| I l@ve RuBoard |
Scripting languages were designed in part in order to help people do repetitive tasks quickly and simply. One of the common things webmasters, system administrators, and programmers need to do is to take a set of files, select a subset of those files, do some sort of manipulation on this subset, and write the output to one or a set of output files. (For example, in each file in a directory, find the last word of every other line that starts with something other than the # character, and print it along with the name of the file.) This is a task for which special-purpose tools have been developed, such as sed and awk. We find that Python does the job just fine using very simple tools.
The sys module is most helpful when it comes to dealing with an input file, parsing the text it contains and processing it. Among its attributes are three file objects, called sys.stdin , sys.stdout , and sys.stderr . The names come from the notion of the three streams, called standard in, standard out, and standard error, which are used to connect command line tools. Standard output (stdout) is used by every print statement. It's a file object with all the output methods of file objects opened in write mode, such as write and writelines. The other often-used stream is standard in (stdin), which is also a file object, but with the input methods, such as read, readline, and readlines. For example, the following script counts all the lines in the file that is "piped in":
import sys data = sys.stdin.readlines() print "Counted", len(data), "lines."
On Unix, you could test it by doing something like:
% cat countlines.py | python countlines.py Counted 3 lines.
On Windows or DOS, you'd do:
C:\> type countlines.py | python countlines.py Counted 3 lines.
The readlines function is useful when implementing simple filter operations. Here are a few examples of such filter operations:
import sys
for line in sys.stdin.readlines():
if line[0] == '#':
print line,
Note that a final comma is needed after the print statement because the line string already includes a newline character as its last character.
import sys, string
for line in sys.stdin.readlines():
words = string.split(line)
if len(words) >= 4:
print words[3]
We look at the length of the words list to find if there are indeed at least four words. The last two lines could also be replaced by the try/except idiom, which is quite common in Python:
try:
print words[3]
except IndexError: # there aren't enough words
passimport sys, string
for line in sys.stdin.readlines():
words = string.split(line, ':')
if len(words) >= 4:
print string.lower(words[3])import sys, string
lines = sys.stdin.readlines()
sys.stdout.writelines(lines[:10]) # first ten lines
sys.stdout.writelines(lines[-10:]) # last ten lines
for lineIndex in range(0, len(lines), 2): # get 0, 2, 4, ...
sys.stdout.write(lines[lineIndex]) # get the indexed lineimport string text = open(fname).read() print string.count(text, 'Python')
In this more complicated example, the task is to "transpose" a file; imagine you have a file that looks like:
Name: Willie Mark Guido Mary Rachel Ahmed Level: 5 4 3 1 6 4 Tag#: 1234 4451 5515 5124 1881 5132
And you really want it to look like the following instead:
Name: Level: Tag#: Willie 5 1234 Mark 4 4451 ...
You could use code like the following:
import sys, string
lines = sys.stdin.readlines()
wordlists = []
for line in lines:
words = string.split(line)
wordlists.append(words)
for row in range(len(wordlists[0])):
for col in range(len(wordlists)):
print wordlists[col][row] + '\t',
print
Of course, you should really use much more defensive programming techniques to deal with the possibility that not all lines have the same number of words in them, that there may be missing data, etc. Those techniques are task-specific and are left as an exercise to the reader.
All the preceding examples assume you can read the entire file at once (that's what the readlines call expects). In some cases, however, that's not possible, for example when processing really huge files on computers with little memory, or when dealing with files that are constantly being appended to (such as log files). In such cases, you can use a while/readline combination, where some of the file is read a bit at a time, until the end of file is reached. In dealing with files that aren't line-oriented, you must read the file a character at a time:
# read character by character
while 1:
next = sys.stdin.read(1) # read a one-character string
if not next: # or an empty string at EOF
break
Process character 'next'
Notice that the read() method on file objects returns an empty string at end of file, which breaks out of the while loop. Most often, however, the files you'll deal with consist of line-based data and are processed a line at a time:
# read line by line
while 1:
next = sys.stdin.readline() # read a one-line string
if not next: # or an empty string at EOF
break
Process line 'next'
Being able to read stdin is a great feature; it's the foundation of the Unix toolset. However, one input is not always enough: many tasks need to be performed on sets of files. This is usually done by having the Python program parse the list of arguments sent to the script as command-line options. For example, if you type:
% python myScript.py input1.txt input2.txt input3.txt output.txt
you might think that myScript.py wants to do something with the first three input files and write a new file, called output.txt. Let's see what the beginning of such a program could look like:
import sysinputfilenames, outputfilename = sys.argv[1:-1], sys.argv[-1]for inputfilename in inputfilenames: inputfile = open(inputfilename, "r") do_something_with_input(inputfile) outputfile = open(outputfilename, "w") write_results(outputfile)
The second line extracts parts of the argv attribute of the sys module. Recall that it's a list of the words on the command line that called the current program. It starts with the name of the script. So, in the example above, the value of sys.argv is:
['myScript.py', 'input1.txt', 'input2.txt', 'input3.txt', 'output.txt'].
The script assumes that the command line consists of one or more input files and one output file. So the slicing of the input file names starts at 1 (to skip the name of the script, which isn't an input to the script in most cases), and stops before the last word on the command line, which is the name of the output file. The rest of the script should be pretty easy to understand (but won't work until you provide the do_something_with_input() and write_results() functions).
Note that the preceding script doesn't actually read in the data from the files, but passes the file object down to a function to do the real work. Such a function often uses the readlines() method on file objects, which returns a list of the lines in that file. A generic version of do_something_with_input() is:
def do_something_with_input(inputfile):
for line in inputfile.readlines()
process(line)
The combination of this idiom with the preceding one regarding opening each file in the sys.argv[1:] list is so common that Python 1.5 introduced a new module that's designed to help do just this task. It's called fileinput and works like this:
import fileinput
for line in fileinput.input():
process(line)
The fileinput.input() call parses the arguments on the command line, and if there are no arguments to the script, uses sys.stdin instead. It also provides a bunch of useful functions that let you know which file and line number you're currently manipulating:
import fileinput, sys, string
# take the first argument out of sys.argv and assign it to searchterm
searchterm, sys.argv[1:] = sys.argv[1], sys.argv[2:]
for line in fileinput.input():
num_matches = string.count(line, searchterm)
if num_matches: # a nonzero count means there was a match
print "found '%s' %d times in %s on line %d." % (searchterm, num_matches,
fileinput.filename(), fileinput.filelineno())
If this script were called mygrep.py, it could be used as follows:
% python mygrep.py in *.py found 'in' 2 times in countlines.py on line 2. found 'in' 2 times in countlines.py on line 3. found 'in' 2 times in mygrep.py on line 1. found 'in' 4 times in mygrep.py on line 4. found 'in' 2 times in mygrep.py on line 5. found 'in' 2 times in mygrep.py on line 7. found 'in' 3 times in mygrep.py on line 8. found 'in' 3 times in mygrep.py on line 12.
We have now covered reading existing files, and if you remember the discussion on the open built-in function in Chapter 2, you know how to create new files. There are a lot of tasks, however, that need different kinds of file manipulations, such as directory and path management and removing files. Your two best friends in such cases are the os and os.path modules described in Chapter 8.
Let's take a typical example: you have lots of files, all of which have a space in their name, and you'd like to replace the spaces with underscores. All you really need is the os.curdir attribute (which returns an operating-system specific string that corresponds to the current directory), the os.listdir function (which returns the list of filenames in a specified directory), and the os.rename function:
import os, string
if len(sys.argv) == 1: # if no filenames are specified,
filenames = os.listdir(os.curdir) # use current dir
else: # otherwise, use files specified
filenames = sys.argv[1:] # on the command line
for filename in filenames:
if ' ' in filename:
newfilename = string.replace(filename, ' ', '_')
print "Renaming", filename, "to", newfilename, "..."
os.rename(filename, newfilename)
This program works fine, but it reveals a certain Unix-centrism. That is, if you call it with wildcards, such as:
python despacify.py *.txt
you find that on Unix machines, it renames all the files with names with spaces in them and that end with .txt. In a DOS-style shell, however, this won't work because the shell normally used in DOS and Windows doesn't convert from *.txt to the list of filenames; it expects the program to do it. This is called globbing, because the * is said to match a glob of characters.
The glob module exports a single function, also called glob, which takes a filename pattern and returns a list of all the filenames that match that pattern (in the current working directory):
import sys, glob, operator print sys.argv[1:] sys.argv = reduce(operator.add, map(glob.glob, sys.argv)) print sys.argv[1:]
Running this on Unix and DOS shows that on Unix, the Python glob didn't do anything because the globbing was done by the Unix shell before Python was invoked, and on DOS, Python's globbing came up with the same answer:
/usr/python/book$ python showglob.py *.py ['countlines.py', 'mygrep.py', 'retest.py', 'showglob.py', 'testglob.py'] ['countlines.py', 'mygrep.py', 'retest.py', 'showglob.py', 'testglob.py'] C:\python\book> python showglob.py *.py ['*.py'] ['countlines.py', 'mygrep.py', 'retest.py', 'showglob.py', 'testglob.py']
This script isn't trivial, though, because it uses two conceptually difficult operations; a map followed by a reduce. map was mentioned in Chapter 4, but reduce is new to you at this point (unless you have background in LISP-type languages). map is a function that takes a callable object (usually a function) and a sequence, calls the callable object with each element of the sequence in turn, and returns a list containing the values returned by the function. For an graphical representation of what map does, see Figure 9.1.[3]
[3] It turns out that map can do more; for example, if None is the first argument, map converts the sequence that is its second argument to a list. It can also operate on more than one sequence at a time. Check a reference source for details.
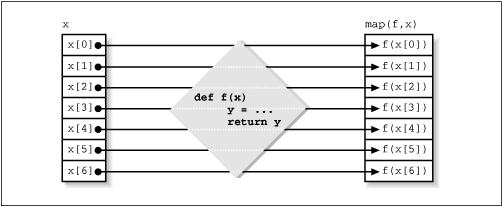
map is needed here (or something equivalent) because you don't know how many arguments were entered on the command line (e.g., it could have been *.py *.txt *.doc). So the glob.glob function is called with each argument in turn. Each glob.glob call returns a list of filenames that match the pattern. The map operation then returns a list of lists, which you need to convert to a single list梩he combination of all the lists in this list of lists. That means doing list1 + list2 + ... + listN. That's exactly the kind of situation where the reduce function comes in handy.
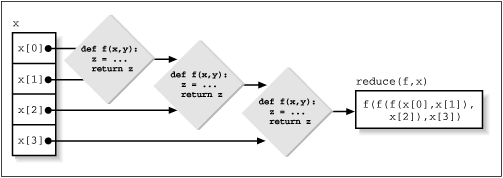
Just as with map, reduce takes a function as its first argument and applies it to the first two elements of the sequence it receives as its second argument. It then takes the result of that call and calls the function again with that result and the next element in the sequence, etc. (See Figure 9.2 for an illustration of reduce.) But wait: you need + applied to a set of things, and + doesn't look like a function (it isn't). So a function is needed that works the same as +. Here's one:
define myAdd(something, other):
return something + other
You would then use reduce(myAdd, map(...)). This works fine, but better yet, you can use the add function defined in the operator module, which does the same thing. The operator module defines functions for every syntactic operation in Python (including attribute-getting and slicing), and you should use those instead of homemade ones for two reasons. First, they've been coded, debugged, and tested by Guido, who has a pretty good track record at writing bugfree code. Second, they're actually C functions, and applying reduce (or map, or filter) to C functions results in much faster performance than applying it to Python functions. This clearly doesn't matter when all you're doing is going through a few hundred files once. If you do thousands of globs all the time, however, speed can become an issue, and now you know how to do it quickly.
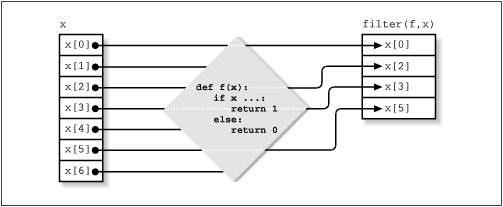
The filter built-in function, like map and reduce, takes a function and a sequence as arguments. It returns the subset of the elements in the sequence for which the specified function returns something that's true. To find all of the even numbers in a set, type this:
>>> numbers = range(30)
>>> def even(x):
... return x % 2 == 0
... >>> print numbers
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29] >>> print filter(even, numbers)
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28]
Or, if you wanted to find all the words in a file that are at least 10 characters long, you could use:
import string
words = string.split(open('myfile.txt').read()) # get all the words
def at_least_ten(word):
return len(word) >= 10
longwords = filter(at_least_ten, words)
For a graphical representation of what filter does, see Figure 9.3. One nice special feature of filter is that if one passes None as the first argument, it filters out all false entries in the sequence. So, to find all the nonempty lines in a file called myfile.txt, do this:
lines = open('myfile.txt').readlines()
lines = filter(None, lines) # remember, the empty string is false
map, filter, and reduce are three powerful constructs, and they're worth knowing about; however, they are never necessary. It's fairly simple to write a Python function that does the same thing as any of them. The built-in versions are prob-ably faster, especially when operating on built-in functions written in C, such as the functions in the operator module.
If you've ever written a shell script and needed to use intermediary files for storing the results of some intermediate stages of processing, you probably suffered from directory litter. You started out with 20 files called log_001.txt, log_002.txt etc., and all you wanted was one summary file called log_sum.txt. In addition, you had a whole bunch of log_001.tmp, log_001.tm2, etc. files that, while they were labeled temporary, stuck around. At least that's what we've seen happen in our own lives. To put order back into your directories, use temporary files in specific directories and clean them up afterwards.
To help in this temporary file-management problem, Python provides a nice little module called tempfile that publishes two functions: mktemp() and TemporaryFile(). The former returns the name of a file not currently in use in a directory on your computer reserved for temporary files (such as /tmp on Unix or C:\TMP on Windows). The latter returns a new file object directly. For example:
# read input file
inputFile = open('input.txt', 'r')
import tempfile
# create temporary file
tempFile = tempfile.TemporaryFile() # we don't even need to
first_process(input = inputFile, output = tempFile) # know the filename...
# create final output file
outputFile = open('output.txt', 'w')
second_process(input = tempFile, output = outputFile)
Using tempfile.TemporaryFile() works well in cases where the intermediate steps manipulate file objects. One of its nice features is that when it's deleted, it automatically deletes the file it created on disk, thus cleaning up after itself. One important use of temporary files, however, is in conjunction with the os.system call, which means using a shell, hence using filenames, not file objects. For example, let's look at a program that creates form letters and mails them to a list of email addresses (on Unix only):
formletter = """Dear %s,\nI'm writing to you to suggest that ...""" # etc.
myDatabase = [('Bill Clinton', 'bill@whitehouse.gov.us'),
('Bill Gates', 'bill@microsoft.com'),
('Bob', 'bob@subgenius.org')]
for name, email in myDatabase:
specificLetter = formletter % name
tempfilename = tempfile.mktemp()
tempfile = open(tempfilename, 'w')
tempfile.write(specificLetter)
tempfile.close()
os.system('/usr/bin/mail %(email)s -s "Urgent!" < %(tempfilename)s' % vars())
os.remove(tempfilename)
The first line in the for loop returns a customized version of the form letter based on the name it's given. That text is then written to a temporary file that's emailed to the appropriate email address using the os.system call (which we'll cover later in this chapter). Finally, to clean up, the temporary file is removed. If you forgot how the % bit works, go back to Chapter 2 and review it; it's worth knowing. The vars() function is a built-in function that returns a dictionary corresponding to the variables defined in the current local namespace. The keys of the dictionary are the variable names, and the values of the dictionary are the variable values. vars() comes in quite handy for exploring namespaces. It can also be called with an object as an argument (such as a module, a class, or an instance), and it will return the namespace of that object. Two other built-ins, locals() and globals(), return the local and global namespaces, respectively. In all three cases, modifying the returned dictionaries doesn't guarantee any effect on the namespace in question, so view these as read-only and you won't be surprised. You can see that the vars() call creates a dictionary that is used by the string interpolation mechanism; it's thus important that the names inside the %(...)s bits in the string match the variable names in the program.
Suppose you've run a program that stores its output in a text file, which you need to load. The program creates a file that's composed of a series of lines that each contain a value and a key separated by whitespace:
value key value key value keyand so on...
A key can appear on more than one line in the file, and you'd probably like to collect all the values that appear for each given key as you scan the file. Here's one way to solve this problem:
#!/usr/bin/env python
import sys, string
entries = {}
for line in open(sys.argv[1], 'r').readlines():
left, right = string.split(line)
try:
entries[right].append(left) # extend list
except KeyError:
entries[right] = [left] # first time seen
for (right, lefts) in entries.items():
print "%04d '%s'\titems => %s" % (len(lefts), right, lefts)
This script uses the readlines method to scan the text file line by line, and calls the built-in string.split function to chop the line into a list of substrings梐 list containing the value and key strings separated by blanks or tabs in the file. To store all occurrences of a key, the script uses a dictionary called entries. The try statement in the loop tries to add new values to an existing entry for a key; if no entry exists for the key, it creates one. Notice that the try could be replaced with an if here:
if entries.has_key(right): # is it already in the dictionary?
entries[right].append(left) # add to the list of current values for key
else:
entries[right] = [left] # initialize key's values list
Testing whether a dictionary contains a key is sometimes faster than catching an exception with the try technique; it depends on how many times the test is true. Here's an example of this script in action. The input filename is passed in as a command-line argument (sys.argv[1]):
% cat data.txt 1 one 2 one 3 two 7 three 8 two 10 one 14 three 19 three 20 three 30 three % python collector1.py data.txt 0003 'one' items => ['1', '2', '10'] 0005 'three' items => ['7', '14', '19', '20', '30'] 0002 'two' items => ['3', '8']
You can make this code more useful by packaging the scanner logic in a function that returns the entries dictionary as a result and wrapping the printing loop logic at the bottom in an if test:
#!/usr/bin/env python
import sys, string
def collect(file):
entries = {}
for line in file.readlines():
left, right = string.split(line)
try:
entries[right].append(left) # extend list
except KeyError:
entries[right] = [left] # first time seen
return entries
if __name__ == "__main__": # when run as a script
if len(sys.argv) == 1:
result = collect(sys.stdin) # read from stdin stream
else:
result = collect(open(sys.argv[1], 'r')) # read from passed filename
for (right, lefts) in result.items():
print "%04d '%s'\titems => %s" % (len(lefts), right, lefts)
This way, the program becomes a bit more flexible. By using the if __name__ == "__main_ _" trick, you can still run it as a top-level script (and get a display of the results), or import the function it defines and process the resulting dictionary explicitly:
# run as a script file
% collector2.py < data.txt
result displayed here...
# use in some other component (or interactively)
from collector2 import collect
result = collect(open("spam.txt", "r"))
process result here...
Since the collect function accepts an open file object, it also works on any object that provides the methods (i.e., interface) built-in files do. For example, if you want to read text from a simple string, wrap it in a class that implements the required interface and pass an instance of the class to the collect function:
>>> from collector2 import collect?/b>
>>> from StringIO import StringIO?/b>
>>>
>>> str = StringIO("1 one\n2 one\n3 two")?/b>
>>> result = collect(str)?/b> # scans the wrapped string
>>> print result?/b> # {'one':['1','2'],'two':['3']}?/i>
This code uses the StringIO class in the standard Python library to wrap the string into an instance that has all the methods file objects have; see the Library Reference for more details on StringIO. You could also write a different class or subclass from StringIO if you need to modify its behavior. Regardless, the collect function happily reads text from the StringIO object str, which happens to be an in-memory object, not a file.
The main reason all this works is that the collect function was designed to avoid making assumptions about the type of object its file parameter references. As long as the object exports a readlines method that returns a list of strings, collect doesn't care what type of object it processes. The interface is all that matters. This runtime binding[4] is an important feature of Python's object system, and allows you to easily write component programs that communicate with other components. For instance, consider a program that reads and writes satellite telemetry data using the standard file interface. By plugging in an object with the right sort of interface, you can redirect its streams to live sockets, GUI boxes, web interfaces, or databases without changing the program i tself or even recompiling it.
[4] Runtime binding means that Python doesn't know which sort of object implements an interface until the program is running. This behavior stems from the lack of type declarations in Python and leads to the notion of polymorphism; in Python, the meaning of a object operation (such as indexing, slicing, etc.) depends on the object being operated on.
| I l@ve RuBoard |