


We begin this chapter by considering the differences in access characteristics between main memory and external storage devices such as disks. We then present several algorithms for sorting files of externally stored data. We conclude the chapter with a discussion of data structures and algorithms, such as indexed files and B-trees, that are well suited for storing and retrieving information on secondary storage devices.
In the algorithms discussed so far, we have assumed that the amount of input data is sufficiently small to fit in main memory at the same time. But what if we want to sort all the employees of the government by length of service or store all the information in the nation's tax returns? In such problems the amount of data to be processed exceeds the capacity of the main memory. Most large computer systems have on-line external storage devices, such as disks or mass storage devices, on which vast quantities of data can be stored. These on-line storage devices, however, have access characteristics that are quite different from those of main memory. A number of data structures and algorithms have been developed to utilize these devices more effectively. This chapter discusses data structures and algorithms for sorting and retrieving information stored in secondary memory.
Pascal, and some other languages, provide the file data type, which is intended to represent data stored in secondary memory. Even if the language being used does not have a file data type, the operating system undoubtedly supports the notion of files in secondary memory. Whether we are talking about Pascal files or files maintained by the operating system directly, we are faced with limitations on how files may be accessed. The operating system divides secondary memory into equal-sized blocks. The size of blocks varies among operating systems, but 512 to 4096 bytes is typical.
We may regard a file as stored in a linked list of blocks, although more typically the operating system uses a tree-like arrangement, where the blocks holding the file are leaves of the tree, and interior nodes each hold pointers to many blocks of the file. If, for example, 4 bytes suffice to hold the address of a block, and blocks are 4096 bytes long, then a root block can hold pointers to up to 1024 blocks. Thus, files of up to 1024 blocks, i.e., about four million bytes, could be represented by a root block and blocks holding the file. Files of up to 220 blocks, or 232 bytes could be represented by a root block pointing to 1024 blocks at an intermediate level, each of which points to 1024 leaf blocks holding a part of the file, and so on.
The basic operation on files is to bring a single block to a buffer in main memory; a buffer is simply a reserved area of main memory whose size is the same as the size of a block. A typical operating system facilitates reading the blocks in the order in which they appear in the list of blocks that holds the file. That is, we initially read the first block into the buffer for that file, then replace it by the second block, which is written into the same buffer, and so on.
We can now see the rationale behind the rules for reading Pascal files. Each file is stored in a sequence of blocks, with a whole number of records in each block. (Space may be wasted, as we avoid having one record split across block boundaries.) The read-cursor always points to one of the records in the block that is currently in the buffer. When that cursor must move to a record not in the buffer, it is time to read the next block of the file.
Similarly, we can view the Pascal file-writing process as one of creating a file in a buffer. As records are "written" into the file, they are placed in the buffer for that file, in the position immediately following any previously placed records. When the buffer cannot hold another complete record, the buffer is copied into an available block of secondary storage and that block is appended to the end of the list of blocks for that file. We can now regard the buffer as empty and write more records into it.
It is the nature of secondary storage devices such as disks that the time to find a block and read it into main memory is large compared with the time to process the data in that block in simple ways. For example, suppose we have a block of 1000 integers on a disk rotating at 1000 rpm. The time to position the head over the track holding this block (seek time) plus the time spent waiting for the block to come around to the head (latency time) might average 100 milliseconds. The process of writing a block into a particular place on secondary storage takes a similar amount of time. However, the machine could typically do 100,000 instructions in those 100 milliseconds. This is more than enough time to do simple processing to the thousand integers once they are in main memory, such as summing them or finding their maximum. It might even be sufficient time to quicksort the integers.
When evaluating the running time of algorithms that operate on data stored as files, we are therefore forced to consider as of primary importance the number of times we read a block into main memory or write a block onto secondary storage. We call such an operation a block access. We assume the size of blocks is fixed by the operating system, so we cannot appear to make an algorithm run faster by increasing the block size, thereby decreasing the number of block accesses. As a consequence, the figure of merit for algorithms dealing with external storage will be the number of block accesses. We begin our study of algorithms for external storage by looking at external sorting.
Sorting data organized as files, or more generally, sorting data stored in secondary memory, is called "external" sorting. Our study of external sorting begins with the assumption that the data are stored on a Pascal file. We show how a "merge sorting" algorithm can sort a file of n records with only O(log n) passes through the file; that figure is substantially better than the O(n) passes needed by the algorithms studied in Chapter 8. Then we consider how utilization of certain powers of the operating system to control the reading and writing of blocks at appropriate times can speed up sorting by reducing the time that the computer is idle, waiting for a block to be read into or written out of main memory.
The essential idea behind merge sort is that we organize a file into progressively larger runs, that is, sequences of records r1, . . . , rk, where the key of ri is no greater than the key of ri+1 for 1 ?/FONT> i < k. We say a file r1, . . . ,rm of records is organized into runs of length k if for all i ?/FONT> 0 such that ki ?/FONT> m, rk(i-l)+l, rk(i-1)+2, . . . ,rki is a run of length k, and furthermore if m is not divisible by k, and m = pk+q, where q<k, then the sequence of records rm-q+1, rm-q+2, . . . ,rm, called the tail, is a run of length q. For example, the sequence of integers shown in Fig. 11.1 is organized into runs of length 3 as shown. Note that the tail is of length less than 3, but consists of records in sorted order, namely 5, 12.

Fig. 11.1. File with runs of length three.
The basic step of a merge sort on files is to begin with two files, say f1 and f2, organized into runs of length k. Assume that
Then it is a simple process to read one run from each of f1 and f2, merge the runs and append the resulting run of length 2k onto one of two files g1 and g2, which are being organized into runs of length 2k. By alternating between g1 and g2, we can arrange that these files are not only organized into runs of length 2k, but satisfy (l), (2), and (3) above. To see that (2) and (3) are satisfied it helps to observe that the tail among the runs of f1 and f2 gets merged into (or perhaps is) the last run created.
We begin by dividing all n of our records into two files f1 and f2, as evenly as possible. Any file can be regarded as organized into runs of length 1. Then we can merge the runs of length 1 and distribute them into files g1 and g2, organized into runs of length 2. We make f1 and f2 empty, and merge g1 and g2 into f1 and f2, which will then be organized into runs of length 4. Then we merge f1 and f2 to create g1 and g2 organized into runs of length 8, and so on.
After i passes of this nature, we have two files consisting of runs of length 2i. If 2i ?/FONT> n, then one of the two files will be empty and the other will contain a single run of length n, i.e., it will be sorted. As 2i ?/FONT> n when i ?/FONT> logn, we see that [logn] passes suffice. Each pass requires the reading of two files and the writing of two files, all of length about n/2. The total number of blocks read or written on a pass is thus about 2n/b, where b is the number of records that fit on one block. The number of block reads and writes for the entire sorting process is thus O((nlogn)/b), or put another way, the amount of reading and writing is about the same as that required by making O(logn) passes through the data stored on a single file. This figure is a large improvement over the O(n) passes required by many of the sorting algorithms discussed in Chapter 8.
Figure 11.2 shows the merge process in Pascal. We read two files organized into runs of length k and write two files organized into runs of length 2k. We leave to the reader the specification of an algorithm, following the ideas above, that uses the procedure merge of Fig. 11.2 logn times to sort a file of n records.
procedure merge ( k: integer; { the input run length }
f1, f2, g1, g2: file of recordtype );
var
outswitch: boolean; { tells if writing g1 (true) or g2 (false) }
winner: integer; { selects file with smaller key in current record }
used: array [1..2] of integer; { used[j] tells how many
records have been read so far from the current run of file fj }
fin: array [1..2] of boolean; { fin[j] is true if we have
finished the run from fj - either we have read k records,
or reached the end of the file of fj }
current: array [1..2] of recordtype; { the current records
from the two files }
procedure getrecord ( i: integer ); { advance file
fi, but
not beyond the end of the file or the end of the run.
Set fin[i] if end of file or run found }
begin
used[i] := used[i] + 1;
if (used[i] = k) or
(i = 1) and eof(f 1) or
(i = 2) and eof(f 2) then fin[i]:= true
else if i = 1 then read(f 1, current[1])
else read(f 2, current[2])
end; { getrecord }
begin { merge }
outswitch := true; { first merged run goes to g 1 }
rewrite(g 1); rewrite(g 2);
reset(f 1); reset(f 2);
while not eof(f 1) or not eof(f 2) do begin
{ merge two file }
{ initialize }
used[1] := 0; used[2] := 0;
fin[1] := false; fin[2] := false;
getrecord(1); getrecord(2);
while not fin[1] or not fin[2] do begin { merge two runs
}
{ select winner }
if fin[1] then winner : = 2
{ f 2 wins by "default" - run from f 1 exhausted }
else if fin[2] then winner := 1
{ f 1 wins by default }
else { neither run exhausted }
if current[1].key < current[2].key then
winner := 1
else winner := 2;
{ write winning record }
if outswitch then write(g 1,
current[winner])
else write(g 2, current[winner]);
{ advance winning file }
getrecord(winner)
end;
{ we have finished merging two runs - switch output
file and repeat }
outswitch := not outswitch
end
end; { merge }
Fig. 11.2. The procedure merge.
Notice that the procedure merge, of Fig. 11.2, is not required ever to have a complete run in memory; it reads and writes a record at a time. It is our desire not to store whole runs in main memory that forces us to have two input files. Otherwise, we could read two runs at a time from one file.
Example 11.1. Suppose we have the list of 23 numbers shown divided into two files in Fig. 11.3(a). We begin by merging runs of length 1 to create the two files of Fig. 11.3(b). For example, the first runs of length 1 are 28 and 31; these are merged by picking 28 and then 31. The next two runs of length one, 3 and 5, are merged to form a run of length two, and that run is placed on the second file of Fig. ll.3(b). The runs are separated in Fig. 11.3(b) by vertical lines that are not part of the file. Notice that the second file in Fig. 11.3(b) has a tail of length one, the record 22, while the first file has no tail.
We go from Fig. 11.3(b) to (c) by merging runs of length two. For example, the two runs 28, 31 and 3, 5 are merged to form 3, 5, 28, 31 in Fig. 11.3(c). By the time we get to runs of length 16 in Fig. 11.3(e), one file has one complete run and the other has only a tail, of length 7. At the last stage, where the files are ostensibly organized as runs of length 32, we in fact have one file with a tail only, of length 23, and the second file is empty. The single run of length 23 is, of course, the desired sorted order.
For example, if we have a million records, it would take 20 passes through the data to sort starting with runs of length one. If, however, we can hold 10,000 records at once in main memory, we can, in one pass, read 100 groups of 10,000 records, sort each group, and be left with 100 runs of length 10,000 distributed evenly between two files. Seven more merging passes results in a file organized as one run of length 10,000 x 27 = 1,280,000, which is more than a million and means that the data are sorted.
In modern time-shared computer systems, one is generally not charged for the time one's program spends waiting for blocks of a file to be read in, as must happen during the merge sort process. However, the fact is that the elapsed time of such a sorting process is greater, often substantially so, than the time spent computing with data found in the main memory. If we are sorting really large files, where the whole operation takes hours, the elapsed time becomes important, even if we do not "pay" for the time, and we should consider how the merging process might be performed in minimum elapsed time.
As was mentioned, it is typical that the time to read data from a disk or tape is greater than the time spent doing simple computations with that data,

Fig. 11.3. Merge-sorting a list.
such as merging. We should therefore expect that if there is only one channel over which data can be transferred into or out of main memory, then this channel will form a bottleneck; the data channel will be busy all the time, and the total elapsed time equals the time spent moving data into and out of main memory. That is, all the computation will be done almost as soon as the data becomes available, while additional data are being read or written.Even in this simple environment, we must exercise a bit of care to make sure that we are done in the minimum amount of time. To see what can go wrong, suppose we read the two input files f1 and f2 one block at a time, alternately. The files are organized into runs of some length much larger than the size of a block, so to merge two runs we must read many blocks from each file. However, suppose it happens that all the records in the run from file f1 happen to precede all the records from file f2. Then as we read blocks alternately, all the blocks from f2 have to remain in memory. There may not be space to hold all these blocks in main memory, and even if there is, we must, after reading all the blocks of the run, wait while we copy and write the whole run from f2.
To avoid these problems, we consider the keys of the last records in the last blocks read from f1 and f2, say keys k1 and k2, respectively. If either run is exhausted, we naturally read next from the other file. However, if a run is not exhausted, we next read a block from f1 if k1<k2, and we read from f2 otherwise. That is, we determine which of the two runs will first have all its records currently in main memory selected, and we replenish the supply of records for that run first. If selection of records proceeds faster than reading, we know that when we have read the last block of the two runs, there cannot be more than two "blockfuls" of records left to merge; perhaps the records will be distributed over three blocks, but never more.
If reading and writing between main and secondary memory is the bottleneck, perhaps we could save time if we had more than one data channel. Suppose, for example, that we have 2m disk units, each with its own channel. We could place m files, f1, f2, . . .,fm on m of the disk units, say organized as runs of length k. We can read m runs, one from each file, and merge them into one run of length mk. This run is placed on one of m output files g1, g2, . . . ,gm, each getting a run in turn.
The merging process in main memory can be carried out in O(logm) steps per record if we organize the m candidate records, that is, the currently smallest unselected records from each file, into a partially ordered tree or other data structure that supports the priority queue operations INSERT and DELETEMIN in logarithmic time. To select from the priority queue the record with the smallest key, we perform DELETEMIN, and then INSERT into the priority queue the next record from the file of the winner, as a replacement for the selected record.
If we have n records, and the length of runs is multiplied by m with each pass, then after i passes runs will be of length mi. If mi ?/FONT> n, that is, after i = logmn passes, the entire list will be sorted. As logmn = log2n/log2m, we save by a factor of log2m in the number of times we read each record. Moreover, if m is the number of disk units used for input files, and m are used for output, we can process data m times as fast as if we had only one disk unit for input and one for output, or 2m times as fast as if both input and output files were stored on one disk unit. Unfortunately, increasing m indefinitely does not speed processing by a factor of logm. The reason is that for large enough m, the time to do the merging in main memory, which is actually increasing as logm, will exceed the time to read or write the data. At that point, further increases in m actually increase the elapsed time, as computation in main memory becomes the bottleneck.
Such a merge-sorting process is called a polyphase sort. The exact calculation of the numbers of passes needed, as a function of m and n (the number of records), and calculation of the initial distribution of the runs into m files are left as exercises. However, we shall give one example here to suggest the general case.
Example 11.2. If m = 2, we start with two files f1 and f2, organized into runs of length 1. Records from f1 and f2 are merged to make runs of length 2 on the third file, f3. Just enough runs are merged to empty f1. We then merge the remaining runs of length 1 from f2 with an equal number of runs of length 2 from f3. These yield runs of length 3, and are placed on f1. Then we merge runs of length 2 on f3 with runs of length 3 on f1. These runs, of length 5, are placed on f2, which was emptied at the previous pass.
The run length sequence: 1, 1, 2, 3, 5, 8, 13, 21, . . . . . is the Fibonacci sequence. This sequence is generated by the recurrence relation F0 = F1 = 1, and Fi = Fi-1 + Fi- 2, for i ?/FONT> 2. Note that the ratio of consecutive Fibonacci numbers Fi+1/Fi approaches the "golden ratio" (?/FONT>`5+1)/2 = 1.618 . . . as i gets large.
It turns out that in order to keep this process going, until the list is sorted, the initial numbers of records on f1 and f2 must be two consecutive Fibonacci numbers. For example, Fig. 11.4 shows what happens when we start with n = 34 records (34 is the Fibonacci number F8) distributed 13 on f1 and 21 on f2. (13 and 21 are F6 and F7, so the ratio F7/F6 is very close to 1.618. It is 1.615, in fact). The status of a file is represented in Fig. 11.4 as a(b), meaning it has a runs of length b.

Fig. 11.4. Example of polyphase sorting.
When reading files is the bottleneck, the next block read must be carefully chosen. As we have mentioned, the situation to avoid is one where we have to store many blocks of one run because that run happened to have records with high keys, which get selected after most or all of the records of the other run. The trick to avoiding this problem is to determine quickly which run will first exhaust those of its records currently in main memory, by comparing the last such records in each file.
When the time taken to read data into main memory is comparable to, or less than, the time taken to process the data, it becomes even more critical that we select the input file from which to read a block carefully, since there is no hope of building a reserve of records in main memory in case the merge process suddenly starts taking more records from one run than the other. The "trick" mentioned above helps us in a variety of situations, as we shall see.
We consider the case where merging, rather than reading or writing, is a bottleneck for two reasons.
We therefore shall consider a simple model of the problem that might be encountered when merging becomes the bottleneck in a merge sort performed on data stored in secondary memory. Specifically, we assume that
Under these assumptions, we can consider a class of merging strategies where several input buffers (space to hold a block) are allocated in main memory. At all times some of these buffers will hold the unselected records from the two input runs, and one of them will be in the process of being read into from one of the input files. Two other buffers will hold output, that is, the selected records in their properly merged order. At all times, one of these buffers is in the process of being written into one of the output files and the other is being filled from records selected from the input buffers.
A stage consists of doing the following (possibly at the same time):
By our assumptions, (1), (2), and (3) all take the same time. For maximum efficiency, we must do them in parallel. We can do so, unless (2), the selection of records with the smallest keys, includes some of the records currently being read in.† We must thus devise a strategy for selecting buffers to be read so that at the beginning of each stage the b unselected records with smallest keys are already in input buffers, where b is the number of records that fills a block or buffer.
The conditions under which merging can be done in parallel with reading are simple. Let k1 and k2 be the highest keys among unselected records in main memory from the first and second runs, respectively. Then there must be in main memory at least b unselected records whose keys do not exceed min(k1, k2). We shall first show how to do the merge with six buffers, three used for each file, then show that four buffers suffice if we share them between the two files.
Our first scheme is represented by the picture in Fig. 11.5. The two output buffers are not shown. There are three buffers for each file; each buffer has capacity b records. The shaded area represents available records, and keys are in increasing order clockwise around the circles. At all times, the total number of unselected records is 4b (unless fewer than that number of records remain from the runs being merged). Initially, we read the first two blocks from each run into buffers.† As there are always 4b records available, and at most 3b can be from one file, we know there are b records at least from each file. If k1 and k2 are the largest available keys from the two runs, there must be b records with keys equal to or less than k1 and b with keys equal to or less than k2. Thus, there are b records with keys equal to or less than min(k1, k2).
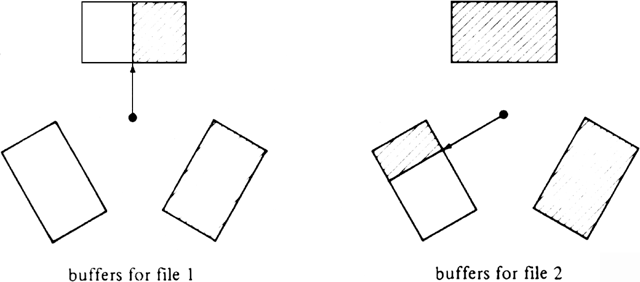
Fig. 11.5. A six-input buffer merge.
The question of which file to read from next is trivial. Usually, since two buffers will be partially full, as in Fig. 11.5, there will be only one empty buffer, and this must be filled. If it happens, as in the beginning, that each run has two completely filled and one empty buffer, pick either empty buffer to fill. Note that our proof that we could not exhaust a run [b records with keys equal to or less than min(k1, k2) exist] depended only on the fact that 4b records were present.
As an aside, the arrows in Fig. 11.5 represent pointers to the first (lowest-keyed) available records from the two runs. In Pascal, we could represent such a pointer by two integers. The first, in the range 1..3, represents the buffer pointed to, and the second, in the range 1..b, represents the record within the buffer. Alternatively, we could let the buffers be the first, middle, and last thirds of one array and use one integer in the range 1..3b. In other languages, where pointers can point to elements of arrays, a pointer of type ?/FONT> recordtype would be preferred.
Figure 11.6 suggests a four-buffer scheme. At the beginning of each stage, 2b records are available. Two of the input buffers are assigned to one of the files; B1 and B2 in Fig. 11.6 are assigned to file one. One of these buffers will be partially full (empty in the extreme case) and the other full. A third buffer is assigned to the other file, as B3 is assigned to file two in Fig. 11.6. It is partially full (completely full in the extreme case). The fourth buffer is uncommitted, and will be filled from one of the files during the stage.
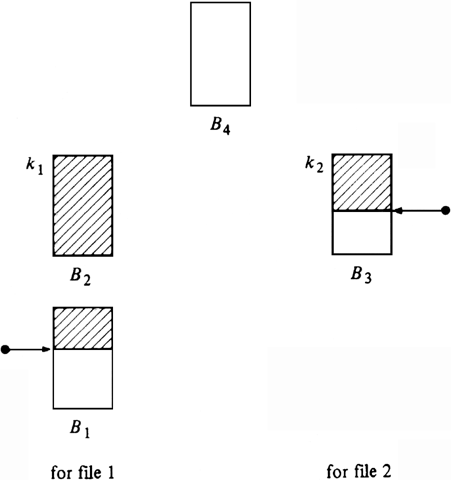
Fig. 11.6. A four-input buffer merge.
We shall maintain, of course, the property that allows us to merge in parallel with reading; at least b of the records in Fig. 11.6 must have keys equal to or less than min(k1, k2), where k1 and k2 are the keys of the last available records from the two files, as indicated in Fig. 11.6. We call a configuration that obeys the property safe. Initially, we read one block from each run (this is the extreme case, where B1 is empty and B3 is full in Fig. 11.6), so that the initial configuration is safe. We must, on the assumption that Fig. 11.6 is safe, show that the configuration will be safe after the next stage is complete.
If k1<k2, we choose to fill B4 with the next block from file one, and otherwise, we fill it from file two. Suppose first that k1<k2. Since B1 and B3 in Fig. 11.6 have together exactly b records, we must, during the next stage, exhaust B1, else we would exhaust B3 and contradict the safety of Fig. 11.6. Thus after a stage the configuration looks like Fig. 11.7(a).
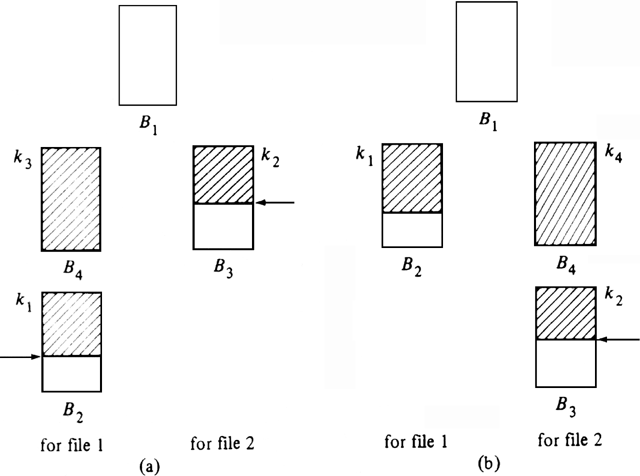
Fig. 11.7. Configuration after one stage.
To see that Fig. 11.7(a) is safe, consider two cases. First, if k3, the last key in the newly-read block B4, is less than k2, then as B4 is full, there are surely b records equal to or less than min(k3, k2), and the configuration is safe. If k2?/FONT>k3, then since k1<k2 was assumed (else we would have filled B4 from file two), the b records in B2 and B3 have keys equal to or less than min(k2, k3)=k2.
Now let us consider the case where k1?/FONT>k2 in Fig. 11.6. Then we choose to read the next block from file two. Figure 11.7(b) shows the resulting situation. As in the case k1<k2, we can argue that B1 must exhaust, which is why we show file one as having only buffer B2 in Fig. 11.7(b). The proof that Fig. 11.7(b) is safe is just like the proof for Fig. 11.7(a).
Note that, as in the six buffer scheme, we do not read a file past the end of a run. However, if there is no need to read in a block from one of the present runs, we can read a block from the next run on that file. In this way we have the opportunity to read one block from each of the next runs, and we are ready to begin merging runs as soon as we have selected the last records of the previous run.
In this section we consider data structures and algorithms for storing and retrieving information in externally stored files. We shall view a file as a sequence of records, where each record consists of the same sequence of fields. Fields can be either fixed length, having a predetermined number of bytes, or variable length, having an arbitrary size. Files with fixed length records are commonly used in database management systems to store highly structured data. Files with variable length records are typically used to store textual information; they are not available in Pascal. In this section we shall assume fixed-length fields; the fixed-length techniques can be modified simply to work for variable-length records.
The operations on files we shall consider are the following.
Example 11.3. For example, suppose we have a file whose records consist of three fields: name, address, and phone. We might ask to retrieve all records with phone = "555-1234", to insert the record ("Fred Jones", "12 Apple St.", "555-1234"), or to delete all records with name = "Fred Jones" and address = "12 Apple St." As another example, we might wish to modify all records with name = "Fred Jones" by setting the phone field to "555- 1234".
To a great extent we can view operations on files as if the files were sets of records and the operations were those discussed in Chapters 4 and 5. There are two important differences, however. First, when we talk of files on external storage devices, we must use the cost measure discussed in Section l l.l when evaluating strategies for organizing the files. That is, we assume that files are stored in some number of physical blocks, and the cost of an operation is the number of blocks that we must read into main memory or write from main memory onto external storage.
The second difference is that records, being concrete data types of most programming languages, can be expected to have pointers to them, while the abstract elements of a set would not normally have "pointers" to them. In particular, database systems frequently make use of pointers to records when organizing data. The consequence of such pointers is that records frequently must be regarded as pinned; they cannot be moved around in storage because of the possibility that a pointer from some unknown place would fail to point to the record after it was moved.
A simple way to represent pointers to records is the following. Each block has a physical address, which is the location on the external storage device of the beginning of the block. It is the job of the file system to keep track of physical addresses. One way to represent record addresses is to use the physical address of the block holding the record together with an offset, giving the number of bytes in the block preceding the beginning of the record. These physical address--offset pairs can then be stored in fields of type "pointer to record."
The simplest, and also least efficient, way to implement the above file operations is to use the file reading and writing primitives such as found in Pascal. In this "organization" (which is really a "lack of organization"), records can be stored in any order. Retrieving a record with specified values in certain fields is achieved by scanning the file and looking at each record to see if it has the specified values. An insertion into a file can be performed by appending the record to the end of the file.
For modification of records, scan the file and check each record to see if it matches the designated fields, and if so, make the required changes to the record. A deletion operation works almost the same way, but when we find a record whose fields match the values required for the deletion to take place, we must find a way to delete the record. One possibility is to shift all subsequent records one position forward in their blocks, and move the first record of each subsequent block into the last position of the previous block of the file. However, this approach will not work if records are pinned, because a pointer to the ith record in the file would then point to the i + 1st record.
If records are pinned, we must use a somewhat different approach. We mark deleted records in some way, but we do not move records to fill their space, nor do we ever insert a new record into their space. Thus, the record becomes deleted logically from the file, but its space is still used for the file. This is necessary so that if we ever follow a pointer to a deleted record, we shall discover that the record pointed to was deleted and take some appropriate action, such as making the pointer NIL so it will not be followed again. Two ways to mark records as deleted are:
The obvious disadvantage of a sequential file is that file operations are slow. Each operation requires us to read the entire file, and some blocks may have to be rewritten as well. Fortunately, there are file organizations that allow us to access a record by reading into main memory only a small fraction of the entire file.
To make such organizations possible, we assume each record of a file has a key, a set of fields that uniquely identifies each record. For example, the name field of the name-address-phone file might be considered a key by itself. That is, we might assume that two records with the same name field value cannot exist simultaneously in the file. Retrieval of a record, given values for its key fields, is a common operation, and one that is made especially easy by many common file organizations.
Another element we need for fast file operations is the ability to access blocks directly, rather than running sequentially through the blocks holding a file. Many of the data structures we use for fast file operations will use pointers to the blocks themselves, which are the physical addresses of the blocks, as described above. Unfortunately, we cannot write in Pascal, or in many other languages, programs that deal with data on the level of physical blocks and their addresses; such operations are normally done by file system commands. However, we shall briefly give an informal description of how organizations that make use of direct block access work.
Hashing is a common technique used to provide fast access to information stored on secondary files. The basic idea is similar to open hashing discussed in Section 4.7. We divide the records of a file among buckets, each consisting of a linked list of one or more blocks of external storage. The organization is similar to that portrayed in Fig. 4.10. There is a bucket table containing B pointers, one for each bucket. Each pointer in the bucket table is the physical address of the first block of the linked-list of blocks for that bucket.
The buckets are numbered 0, 1, . . . . ,B - 1. A hash function h maps each key value into one of the integers 0 through B - 1. If x is a key, h(x) is the number of the bucket that contains the record with key x, if such a record is present at all. The blocks making up each bucket are chained together in a linked list. Thus, the header of the ith block of a bucket contains a pointer to the physical address of the i + 1st block. The last block of a bucket contains a NIL pointer in its header.
This arrangement is illustrated in Fig. 11.8. The major difference between Figs. 11.8 and 4.10 is that here, elements stored in one block of a bucket do not need to be chained by pointers; only the blocks need to be chained.
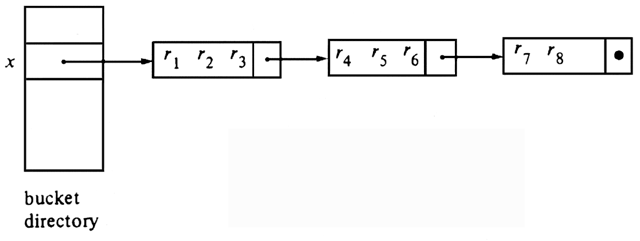
Fig. 11.8. Hashing with buckets consisting of chained blocks.
If the size of the bucket table is small, it can be kept in main memory. Otherwise, it can be stored sequentially on as many blocks as necessary. To look for the record with key x, we compute h(x), and find the block of the bucket table containing the pointer to the first block of bucket h(x). We then read the blocks of bucket h(x) successively, until we find a block that contains the record with key x. If we exhaust all blocks in the linked list for bucket h(x), we conclude that x is not the key of any record.
This structure is quite efficient if the operation is one that specifies values for the fields in the key, such as retrieving the record with a specified key value or inserting a record (which, naturally, specifies the key value for that record). The average number of block accesses required for an operation that specifies the key of a record is roughly the average number of blocks in a bucket, which is n/bk if n is the number of records, a block holds b records, and k is the number of buckets. Thus, on the average, operations based on keys are k times faster with this organization than with the unorganized file. Unfortunately, operations not based on keys are not speeded up, as we must examine essentially all the buckets during these other operations. The only general way to speed up operations not based on keys seems to be the use of secondary indices, which are discussed at the end of this section.
To insert a record with key value x, we first check to see if there is already a record with key x. If there is, we report error, since we assume that the key uniquely identifies each record. If there is no record with key x, we insert the new record in the first block in the chain for bucket h(x) into which the record can fit. If the record cannot fit into any existing block in the chain for bucket h(x), we call upon the file system to find a new block into which the record is placed. This new block is then added to the end of the chain for bucket h(x).
To delete a record with key x, we first locate the record, and then set its deletion bit. Another possible deletion strategy (which cannot be used if the records are pinned) is to replace the deleted record with the last record in the chain for h(x). If the removal of the last record makes the last block in the chain for h(x) empty, we can then return the empty block to the file system for later re-use.
A well-designed hashed-access file organization requires only a few block accesses for each file operation. If our hash function is good, and the number of buckets is roughly equal to the number of records in the file divided by the number of records that can fit on one block, then the average bucket consists of one block. Excluding the number of block accesses to search the bucket table, a typical retrieval based on keys will then take one block access, and a typical insertion, deletion, or modification will take two block accesses. If the average number of records per bucket greatly exceeds the number that will fit on one block, we can periodically reorganize the hash table by doubling the number of buckets and splitting each bucket into two. The ideas were covered at the end of Section 4.8.
Another common way to organize a file of records is to maintain the file sorted by key values. We can then search the file as we would a dictionary or telephone directory, scanning only the first name or word on each page. To facilitate the search we can create a second file, called a sparse index, which consists of pairs (x, b), where x is a key value and b is the physical address of the block in which the first record has key value x. This sparse index is maintained sorted by key values.
Example 11.4. In Fig. 11.9 we see a file and its sparse index file. We assume that three records of the main file, or three pairs of the index file, fit on one block. Only the key values, assumed to be single integers, are shown for records in the main file.
To retrieve a record with a given key x, we first search the index file for a pair (x, b). What we actually look for is the largest z such that z ?/FONT> x and there is a pair (z, b) in the index file. Then key x appears in block b if it is present in the main file at all.
There are several strategies that can be used to search the index file. The simplest is linear search. We read the index file from the beginning until we encounter a pair (x, b), or until we encounter the first pair (y, b) where y > x. In the latter case, the preceding pair (z, b? must have z < x, and if the record with key x is anywhere, it is in block b?
Linear search is only suitable for small index files. A faster method is
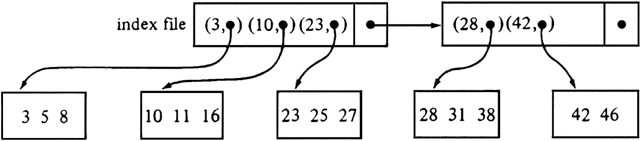
Fig. 11.9. A main file and its sparse index.
binary search. Assume the index file is stored on blocks b1, b2, . . . ,bn. To search for key value x, we take the middle block b[n/2] and compare x with the key value y in the first pair in that block. If x < y, we repeat the search on blocks b1, b2, . . .,b[n/2]-1. If x ?/FONT> y, but x is less than the key of block b[n/2]+1 (or if n=1, so there is no such block), we use linear search to see if x matches the first component of an index pair on block b[n/2]. Otherwise, we repeat the search on blocks b[n/2]+1, b[n/2]+2, . . . ,bn. With binary search we need examine only [log2(n + 1)] blocks of the index file.To initialize an indexed file, we sort the records by their key values, and then distribute the records to blocks, in that order. We may choose to pack as many as will fit into each block. Alternatively, we may prefer to leave space for a few extra records that may be inserted later. The advantage is that then insertions are less likely to overflow the block into which the insertion takes place, with the resultant requirement that adjacent blocks be accessed. After partitioning the records into blocks in one of these ways, we create the index file by scanning each block in turn and finding the first key on each block. Like the main file, some room for growth may be left on the blocks holding the index file.
Suppose we have a sorted file of records that are stored on blocks B1, B2, . . . ,Bm. To insert a new record into this sorted file, we use the index file to determine which block Bi should contain the new record. If the new record will fit in Bi, we place it there, in the correct sorted order. We then adjust the index file, if the new record becomes the first record on Bi.
If the new record cannot fit in Bi, a variety of strategies are possible. Perhaps the simplest is to go to block Bi+1, which can be found through the index file, to see if the last record of Bi can be moved to the beginning of Bi+1. If so, this last record is moved to Bi+1, and the new record can then be inserted in the proper position in Bi. The index file entry for Bi+1, and possibly for Bi, must be adjusted appropriately.
If Bi+1 is also full, or if Bi is the last block (i = m), then a new block is obtained from the file system. The new record is inserted in this new block, and the new block is to follow block Bi in the order. We now use this same procedure to insert a record for the new block in the index file.
Another way to organize a file of records is to maintain the file in random order and have another file, called a dense index, to help locate records. The dense index consists of pairs (x, p), where p is a pointer to the record with key x in the main file. These pairs are sorted by key value, so a structure like the sparse index mentioned above, or the B-tree mentioned in the next section, could be used to help find keys in the dense index.
With this organization we use the dense index to find the location in the main file of a record with a given key. To insert a new record, we keep track of the last block of the main file and insert the new record there, getting a new block from the file system if the last block is full. We also insert a pointer to that record in the dense index file. To delete a record, we simply set the deletion bit in the record and delete the corresponding entry in the dense index (perhaps by setting a deletion bit there also).
While the hashed and indexed structures speed up operations based on keys substantially, none of them help when the operation involves a search for records given values for fields other than the key fields. If we wish to find the records with designated values in some set of fields F1, . . . . ,Fk we need a secondary index on those fields. A secondary index is a file consisting of pairs (v, p), where v is a list of values, one for each of the fields F1, . . . ,Fk, and p is a pointer to a record. There may be more than one pair with a given v, and each associated pointer is intended to indicate a record of the main file that has v as the list of values for the fields F1, . . . ,Fk.
To retrieve records given values for the fields F1, . . . ,Fk, we look in the secondary index for a record or records with that list of values. The secondary index itself can be organized in any of the ways discussed for the organization of files by key value. That is, we pretend that v is a key for (v, p).
For example, a hashed organization does not really depend on keys being unique, although if there were very many records with the same "key" value, then records might distribute themselves into buckets quite nonuniformly, with the effect that hashing would not speed up access very much. In the extreme, say there were only two values for the fields of a secondary index. Then all but two buckets would be empty, and the hash table would only speed up operations by a factor of two at most, no matter how many buckets there were. Similarly, a sparse index does not require that keys be unique, but if they are not, then there may be two or more blocks of the main file that have the same lowest "key" value, and all such blocks will be searched when we are looking for records with that value.
With either the hashed or sparse index organization for our secondary index file, we may wish to save space by bunching all records with the same value. That is, the pairs (v, p1), (v, p2), . . . ,(v, pm) can be replaced by v followed by the list p1, p2, . . . ,pm.
One might naturally wonder whether the best response time to random operations would not be obtained if we created a secondary index for each field, or even for all subsets of the fields. Unfortunately, there is a penalty to be paid for each secondary index we choose to create. First, there is the space needed to store the secondary index, and that may or may not be a problem, depending on whether space is at a premium.
In addition, each secondary index we create slows down all insertions and all deletions. The reason is that when we insert a record, we must also insert an entry for that record into each secondary index, so the secondary indices will continue to represent the file accurately. Updating a secondary index takes at least two block accesses, since we must read and write one block. However, it may take considerably more than two block accesses, since we have to find that block, and any organization we use for the secondary index file will require a few extra accesses, on the average, to find any block. Similar remarks hold for each deletion. The conclusion we draw is that selection of secondary indices requires judgment, as we must determine which sets of fields will be specified in operations sufficiently frequently that the time to be saved by having that secondary index available more than balances the cost of updating that index on each insertion and deletion.
The tree data structures presented in Chapter 5 to represent sets can also be used to represent external files. The B-tree, a generalization of the 2-3 tree discussed in Chapter 5, is particularly well suited for external storage, and it has become a standard organization for indices in database systems. This section presents the basic techniques for retrieving, inserting, and deleting information in B-trees.
However, we are interested here in the storage of records in files, where the files are stored in blocks of external storage. The correct adaptation of the multiway tree idea is to think of the nodes as physical blocks. An interior node holds pointers to its m children and also holds the m-1 key values that separate the descendants of the children. Leaf nodes are also blocks; these blocks hold the records of/P>
If we used a binary search tree of n nodes to represent an externally stored file, then it would require log2n block accesses to retrieve a record from the file, on the average. If instead, we use an m-ary search tree to represent the file, it would take an average of only logmn block accesses to retrieve a record. For n = 106, the binary search tree would require about 20 block accesses, while a 128-way search tree would take only 3 block accesses.
We cannot make m arbitrarily large, because the larger m is, the larger the block size must be. Moreover, it takes longer to read and process a larger block, so there is an optimum value for m to minimize the amount of time needed to search an external m-ary search tree. In practice a value close to the minimum is obtained for a broad range of m's. (See Exercise 11.18).
A B-tree is a special kind of balanced m-ary tree that allows us to retrieve, insert, and delete records from an external file with a guaranteed worst-case performance. It is a generalization of the 2-3 tree discussed in Section 5.4. Formally, a B-tree of order m is an m-ary search tree with the following properties:
Note that every 2-3 tree is a B-tree of order 3. Figure 11.10 shows a B-tree of order 5, in which we assume that at most three records fit in a leaf block.
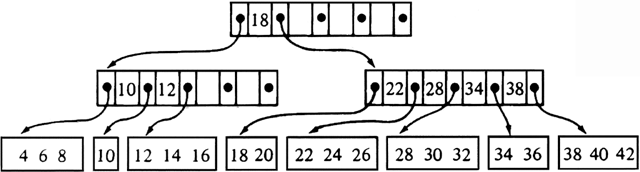
Fig. 11.10. B-tree of order 5.
We can view a B-tree as a hierarchical index in which each node occupies a block in external storage. The root of the B-tree is the first level index. Each non-leaf node in the B-tree is of the form
(p0, k1, p1, k2, p2, . . . ,kn, pn)
where pi is a pointer to the ith child of the node, 0 ?/FONT> i ?/FONT> n, and ki is a key, 1 ?/FONT> i ?/FONT> n. The keys within a node are in sorted order so k1 < k2 < ???/FONT> < kn. All keys in the subtree pointed to by po are less than k1. For 1 ?/FONT> i < n, all keys in the subtree pointed to by pi have values greater than or equal to ki and less than ki+1. All keys in the subtree pointed to by pn are greater than or equal to kn.There are several ways to organize the leaves. Here we shall assume that the main file is stored only in the leaves. Each leaf is assumed to occupy one block.
To retrieve a record r with key value x, we trace the path from the root to the leaf that contains r, if it exists in the file. We trace this path by successively fetching interior nodes (p0, k1, p1, . . . ,kn, pn) from external storage into main memory and finding the position of x relative to the keys k1, k2, . . . ,kn. If ki ?/FONT> x < ki+1, we next fetch the node pointed to by pi and repeat the process. If x < k1, we use p0 to fetch the next node; if x ?/FONT> kn, we use pn. When this process brings us to a leaf, we search for the record with key value x. If the number of entries in a node is small, we can use linear search within the node; otherwise, it would pay to use binary search.
Insertion into a B-tree is similar to insertion into a 2-3 tree. To insert a record r with key value x into a B-tree, we first apply the lookup procedure to locate the leaf L at which r should belong. If there is room for r in L, we insert r into L in the proper sorted order. In this case no modifications need to be made to the ancestors of L.
If there is no room for r in L, we ask the file system for a new block L?/FONT> and move the last half of the records from L to L?/FONT>, inserting r into its proper place in L or L?/FONT>.† Let node P be the parent of node L. P is known, since the lookup procedure traced a path from the root to L through P. We now apply the insertion procedure recursively to place in P a key k?/FONT> and a pointer l?/FONT> to L?/FONT>; k?/FONT> and l?/FONT> are inserted immediately after the key and pointer for L. The value of k?/FONT> is the smallest key value in L?/FONT>.
If P already has m pointers, insertion of k?/FONT> and l?/FONT> into P will cause P to be split and require an insertion of a key and pointer into the parent of P. The effects of this insertion can ripple up through the ancestors of node L back to the root, along the path that was traced by the original lookup procedure. It may even be necessary to split the root, in which case we create a new root with the two halves of the old root as its two children. This is the only situation in which a node may have fewer than m/2 children.
To delete a record r with key value x, we first find the leaf L containing r. We then remove r from L, if it exists. If r is the first record in L, we then go to P, the parent of L, to set the key value in P's entry for L to be the new first key value of L. However, if L is the first child of P, the first key of L is not recorded in P, but rather will appear in one of the ancestors of P, specifically, the lowest ancestor A such that L is not the leftmost descendant of A. Therefore, we must propagate the change in the lowest key value of L backwards along the path from the root to L.
If L becomes empty after deletion, we give L back to the file system.† We now adjust the keys and pointers in P to reflect the removal of L. If the number of children of P is now less than m/2, we examine the node P?/FONT> immediately to the left (or the right) of P at the same level in the tree. If P?/FONT> has at least [m/2] + 1 children, we distribute the keys and pointers in P and P?/FONT> evenly between P and P?/FONT>, keeping the sorted order of course, so that both nodes will have at least [m/2] children. We then modify the key values for P and P?/FONT> in the parent of P, and, if necessary, recursively ripple the effects of this change to as many ancestors of P as are affected.
If P?/FONT> has exactly [m/2] children, we combine P and P?/FONT> into a single node with 2[m/2] - 1 children (this is m children at most). We must then remove the key and pointer to P?/FONT> from the parent for P?/FONT>. This deletion can be done with a recursive application of the deletion procedure.
If the effects of the deletion ripple all the way back to the root, we may have to combine the only two children of the root. In this case the resulting combined node becomes the new root, and the old root can be returned to the file system. The height of the B-tree has now been reduced by one.
Example 11.5. Consider the B-tree of order 5 in Fig. 11.10. Inserting the record with key value 23 into this tree produces the B-tree in Fig. 11.11. To insert 23, we must split the block containing 22, 23, 24, and 26, since we assume that at most three records fit in one block. The two smaller stay in that block, and the larger two are placed in a new block. A pointer-key pair for the new node must be inserted into the parent, which then splits because it cannot hold six pointers. The root receives the pointer-key pair for the new node, but the root does not split because it has excess capacity.
Removing record 10 from the B-tree of Fig. 11.11 results in the B-tree of Fig. 11.12. Here, the block containing 10 is discarded. Its parent now has only two children, and the right sibling of the parent has the minimum number, three. Thus we combine the parent with its sibling, making one node with five children.
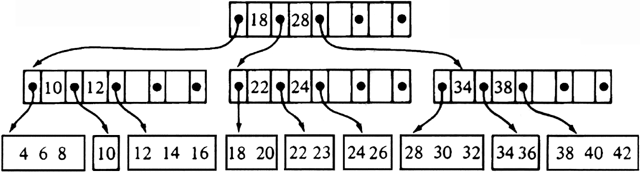
Fig. 11.11. B-tree after insertion.
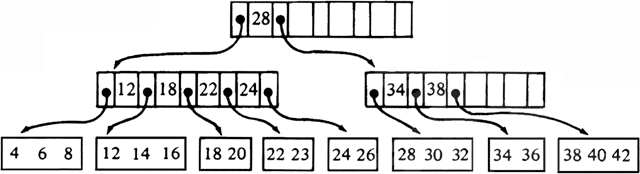
Fig. 11.12. B-tree after deletion.
Suppose we have a file with n records organized into a B-tree of order m. If each leaf contains b records on the average, then the tree has about [n/b] leaves. The longest possible paths in such a tree will occur if each interior node has the fewest children possible, that is, m/2 children. In this case there will be about 2[n/b]/m parents of leaves, 4[n/b]/m2 parents of parents of leaves, and so on.
If there are j nodes along the path from the root to a leaf, then 2j-1[n/b]/mj-1 ?/FONT> 1, or else there would be fewer than one node at the root's level. Therefore, [n/b] ?/FONT> (m/2)j-1, and j ?/FONT> 1 -- logm/2[n/b]. For example, if n = 106, b = 10, and m = 100, then j ?/FONT> 3.9. Note that b is not the maximum number of records we can put in a block, but an average or expected number. However, by redistributing records among neighboring blocks whenever one gets less than half full, we can ensure that b is at least half the maximum value. Also note that we have assumed in the above that each interior node has the minimum possible number of children. In practice, the average interior node will have more than the minimum, and the above analysis is therefore conservative.
For an insertion or deletion, j block accesses are needed to locate the appropriate leaf. The exact number of additional block accesses that are needed to accomplish the insertion or deletion, and to ripple its effects through the tree, is difficult to compute. Most of the time only one block, the leaf storing the record of interest, needs to be rewritten. Thus, 2 + logm/2[n/b] can be taken as the approximate number of block accesses for an insertion or deletion.
We have discussed hashing, sparse indices, and B-trees as possible methods for organizing external files. It is interesting to compare, for each method, the number of block accesses involved in a file operation.
Hashing is frequently the fastest of the three methods, requiring two block accesses on average for each operation (excluding the block accesses required to search the bucket table), if the number of buckets is sufficiently large that the typical bucket uses only one block. With hashing, however, we cannot easily access the records in sorted order.
A sparse index on a file of n records allows the file operations to be done in about 2 + log(n/bb?/FONT>) block accesses using binary search; here b is the number of records that fit on a block, and b?/FONT> is the number of key-pointer pairs that fit on a block for the index file. B-trees allow file operations in about 2 + logm/2[n/b] block accesses, where m, the maximum degree of the interior nodes, is approximately b?/FONT>. Both sparse indices and B-trees allow records to be accessed in sorted order.
All of these methods are remarkably good compared to the obvious sequential scan of a file. The timing differences among them, however, are small and difficult to determine analytically, especially considering that the relevant parameters such as the expected file length and the occupancy rates of blocks are hard to predict in advance.
It appears that the B-tree is becoming increasingly popular as a means of accessing files in database systems. Part of the reason lies in its ability to handle queries asking for records with keys in a certain range (which benefit from the fact that the records appear in sorted order in the main file). The sparse index also handles such queries efficiently, but is almost sure to be less efficient than the B-tree. Intuitively, the reason B-trees are superior to sparse indices is that we can view a B-tree as a sparse index on a sparse index on a sparse index, and so on. (Rarely, however, do we need more than three levels of indices.)
B-trees also perform relatively well when used as secondary indices, where "keys" do not really define a unique record. Even if the records with a given value for the designated fields of a secondary index extend over many blocks, we can read them all with a number of block accesses that is just equal to the number of blocks holding these records plus the number of their ancestors in the B-tree. In comparison, if these records plus another group of similar size happen to hash to the same bucket, then retrieval of either group from a hash table would require a number of block accesses about double the number of blocks on which either group would fit. There are possibly other reasons for favoring the B-tree, such as their performance when several processes are accessing the structure simultaneously, that are beyond the scope of this book.
| 11.1 | Write a program concatenate that takes a sequence of file names as arguments and writes the contents of the files in turn onto the standard output, thereby concatenating the files. |
|---|---|
| 11.2 | Write a program include that copies its input to its output except when it encounters a line of the form #include filename, in which case it is to replace this line with the contents of the named file. Note that included files may also contain #include statements. |
| 11.3 | How does your program for Exercise 11.2 behave when a file includes itself? |
| 11.4 | Write a program compare that will compare two files record-by-record to determine whether the two files are identical. |
| *11.5 | Rewrite the file comparison program of Exercise 11.4 using the LCS algorithm of Section 5.6 to find the longest common subsequence of records in both files. |
| 11.6 | Write a program find that takes two arguments consisting of a pattern string and a file name, and prints all lines of the file containing the pattern string as a substring. For example, if the pattern string is "ufa" and the file is a word list, then find prints all words containing the trigram "ufa." |
| 11.7 | Write a program that reads a file and writes on its standard output the records of the file in sorted order. |
| 11.8 | What are the primitives Pascal provides for dealing with external files? How would you improve them? |
| *11.9 | Suppose we use a three-file polyphase sort, where at the ith phase we
create a file with ri runs of length li. At the
nth phase we want one
run on one of the files and none on the other two. Explain why each
of the following must be true
|
| *11.10 | What additional condition must be added to those of Exercise 11.9 to
make a polyphase sort possible
Hint. Consider a few examples, like ln = 50, ln-1 = 31, or ln = 50, ln-1 = 32. |
| **11.11 | Generalize Exercises 11.9 and 11.10 to polyphase sorts with more than three files. |
| **11.12 | Show that:
|
| 11.13 | Suppose we have an external file of directed arcs x ?/FONT> y
that form a
directed acyclic graph. Assume that there is not enough space in
internal memory to hold the entire set of vertices or edges at one
time.
|
| 11.14 | Suppose we have a file of one million records, where each record takes 100 bytes. Blocks are 1000 bytes long, and a pointer to a block takes 4 bytes. Devise a hashed organization for this file. How many blocks are needed for the bucket table and the buckets? |
| 11.15 | Devise a B-tree organization for the file of Exercise 11.14. |
| 11.16 | Write programs to implement the operations RETRIEVE, INSERT,
DELETE, and MODIFY on
|
| 11.17 | Write a program to find the kth largest element in
|
| 11.18 | Assume that it takes a + bm milliseconds to read a block containing a
node of an m-ary search tree. Assume that it takes c + d
log2m
milliseconds to process each node in internal memory. If there are n
nodes in the tree, we need to read about logmn nodes to locate a given
record. Therefore, the total time taken to find a given record in the
tree is
(logmn)(a + bm + c + d log2m) = (log2n)((a + c + bm)/log2m + d) milliseconds. Make reasonable estimates for the values of a, b, c, and d and plot this quantity as a function of m. For what value of m is the minimum attained? |
| *11.19 | A B*-tree is a B-tree in which each interior node is at least 2/3 full (rather than just 1/2 full). Devise an insertion scheme for B*-trees that delays splitting interior nodes until two sibling nodes are full. The two full nodes can then be divided into three, each 2/3 full. What are the advantages and disadvantages of B*-trees compared with B-trees? |
| *11.20 | When the key of a record is a string of characters, we can save space by storing only a prefix of the key as the key separator in each interior node of the B-tree. For example, "cat" and "dog" could be separated by the prefix "d" or "do" of "dog." Devise a B-tree insertion algorithm that uses prefix key separators that at all times are as short as possible. |
| *11.21 | Suppose that the operations on a certain file are insertions and deletions fraction p of the time, and the remaining 1-p of the time are retrievals where exactly one field is specified. There are k fields in records, and a retrieval specifies the ith field with probability qi. Assume that a retrieval takes a milliseconds if there is no secondary index for the specified field, and b milliseconds if the field has a secondary index. Also assume that an insertion or deletion takes c + sd milliseconds, where s is the number of secondary indices. Determine, as a function of a, b, c, d, p, and the qi's, which secondary indices should be created for the file in order that the average time per operation be minimized. |
| *11.22 | Suppose that keys are of a type that can be linearly ordered, such as
real numbers, and that we know the probability distribution with
which keys of given values will appear in the file. We could use this
knowledge to outperform binary search when looking for a key in a
sparse index. One scheme, called interpolation search, uses this
statistical information to predict where in the range of index blocks
Bi, . . . ,Bj to which the search has been
limited, a key x is most
likely to lie. Give
|
| 11.23 | Suppose we have an external file of records, each consisting of an
edge of a graph G and a cost associated with that edge.
Hint. One approach to this problem is to maintain a forest of currently connected components in core. Each edge is read and processed as follows: If the next edge has ends in two different components, add the edge and merge the components. If the edge creates a cycle in an existing component, add the edge and remove the highest cost edge from that cycle (which may be the current edge). This approach is similar to Kruskal's algorithm but does not require the edges to be sorted, an important consideration in this problem. |
| 11.24 | Suppose we have a file containing a sequence of positive and negative numbers a1, a2, . . . ,an. Write an O(n) program to find a contiguous subsequence ai, ai+1, . . . ,aj that has the largest sum ai + ai+1 ?? ?/FONT> + aj of any such subsequence. |
For additional material on external sorting see Knuth [1973]. Further material on external data structures and their use in database systems can be found there and in Ullman [1982] and Wiederhold [1982]. Polyphase sorting in discussed by Shell [1971]. The six-buffer merging scheme in Section 11.2 is from Friend [1956] and the four-buffer scheme from Knuth [1973].
Secondary index selection, of which Exercise 11.21 is a simplification, is discussed by Lum and Ling [1970] and Schkolnick [1975]. B-trees originated with Bayer and McCreight [1972]. Comer [1979] surveys the many variations, and Gudes and Tsur [1980] discusses their performance in practice.
Information about Exercise 11.12, one- and two- tape sorting, can be found in Floyd and Smith [1973]. Exercise 11.22 on interpolation search is discussed in detail by Yao and Yao [1976] and Perl, Itai, and Avni [1978].
An elegant implementation of the approach suggested in Exercise 11.23 to the external minimum-cost spanning tree problem was devised by V. A. Vyssotsky around 1960 (unpublished). Exercise 11.24 is due to M. I. Shamos.
† It is tempting to assume that if (1) and (2) take the same time, then selection could never catch up with reading; if the whole block were not yet read, we would select from the first records of the block, those that had the lower keys, anyway. However, the nature of reading from disks is that a long period elapses before the block is found and anything at all is read. Thus our only safe assumption is that nothing of the block being read in a stage is available for selection during that stage.
† If these are not the first runs from each file, then this initialization can be done after the previous runs were read and the last 4b records from these runs are being merged.
† This strategy is the simplest of a number of responses that can be made to the situation where a block has to be split. Some other choices, providing higher average occupancy of blocks at the cost of extra work with each insertion, are mentioned in the exercises.
† We can use a variety of strategies to prevent leaf blocks from ever becoming completely empty. In particular, we describe below a scheme for preventing interior nodes from getting less than half full, and this technique can be applied to the leaves as well, with a value of m equal to the largest number of records that will fit in one block.