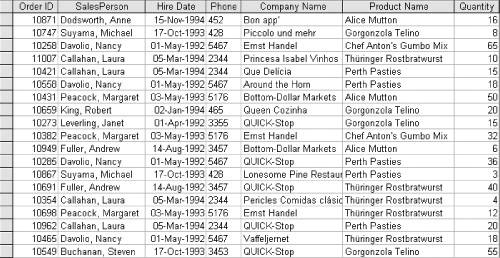
Eliminating RedundancyRedundancy wastes resources and, more importantly, it makes life a lot harder. Take, for example, the recordset shown in Figure 2-1, representing a company's invoices. (Assume, for the moment, that this recordset is a base table that is explicitly stored in the database, not the result of a query.) Figure 2-1. This Recordset Has Redundant Data
You can see that HireDate and Phone values are listed several times for each employee. Now, this has a number of consequences. First, it means that every time you enter a new invoice you have to re-enter values into these fields. And, of course, every time you enter something you have another chance to get it wrong. For example, given the recordset shown in Figure 2-2, how do you know whether Nancy Davolio was hired in 1992 or 1999? Figure 2-2. Duplicate Data Can Result in Inconsistencies
Second, the structure prevents you from storing the hire date or phone number for a new employee until that employee has made a sale. Third, if the invoices for a given year are archived and removed from the database, the hire date and phone number information will be lost. These kinds of problems, usually called update anomalies, are even worse if the redundant data is stored in more than one relation. Consider the recordsets shown in Figure 2-3. (Again, assume that these are base tables, not query results.) If the phone number of Alfreds Futterkiste changes, it must be changed in seven different placesonce in the Customer recordset, and six times in the Invoice recordset. Figure 2-3. The Same Duplicate Data Can Exist in Multiple Recordsets
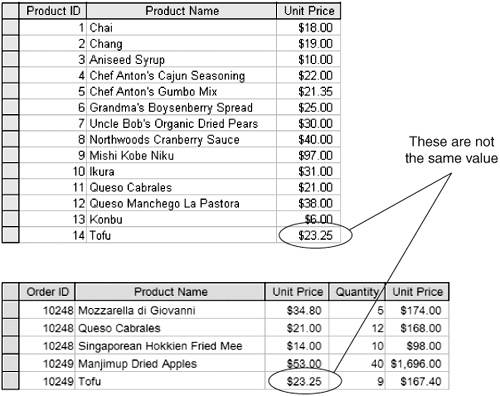
It's not so much that this is impossible or even particularly difficult to do. The problem is remembering to do it. And even if you never forget anything, how will you ensure that the maintenance programmer modifying your system six months from now will know there are redundancies of this kind, much less remember (or know how) to handle them appropriately? It's better, much better, to avoid the redundancies and the resulting problems altogether. However, you need to make sure that the redundant attributes you're considering really are redundant. Consider the example in Figure 2-4. At first glance, you might think that the UnitPrice attributes in these two relations are redundant. But they actually represent two distinct values. The UnitPrice attribute in the Products relation represents the current selling price. The UnitPrice attribute in the Orders relation represents the price at the time the item was sold. Tofu, for example, is listed at a UnitPrice of $18.60 in the Orders relation and $23.25 in the Products relation. The fact that Tofu currently sells for $23.25 doesn't change the fact that it was sold for $18.60 at some point in the past. The two attributes are defined on the same domain, but they are logically distinct. Figure 2-4. Seemingly Identical Data Might Not Actually Be Redundant
|