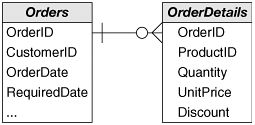
Modeling RelationshipsOnce you've determined that a relationship exists, you must model it by including attributes from one relation (the primary relation) in the other (the foreign relation), as shown in Figure 3-3. Figure 3-3. A Relationship Is Modeled by Including Attributes from the Primary Relation (Orders) in the Foreign Relation (OrderDetails)
The choice of primary and foreign relations isn't arbitrary. It is determined first by the cardinality of the relationship and secondin the rare situation where there is any doubtby the semantics of the data model. For example, given two relations that have a one-to-many relationship, the relation on the one side is always the primary relation, while the relation on the many side is always the foreign relation. That is, a candidate key from the relation on the one side is added (as a foreign key) to the relation on the many side. We'll be looking at this issue as we examine each type of relationship in the rest of this chapter.
And, of course, you don't just copy any attributes from the primary relation to the foreign relation; you must choose attributes that uniquely identify the primary entity. In other words, you add the attributes that make up the candidate key in the primary relation to the foreign relation. Not surprisingly, the duplicated attributes become known as the foreign key in the foreign relations. In the example shown in Figure 3-3, OrderIDthe candidate key of the Orders relationhas been added to the OrderDetails relation. Orders is the primary relation, and OrderDetails is the foreign relation. Note that the candidate key/foreign key pair that models the relationship need not be the primary key of the primary table; any candidate key will serve. You should use the candidate key that makes the most sense semantically. Sometimes you'll want to model not only the fact that a relationship exists, but also certain properties of the relationshipits duration or its commencement date, for example. In this case, it's useful to create an abstract relation representing the relationship. The Positions relation, shown in Figure 3-4, is an example of a "relationship relation". Figure 3-4. Abstract Relations Can Model the Properties of Relationships
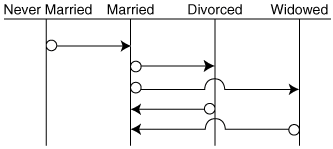
Note Some theoreticians argue that all relationships should be modeled separately, but it has always seemed to me that their argument is with the relational model itself, not the conventional methods for modeling a problem space. Separate relations representing relationships complicate the data model somewhat, and one might be tempted to simply include the relationship attributes in one of the participating relations. This approach isn't necessarily disastrous, but if there are a lot of attributes or a lot of relations with attributes, it can get unwieldy. More importantly, a distinct relationship entity allows you to track the history of a relationship. The model shown in Figure 3-4, for example, allows you to determine an individual's employment history, which would not have been possible had Position been made an attribute of the Employees relation. Abstract relationship entities are also useful when you need to track the way a relationship changes over time. Figure 3-5, for example, is a State Transition diagram describing the possible legal changes in an individual's marital status. Figure 3-5. State Transition Diagrams Plot the Valid Changes in an Entity's Status, in This Case an Individual's Marital Status
State Transition diagrams are not difficult to understand. Each vertical line indicates a valid state, while a horizontal line represents a change from one state to another. For example, an individual can go from "married" to "divorced", and vice versa, but not from "divorced" to "never married". Now, if all you need to model is an individual's current marital status, you don't need to implement an abstract relationship entity to make sure only valid changes are made. But if you ever need to know that John and Mary Smith were married in 1953 and divorced in 1972, and that Mary remarried in 1975 but was widowed in 1986, then you'll need an abstract relationship entity to track that. |