


The process of sorting, or ordering, a list of objects according to some linear order such as ?/FONT> for numbers is so fundamental, and is done so frequently, that a careful examination of the subject is warranted. We shall divide the subject into two parts -- internal and external sorting. Internal sorting takes place in the main memory of a computer, where we can use the random access capability of the main memory to advantage in various ways. External sorting is necessary when the number of objects to be sorted is too large to fit in main memory. There, the bottleneck is usually the movement of data between main and secondary storage, and we must move data in large blocks to be efficient. The fact that physically contiguous data is most conveniently moved in one block constrains the kinds of external sorting algorithms we can use. External sorting will be covered in Chapter 11.
In this chapter, we shall present the principal internal sorting algorithms. The simplest algorithms usually take O(n2) time to sort n objects and are only useful for sorting short lists. One of the most popular sorting algorithms is quicksort, which takes O(nlogn) time on average. Quicksort works well for most common applications, although, in the worst case, it can take O(n2) time. There are other methods, such as heapsort and mergesort, that take O(nlogn) time in the worst case, although their average case behavior may not be quite as good as that of quicksort. Mergesort, however, is well-suited for external sorting. We shall consider several other algorithms called "bin" or "bucket" sorts. These algorithms work only on special kinds of data, such as integers chosen from a limited range, but when applicable, they are remarkably fast, taking only O(n) time in the worst case.
Throughout this chapter we assume that the objects to be sorted are records consisting of one or more fields. One of the fields, called the key, is of a type for which a linear-ordering relationship ?/FONT> is defined. Integers, reals, and arrays of characters are common examples of such types, although we may generally use any key type for which a "less than" or "less than or equal to" relation is defined.
The sorting problem is to arrange a sequence of records so that the values of their key fields form a nondecreasing sequence. That is, given records r1, r2, . . . ,rn, with key values k1, k2, . . . , kn, respectively, we must produce the same records in an order ri1, ri2, . . . , rin, such that ki1 ?/FONT> ki2 ?/FONT> ???/FONT> ?/FONT> kin. The records all need not have distinct values, nor do we require that records with the same key value appear in any particular order.
We shall use several criteria to evaluate the running time of an internal sorting algorithm. The first and most common measure is the number of algorithm steps required to sort n records. Another common measure is the number of comparisons between keys that must be made to sort n records. This measure is often useful when a comparison between a pair of keys is a relatively expensive operation, as when keys are long strings of characters. If the size of records is large, we may also want to count the number of times a record must be moved. The application at hand usually makes the appropriate cost measure evident.
Perhaps the simplest sorting method one can devise is an algorithm called "bubblesort." The basic idea behind bubblesort is to imagine that the records to be sorted are kept in an array held vertically. The records with low key values are "light" and bubble up to the top. We make repeated passes over the array, from bottom to top. As we go, if two adjacent elements are out of order, that is, if the "lighter" one is below, we reverse them. The effect of this operation is that on the first pass the "lightest" record, that is, the record with the lowest key value, rises all the way to the top. On the second pass, the second lowest key rises to the second position, and so on. We need not, on pass two, try to bubble up to position one, because we know the lowest key already resides there. In general, pass i need not try to bubble up past position i. We sketch the algorithm in Fig. 8.1, assuming A is an array[1..n] of recordtype, and n is the number of records. We assume here, and throughout the chapter, that one field called key holds the key value for each record.
(1) for i := 1 to n-1 do (2) for j := n downto i+1 do (3) if A[j].key < A[j-1].key then (4) swap(A[j], A[j-1])
Fig. 8.1. The bubblesort algorithm.
The procedure swap is used in many sorting algorithms and is defined in Fig. 8.2.
Example 8.1. Figure 8.3 shows a list of famous volcanoes, and a year in which each erupted.
For this example we shall use the following type definitions in our sorting programs:
procedure swap ( var x, y: recordtype )
{ swap exchanges the values of x and y }
var
temp: recordtype;
begin
temp := x;
x := y;
y := temp
end; { swap }
Fig. 8.2. The procedure swap.

Fig. 8.3. Famous volcanoes.
type
keytype = array[1..10] of char;
recordtype = record
key: keytype; { the volcano name }
year: integer
end;
The bubblesort algorithm of Fig. 8.1 applied to the list of Fig. 8.3 sorts the list in alphabetical order of names, if the relation ?/FONT> on objects of this key type is the ordinary lexicographic order. In Fig. 8.4, we see the five passes made by the algorithm when n = 6. The lines indicate the point above which the names are known to be the smallest in the list and in the correct order. However, after i = 5, when all but the last record is in its place, the last must also be in its correct place, and the algorithm stops.
At the start of the first pass, St. Helens bubbles past Vesuvius, but not past Agung. On the remainder of that pass, Agung bubbles all the way up to the top. In the second pass, Etna bubbles as far as it can go, to position 2. In the third pass, Krakatoa bubbles past Pelee, and the list is now in lexicographically sorted order although according to the algorithm of Fig. 8.1, two additional passes are made.

Fig. 8.4. The passes of bubblesort.
The second sorting method we shall consider is called "insertion sort," because on the ith pass we "insert" the ith element A[i] into its rightful place among A[1], A[2], . . . , A[i-1], which were previously placed in sorted order. After doing this insertion, the records occupying A[1], . . . , A[i] are in sorted order. That is, we execute
for i := 2 to n do
move A[i] forward to the position j ?/FONT>
i such that
A[i] < A[k] for j ?/FONT>
k < i, and
either A[i] ?/FONT> A[j-1] or
j = 1
To make the process of moving A[i] easier, it helps to introduce an element A[0], whose key has a value smaller than that of any key among A[1], . . . ,A[n]. We shall postulate the existence of a constant -?/FONT> of type keytype that is smaller than the key of any record that could appear in practice. If no constant -?/FONT> can be used safely, we must, when deciding whether to push A[i] up before position j, check first whether j = 1, and if not, compare A[i] (which is now in position j) with A[j-1]. The complete program is shown in Fig. 8.5.
(1) A[0].key := -?/FONT>;
(2) for i := 2 to n do begin
(3) j := i;
(4) while A[j] < A[j-1] do begin
(5) swap(A[j], A[j-1]);
(6) j := j-1
end
end
Fig. 8.5. Insertion sort.
Example 8.2. We show in Fig. 8.6 the initial list from Fig. 8.3, and the result of the passes of insertion sort for i = 2, 3, . . . , 6. After each pass, the elements above the line are guaranteed to be sorted relative to each other, although their order bears no relation to the records below the line, which will be inserted later.

Fig. 8.6. The passes of insertion sort.
The idea behind "selection sorting" is also elementary. In the ith pass, we select the record with the lowest key, among A[i], . . . , A[n], and we swap it with A[i]. As a result, after i passes, the i lowest records will occupy A[1] , . . . , A[i], in sorted order. That is, selection sort can be described by
for i := 1 to n-1 do
select the smallest among A[i], . . . , A[n] and
swap it with A[i];
A more complete program is shown in Fig. 8.7.
Example 8.3. The passes of selection sort on the list of Fig. 8.3 are shown in Fig. 8.8. For example, on pass 1, the ultimate value of lowindex is 4, the position of Agung, which is swapped with Pelee in A[1].
The lines in Fig. 8.8 indicate the point above which elements known to be smallest appear in sorted order. After n - 1 passes, record A[n], Vesuvius in Fig. 8.8, is also in its rightful place, since it is the element known not to be among the n - 1 smallest.
Bubblesort, insertion sort, and selection sort each take O(n2) time, and will take W(n2) time on some, in fact, on most input sequences of n elements. Consider bubblesort in Fig. 8.1. No matter what recordtype is, swap takes a constant time. Thus lines (3) and (4) of Fig. 8.1 take at most c1 time units for some constant c1. Hence for a fixed value of i, the loop of lines (2- 4)
var
lowkey: keytype; { the currently smallest key found
on a pass through A[i], . . . , A[n] }
lowindex : integer; { the position of lowkey }
begin
(1) for i := 1 to n-1 do begin
{ select the lowest among A[i], . . . , A[n] and swap it with
A[i] }
(2) lowindex := i;
(3) lowkey := A[i].key;
(4) for j := i + 1 to n do
{ compare each key with current lowkey }
(5) if A[j].key < lowkey then begin
(6) lowkey := A[j].key;
(7) lowindex := j
end;
(8) swap(A[i], A[lowindex])
end
end;
Fig. 8.7. Selection sort.

Fig. 8.8. Passes of selection sort.
takes at most c2(n-i) steps, for some constant c2; the latter constant is somewhat larger than c1 to account for decrementation and testing of j. Consequently, the entire program takes at most

steps, where the term c3n accounts for incrementating and testing i. As the latter formula does not exceed (c2/2+c3)n2, for n ?/FONT> 1, we see that the time complexity of bubblesort is O(n2). The algorithm requires W(n2) steps, since even if no swaps are ever needed (i.e., the input happens to be already sorted), the test of line (3) is executed n(n - 1)/2 times.
Next consider the insertion sort of Fig. 8.5. The while-loop of
lines (4-6)
of Fig. 8.5 cannot take more than O(i) steps, since j is initialized to i at line
(3), and decreases each time around the loop. The loop terminates by the
time j = 1, since A[0] is -?/FONT>, which forces the test of
line (4) to be false when
j = 1. We may conclude that the for-loop of lines (2-6) takes at most ![]() steps for some constant c. This sum is O(n2).
steps for some constant c. This sum is O(n2).
The reader may check that if the array is initially sorted in reverse
order,
then we actually go around the while-loop of lines (4-6) i-1 times, so line
(4) is executed
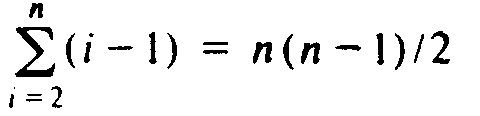 times. Therefore, insertion
sort
requires W(n2) time in the worst case. It can
be shown that this smaller
bound holds in the average case as well.
times. Therefore, insertion
sort
requires W(n2) time in the worst case. It can
be shown that this smaller
bound holds in the average case as well.
Finally, consider selection sort in Fig. 8.7. We may check that the
inner
for-loop of lines (4-7) takes O(n-i) time, since j ranges from i+1 to
n.
Thus the total time taken by the algorithm is c
 , for some constant c.
This sum, which is cn(n - 1)/2, is seen easily to be O(n2).
Conversely, one
can show that line (5), at least, is executed
, for some constant c.
This sum, which is cn(n - 1)/2, is seen easily to be O(n2).
Conversely, one
can show that line (5), at least, is executed
 times
regardless of the initial array A, so selection sort takes W(n2) time in the
worst case and the average case as well.
times
regardless of the initial array A, so selection sort takes W(n2) time in the
worst case and the average case as well.
If the size of records is large, the procedure swap, which is the only place in the three algorithms where records are copied, will take far more time than any of the other steps, such as comparison of keys and calculations on array indices. Thus, while all three algorithms take time proportional to n2, we might be able to compare them in more detail if we count the uses of swap.
To begin, bubblesort executes the swap step of line (4) of Fig. 8.1 at most
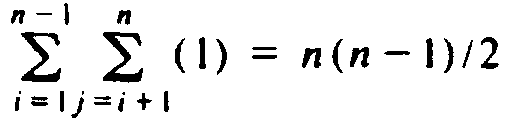
times, or about n2/2 times. But since the execution of line (4) depends on the outcome of the test of line (3), we might expect that the actual number of swaps will be considerably less than n2/2.
In fact, bubblesort swaps exactly half the time on the average, so
the
expected number of swaps if all initial sequences are equally likely is about
n2/4. To see this, consider two initial lists of keys that are the reverse of one
another, say L1 = k1, k2 , . . . ,
kn and L2 = kn,
kn - 1, . . . ,
k1. A swap is the only way ki and
kj can cross each other if they are initially out of order. But
ki and kj are out of order in exactly one of
L1 and L2. Thus the total number
of swaps executed when bubblesort is applied to L1 and L2
is equal to the
number of pairs of elements, that is, (
![]() ) or
n(n - 1)/2. Therefore the average
number of swaps for L1 and L2 is n(n -
1)/4 or about n2/4. Since all possible
orderings can be paired with their reversals, as L1 and L2
were, we see that
the average number of swaps over all orderings will likewise be about n2/4.
) or
n(n - 1)/2. Therefore the average
number of swaps for L1 and L2 is n(n -
1)/4 or about n2/4. Since all possible
orderings can be paired with their reversals, as L1 and L2
were, we see that
the average number of swaps over all orderings will likewise be about n2/4.
The number of swaps made by insertion sort on the average is exactly what it is for bubblesort. The same argument applies; each pair of elements gets swapped either in a list L or its reverse, but never in both.
However, in the case that swap is an expensive operation we can easily see that selection sort is superior to either bubblesort or insertion sort. Line (8) in Fig. 8.7 is outside the inner loop of the selection sort algorithm, so it is executed exactly n - 1 times on any array of length n. Since line (8) has the only call to swap in selection sort, we see that the rate of growth in the number of swaps by selection sort, which is O(n), is less than the growth rates of the number of swaps by the other two algorithms, which is O(n2). Intuitively, unlike bubblesort or insertion sort, selection sort allows elements to "leap" over large numbers of other elements without being swapped with each of them individually.
A useful strategy to use when records are long and swaps are expensive is to maintain an array of pointers to the records, using whatever sorting algorithm one chooses. One can then swap pointers rather than records. Once the pointers to the records have been arranged into the proper order, the records themselves can be arranged into the final sorted order in O(n) time.
We should not forget that each of the algorithms mentioned in this section has an O(n2) running time, in both the worst case and average case. Thus, for large n, none of these algorithms compares favorably with the O(nlogn) algorithms to be discussed in the next sections. The value of n at which these more complex O(nlogn) algorithms become better than the simple O(n2) algorithms depends on a variety of factors such as the quality of the object code generated by the compiler, the machine on which the programs are run, and the size of the records we must swap. Experimentation with a time profiler is a good way to determine the cutover point. A reasonable rule of thumb is that unless n is at least around one hundred, it is probably a waste of time to implement an algorithm more complicated than the simple ones discussed in this section. Shellsort, a generalization of bubblesort, is a simple, easy-to-implement O(n1.5) sorting algorithm that is reasonably efficient for modest values of n. Shellsort is presented in Exercise 8.3.
The first O(nlogn) algorithm† we shall discuss, and probably the most efficient for internal sorting, has been given the name "quicksort." The essence of quicksort is to sort an array A[1], . . . , A[n] by picking some key value v in the array as a pivot element around which to rearrange the elements in the array. We hope the pivot is near the median key value in the array, so that it is preceded by about half the keys and followed by about half. We permute the elements in the array so that for some j, all the records with keys less than v appear in A[1] , . . . , A[ j], and all those with keys v or greater appear in A[j+ 1], . . . , A[n]. We then apply quicksort recursively to A[1], . . . , A[j] and to A[j + 1] , . . . , A[n] to sort both these groups of elements. Since all keys in the first group precede all keys in the second group, the entire array will thus be sorted.
Example 8.4. In Fig. 8.9 we display the recursive steps that quicksort might take to sort the sequence of integers 3, 1, 4, 1, 5, 9, 2, 6, 5, 3. In each case, we have chosen to take as our value v the larger of the two leftmost distinct values. The recursion stops when we discover that the portion of the array we have to sort consists of identical keys. We have shown each level as consisting of two steps, one before partitioning each subarray, and the second after. The rearrangement of records that takes place during partitioning will be explained shortly.
Let us now begin the design of a recursive procedure quicksort(i, j) that operates on an array A with elements A[1] , . . . , A[n], defined externally to the procedure. quicksort(i, j) sorts A[i] through A[j], in place. A preliminary sketch of the procedure is shown in Fig. 8.10. Note that if A[i], . . . , A[ j] all have the same key, the procedure does nothing to A.
We begin by developing a function findpivot that implements the test of line (1) of Fig. 8.10, determining whether the keys of A[i], . . . , A[j] are all the same. If findpivot never finds two different keys, it returns 0. Otherwise, it returns the index of the larger of the first two different keys. This larger key becomes the pivot element. The function findpivot is written in Fig. 8.11.
Next, we implement line (3) of Fig. 8.10, where we face the problem of permuting A[i], . . . , A[j], in place‡, so that all the keys smaller than the pivot value appear to the left of the others. To do this task, we introduce two cursors, l and r, initially at the left and right ends of the portion of A being sorted, respectively. At all times, the elements to the left of l, that is, A[i], . . . , A[l - 1] will have keys less than the pivot. Elements to the right of r, that is, A[r+1], . . . , A[j], will have keys equal to or greater than the pivot, and elements in the middle will be mixed, as suggested in Fig. 8.12.
Initially, i = l and j = r so the above statement holds since nothing is to the left of l or to the right of r. We repeatedly do the following steps, which move l right and r left, until they finally cross, whereupon A[i], . . . , A[l - 1] will contain all the keys less than the pivot and A[r+1], . . . , A[j] all the keys equal to or greater than the pivot.

Fig. 8.9. The operation of quicksort.
selection of the pivot by findpivot guarantees that there is at least one key less than the pivot and at least one not less than the pivot, so l and r will surely come to rest before moving outside the range i to j.
(1) if A[i] through A[j] contains at least two distinct keys
then begin
(2) let v be the larger of the first two distinct keys found;
(3) permute A[i], . . . ,A[j] so that for some k between
i + 1 and j, A[i], . . . ,A[k - 1 ] all have keys less
than
v and A[k], . . . ,A[j] all have keys ?/FONT> v;
(4) quicksort(i, k - 1 );
(5) quicksort(k, j)
end
Fig. 8.10. Sketch of quicksort.
function findpivot ( i, j: integer ) :integer;
{ returns 0 if A[i], . . . ,A[j] have identical keys, otherwise
returns the index of the larger of the leftmost two different keys }
var
firstkey: keytype; { value of first key found, i.e., A[i].key }
k: integer; { runs left to right looking for a different key }
begin
firstkey := A[i].key;
for k := i + 1 to j do {scan for different key}
if A[k].key > firstkey then { select larger key }
return (k)
else if A[k].key < firstkey then
return (i);
return (0) { different keys were never found }
end; { findpivot }
Fig. 8.11. The procedure findpivot.
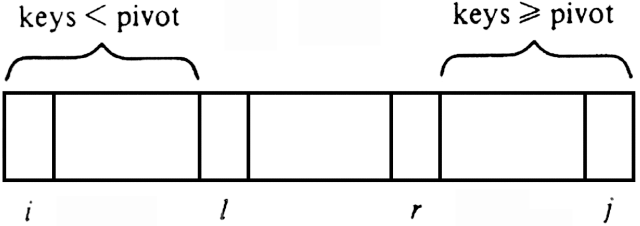
Fig. 8.12. Situation during the permutation process.
swap A[l] with A[r]. After doing so, A[l] has a key less than the pivot and A[r] has a key at least equal to the pivot, so we know that in the next scan phase, l will move at least one position right, over the old A[r], and r will move at least one position left.The above loop is awkward, since the test that terminates it is in the middle. To put it in the form of a repeat-loop, we move the switch phase to the beginning. The effect is that initially, when i = l and j = r, we shall swap A[i] with A[j]. This could be right or wrong; it doesn't matter, as we assume no particular order for the keys among A[i], . . . , A[j] initially. The reader, however, should be aware of this "trick" and not be puzzled by it. The function partition, which performs the above operations and returns l, the point at which the upper half of the partitioned array begins, is shown in Fig. 8.13.
function partition ( i, j: integer; pivot: keytype ): integer;
{ partitions A[i], . . . ,A[j] so keys < pivot are at the left
and keys ?/FONT> pivot are on the right. Returns the
beginning of the
group on the right. }
var
l, r: integer; { cursors as described above }
begin
(1) l := i;
(2) r := j;
repeat
(3) swap(A[l], A[r]);
{ now the scan phase begins }
(4) while A[l].key < pivot do
(5) l := l + 1;
(6) while A[r].key > = pivot do
(7) r := r - 1
until
(8) l > r;
(9) return (l)
end; { partition }
Fig. 8.13. The procedure partition.
We are now ready to elaborate the quicksort sketch of Fig. 8.10. The final program is shown in Fig. 8.14. To sort an array A of type array[1..n] of recordtype we simply call quicksort(1, n).
We shall show that quicksort takes O(nlogn) time on the average to sort n elements, and O(n2) time in the worst case. The first step in substantiating both claims is to prove that partition takes time proportional to the number of elements that it is called upon to separate, that is, O(j - i + 1) time.
procedure quicksort ( i, j: integer );
{ sort elements A[i], . . . ,A[j] of external array A }
var
pivot: keytype; { the pivot value }
pivotindex: integer; { the index of an element of A where
key is the pivot }
k: integer; { beginning index for group of elements ?/FONT>
pivot }
begin
(1) pivotindex := findpivot(i, j);
(2) if pivotindex <> 0 then begin { do nothing if all keys are equal }
(3) pivot := A[pivotindex].key;
(4) k := partition(i, j, pivot);
(5) quicksort(i, k - 1);
(6) quicksort(k, j)
end
end; { quicksort }
Fig. 8.14. The procedure quicksort.
To see why that statement is true, we must use a trick that comes up frequently in analyzing algorithms; we must find certain "items" to which time may be "charged," and then show how to charge each step of the algorithm so no item is charged more than some constant. Then the total time spent is no greater than this constant times the number of "items."
In our case, the "items" are the elements from A[i] to A[j], and we charge to each element all the time spent by partition from the time l or r first points to that element to the time l or r leaves that element. First note that neither l nor r ever returns to an element. Because there is at least one element in the low group and one in the high group, and because partition stops as soon as l exceeds r, we know that each element will be charged at most once.
We move off an element in the loops of lines (4) and (6) of Fig. 8.13, either by increasing l or decreasing r. How long could it be between times when we execute l : = l + 1 or r := r - 1? The worst that can happen is at the beginning. Lines (1) and (2) initialize l and r. Then we might go around the loop without doing anything to l or r. On second and subsequent passes, the swap at line (3) guarantees that the while-loops of lines (4) and (6) will be successful at least once each, so the worst that can be charged to an execution of l := l + 1 or r := r - 1 is the cost of line (1), line (2), twice line (3), and the tests of lines (4), (6), (8), and (4) again. This is only a constant amount, independent of i or j, and subsequent executions of l := l + 1 or r := r - 1 are charged less -- at most one execution of lines (3) and (8) and once around the loops of lines (4) or (6).
There are also the final two unsuccessful tests at lines (4), (6), and (8), that may not be charged to any "item," but these represent only a constant amount and may be charged to any item. After all charges have been made, we still have some constant c so that no item has been charged more than c time units. Since there are j - i + 1 "items," that is, elements in the portion of the array to be sorted, the total time spent by partition(i, j, pivot) is O(j - i + 1).
Now let us turn to the running time spent by quicksort(i, j). We can easily check that the time spent by the call to findpivot at line (1) of Fig. 8.14 is O(j - i + 1), and in most cases much smaller. The test of line (2) takes a constant amount of time, as does step (3) if executed. We have just argued that line (4), the call to partition, will take O(j - i + 1) time. Thus, exclusive of recursive calls it makes to quicksort, each individual call of quicksort takes time at most proportional to the number of elements it is called upon to sort.
Put another way, the total time taken by quicksort is the sum over all elements of the number of times that element is part of the subarray on which a call to quicksort is made. Let us refer back to Fig. 8.9, where we see calls to quicksort organized into levels. Evidently, no element can be involved in two calls at the same level, so the time taken by quicksort can be expressed as the sum over all elements of the depth, or maximum level, at which that element is found. For example, the 1's in Fig. 8.9 are of depth 3 and the 6 of depth 5.
In the worst case, we could manage to select at each call to quicksort a worst possible pivot, say the largest of the key values in the subarray being sorted. Then we would divide the subarray into two smaller subarrays, one with a single element (the element with the pivot as key) and the other with everything else. That sequence of partitions leads to a tree like that of Fig. 8.15, where r1, r2 , . . . , rn is the sequence of records in order of increasing keys.
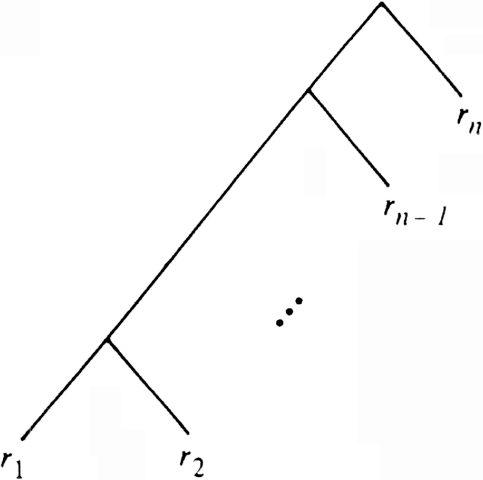
Fig. 8.15. A worst possible sequence of pivot selections.
The depth of ri is n - i + 1 for 2 ?/FONT> i ?/FONT> n, and the depth of r1 is n - 1. Thus the sum of the depths is
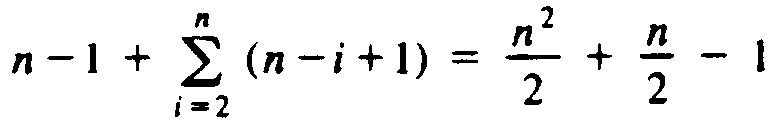
which is W(n2). Thus in the worst case, quicksort takes time proportional to n2 to sort n elements.
Let us, as always, interpret "average case" for a sorting algorithm to mean the average over all possible initial orderings, equal probability being attributed to each possible ordering. For simplicity, we shall assume no two elements have equal keys. In general, equalities among elements make our sorting task easier, not harder, anyway.
A second assumption that makes our analysis of quicksort easier is that, when we call quicksort(i, j), then all orders for A [i], . . . , A [j] are equally likely. The justification is that prior to this call, no pivots with which A [i], . . . , A [j] were compared distinguished among them; that is, for each such pivot v, either all were less than v or all were equal to or greater than v. A careful examination of the quicksort program we developed shows that each pivot element is likely to wind up near the right end of the subarray of elements equal to or greater than this pivot, but for large subarrays, the fact that the minimum element (the previous pivot, that is) is likely to appear near the right end doesn't make a measurable difference.†
Now, let T(n) be the average time taken by quicksort to sort n elements. Clearly T(1) is some constant c1, since on one element, quicksort makes no recursive calls to itself. When n > 1, since we assume all elements have unequal keys, we know quicksort will pick a pivot and split the subarray, taking c2n time to do this, for some constant c2, then call quicksort on the two subarrays. It would be nice if we could claim that the pivot was equally likely to be any of the first, second, . . . , nth element in the sorted order for the subarray being sorted. However, to guarantee ourselves that quicksort would find at least one key less than each pivot and at least one equal to or greater than the pivot (so each piece would be smaller than the whole, and therefore infinite loops would not be possible), we always picked the larger of the first two elements found. It turns out that this selection doesn't affect the distribution of sizes of the subarrays, but it does tend to make the left groups (those less than the pivot) larger then the right groups.
Let us develop a formula for the probability that the left group has i of the n elements, on the assumption that all elements are unequal. For the left group to have i elements, the pivot must be the i + 1st among the n. The pivot, by our method of selection, could either have been in the first position, with one of the i smaller elements second, or it could have been second, with one of the i smaller ones first. The probability that any particular element, such as the i + 1st, appears first in a random order is 1/n. Given that it did appear first, the probability that the second element is one of the i smaller elements out of the n -1 remaining elements is i/(n - 1). Thus the probability that the pivot appears in the first position and is number i + 1 out of n in the proper order is i/n(n - 1). Similarly, the probability that the pivot appears in the second position and is number i + 1 out of n in the sorted order is i/n(n - 1), so the probability that the left group is of size i is 2i/n(n - 1), for 1 ?/FONT> i < n.
Now we can write a recurrence for T(n).

Equation (8.1) says that the average time taken by quicksort is the time, c2n, spent outside of the recursive calls, plus the average time spent in recursive calls. The latter time is expressed in (8.1) as the sum, over all possible i, of the probability that the left group is of size i (and therefore the right group is of size n - i) times the cost of the two recursive calls: T(i) and T(n - i), respectively.
Our first task is to transform (8.1) so that the sum is simplified, and in fact, so (8.1) takes on the form it would have had if we had picked a truly random pivot at each step. To make the transformation, observe that for any function f (i) whatsoever, by substituting i for n - i we may prove
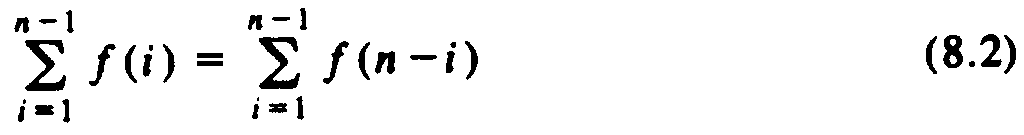
By replacing half the left side of (8.2) by the right side, we see
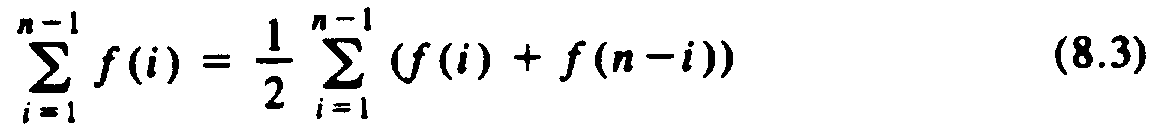
Applying (8.3) to (8.1), with f(i) equal to the expression inside the summation of (8.1), we get

Next, we can apply (8.3) to (8.4), with f(i) = T(i). This transformation yields

Note that (8.4) is the recurrence we would get if all sizes between 1 and n - 1 for the left group were equally likely. Thus, picking the larger of two keys as the pivot really doesn't affect the size distribution. We shall study recurrences of this form in greater detail in Chapter 9. Here we shall solve recurrence (8.5) by guessing a solution and showing that it works. The solution we guess is that T(n) ?/FONT> cn log n for some constant c and all n ?/FONT> 2.
To prove that this guess is correct, we perform an induction on n. For n = 2, we have only to observe that for some constant c, T(2) ?/FONT> 2c log2 = 2c. To prove the induction, assume T(i) ?/FONT> ci log i for i < n, and substitute this formula for T(i) in the right side of (8.5) to show the resulting quantity is no greater than cn log n. Thus, (8.5) becomes
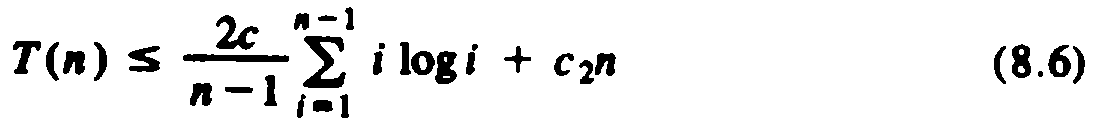
Let us split the summation of (8.6) into low terms, where i ?/FONT> n/2, and therefore log i is no greater than log(n/2), which is (logn) - 1, and high terms, where i > n/2, and log i may be as large as log n. Then (8.6) becomes
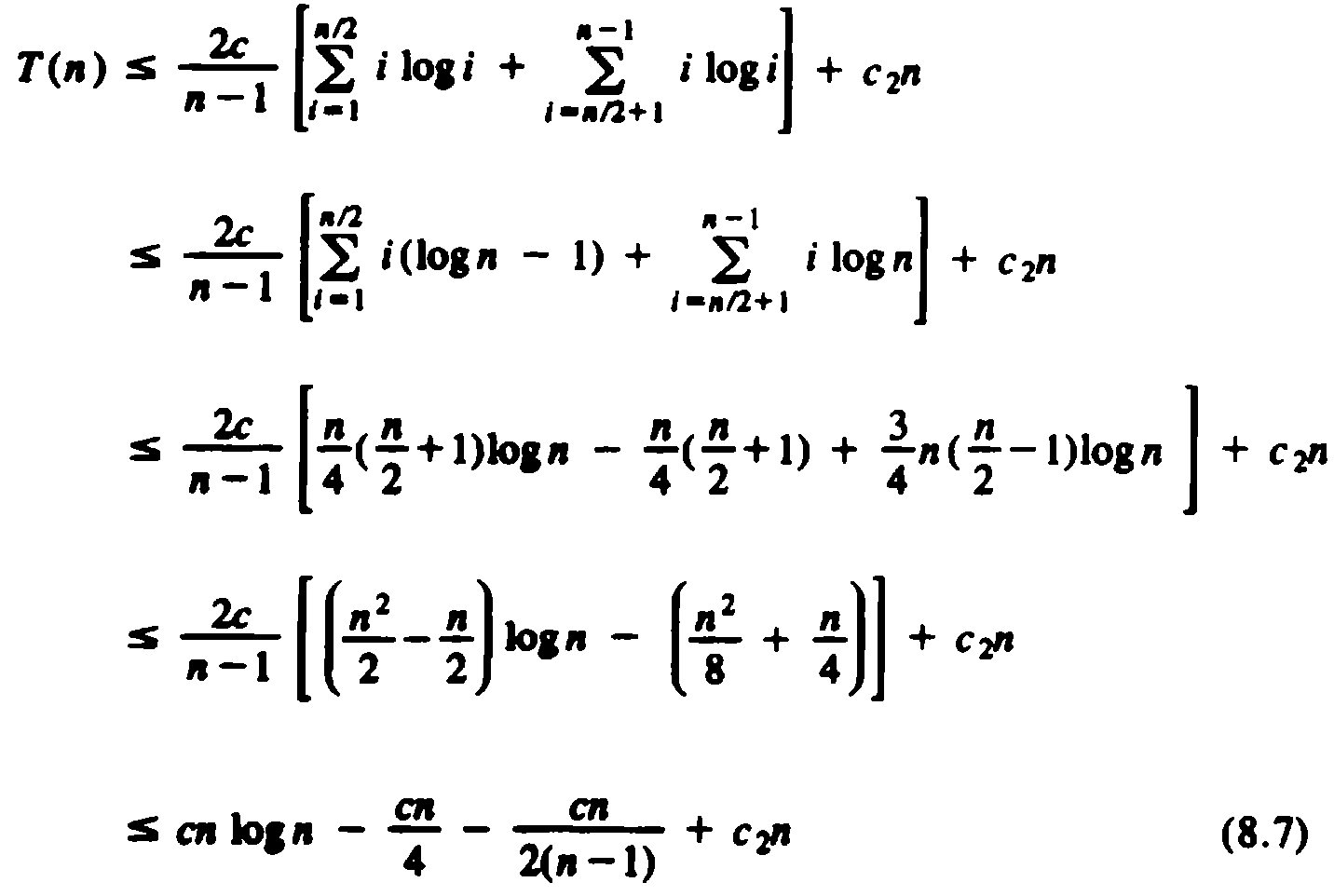
If we pick c ?/FONT> 4c2, then the sum of the second and fourth terms of (8.7) is no greater than zero. The third term of (8.7) makes a negative contribution, so from (8.7) we may claim that T(n) ?/FONT> cn log n, if we pick c = 4c2. This completes the proof that quicksort requires O (n log n) time in the average case.
Not only is quicksort fast, its average running time is less than that of all other currently known O(n log n) sorting algorithms (by a constant factor, of course). We can improve the constant factor still further if we make some effort to pick pivots that divide each subarray into close-to-equal parts. For example, if we always divide subarrays equally, then each element will be of depth exactly logn, in the tree of partitions analogous to Fig. 8.9. In comparison, the average depth of an element for quicksort as constituted in Fig. 8.14, is about 1.4logn. Thus we could hope to speed up quicksort by choosing pivots carefully.
For example, we could choose three elements of a subarray at
random,
and pick the middle one as the pivot. We could pick k elements at random
for any k, sort them either by a recursive call to quicksort or by one of the
simpler sorts of Section 8.2, and pick the median element, that is, the
![]() element, as pivot.† It is an interesting exercise to determine the
best value of
k, as a function of the number of elements in the subarray to be sorted. If we
pick k too small, it costs time because on the average the pivot will divide the
elements unequally. If we pick k too large, we spend too much time finding
the median of the k elements.
element, as pivot.† It is an interesting exercise to determine the
best value of
k, as a function of the number of elements in the subarray to be sorted. If we
pick k too small, it costs time because on the average the pivot will divide the
elements unequally. If we pick k too large, we spend too much time finding
the median of the k elements.
Another improvement to quicksort concerns what happens when we get small subarrays. Recall from Section 8.2 that the simple O(n2) methods are better than the O(n log n) methods such as quicksort for small n. How small n is depends on many factors, such as the time spent making a recursive call, which is a property of the machine architecture and the strategy for implementing procedure calls used by the compiler of the language in which the sort is written. Knuth [1973] suggests 9 as the size subarray on which quicksort should call a simpler sorting algorithm.
There is another "speedup" to quicksort that is really a way to trade space for time. The same idea will work for almost any sorting algorithm. If we have the space available, create an array of pointers to the records in array A. We make the comparisons between the keys of records pointed to. But we don't move the records; rather, we move the pointers to records in the same way quicksort moves the records themselves. At the end, the pointers, read in left-to-right order, point to the records in the desired order, and it is then a relatively simple matter to rearrange the records of A into the correct order.
In this manner, we make only n swaps of records, instead of O(n log n) swaps, which makes a substantial difference if records are large. On the negative side, we need extra space for the array of pointers, and accessing keys for comparisons is slower than it was, since we have first to follow a pointer, then go into the record, to get the key field.
In this section we develop a sorting algorithm called heapsort whose worst case as well as average case running time is O(nlogn). This algorithm can be expressed abstractly using the four set operations INSERT, DELETE, EMPTY, and MIN introduced in Chapters 4 and 5. Suppose L is a list of the elements to be sorted and S a set of elements of type recordtype, which will be used to hold the elements as they are being sorted. The MIN operator applies to the key field of records; that is, MIN(S) returns the record in S with the smallest key value. Figure 8.16 presents the abstract sorting algorithm that we shall transform into heapsort.
(1) for x on list L do (2) INSERT(x, S); (3) while not EMPTY(S) do begin (4) y := MIN(S); (5) writeln(y); (6) DELETE(y, S) end
Fig. 8.16. An abstract sorting algorithm.
In Chapters 4 and 5 we presented several data structures, such as 2-3 trees, capable of supporting each of these set operations in O(logn) time per operation, if sets never grow beyond n elements. If we assume list L is of length n, then the number of operations performed is n INSERT's, n MIN's, n DELETE's, and n + 1 EMPTY tests. The total time spent by the algorithm of Fig. 8.16 is thus O(nlogn), if a suitable data structure is used.
The partially ordered tree data structure introduced in Section 4.11 is well suited for the implementation of this algorithm. Recall that a partially ordered tree can be represented by a heap, an array A[1], . . . , A[n], whose elements have the partially ordered tree property: A[i].key ?/FONT> A[2*i].key and A[i].key ?/FONT> A[2*i + 1].key. If we think of the elements at 2i and 2i + 1 as the "children" of the element at i, then the array forms a balanced binary tree in which the key of the parent never exceeds the keys of the children.
We showed in Section 4.11 that the partially ordered tree could support the operations INSERT and DELETEMIN in O(logn) time per operation. While the partially ordered tree cannot support the general DELETE operation in O(logn) time (just finding an arbitrary element takes linear time in the worst case), we should notice that in Fig. 8.16 the only elements we delete are the ones found to be minimal. Thus lines (4) and (6) of Fig. 8.16 can be combined into a DELETEMIN function that returns the element y. We can thus implement Fig. 8.16 using the partially ordered tree data structure of Section 4.11.
We shall make one more modification to the algorithm of Fig. 8.16 to avoid having to print the elements as we delete them. The set S will always be stored as a heap in the top of array A, as A[1], . . . , A[i], if S has i elements. By the partially ordered tree property, the smallest element is always in A[1]. The elements already deleted from S can be stored in A [i + 1], . . . ,A [n], sorted in reverse order, that is, with A[i + 1] ?/FONT> A[i + 2]?/FONT> ???/FONT> ?/FONT> A[n].† Since A[1] must be smallest among A[1], . . . , A[i], we may effect the DELETEMIN operation by simply swapping A[1] with A[i]. Since the new A[i] (the old A[1]) is no smaller than A[i + 1] (or else the former would have been deleted from S before the latter), we now have A[i], . . . , A[n] sorted in decreasing order. We may now regard S as occupying A[1], . . . ,A [i - 1].
Since the new A[1] (old A[i]) violates the partially ordered tree property, we must push it down the tree as in the procedure DELETEMIN of Fig. 4.23. Here, we use the procedure pushdown shown in Fig. 8.17 that operates on the externally defined array A. By a sequence of swaps, pushdown pushes element A[first] down through its descendants to its proper position in the tree. To restore the partially ordered tree property to the heap, we call pushdown with first = 1.
We now see how lines (4 - 6) of Fig. 8.16 are to be done. Selecting the minimum at line (4) is easy; it is always in A[l] because of the partially ordered tree property. Instead of printing at line (5), we swap A[1] with A[i], the last element in the current heap. Deleting the minimum element from the partially ordered tree is now easy; we just decrement i, the cursor that indicates the end of the current heap. We then invoke pushdown(1, i) to restore the partially ordered tree property to the heap A[1], . . . , A[i].
The test for emptiness of S at line (3) of Fig. 8.16 is done by testing the value of i, the cursor marking the end of the current heap. Now we have only to consider how to perform lines (1) and (2). We may assume L is originally present in A[1], . . . , A[n] in some order. To establish the partially ordered tree property initially, we call pushdown(j,n) for all j = n/2, n/2 - 1 , . . . , 1. We observe that after calling pushdown(j, n), no violations of the partially ordered tree property occur in A[j], . . . , A[n] because pushing a record down the tree does not introduce new violations, since we only swap a violating record with its smaller child. The complete procedure, called heapsort, is shown in Fig. 8.18.
Let us examine the procedure pushdown to see how long it takes. An inspection of Fig. 8.17 confirms that the body of the while-loop takes constant time. Also, after each iteration, r has at least twice the value it had before. Thus, since r starts off equal to first, after i iterations we have r ?/FONT> first * 2i.
procedure pushdown ( first, last: integer );
{ assumes A[first], . . . ,A[last] obeys partially ordered tree property
except possibly for the children of A[first]. The procedure pushes
A[first] down until the partially ordered tree property is restored }
var
r: integer; { indicates the current position of A[first] }
begin
r := first; { initialization }
while r < = last div 2 do
if last = 2*r then begin { r has one child at 2*r }
if A[r].key > A[2*r].key
then
swap(A[r], A[2*r]);
r := last { forces a break from the while-loop }
end
else { r has two children, elements at 2*r and 2*r + 1 }
if A[r].key > A[2*r].key
and
A[2*r].key < = A[2*r + l].key then
begin
{ swap r with left child }
swap(A[r], A[2*r]);
r := 2*r
end
else if A[r].key > A[2*r + l].key
and
A[2*r + l].key < A[2*r].key then
begin
{ swap r with right child }
swap(A[r], A[2*r + 1]);
r := 2*r + l
end
else { r does not violate partially ordered tree property }
r := last { to break while-loop }
end; { pushdown }
Fig. 8.17. The procedure pushdown.
Surely, r > last/2 if first * 2i > last/2, that is if
i > log(last/first) - 1 (8.8)
Hence, the number of iterations of the while-loop of pushdown is at most log(last/first).
Since first ?/FONT> 1 and
last ?/FONT> n in each call to pushdown by the
heapsort
algorithm of Fig. 8.18, (8.8) says that each call to pushdown, at line (2) or (5) of
Fig. 8.18, takes O(logn) time. Clearly the loop of lines (1) and (2) iterates
n/2 times, so the time spent in lines (1 - 2) is O(n logn).† Also, the loop of
Fig. 8.18. The procedure heapsort.
procedure heapsort;
{ sorts array A[1], . . . ,A[n] into decreasing order }
var
i: integer; { cursor into A }
begin
{ establish the partially ordered tree property initially }
(1) for i := n div 2 downto 1 do
(2) pushdown(i, n );
(3) for i := n downto 2 do begin
(4) swap(A[1], A[i]);
{ remove minimum from front of heap }
(5) pushdown(1, i - 1)
{ re-establish partially ordered tree property }
end
end; { heapsort }
Despite its O (n log n) worst case time, heapsort will, on the average take more time than quicksort, by a small constant factor. Heapsort is of intellectual interest, because it is the first O(n log n) worst-case sort we have covered. It is of practical utility in the situation where we want not all n elements sorted, but only the smallest k of them for some k much less than n. As we mentioned, lines (1 - 2) really take only O(n) time. If we make only k iterations of lines (3 - 5), the time spent in that loop is O(k log n). Thus, heapsort, modified to produce only the first k elements takes O(n + k log n) time. If k ?/FONT> n/log n, that is, we want at most (1/log n)th of the entire sorted list, then the required time is O(n).
One might wonder whether W (n log n) steps are necessary to sort n elements. In the next section, we shall show that to be the case for sorting algorithms that assume nothing about the data type of keys, except that they can be ordered by some function that tells whether one key value is "less than" another. We can often sort in less than O(n log n) time, however, when we know something special about the keys being sorted.
Example 8.5. Suppose keytype is integer, and the values of the key are known to be in the range l to n, with no duplicates, where n is the number of elements. Then if A and B are of type array[1..n] of recordtype, and the n elements to be sorted are initially in A, we can place them in the array B, in order of their keys by
for i := 1 to n do
B[A[i].key] := A[i]; (8.9)
This code calculates where record A[i] belongs and places it there. The entire loop takes O(n) time. It works correctly only when there is exactly one record with key v for each value of v between 1 and n. A second record with key value v would also be placed in B[v], obliterating the previous record with key v.
There are other ways to sort an array A with keys 1,2, . . . , n in place in only O(n) time. Visit A[1], . . . , A[n] in turn. If the record in A[i] has key j ?/FONT> i, swap A[i] with A[j]. If, after swapping, the record with key k is now in A[i], and k ?/FONT> i, swap A[i] with A[k], and so on. Each swap places some record where it belongs, and once a record is where it belongs, it is never moved. Thus, the following algorithm sorts A in place, in O(n) time, provided there is one record with each of keys 1, 2 , . . . , n.
for i := 1 to n do
while A [i].key < > i do
swap(A[i], A[A[i].key]);
The program (8.9) given in Example 8.5 is a simple example of a "binsort," a sorting process where we create a "bin" to hold all the records with a certain key value. We examine each record r to be sorted and place it in the bin for the key value of r. In the program (8.9) the bins are the array elements B[1], . . . , B[n], and B[i] is the bin for key value i. We can use array elements as bins in this simple case, because we know we never put more than one record in a bin. Moreover, we need not assemble the bins into a sorted list here, because B serves as such a list.
In the general case, however, we must be prepared both to store more than one record in a bin and to string the bins together (or concatenate) the bins in proper order. To be specific, suppose that, as always, A[1], . . . , A[n] is an array of type recordtype, and that the keys for records are of type keytype. Suppose for the purposes of this section only, that keytype is an enumerated type, such as l..m or char. Let listtype be a type that represents lists of elements of type recordtype; listtype could be any of the types for lists mentioned in Chapter 2, but a linked list is most effective, since we shall be growing lists of unpredictable size in each bin, yet the total lengths of the lists is fixed at n, and therefore an array of n cells can supply the lists for the various bins as needed.
Finally, let B be an array of type array[keytype] of listtype. Thus, B is an array of bins, which are lists (or, if the linked list representation is used, headers for lists). B is indexed by keytype, so there is one bin for each possible key value. In this manner we can effect the first generalization of (8.9) -- the bins have arbitrary capacity.
Now we must consider how the bins are to be concatenated. Abstractly, we must form from lists a1, a2, . . . ,ai and b1, b2, . . . , bj the concatenation of the lists, which is a1, a2, . . . ,ai. b1, b2, . . . ,bj. The implementation of this operation CONCATENATE(L1, L2), which replaces list L1 by the concatenation L1L2, can be done in any of the list representations we studied in Chapter 2.
For efficiency, however, it is useful to have, in addition to a header, a pointer to the last element on each list (or to the header if the list is empty). This modification facilitates finding the last element on list L1 without running down the entire list. Figure 8.19 shows, by dashed lines, the revised pointers necessary to concatenate L1 and L2 and to have the result be called L1. List L1 is assumed to "disappear" after concatenation, in the sense that the header and end pointer for L2 become null.
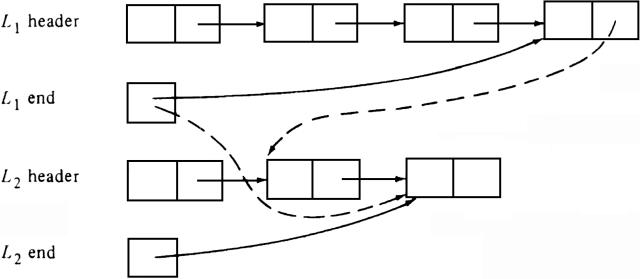
Fig. 8.19. Concatenation of linked lists.
We can now write a program to binsort arbitrary collections of records, where the key field is of an enumerated type. The program, shown in Fig. 8.20, is written in terms of list processing primitives. As we mentioned, a linked list is the preferred implementation, but options exist. Recall also that the setting for the procedure is that an array A of type array[1..n] of recordtype holds the elements to be sorted, and array B, of type array [keytype] of listtype represents the bins. We assume keytype is expressible as lowkey..highkey, as any enumerated type must be, for some quantities lowkey and highkey.
procedure binsort;
{ binsort array A, leaving the sorted list in B[lowkey] }
var
i: integer;
v: keytype;
begin
{ place the records into bins }
(1) for i := l to n do
{ push A[i] onto the front of the bin for its key }
(2) INSERT(A[i], FIRST(B[A[i].key]),
B[A[i].key]);
(3) for v := succ(lowkey) to highkey do
{ concatenate all the bins onto the end of B[lowkey] }
(4) CONCATENATE (B[lowkey], B[v])
end; { binsort }
Fig. 8.20. The abstract binsort program.
We claim that if there are n elements to be sorted, and there are m different key values (hence m different bins), then the program of Fig. 8.20 takes O(n + m) time, if the proper data structure for bins is used. In particular, if m ?/FONT> n, then binsort takes O(n) time. The data structure we have in mind is a linked list. Pointers to list ends, as indicated in Fig. 8.19, are useful but not required.
The loop of lines (1 - 2) of Fig. 8.20, which places the records in bins, takes O(n) time, since the INSERT operation of line (2) requires constant time, the insertion always occurring at the beginning of the list. For the loop of lines (3 - 4), concatenating the bins, temporarily assume that pointers to the ends of lists exist. Then step (4) takes constant time, so the loop takes O(m) time. Hence the entire binsort program takes O(n + m) time.
If pointers to the ends of lists do not exist, then in line (4) we must spend time running down to the end of B[v] before concatenating it to B[lowkey]. In this manner, the end of B[lowkey] will always be available for the next concatenation. The extra time spent running to the end of each bin once totals O(n), since the sum of the lengths of the bins is n. This extra time does not affect the order of magnitude of running time for the algorithm, since O(n) is no greater than O(n + m).
Example 8.6. Consider the specific problem of sorting n integers in the range 0 to n2 - 1. We sort the n integers in two phases. The first phase appears not to be of much help at all, but it is essential. We use n bins, one for each of the integers 0, 1 , . . . , n - 1. We place each integer i on the list to be sorted, into the bin numbered i mod n. However, unlike Fig. 8.20, it is important that we append each integer to the end of the list for the bin, not the beginning. If we are to append efficiently, we require the linked list representation of bins, with pointers to list ends.
For example, suppose n = 10, and the list to be sorted is the perfect squares from 02 to 92 in the random order 36, 9, 0, 25, 1, 49, 64, 16, 81, 4. In this case, where n = 10, the bin for integer i is just the rightmost digit of i written in decimal. Fig. 8.21(a) shows the placement of our list into bins. Notice that integers appear in bins in the same order that they appear in the original list; e.g., bin 6 has contents 36, 16, not 16, 36, since 36 precedes 16 on the original list.
Now, we concatenate the bins in order, producing the list
0, 1, 81, 64, 4, 25, 36, 16, 9, 49 (8.10)
from Fig. 8.21(a). If we use the linked list data structure with pointers to list
ends, then the placement of the n integers into bins and the concatenation of
the bins can each be done in O(n) time.
The integers on the list created by concatenating the bins are redistributed into bins, but using a different bin selection strategy. Now place integer i into bin [i/n], that is, the greatest integer equal to or less than i/n. Again, append integers to the ends of the lists for the bins. When we now concatenate the bins in order, we find the list is sorted.
For our example, Fig. 8.21(b) shows the list (8.10) distributed into bins, with i going into bin [i/10].
To see why this algorithm works, we have only to notice that when several integers are placed in one bin, as 0, 1, 4, and 9 were placed in bin 0, they must be in increasing order, since the list (8.10) resulting from the first pass ordered them by rightmost digit. Hence, in any bin the rightmost digits must form an increasing sequence. Of course, any integer placed in bin i must precede an integer placed in a bin higher than i, so concatenating the bins in order produces the sorted list.
More generally, we can think of the integers between 0 and n2 - 1 as

Fig. 8.21. Two-pass binsorting.
two-digit numbers in base n and use the same argument to see that the sorting strategy works. Consider the integers i = an + b and j = cn + d, where a, b, c, and d are each in the range 0 to n - l; i.e., they are base- n digits. Suppose i<j. Then, a>c is not possible, so we may assume a?/FONT>c. If a<c, then i appears in a lower bin than j after the second pass, so i will precede j in the final order. If a=c, then b must be less than d. Then after the first pass, i precedes j, since i was placed in bin b and j in bin d. Thus, while both i and j are placed in bin a (the same as bin c), i is inserted first, and j must follow it in the bin.Suppose keytype is a sequence of fields, as in
type
keytype = record
day: 1..31;
month: (jan , . . . , dec); (8.11)
year: 1900..1999
end;
or an array of elements of the same type, as in
type
keytype = array[1..10] of char; (8.12)
We shall assume from here that keytype consists of k components, f1,f2, . . . ,fk of types t1, t2, . . . , tk. For example, in (8.11) t1 = 1..31, t2 = (jan , . . . , dec), and t3 = 1900..1999. In (8.12), k = 10, and t1 = t2 = ???/FONT> = tk = char.
Let us also assume that we desire to sort records in the lexicographic order of their keys. That is, key value (a1, a2, . . . ,ak) is less than key value (b1, b2, . . . ,bk), where ai and bi are the values in field fi, for i = 1, 2, . . . ,k, if either
1. a1 < b1, or
2. a1 = b1 and a2 <
b2, or
.
.
.
k. a1 = b1, a2 = b2, . . . ,ak - 1=bk - 1, and ak < bk.
That is, for some j between 0 and k - 1, a1 = b1, . . . , aj = bj, † and aj + 1 <bj + 1.
We can view keys of the type defined above as if key values were integers expressed in some strange radix notation. For example, (8.12) where each field is a character, can be viewed as expressing integers in base 128, or however many characters there are in a character set for the machine at hand. Type definition (8.11) can be viewed as if the rightmost place were in base 100 (corresponding to the values between 1900 and 1999), the next place in base 12, and the third in base 31. Because of this view, generalized binsort has become known as radix sorting. In the extreme, we can even use it to sort integers up to any fixed limit by seeing them as arrays of digits in base 2, or another base.
The key idea behind radix sorting is to binsort all the records, first on fk, the "least significant digit," then concatenate the bins, lowest value first, binsort on fk - 1, and so on. As in Example 8.6, when inserting into bins, make sure that each record is appended to the end of the list, not the beginning. The radix sorting algorithm is sketched in Fig. 8.22; the reason it works was illustrated in Example 8.6. In general, after binsorting on fk, fk - 1, . . . ,fi, the records will appear in lexicographic order if the key consisted only of fields fi, . . . ,fk.
First, we must use the proper data structures to make radix sort efficient. Notice that we assume the list to be sorted is already in the form of a linked list, rather than an array. In practice, we need only to add one additional field, the link field, to the type recordtype, and we can link A[i] to A[i + 1] for i=1, 2 , . . . ,n - 1 and thus make a linked list out of the array A in O(n) time. Notice also that if we present the elements to be sorted in this way, we never copy a record. We just move records from one list to another.
procedure radixsort;
{ sorts list A of n records with keys consisting of fields
f1, . . . , fk
of types t1, . . . , tk, respectively. The
procedure uses
arrays Bi of type array[ti]
of listtype for 1 ?/FONT> i ?/FONT> k,
where listtype is a linked list of records. }
begin
(1) for i := k downto l do begin
(2) for each value v of type ti do {
clear bins }
(3) make Bi[v] empty;
(4) for each record r on list A do
(5) move r from A onto the end of bin
Bi[v],
where v is the value of field fi of the key of
r;
(6) for each value v of type ti, from lowest to
highest do
(7) concatenate Bi[v] onto the end of A
end
end; { radixsort }
Fig. 8.22. Radix sorting.
As before, for concatenation to be done quickly, we need pointers
to the end of each list. Then, the loop of lines (2 - 3) in Fig. 8.22 takes
O(si) time,
where si is the number of different values of type
ti. The loop of lines (4 - 5)
takes O(n) time, and the loop of lines (6 - 7) takes
O(si) time. Thus, the
total time taken by radix sort is
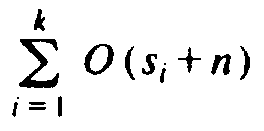 , which is
, which is
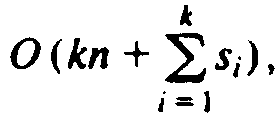 if k is assumed a constant.
if k is assumed a constant.
Example 8.7. If keys are integers in the range 0 to nk - 1, for some
constant
k, we can generalize Example 8.6 and view keys as base-n integers k digits
long. Then ti is 0..(n - 1) for all i between 1 and k,
so si = n. The expression
 becomes O(n +
kn) which, since k is a constant, is O(n).
becomes O(n +
kn) which, since k is a constant, is O(n).
As another example, if keys are character strings of length
k, for constant k, then si = 128 (say) for all i, and ![]() is a constant. Thus radix sort on
fixed length character strings is also O(n). In fact, whenever k is a constant
and the si's are constant, or even O(n), then radix sort takes
O(n) time.
Only if k grows with n can radix sort not be O(n). For example, if keys are
regarded as binary strings of length logn, then k = logn, and
si = 2 for l?/FONT>i?/FONT>k. Thus
radix sort would be
is a constant. Thus radix sort on
fixed length character strings is also O(n). In fact, whenever k is a constant
and the si's are constant, or even O(n), then radix sort takes
O(n) time.
Only if k grows with n can radix sort not be O(n). For example, if keys are
regarded as binary strings of length logn, then k = logn, and
si = 2 for l?/FONT>i?/FONT>k. Thus
radix sort would be 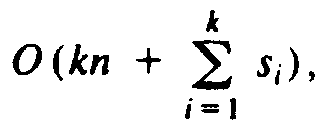 , which is
O(n log n).†
, which is
O(n log n).†
The reader should notice that in all the sorting algorithms prior to Section 8.5, progress toward determining the proper order for the elements is made when we compare two keys, and then the flow for control in the algorithm goes one of only two ways. In contrast, an algorithm like that of Example 8.5 causes one of n different things to happen in only one step, by storing a record with an integer key in one of n bins depending on the value of that integer. All programs in Section 8.5 use a capability of programming languages and machines that is much more powerful than a simple comparison of values, namely the ability to find in one step a location in an array, given the index of that location. But this powerful type of operation is not available if keytype were, say, real. We cannot, in Pascal or most other languages, declare an array indexed by real numbers, and even if we could, we could not then concatenate in a reasonable amount of time all the bins corresponding to the computer-representable real numbers.
Let us focus our attention on sorting algorithms whose only use of the elements to be sorted is in comparisons of two keys. We can draw a binary tree in which the nodes represent the "status" of the program after making some number of comparisons of keys. We can also see a node as representing those initial orderings of that data that will bring the program to this "status." Thus a program "status" is essentially knowledge about the initial ordering gathered so far by the program.
If any node represents two or more possible initial orderings, then the program cannot yet know the correct sorted order, and so must make another comparison of keys, such as "is k1<k2?" We may then create two children for the node. The left child represents those initial orderings that are consistent with the outcome that k1<k2; the right child represents the orderings that are consistent with the fact that k1>k2.† Thus each child represents a "status" consisting of the information known at the parent plus either the fact k1<k2 or the fact k1>k2, depending on whether the child is a left or right child, respectively.
Example 8.8. Consider the insertion sort algorithm with n = 3. Suppose that initially A[1], A[2], and A[3] have key values a, b, and c, respectively. Any of the six orderings of a, b, and c could be the correct one, so we begin construction of our decision tree with the node labeled (1) in Fig. 8.23, which represents all possible orderings. The insertion sort algorithm first compares A[2] with A[1], that is, b with a. If b turns out to be the smaller, then the correct ordering can only be bac, bca, or cba, the three orderings in which b precedes a. These three orderings are represented by node (2) in Fig. 8.23. The other three orderings are represented by node (3), the right child of (1). They are the orderings for which a precedes b.

Fig. 8.23. Decision tree for insertion sort with n = 3.
Now consider what happens if the initial data is such that we reach node (2). We have just swapped A[1] with A[2], and find A[2] can rise no higher since it is at the "top" already. The current ordering of the elements is bac. Insertion sort next begins inserting A[3] into its rightful place, by comparing A[3] with A[2]. Since A[2] now holds a and A[3] holds c, we are comparing c with a; node (4) represents the two orderings from node (2) in which c precedes a, while (5) represents the one ordering where it does not.
If the algorithm reaches the status of node (5), it will end, since it has already moved A[3] as high as it can go. On the other hand in the status of node (4), we found A[3]<A[2], and so swapped them, leaving b in A[1] and c in A[2]. Insertion sort next compares these two elements and swaps them if c<b. Nodes (8) and (9) represents the orderings consistent with c<b and its opposite, respectively, as well as the information gathered going from nodes (1) to (2) to (4), namely b<a and c<a. Insertion sort ends, whether or not it has swapped A[2] with A[1], making no more comparisons. Fortunately, each of the leaves (5), (8), and (9) represent a single ordering, so we have gathered enough information to determine the correct sorted order.
The description of the tree descending from node (3) is quite symmetric with what we have seen, and we omit it. Figure 8.23, since all its leaves are associated with a single ordering, is seen to determine the correct sorted order of three key values a, b, and c.
Figure 8.23 has six leaves, corresponding to the six possible orderings of the initial list a, b, c. In general, if we sort a list of n elements, there are n! = n(n - 1)(n - 2) ???/FONT> (2)(1) possible outcomes, which are the correct sorted orders for the initial list a1, a2, . . . , an. That is, any of the n elements could be first, any of the remaining n - 1 second, any of the remaining n - 2 third, and so on. Thus any decision tree describing a correct sorting algorithm working on a list of n elements must have at least n! leaves, since each possible ordering must be alone at a leaf. In fact, if we delete nodes corresponding to unnecessary comparisons, and if we delete leaves that correspond to no ordering at all (since the leaves can only be reached by an inconsistent series of comparison results), there will be exactly n! leaves.
Binary trees that have many leaves must have long paths. The length of a path from the root to a leaf gives the number of comparisons made when the ordering represented by that leaf is the sorted order for a certain input list L. Thus, the length of the longest path from the root to a leaf is a lower bound on the number of steps performed by the algorithm in the worst case. Specifically, if L is the input list, the algorithm will make at least as many comparisons as the length of the path, in addition, probably, to other steps that are not comparisons of keys.
We should therefore ask how short can all paths be in a binary tree with k leaves. A binary tree in which all paths are of length p or less can have 1 root, 2 nodes at level 1, 4 nodes at level 2, and in general, 2i nodes at level i. Thus, the largest number of leaves of a tree with no nodes at levels higher than p is 2p. Put another way, a binary tree with k leaves must have a path of length at least logk. If we let k = n!, then we know that any sorting algorithm that only uses comparisons to determine the sorted order must take W(log(n!)) time in the worst case.
But how fast does log(n!) grow? A close approximation to n! is (n/e)n, where e = 2.7183 ???/FONT> is the base of natural logarithms. Since log((n/e)n) = nlogn-nloge, we see that log(n!) is on the order of nlogn. We can get a precise lower bound by noting that n(n - 1) ???/FONT> (2)(1) is the product of at least n/2 factors that are each at least n/2. Thus n! ?/FONT> (n/2)n/2. Hence log(n!) ?/FONT> (n/2)log(n/2) = (n/2)logn - n/2. Thus sorting by comparisons requires W(nlogn) time in the worst case.
One might wonder if there could be an algorithm that used only comparisons to sort, and took W(nlogn) time in the worst case, as all such algorithms must, but on the average took time that was O(n) or something less than O(nlogn). The answer is no, and we shall only mention how to prove the statement, leaving the details to the reader.
What we want to prove is that in any binary tree with k
leaves, the
average depth of a leaf is at least logk. Suppose that were not the case, and let
tree T be the counterexample with the fewest nodes. T cannot be a single
node, because our statement says of one-leaf trees only that they have average
depth of at least 0. Now suppose T has k leaves. A binary tree with k ?/FONT> 2
leaves looks either like the tree in Fig. 8.24(a) or that in (b).
Fig. 8.24. Possible forms of binary tree T. Figure 8.24(a) cannot be the smallest counterexample, because the
tree
rooted at n1 has as many leaves as T, but even smaller average depth. If
Fig.
8.24(b) were T, then the trees rooted at n1 and n2,
being smaller then T,
would not violate our claim. That is, the average depth of leaves in T1 is at
least log(k1), and the average depth in T2 is at least
log(k2). Then the
average depth in T is
Since k1 + k2 =
k, we can express the average depth as
The reader can check that when k1 = k2 = k/2,
(8.13) has value logk. The
reader must show that (8.13) has a minimum when k1 = k2,
given the
constraint that k1 + k2 = k. We leave this proof as
an exercise to the reader
skilled in differential calculus. Granted that (8.13) has a minimum value of
logk, we see that T was not a counterexample at all. The problem of computing order statistics is, given a list of n records and an
integer k, to find the key of the record that is kth in the sorted order of the
records. In general, we refer to this problem as "finding the kth out of
n."
Special cases occur when k = 1 (finding the minimum), k = n (finding the
maximum), and the case where n is odd and k = (n + 1)/2, called finding the
median. Certain cases of the problem are quite easy to solve in linear time.
For
example, finding the minimum of n elements in O (n) time requires no special
insight. As we mentioned in connection with heapsort, if k ?/FONT>
n/logn then
we can find the kth out of n by building a heap, which takes O
(n) time, and
then selecting the k smallest elements in O(n + k log n) =
O(n) time.
Symmetrically, we can find the kth of n in O(n) time when
k ?/FONT> n - n/log n. Probably the fastest way, on the average, to find the kth out of n is to
use a
recursive procedure similar to quicksort, call it select(i, j, k), that finds the
kth element among A[i], . . . , A[j] within some
larger array
A [1], . . . , A [n]. The basic steps of select are: Eventually we find that select(i, j,
k) is called, where all of
A[i], . . . , A [j] have the same key (usually because j=i).
Then we know
the desired key; it is the key of any of these records. As with quicksort, the function select outlined above can
take W(n2) time
in the worst case. For example, suppose we are looking for the first element,
but by bad luck, the pivot is always the highest available key. However, on
the average, select is even faster than quicksort; it takes O(n) time. The
principle is that while quicksort calls itself twice, select calls itself only once. We
could analyze select as we did quicksort, but the mathematics is again
complex, and a simple intuitive argument should be convincing. On the average,
select calls itself on a subarray half as long as the subarray it was given.
Suppose that to be conservative, we say that each call is on an array 9/10 as long
as the previous call. Then if T(n) is the time spent by select on an array of
length n, we know that for some constant c we have
Using techniques from the next chapter, we can show that the solution to
(8.14) is T(n) = O(n). To guarantee that a function like select has worst case, rather than average
case, complexity O(n), it suffices to show that in linear time we can find some
pivot that is guaranteed to be some positive fraction of the way from either
end. For example, the solution to (8.14) shows that if the pivot of n elements
is never less than the The trick to finding a good pivot is contained in the following two
steps. This pivot is far from the extremes, provided that not too many records have
the pivot for key.† To simplify matters let us temporarily assume
that all keys are different. Then we claim the chosen pivot, the
Fig. 8.25. Worst-case linear algorithm for finding
kth element. To analyze the running time of select of Fig. 8.25, let
n be j - i + 1. Lines
(2) and (3) are only executed if n is 74 or less. Thus, even though step (2)
may take O(n2) steps in general, there is some constant
c1, however large,
such that for n ?/FONT> 74, lines (1 - 3) take no more than
c1 time. Now consider lines (4 - 10). Line (7), the partition step, was
shown in
connection with quicksort to take O(n) time. The loop of lines (4 - 5) is
iterated about n/5 times, and each execution of line (5), requiring the sorting
of 5 elements, takes some constant time, so the loop takes O(n) time as a
whole. Let T(n) be the time taken by a call to
select on n elements. Then line
(6) takes at most T(n/5) time. Since n ?/FONT> 75
when line (10) is reached, and
we have argued that if n ?/FONT> 75, at most 3n/4 elements
are less than the pivot,
and at most 3n/4 are equal to or greater than the pivot, we know that line (9)
or (10) takes time at most T(3n/4). Hence, for some constants c1
and c2 we
have
The term c2n in (8.15) represents
lines (1), (4), (5), and (7); the term
T(n/5) comes from line (6), and T(3n/4) represents lines (9) and (10). We shall show that T(n) in (8.15) is
O(n). Before we proceed, the
reader should now appreciate that the "magic number" 5, the size of the
groups in line (5), and our selection of n = 75 as the breakpoint below which
we did not use select recursively, were designed so the arguments n/5 and
3n/4 of T in (8.15) would sum to something less than n. Other choices of
these parameters could be made, but observe when we solve (8.15) how the
fact that 1/5 + 3/4 < 1 is needed to prove linearity. Equation (8.15) can be solved by guessing a solution and
verifying by
induction that it holds for all n. We shall chose a solution of the form cn, for
some constant c. If we pick c ?/FONT>
c1, we know T(n) ?/FONT>
cn for all n between 1
and 74, so consider the case n ?/FONT> 75. Assume by induction that
T(m) ?/FONT> cm
for m<n. Then by (8.15),
T(n) ?/FONT> c2n +
cn/5 + 3cn/4
?/FONT> c2n +
19cn/20 (8.16)
If we pick c = max(c1, 20c2), then by (8.16),
we have
T(n) ?/FONT> cn/20 + cn/5 + 3cn/4 =
cn, which we needed to show. Thus, T(n)
is O(n). Recall that we assumed no two keys were equal in Fig. 8.25. The reason this
assumption was needed is that otherwise line (7) cannot be shown to partition
A into blocks of size at most 3n/4. The modification we need to handle key
equalities is to add, after step (7), another step like partition, that groups
together all records with key equal to the pivot. Say there are p ?/FONT> 1 such
keys. If m - i ?/FONT> k ?/FONT> m - i + p, then no recursion is necessary; simply
return
A[m].key. Otherwise, line (8) is unchanged, but line (10) calls
select(m + p, j, k - (m - i) - p). Fig. 8.26. Shellsort. Knuth [1973] is a comprehensive reference on sorting methods. Quicksort is
due to Hoare [1962] and subsequent improvements to it were published by
Singleton [1969] and Frazer and McKellar [1970]. Heapsort was discovered
by Williams [1964] and improved by Floyd [1964]. The decision tree
complexity of sorting was studied by Ford and Johnson [1959]. The linear selection
algorithm in Section 8.7 is from Blum, Floyd, Pratt, Rivest, and Tarjan
[1972]. Shellsort is due to Shell [1959] and its performance has been
analyzed by
Pratt [1979]. See Aho, Hopcroft, and Ullman [1974] for one solution to
Exercise 8.9. † Technically, quicksort is only O(n log
n) in the average case; it is O(n2) in the worst case. ‡We could copy A[i], . . .
,A[j] and arrange them as we do so, finally copying the result
back into A[i], . . . ,A[j]. We choose not to do so because that approach
would waste
space and take longer than the in-place arrangement method we use. † If there is reason to believe nonrandom orders of elements
might make quicksort run
slower than expected, the quicksort program should permute the elements of the array at
random before sorting. † Since we only want the median, not the entire sorted list of
k elements, it may be better
to use one of the fast median-finding algorithms of Section 8.7. † We could at the end, reverse array A, but if we wish
A to end up sorted lowest first,
then simply apply a DELETEMAX operator in place of DELETEMIN, and partially
order A in such a way that a parent has a key no smaller (rather than no larger) than its
children. † In fact, this time is O(n), by a more careful
argument. For j in the range n/2 to
n/4+1, (8.8) says only one iteration of pushdown's while-loop is needed. For j between
n/4 and n/8+1, only two iterations, and so on. The total number of iterations as j
ranges between n/2 and 1 is bounded by
† Note that a sequence ranging from 1 to 0 (or more
generally, from x to y, where y < x)
is deemed to be an empty sequence. † But in this case, if log n-bit integers can fit in one
word, we are better off treating keys
as consisting of one field only, of type l..n, and using ordinary binsort. † We may as well assume all keys are different, since if we
can sort a collection of distinct
keys we shall surely produce a correct order when some keys are the same. † In the extreme case, when all keys are equal, the pivot
provides no separation at all.
Obviously the pivot is the kth element for any k, and another approach is
needed.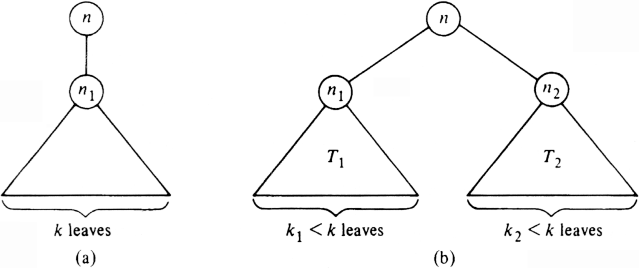
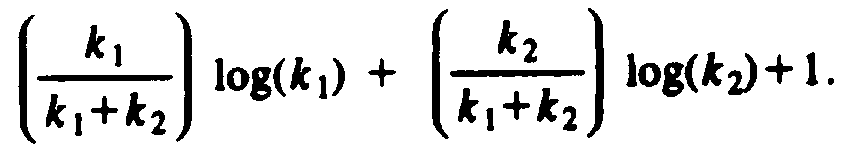
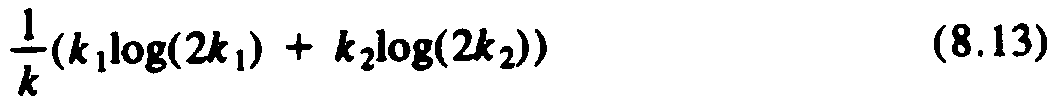
8.7 Order Statistics
A Quicksort Variation

A Worst-Case Linear Method for Finding Order Statistics
![]() element, nor
greater than the
element, nor
greater than the ![]() element, so the
recursive call to select is on at most nine-tenths of the array, then this variant
of select will be O(n) in the worst case.
element, so the
recursive call to select is on at most nine-tenths of the array, then this variant
of select will be O(n) in the worst case.
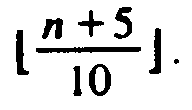 .
. element of the
element of the
![]() middle elements out of groups of 5 is
greater than at least
middle elements out of groups of 5 is
greater than at least 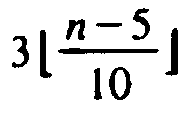 of
the n elements. For it exceeds
of
the n elements. For it exceeds ![]() of
the middle elements, and each of
those exceeds two more, from the five of which it is the middle. If n ?/FONT> 75,
then
of
the middle elements, and each of
those exceeds two more, from the five of which it is the middle. If n ?/FONT> 75,
then
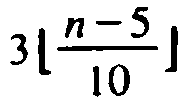 is at least n/4. Similarly, we
may check that the chosen pivot is
less than or equal to at least
is at least n/4. Similarly, we
may check that the chosen pivot is
less than or equal to at least
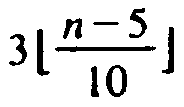 elements, so
for n ?/FONT> 75, the pivot lies
between the 1/4 and 3/4 point in the sorted order. Most importantly, when we
use the pivot to partition the n elements, the kth element will be isolated to
within a range of at most 3n/4 of the elements. A sketch of the complete
algorithm is given in Fig. 8.25; as for the sorting algorithms it assumes an
array A[1], . . . , A[n] of recordtype, and that recordtype has a field key of
type keytype. The algorithm to find the kth element is just a call to
select(1,n,k), of course.
elements, so
for n ?/FONT> 75, the pivot lies
between the 1/4 and 3/4 point in the sorted order. Most importantly, when we
use the pivot to partition the n elements, the kth element will be isolated to
within a range of at most 3n/4 of the elements. A sketch of the complete
algorithm is given in Fig. 8.25; as for the sorting algorithms it assumes an
array A[1], . . . , A[n] of recordtype, and that recordtype has a field key of
type keytype. The algorithm to find the kth element is just a call to
select(1,n,k), of course.
function select ( i, j, k: integer ): keytype;
{ returns the key of the kth element in sorted order
among A[i], . . . ,A[j] }
var
m: integer; { used as index }
begin
(1) if j-i < 74 then begin { too few to use select recursively }
(2) sort A[i], . . . ,A[j] by some simple algorithm;
(3) return (A[i + k - 1 ].key)
end
else begin { apply select recursively }
(4) for m := 0 to (j - i - 4) div 5 do
{ get the middle elements of groups of 5
into A[i], A[i + 1], . . . }
(5) find the third element among A[i + 5*m] through
A[i + 5*m + 4] and swap it with A[i +
m];
(6) pivot := select(i, i+(j-i-4) div 5, (j -
i - 4) div 10);
{ find median of middle elements. Note j - i - 4
here is n - 5 in the informal description above }
(7) m := partition(i, j, pivot);
(8) if k <= m - i then
(9) return (select(i, m - 1, k))
else
(10) return (select(m, j, k-(m - i)))
end
end; { select }
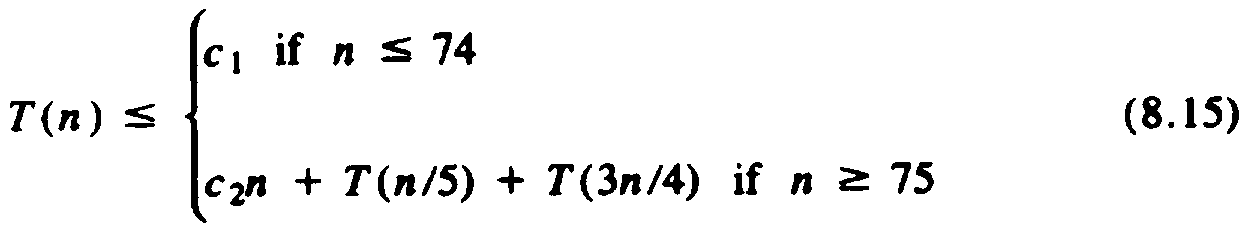
The Case Where Some Equalities Among Keys Exist
Exercises
8.1
Here are eight integers: 1, 7, 3, 2, 0, 5, 0, 8. Sort them using (a) bubblesort, (b) insertion sort,
and (c) selection sort.
8.2
Here are sixteen integers: 22, 36, 6, 79, 26, 45, 75, 13, 31, 62, 27, 76, 33, 16, 62, 47. Sort them
using (a) quicksort, (b) insertion sort, (c) heapsort, and (d) bin sort, treating them as pairs of digits in
the range 0-9.
8.3
The procedure Shellsort of Fig. 8.26, sometimes called diminishing-increment sort,
sorts an array A[1..n] of integers by sorting n/2 pairs
(A[i],A[n/2 + i]) for 1 ?/FONT>
i ?/FONT> n/2 in the first pass, n/4 four-tuples
(A[i], A[n/4 + i], A[n/2 + i],
A[3n/4 + i]) for 1 ?/FONT> i
?/FONT> n/4 in the second pass, n/8 eight-tuples in the third
pass, and so on. In each pass the sorting is done using insertion sort in which we stop sorting once we
encounter two elements in the proper order.
procedure Shellsort ( var A: array[l..n]
of integer );
var
i, j, incr: integer;
begin
incr := n div 2;
while incr > 0 do begin
for i := incr + l to n do begin
j := i - incr;
while j > 0 do
if A[j] > A[j + incr] then begin
swap(A[j], A[j + incr]);
j := j - incr
end
else
j := 0 { break }
end;
incr := incr div 2
end
end; { Shellsort }
*8.4
Suppose you are to sort a list L consisting of a sorted list followed by a few
"random" elements. Which of the sorting methods discussed in this chapter
would be especially suitable for such a task?
*8.5
A sorting algorithm is stable if it preserves the original order of records with equal keys.
Which of the sorting methods in this chapter are stable?
*8.6
Suppose we use a variant of quicksort where we always choose as the
pivot the first element in the subarray being sorted.
8.7
Show that any sorting algorithm that moves elements only one
position at a time must have time complexity at least W(n2).
8.8
In heapsort the procedure pushdown of Fig. 8.17 establishes the
partially ordered tree property in time O(n). Instead of starting at the
leaves and pushing elements down to form a heap, we could start at
the root and push elements up. What is the time complexity of this
method?
*8.9
Suppose we have a set of words, i.e., strings of the letters a - z, whose
total length is n. Show how to sort these words in O(n) time. Note
that if the maximum length of a word is constant, binsort will work.
However, you must consider the case where some of the words are
very long.
*8.10
Show that the average-case running time of insertion sort is W(n2).
*8.11
Consider the following algorithm randomsort to sort an array A[1..n]
of integers: If the elements A[1], A[2], . . . , A[n] are in sorted
order, stop; otherwise, choose a random number i between 1 and n,
swap A[1] and A[i], and repeat. What is the expected running time
of randomsort?
*8.12
We showed that sorting by comparisons takes W(n log
n) comparisons
in the worse case. Prove that this lower bound holds in the average
case as well.
*8.13
Prove that the procedure select, described informally at the beginning
of Section 8.7, has average case running time of O(n).
*8.14
Implement CONCATENATE for the data structure of Fig. 8.19.
*8.15
Write a program to find the k smallest elements in an array of length
n. What is the time complexity of your program? For what value of
k does it become advantageous to sort the array?
*8.16
Write a program to find the largest and smallest elements in an array.
Can this be done in fewer than 2n - 3 comparisons?
*8.17
Write a program to find the mode (the most frequently occurring
element) of a list of elements. What is the time complexity of your
program?
*8.18
Show that any algorithm to purge duplicates from a list requires at
least W(n log n) time under the decision tree model of
computation of
Section 8.6.
*8.19
Suppose we have k sets, S1, S2, . . . ,
Sk, each containing n real
numbers. Write a program to list all sums of the form
s1 + s2 + . . . + sk, where
si is in Si, in sorted order. What is the
time complexity of your program?
*8.20
Suppose we have a sorted array of strings s1, s2, . . . ,
sn. Write a
program to determine whether a given string x is a member of this
sequence. What is the time complexity of your program as a function
of n and the length of x?
Bibliographic Notes
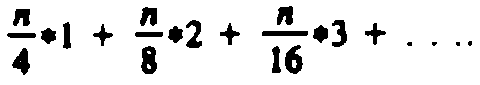 Note that the
improved bound for lines (1 - 2) does not imply an improved bound for heapsort as a whole;
all the time is taken in lines (3 - 5).
Note that the
improved bound for lines (1 - 2) does not imply an improved bound for heapsort as a whole;
all the time is taken in lines (3 - 5).