==(const String &a, const String &b);
friend int operator!=(const String &a, const String &b);
friend int operator>(const String &a, const String &b);
friend int operator>=(const String &a, const String &b);
friend int operator<(const String &a, const String &b);
friend int operator<=(const String &a, const String &b);
friend ostream &operator<<(ostream &strm, const String &s);
friend istream &operator>>(istream &strm, String &s);
};

class StrRep { // Alternative representationprivate:
unsigned refcnt;
RVarray<char>;
...
};
const char &operator[](unsigned i) const
// One way to do subscripting
{return rep->data[i+ofs]; // Ofs = where substring starts
}
const char &operator[](unsigned i) const
// Another, simpler way using a pre-nitialized text
// pointer to the start of the substring
{return text[i];
}
text = rep->data[i+ofs];
CONSTRUCTING STRINGS
String::String(unsigned n, int gb)
// Constructor to create a string of allocated
// length n, and a grow_by increment of gb.
{Alloc(n, gb) ;
}
String::String(const char *s, int gb)
// Creates a string by copying bytes from a null-
// terminated array, with a grow_by increment of gb.
{unsigned slen = strlen(s);
unsigned dlen = slen;
if (gb) { // Compute next highest multiple of gbunsigned addval = (dlen % gb) ? gb : 0;
dlen = (dlen / gb) * gb + addval ;
}
Figure 6.4 The string text pointer.
if (Alloc(dlen, gb)) CopyN(s, slen);
}
String::String(const char *s, unsigned n, int gb)
// Create a string of allocated length n, grow_by
// increment of gb, copying bytes from s
{if (Alloc(n, gb)) CopyN(s, n);
}
enum { defsize = 16, definc = 16 } ;int String::Alloc(unsigned n, int gb)
// Allocate a new string of allocated size n, and
// a grow by increment of gb
{rep = new(n) StrRep; // Allocate string rep
text = rep->data; // Point to starting text element
len = 0;
if (IsNull()) { // Wasn't able to allocate spacedimlen = 1; // null_rep has one byte of text
grow_by = 0;
return 0; // Indicate failure
}
else {dimlen = n;
grow_by = gb;
return 1; // Indicate success
}
}
String::~String()
// Destructor unbinds from the shared text
{Unbind();
}
// Empty string with initial dimensioned length of 10,
// and a default growth increment
String a(10);
// Empty string with intial dimensioned length of 10
// that can't grow
String b(10,0);
// String containing a copy of a null-terminated string,
// with default growth increment
String s("This is a test");// String containing a copy of some raw bytes, with a
// default growth increment
char bytes[7] = {34, 56, 7, 42, 17, 25, 55];String t(bytes, 7);
// String that's a copy of another string
String u(t):
STRING COPYING
String::String(const String &s)
// Copy constructor, which uses share semantics
{Bind(s);
len = s.len;
dimlen = s.dimlen;
grow_by = s.grow_by;
text = s.text;
}
String &String::operator=(const String &s)
// Assigns one string to another. Checks for assignment
// to self. Uses share semantics.
{if (this != &s) {NewBinding(s);
len = s.len;
dimlen = s.dimlen;
grow_by = s.grow_by;
text = s.text;
}
return *this;
}
CREATING SUBSTRINGS
String::String(const String &s, unsigned ofs, unsigned n, int gb)
// A constructor to create a substring of string s.
// The substring shares its data with s, starting at
// offset ofs, and of length n. It has an allocated
// length of n, and a grow_by increment of gb.
{Bind(s);
// Keep ofs and length in range
if (ofs > s.len-1) ofs = s.len-1;
if (n + ofs > s.len) n = s.len-ofs;
// Set max and logical bounds of the substring
dimlen = n;
len = n;
grow_by = gb;
text = s.text + ofs; // Compute starting text element
}
String String::Left(unsigned n) const
// Returns the left substring of length n
{return String(*this, 0, n);
}
String String::Mid(unsigned p, unsigned n) const
// Returns a substring of length n, starting at
// index p
{return String(*this, p, n);
}
String String::Right(unsigned n) const
// Returns a right substring of length n
{if (n > len) n = len; // Trap possible overflow
return String(*this, len-n, n);
}
String s("Supercalifragilisticexpialadocius");String Super = s.Left(5);
String fragil = s.Mid(9,6);
String docius = s.Right(6);
IMPLEMENTING LAZY COPYING
Figure 6.5 Overlapping substrings.
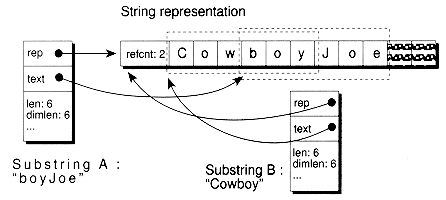
Figure 6.6 Updating shared string text.
int String::IsUnique() const
// Returns 1 if the string's text has refcnt == 1
{return rep->refcnt == 1;
}
String String::Clone() const
// Return a copy of this string. The copy will
// be unique (with refcnt = 1).
// Note: If allocation of copy fails, a null
// string is returned.
{String temp(dimlen, grow_by);
temp.CopyN(text, len);
return temp;
}
int String::EnsureUnique()
// Ensures that this string uniquely owns its string
// rep (ie. the reference count is 1).
// Might have to copy the string text to ensure this.
// Returns 1 if it can make the string unique, O if it can't (allocation
// for copy failed).
{if (!IsUnique( )) { // Need to copy to make uniqueString &c = Clone( ); // Attempt to copy
if (c.IsNull( )) return 0; // Couldn't copy
NewBinding(c); // Bind to copy
text = c.text; // Reset starting text pointer
}
return 1;
}
unsigned String::
InsReplAt(unsigned p, const char *s, unsigned n, int ins)
// Inserts/replaces (depending on ins flag) the data pointed to
// by s into the string. Up to n elements are inserted/replaced
// (truncating if necesary), starting at position p (counted
// by zero). The string will grow in size if inserting and needed
// and grow_by != 0. The size it will grow to will be the next highest
// multiple of grow_by >= the size needed. If p >= len, then the
// data is concatenated onto the end. Returns number of elements
// inserted/replaced, or 0 if error occurs.
{unsigned room, needed, addval;
if (ins) {room = dimlen - len;
if (n > room && grow_by != 0) {needed = (n - room);
addval = (needed % grow_by) ? grow_by : 0;
needed = (needed / grow_by) * grow_by + addval;
// Grow the string by needed amount. Note that the
// growth may fail, in which case the string stays
// the same size, with data intact.
GrowBy(needed);
}
}
// Note: At this point, GrowBy( ) may have already made
// our string unique
if (!EnsureUnique( )) return 0; // Can't update
// Don't allow gaps
if (p >= len) p = len; // We'll be concatenating
if (ins) {// Keep things in range. May have to truncate.
if (n > dimlen - len) n = dimlen - len;
if (p < len) {// Make room for inserted data somewhere in the middle
memmove(text+p+n, text+p, len-p);
}
}
else {// Keep things in range. May have to truncate.
if (n > dimlen - p) n = dimlen - p;
}
// Copy in source; compute final length
memmove(text+p, s, n);
if (ins) {len += n;
}
else {if ((p+n) > len) len = p+n;
}
return n;
}
void String::CopyN(const char *s, unsigned n)
// Copies the data from s, resizing the string if n is
// larger than the dimensioned length, and grow_by != 0.
// The string is guaranteed unique as well.
// If the string can't be resized, it keeps its old size,
// and not all of the data will be copied.
{len = 0; // Cleverly set length to zero
InsReplAt(0, s, n); // and let InsReplAt() do all the work
}
void String::Copy(const char *s)
// Copies data from a null-terminated string into
// this object. The string might be resized if
// necessary and allowable.
{CopyN(s, strlen(s));
}
void String::Copy(const String &s)
// Copies data from String s into this string.
// The string might be resized if necessary
// and allowable.
{CopyN(s.text, s.len);
}
String &String::operator=(const char *s)
// Copy a null-terminated string into this object. The
// string might be resized if necessary and allowable.
{Copy(s);
return *this;
}
String s(80);
s = "The answer is 42"; // Copied into s
SUBTLE SUBSCRIPTING ISSUES
char &String::operator[](unsigned i)
// Subscripting that may update a character in the string,
// so we must make the string unique
{if (EnsureUnique( ))
return text[CHECK(i)];
else return StrRep::null_rep.data[0];
}
String s("I can't speel");s[11] = 'l'; // Correct the spelling
char c = s[11]; // s still is made unique
const char &String::operator[](unsigned i) const
// Read only version of subscript operator.
// Note the two uses of the const keyword!
{return text[CHECK(i)];
}
const String s("I can't speel"); // A constant string// Invoke constant subscript operator
char c = s[11]; // Fine, just reading
s[11] = 'l'; // Can't do. Compiler error.
STRING CONCATENATION
void String::operator+=(const String &s)
// Adds String s to the end of this string
{Concatenate(s.text, s.len);
}
void String::operator+=(const char *s)
// Adds a null-terminated string s onto the end of
// this string. The null byte isn't added.
{Concatenate(s, strlen(s));
}
void String::operator+=(const char c)
// Adds a single character to the end of the string
{Concatenate(&c, 1);
}
void String::Concatenate(const char *s, unsigned n)
// Adds n bytes from s onto the end of this string
{InsReplAt(len, s, n);
}
String operator+(const String &a, const String &b)
// Adds two strings together and returns the result
{String r(a.text->Length( ) + b.text->Length( ));
r += a;
r += b;
return r;
}
String a("This is "), b("a test);String c(80);
c = a + b;
c += " of the emergency broadcast system";
STRING COMPARISONS
int operator==(const String &a, const String &b)
{return Compare(a, b) == 0;
}
int operator>=(const String &a, const String &b)
{return Compare(a, b) >= 0;
}
int Compare(const String &a, const String &b)
// Uses unsigned decimal value of characters for collating order.
// Returns -1 if a < b, 0 if a == b, and 1 if a > b.
{unsigned an = a.text->Length( );
unsigned bn = b.text->Length( );
unsigned sn = (an < bn) ? an : bn;
unsigned char *ap = (unsigned char *)a.text->Data( );
unsigned char *bp = (unsigned char *)b.text->Data( );
for (unsigned i = 0; i<sn; i++) {if (*ap < *bp) return -1; // a < b
if (*ap++ > *bp++) return 1; // a > b
}
// Equal unless lengths are different
if (an == bn) return 0;
if (an < bn) return -1;
return 1;
}
String a("abc"), x("xyz"), s("ab");if (a < x) cout << "Yes"; else cout << "No"; // Returns "Yes"
if (a == s) cout << "Yes"; else cout << "No"; // Returns "No"
PATTERN MATCHING AND FILLING
unsigned String::Find(char *s, unsigned ofs) const
// Returns index of first occurrence of pattern s
// (assumed to be null-terminated) beginning at
// offset ofs. Returns Oxffff if not found, or
// offset not in bounds.
{char *q = text + ofs; // Start of string data
char *p = q; // Next string element ptr
char *t = s; // Next pattern element ptr
unsigned i = ofs; // Next string element index
while(i<len && *t) {if (*p == *t) {t++;
if (*t == 0) return i; // We found it!
p++ ;
}
else {i++;
q++;
p = q;
t = s;
}
}
return Oxffff;
}
String test("The cow jumped over the moon");char pat[] = "the";
unsigned ofs = 0;
while((ofs = test.Find(pat, ofs)) != Oxffff) {cout << "Pattern found at offset " << ofs << '\n';
ofs += strlen(pat); // Start at next possible spot in string
}
void String::
Fill(const char *p, unsigned n, unsigned ofs, unsigned m)
// Fills the string with pattern p of length n, up to length m
// or the dimensioned length of the string, whichever is smaller,
// starting at offset ofs. If m is 0, it means use the dimensioned
// length of the string. Pattern repeats if necessary. Does not
// cause the string to grow, but it may have to make a copy to
// ensure the string is unique.
{if (dimlen == 0 || n == 0) return; // Nothing to do
if (!EnsureUnique( )) return; // Can't fill
// Keep parms in range
if (m == 0) m = dimlen;
if (ofs >= dimlen) ofs = dimlen-1; // dimlen must be > 0!
if (m+ofs > dimlen) m = dimlen - ofs;
len = m+ofs;
char *t = text+ofs;
if (n == 1) {// Use fast method for single character fills
memset(t, *p, m);
}
else {// Multi-character pattern fills
unsigned np = n;
const char *s = p;
while(m) {*t++ = *s++;
if (np == 1) {np = n;
s = p;
} else np-;
m-;
}
}
}
String s(15);
s.Fill("1234567890"); // s = "123456789012345" DESIGN CRITIQUE