Basic PrinciplesThe process of structuring the data in the problem space to achieve these two goals of eliminating redundancy and ensuring flexibility is called normalization. The principles of normalization discussed in the rest of this chapter are tools for controlling the structure of data in the same way that a paper clip controls sheets of paper. The normal forms (we'll discuss six) specify increasingly stringent rules for the structure of relations. Each form extends the previous one in such a way as to prevent certain kinds of update anomalies. Bear in mind that the normal forms are not a prescription for creating a "correct" data model. A data model could be perfectly normalized and still fail to answer the questions asked of it; or, it might provide the answers, but so slowly and awkwardly that the database system built around it is unusable. But if your data model is normalizedthat is, if it conforms to the rules of relational structurethe chances are high that the result will be an efficient, effective data model. Before we turn to normalization, however, you should be familiar with a couple of underlying principles. Lossless DecompositionThe relational model allows relations to be joined in various ways by linking attributes. The process of obtaining a fully normalized data model involves removing redundancy by dividing relations in such a way that the resultant relations can be recombined without losing any of the information. This is the principle of lossless decomposition. For example, given the relation shown in Figure 2-7, you can derive the two relations shown in Figure 2-8. Figure 2-7. An Unnormalized Relation
Figure 2-8. The Relation in Figure 2-8 Can Be Divided into These Two Relations without Losing Any Information
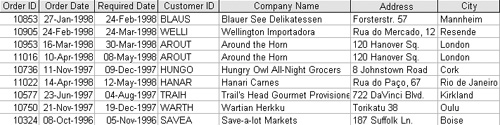
Candidate Keys and Primary KeysIn Chapter 1, I defined a relation body as an unordered set of zero or more tuples and pointed out that, by definition, each member of a set is unique. This being the case, for any relation there must be some combination of attributes that uniquely identifies each tuple. If the rows cannot be uniquely identified, they do not constitute tuples in relational theory. This set of one or more attributes is called a candidate key. There might be more than one candidate key for any given relation, but it must always be the case that each candidate key uniquely identifies each tuple, not just for any specific set of tuples but for all possible tuples for all time. The inverse of this principle must also be true, by the way. Given any two tuples with the same candidate key, both tuples must represent the same entity. Like so many things in relational design, the identification of a candidate key is semantic. You cannot do it by inspection. Just because some field or combination of attributes is unique for a given set of tuples, you cannot guarantee that it will be unique for all tuples, which it must be to qualify as a candidate key. Once again, you must understand the semanticswhat the data meansof the data model, not what it appears to mean. Consider the Orders relation shown at the bottom of Figure 2-8. The CustomerID is unique in the example, but it's extremely unlikely that it will remain that way. After all, most companies rely on repeat business. Despite appearances, the semantics of the model tell us that this field is not a candidate key. By definition, all relations must have at least one candidate key: the set of all attributes comprising the tuple. Candidate keys can be composed of a single attribute (a simple key) or of multiple attributes (a composite key). Some people are under the impression that composite keys are somehow incorrect, and that they must add an artificial identifiereither an identity or autonumber fieldto their tables to avoid them. Nothing could be further from the truth. Artificial keys are often more convenient, as we'll see, but composite keys are perfectly acceptable. However, an additional requirement of a candidate key is that it must be irreducible, so the set of all attributes is not necessarily a candidate key. In the relation shown in Figure 2-9, the attribute {CategoryName} is a candidate key, as is {Description}, but the set {CategoryName, Description}, although it is unique, is not a candidate key since the Description attribute is unnecessary. Figure 2-9. Candidate Keys Must Be Irreducible, so {CategoryName} Qualifies, but { CategoryName, Description} Does Not
It is sometimes the casealthough it doesn't happen oftenthat there are multiple possible candidate keys for a relation. In this case, it is customary to designate one candidate key as a primary key and consider other candidate keys alternate keys. This is an arbitrary decision and isn't very useful at the logical level. (Remember that the data model is purely abstract.) To help maintain the distinction between the model and its physical implementation, I prefer to use the term "candidate key" at the data model level and reserve "primary key" for the implementation. When the only possible candidate key is unwieldyit requires too many attributes or is too large, for exampleyou can use an artificial unique field data type for creating artificial keys with values that will be generated by the system. Called AutoNumber fields in Microsoft Jet and Identity fields in SQL Server, fields based on this data type are terrifically useful tools, provided you don't try to make them mean anything. They're just tags. They aren't guaranteed to be sequential, you have very little control over how they're generated, and if you try to use them to mean anything you'll cause more problems than you solve. Although choosing candidate keys is, as we've seen, a semantic process, don't assume that the attributes you use to identify an entity in the real world will make an appropriate candidate key. Individuals, for example, are usually referred to by their names, but a quick look at any phone book will establish that names are hardly unique. Of course, the name must provide a candidate key when combined with some other set of attributes, but this can be awkward to determine. I once worked in an office with about 20 people, of whom two were named Larry Simon and one was named Lary Simon. All three were Vice Presidents. Amongst ourselves, they were "Short Lary," "German Larry," and "Blond Larry"; that's height, nationality, and hair color combined with name, hardly a viable candidate key. In situations like this, it's probably best to use a system-generated ID number, such as an Autonumber or Identity field, but remember, don't try to make it mean anything. You need to be careful, of course, that your users are adding apparent duplicates intentionally, but as we'll see in Chapter 20, it's best to do this as part of the user interface rather than imposing artificial (and ultimately unnecessary) constraints on the data the system can maintain. Functional DependencyThe concept of functional dependency is an extremely useful tool for thinking about data structures. Given any tuple T, with two sets of attributes {X1...Xn} and {Y1...Yn} (the sets need not be mutually exclusive), then set Y is functionally dependent on set X if, for any legal value of X, there is only one legal value for Y. For example, in the relation shown in Figure 2-9, every tuple that has the same values for {CategoryName} will have the same value for {Description}. We can therefore say that the attribute CategoryName functionally determines the attribute Description. Note that functional dependency doesn't necessarily work the other way: knowing a value for Description won't allow us to determine the corresponding value for CategoryID. You can indicate the functional dependency between sets of attributes as shown in Figure 2-10. In text, you can express functional dependencies as X Figure 2-10. Functional Dependency Diagrams Are Largely Self-Explanatory
Functional dependency is interesting to academics because it provides a mechanism for developing something that starts to resemble a mathematics of data modeling. You can, for example, discuss the reflexivity and transitivity of a functional dependency if you are so inclined. In practical application, functional dependency is a convenient way of expressing what is a fairly self-evident concept: Given any relation, there will be some set of attributes that is unique to each tuple, and knowing those, it is possible to determine those attributes that are not unique. Thus, given the tuple {X, Y}, if {X} is a candidate key, then all attributes {Y} must necessarily be functionally dependent on {X}; this follows from the definition of candidate key. If {X} is not a candidate key and the functional dependency is not trivial (that is, {Y} is not a subset of {X}), then the relation will necessarily involve some redundancy, and further normalization will be required. To return to the example shown in Figure 2-9, by knowing the CategoryName, we can easily determine the CategoryDescription. In a sense, data normalization is the process of ensuring that, as shown in Figure 2-10, all the arrows come out of candidate keys. |


 Y, which reads "X functionally determines Y."
Y, which reads "X functionally determines Y."