| [ Team LiB ] |
|
Introduction to Relational Database DesignMany people believe Access is such a simple product to use that database design is something they don't need to worry about. I couldn't disagree more! Just as a poorly planned vacation will generally not be very much fun, a database with poorly designed tables and relationships will fail to meet the needs of its users. The History of Relational Database DesignYou should be happy to learn that, although Microsoft Access is not a perfect application development environment, it measures up quite well as a relational database system. Goals of Relational Database DesignThe number-one goal of relational database design is to, as closely as possible, develop a database that models some real-world system. This involves breaking the real-world system into tables and fields and determining how the tables relate to each other. Although on the surface this might appear to be a trivial task, it can be an extremely cumbersome process to translate a real-world system into tables and fields. A properly designed database has many benefits. The processes of adding, editing, deleting, and retrieving table data are greatly facilitated in a properly designed database. In addition, reports are easy to build. Most importantly, the database is easy to modify and maintain. Rules of Relational Database DesignTo adhere to the relational model, you must follow certain rules. These rules determine what you store in a table and how you relate the tables. These are the rules:
The Rules of TablesThe Rules of Uniqueness and KeysIt is generally a good idea to choose a primary key that is
Following these rules greatly improves the performance and maintainability of a database application, particularly if it deals with large volumes of data. In examples such as this, I suggest adding EmployeeID as an AutoNumber field. Although the field would violate the rule of simplicity (because an employee number is meaningless to the user), it is both small and stable. Because it is numeric, it is also efficient to process. In fact, I use AutoNumber fields as primary keys for most of the tables that I build. The Rules of Foreign Keys and DomainsA foreign key in one table is the field that relates to the primary key in a second table. For example, the CustomerID field may be the primary key in a Customers table and the foreign key in an Orders table. Normalization and Normal Forms
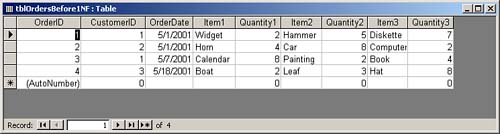
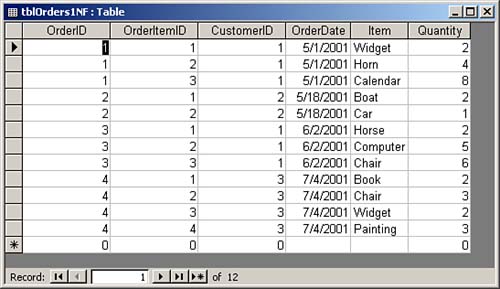
First Normal FormAnother requirement for first normal form is that the table must not contain repeating values. An example of repeating values is a scenario in which Item1, Quantity1, Item2, Quantity2, Item3, and Quantity3 fields are all found within the Orders table (see Figure 9.1). This design introduces several problems. What if the user wants to add a fourth item to the order? Furthermore, finding the total ordered for a product requires searching several columns. In fact, all numeric and statistical calculations on the table are extremely cumbersome. Repeating groups make it difficult to summarize and manipulate table data. The alternative, shown in Figure 9.2, achieves first normal form. Notice that each item ordered is located in a separate row. All fields are atomic, and the table contains no repeating groups. Figure 9.1. A table that contains repeating groups.
Figure 9.2. A table that achieves first normal form.
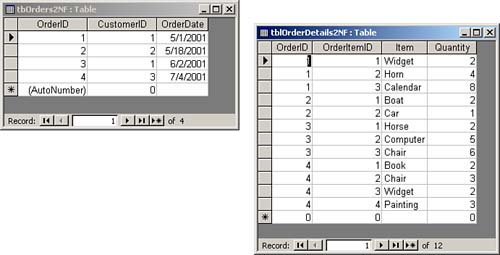
Second Normal Form
Figure 9.3. Tables that achieve second normal form.
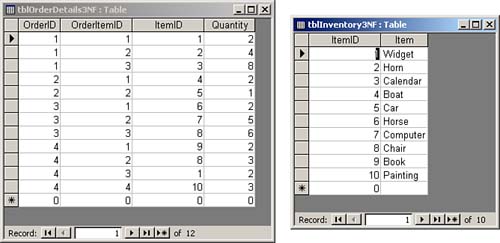
Third Normal FormTo attain third normal form, a table must meet all the requirements for first and second normal forms, and all non-key columns must be mutually independent. This means that you must eliminate any calculations, and you must break out the data into lookup tables. Lookup tables include tables such as inventory tables, course tables, state tables, and any other table where you look up a set of values from which you select the entry that you store in the foreign key field. For example, from the Customer table, you look up within the set of states in the state table to select the state associated with the customer. An example of a calculation stored in a table is the product of price multiplied by quantity. Instead of storing the result of this calculation in the table, you would generate the calculation in a query or in the control source of a control on a form or a report. The example in Figure 9.3 does not achieve third normal form because the description of the inventory items is stored in the Order Details table. If the description changes, all rows with that inventory item need to be modified. The Order Details table, shown in Figure 9.4, shows the item descriptions broken into an Inventory table. This design achieves third normal form. We have moved the description of the inventory items to the Inventory table, and ItemID is stored in the Order Details table. All fields are mutually independent. You can modify the description of an inventory item in one place. Figure 9.4. A table (on the right) that achieves third normal form.
Denormalization: Purposely Violating the RulesAn example of when denormalization might be the preferred tact could involve an open invoices table and a summarized accounting table. It might be impractical to calculate summarized accounting information for a customer when you need it. Instead, you can maintain the summary calculations in a summarized accounting table so that you can easily retrieve them as needed. Although the upside of this scenario is improved performance, the downside is that you must update the summary table whenever you make changes to the open invoices. This imposes a definite trade-off between performance and maintainability. You must decide whether the trade-off is worth it. If you decide to denormalize, you should document your decision. You should make sure that you make the necessary application adjustments to ensure that you properly maintain the denormalized fields. Finally, you need to test to ensure that the denormalization process actually improves performance. Integrity RulesAlthough integrity rules are not part of normal forms, they are definitely part of the database design process. Integrity rules are broken into two categories: overall integrity rules and database-specific integrity rules. Overall Integrity Rules
Entity integrity dictates that the primary key value cannot be Null. This rule applies not only to single-column primary keys, but also to multicolumn primary keys. In fact, in a multicolumn primary key, no field in the primary key can be Null. This makes sense because if any part of the primary key can be Null, the primary key can no longer act as a unique identifier for the row. Fortunately, the Jet Engine does not allow a field in a primary key to be Null. Database-Specific Integrity RulesDatabase-specific integrity rules are not applicable to all databases, but are, instead, dictated by business rules that apply to a specific application. Database-specific rules are as important as overall integrity rules. They ensure that the user enters only valid data into a database. An example of a database-specific integrity rule is requiring the delivery date for an order to fall after the order date. The Types of RelationshipsThree types of relationships can exist between tables in a database: one-to-many, one-to-one, and many-to-many. Setting up the proper type of relationship between two tables in a database is imperative. The right type of relationship between two tables ensures
The reasons behind these benefits are covered throughout this hour. Before you can understand the benefits of relationships, though, you must understand the types of relationships available. One-to-Many RelationshipsIn the Customers and Orders tables example, the CustomerID field that joins the two tables must be unique within the Customers table. If more than one customer in the Customers table has the same customer ID, it is not clear which customer belongs to an order in the Orders table. For this reason, the field that joins the two tables on the "one" side of the one-to-many relationship must be a primary key or have a unique index. In almost all cases, the field relating the two tables is the primary key of the table on the "one" side of the relationship. The field relating the two tables on the "many" side of the relationship is the foreign key. One-to-One Relationships
The maximum number of fields allowed in an Access table is 255. There are very few reasons a table should ever have more than 255 fields. In fact, before you even get close to 255 fields, you should take a close look at the design of the system. On the rare occasion when having more than 255 fields is appropriate, you can simulate a single table by moving some of the fields to a second table and creating a one-to-one relationship between the two tables. The last situation in which you would want to define one-to-one relationships is when you will use certain fields in a table for only a relatively small subset of records. An example is an Employees table and a Vesting table. Certain fields are required only for employees who are vested. If only a small percentage of a company's employees are vested, it is not efficient, in terms of performance or disk space, to place all the fields containing information about vesting in the Employees table. This is especially true if the vesting information requires a large number of fields. By breaking the information into two tables and creating a one-to-one relationship between the tables, you can reduce disk-space requirements and improve performance. This improvement is particularly pronounced if the Employees table is large. Many-to-Many Relationships |
| [ Team LiB ] |
|