Parsing Server Data
Now that we have data from the server, we need to find the exact information we need and make sure that it is in a format that our Ajax application can use. To do that, we'll first need to examine the information. Because the data is a nicely structured XML document, our script walks the XML document tree to find and extract the particular data we need and store it in variables. Then, if needed, the script can reformat the data for later use.
The HTML is unchanged from the last example, so all we need to do is add more code in the JavaScript file. The result is Script 15.5. For this task, the XML file is data about photographs stored on Flickr; a portion of the XML can be seen in Script 15.6.
Script 15.5. The additional JavaScript in this script allows you to parse the data you previously requested.
window.onload = initAll;
var xhr = false;
function initAll() {
if (window.XMLHttpRequest) {
xhr = new XMLHttpRequest();
}
else {
if (window.ActiveXObject) {
try {
xhr = new ActiveXObject ("Microsoft.XMLHTTP");
}
catch (e) { }
}
}
if (xhr) {
xhr.onreadystatechange = showPictures;
xhr.open("GET", "flickrfeed.xml", true);
xhr.send(null);
}
else {
alert("Sorry, but I couldn't create an XMLHttpRequest");
}
}
function showPictures() {
var tempDiv = document.createElement ("div");
var pageDiv = document.getElementById ("pictureBar");
if (xhr.readyState == 4) {
if (xhr.status == 200) {
tempDiv.innerHTML = xhr.responseText;
var allLinks = tempDiv. getElementsByTagName("a");
for (var i=1; i<allLinks.length; i+=2) {
pageDiv.appendChild(allLinks[i]. cloneNode(true));
}
}
else {
alert("There was a problem with the request " + xhr.status);
}
}
}
|
Script 15.6. This is an edited and shortened version of the XML file that Flickr provides; the original was approximately 500 lines in length!
<?xml version="1.0" encoding="utf-8" standalone= "yes"?>
<feed xmlns="http://www.w3.org/2005/Atom" xmlns: dc="http://purl.org/dc/elements/1.1/">
<title>Dori Smith's Photos</title>
<link rel="self" href="http://www.flickr. com/services/feeds/photos_public.gne?id=
 23922109@N00" />
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/ dorismith/"/>
<id>tag:flickr.com,2005:/photos/public/ 116078</id>
<icon>http://static.flickr.com/5/ buddyicons/23922109@N00.jpg?1113973282 </icon>
<subtitle>A feed of Dori Smith's Photos </subtitle>
<updated>2006-03-22T20:12:44Z</updated>
<generator uri="http://www.flickr.com/ ">Flickr</generator>
<entry>
<title>Mash note</title>
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/
dorismith/116463569/"/>
<id>tag:flickr.com,2005:/photo/116463569</id>
<published>2006-03-22T20:12:44Z</published>
<updated>2006-03-22T20:12:44Z</updated>
<dc:date.Taken>2006-03-22T12:12:44-08:00</dc:date.Taken>
<content type="html"><p><a href="http://www.flickr.com/people/dorismith/">Dori
Smith</a> posted a photo:</p>
<p><a href="http://www.flickr.com/photos/dorismith/116463569/" title="Mash note"><img
src="http:// static.flickr.com/44/116463569_483fd4ee7c_s.jpg" width="75" height="75"
alt="Mash note" style= "border: 5px solid #ddd;" /></a></p></content>
<author>
<name>Dori Smith</name>
<uri>http://www.flickr.com/people/dorismith/</uri>
</author>
<category term="dorismith" scheme="http://www.flickr.com/photos/tags/" />
<category term="ncmug" scheme="http://www.flickr.com/photos/tags/" />
</entry>
<entry>
<title>My odometer reading</title>
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos
/dorismith/69558528/"/>
<id>tag:flickr.com,2005:/photo/69558528</id>
<published>2005-12-03T03:48:40Z</published>
<updated>2005-12-03T03:48:40Z</updated>
<dc:date.Taken>2005-11-07T13:04:54-08:00</dc:date.Taken>
<content type="html"><p><a href="http://www.flickr.com/people/dorismith/">Dori
Smith</a> posted a photo:</p>
<p><a href="http://www.flickr.com/photos/dorismith/69558528/" title="My odometer
reading"><img src= "http://static.flickr.com/20/69558528_d6b9bb4b08_s.jpg" width="75"
height="75" alt="My odometer reading" style="border: 5px solid #ddd;" /></a></p>
<p>Why yes, I am a geek.</p></content>
<author>
<name>Dori Smith</name>
<uri>http://www.flickr.com/people/dorismith/</uri>
</author>
<category term="32768" scheme="http://www.flickr.com/photos/tags/" />
<category term="dori" scheme="http://www.flickr.com/photos/tags/" />
<category term="geek" scheme="http://www.flickr.com/photos/tags/" />
<category term="dorismith" scheme="http://www.flickr.com/photos/tags/" />
</entry>
</feed> 23922109@N00" />
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/ dorismith/"/>
<id>tag:flickr.com,2005:/photos/public/ 116078</id>
<icon>http://static.flickr.com/5/ buddyicons/23922109@N00.jpg?1113973282 </icon>
<subtitle>A feed of Dori Smith's Photos </subtitle>
<updated>2006-03-22T20:12:44Z</updated>
<generator uri="http://www.flickr.com/ ">Flickr</generator>
<entry>
<title>Mash note</title>
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/
dorismith/116463569/"/>
<id>tag:flickr.com,2005:/photo/116463569</id>
<published>2006-03-22T20:12:44Z</published>
<updated>2006-03-22T20:12:44Z</updated>
<dc:date.Taken>2006-03-22T12:12:44-08:00</dc:date.Taken>
<content type="html"><p><a href="http://www.flickr.com/people/dorismith/">Dori
Smith</a> posted a photo:</p>
<p><a href="http://www.flickr.com/photos/dorismith/116463569/" title="Mash note"><img
src="http:// static.flickr.com/44/116463569_483fd4ee7c_s.jpg" width="75" height="75"
alt="Mash note" style= "border: 5px solid #ddd;" /></a></p></content>
<author>
<name>Dori Smith</name>
<uri>http://www.flickr.com/people/dorismith/</uri>
</author>
<category term="dorismith" scheme="http://www.flickr.com/photos/tags/" />
<category term="ncmug" scheme="http://www.flickr.com/photos/tags/" />
</entry>
<entry>
<title>My odometer reading</title>
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos
/dorismith/69558528/"/>
<id>tag:flickr.com,2005:/photo/69558528</id>
<published>2005-12-03T03:48:40Z</published>
<updated>2005-12-03T03:48:40Z</updated>
<dc:date.Taken>2005-11-07T13:04:54-08:00</dc:date.Taken>
<content type="html"><p><a href="http://www.flickr.com/people/dorismith/">Dori
Smith</a> posted a photo:</p>
<p><a href="http://www.flickr.com/photos/dorismith/69558528/" title="My odometer
reading"><img src= "http://static.flickr.com/20/69558528_d6b9bb4b08_s.jpg" width="75"
height="75" alt="My odometer reading" style="border: 5px solid #ddd;" /></a></p>
<p>Why yes, I am a geek.</p></content>
<author>
<name>Dori Smith</name>
<uri>http://www.flickr.com/people/dorismith/</uri>
</author>
<category term="32768" scheme="http://www.flickr.com/photos/tags/" />
<category term="dori" scheme="http://www.flickr.com/photos/tags/" />
<category term="geek" scheme="http://www.flickr.com/photos/tags/" />
<category term="dorismith" scheme="http://www.flickr.com/photos/tags/" />
</entry>
</feed>
|
To parse information from the server:
1. |
xhr.onreadystatechange = showPictures;
xhr.open("GET", "flickrfeed.xml", true);
Every time readyState changes, we want to call the showPictures() function. The file name we want to read off the server is flickrfeed.xml. Both those values are set here.
| 2. |
var tempDiv = document.createElement ("div");
var pageDiv = document. getElementById("pictureBar");
Down in showPictures() is where the real work is done. We start by creating variables to store two elements: tempDiv, a temporary div placeholder, and pageDiv, a reference to the pictureBar div on the page.
| | | 3. |
tempDiv.innerHTML = xhr.responseText;
var allLinks = tempDiv. getElementsByTagName("a");
The response back from the server contained XML, but for the sake of convenience here, we're taking the data from responseText (that is, the text version) and throwing it into tempDiv's innerHTML property.
Take a look at the XML in Script 15.6, and you'll see that there's a lot of stuff there that we don't care about at allin fact, all we want is what's in the <a> tags (and really, only half of those). So, we start to narrow down to just what we want by creating the allLinks array, which will contain the contents of all the <a> nodes in the document.
| 4. |
for (var i=1; i<allLinks.length; i+=2) {
As previously mentioned, we only want half the <a> nodes, so we winnow out the ones here that we don't want. In a file with information about 20 photos, there will be 20 <entry> nodes, each of which contains two links. Each <entry> node contains the photographer's name (linked to their Flickr page), followed by a thumbnail image which is linked to the full-size version. We want just the latter, so we can go through the loop starting with 1 (rather than 0) and increment i by 2 each go-round.
The end result: we'll get links 1, 3, 5, and so on, each of which is just the thumbnail image inside a link.
| | | 5. |
pageDiv.appendChild(allLinks[i]. cloneNode(true));
Inside the loop, we take the node that we want, clone it, and then append it onto the HTML page's pageDiv. The end result is as we see it in Figure 15.3, where every thumbnail image on the page is a link back to the full-size version.
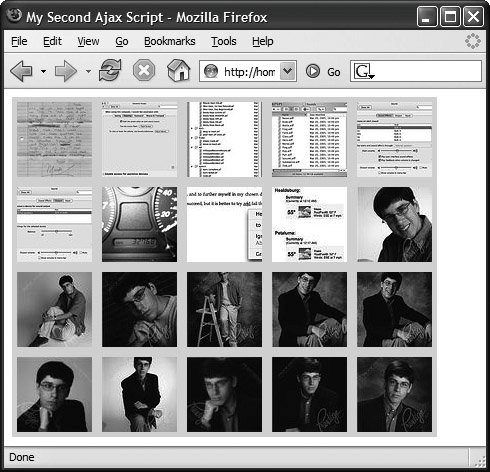
We need to use cloneNode and not simply append allLinks[i] because using append actually moves the nodes from one to anotherinstead, we want to duplicate what we've already got. The value true passed as a parameter tells JavaScript to clone not just this node, but also any child nodes of this node, and that's exactly what we want to do to get the <img> node along with the <a>.
|
 Tips Tips
While you can't read a data file that's stored on another server (see the "Getting Your Data" sidebar for more about why that's the case), you can always have your HTML file load information from another server. Here, your Web page, no matter where it is, is able to display images from flickr.com's servers. One of the best things about the new crop of Web 2.0 dot-coms is that they understand that people want access to dataand not just their own data, but other people's data (when they've agreed to make it public) as well. For instance, it's possible to search Flickr for all the photographs containing the tags "Hawaii" and "sunset," and then get the result as an XML file. Combine that with this script or the next, and you'll always have new and lovely photos on your page.
|
One of the things people want to do when they first hear about Ajax is write JavaScript that reads in all kinds of XML files (including RSS and Atom feeds), mash them up, and then put the result on their own Web page.
The bad news: it doesn't quite work that waya script can only read a file that comes from the same server as the one that the script is on itself. If you think about it for a while, you'll start to figure out why; after all, if a script could read anything, then that would open up all kinds of possible security scams and fake sites.
The sort-of good news: you can have a program on your server that goes out periodically, grabs an XML file, and then stores it locally. Once you've done that, your Ajax application will have no problems reading it. In this example and the next, it's assumed that you've got something running that grabs the Flickr data file of your choice periodically and saves it on your server. How to do that, though, is beyond the scope of this book.
|
|