Implementing Data IntegrityUp until now, we've concentrated on capturing the problem space at an abstract level in the conceptual data model. In this section, we'll look at a few of the issues involved in creating the physical model of the problem space: the database schema. Moving from one level to another is primarily a change in terminologyrelations become tables and attributes become fieldsexcept for issues of data integrity. These never map quite as cleanly as one wants. Unknown and Nonexistent Values (Again)Earlier in this chapter, I somewhat blithely declared that domains and attributes should be examined to determine whether they are permitted to be empty or unknown. I didn't, then, discuss how these constraints might be implemented. The implementation issue (and it is an issue) can't be avoided once we turn to the database schema. The so-called "missing information problem" has been acknowledged since the relational model was first proposed. How does one indicate that any given bit of information is either missing (the customer does have a surname, we just don't know what it is) or nonexistent (the customer doesn't have a middle name)? Most relational databases, including Microsoft Jet databases and SQL Server databases, have incorporated the Null as a way of handling missing and nonexistent values. To call the Null a solution to the issue is probably excessive, as it has numerous problems. Some database experts reject Nulls entirely. C. J. Date declares that they "wreck the model,"[1] and I've lost track of how many times I've heard them declared "evil." Any remarks about the complexity of handling Nulls or rueful admissions to having been caught out by them will result in remarks along the lines of "Good. You shouldn't be using them. They should hurt."
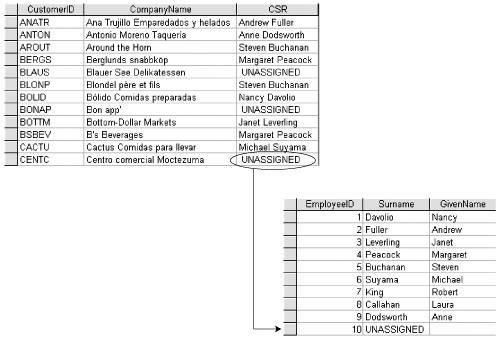
As an alternative, the "Nulls are evil" school recommends the use of specific values of the appropriate domain to indicate unknown or nonexistent values, or both. I think of this as the conventional value approach. The conventional value approach has several problems. First, in many instances the chosen value is only conventional. A date of 9/9/1900 doesn't really mean the date is unknown, we just agree that's what we'll interpret it to mean. And it's one of those "you only know if somebody tells you" situations that place an unfair burden on the system and the user alike. I fail to see that this approach is an improvement over the Null. A Null is a conventional value as well, of course, but it can't be confused with anything else, and it has the advantage of being supported by the relational model and most relational database engines. The second, and to my mind disqualifying, problem with the conventional value approach is its impact on referential integrity. Take, for example, an optional relationship between a Customer and a Customer Service Representative (CSR), such that the CSR, if one is assigned, must be listed in the CSR table. The conventional value approach requires that a record be added to the CSR table to match the conventional value chosen to indicate that no CSR is assigned, as shown in Figure 4-2. Figure 4-2. Conventional Values Require the Addition of "Dummy" Records to Maintain Referential Integrity
Now, how many CSRs does the company employ? One less than the number of CSRs listed in the table, since one of them is a dummy record. Eek. What's the average number of customers per CSR? The number of records in the Customer table minus the number of records that match the "UNASSIGNED" CSR, divided by one less than the number of records in the CSR table. Double eek. Conventional values are useful when you're producing reports. For example, you might want to substitute "Unknown" for Null values and "Not Applicable" for empty values. But that is a very different proposition from storing these conventional values in the database, where they interfere with data manipulation, as we've seen. Evil the Null might be, and ugly it most assuredly is, but it's the best tool we have for handling unknown and nonexistent values. Just think the issue through, find alternatives where that's reasonable, and allow for the difficulties of using Nulls where alternatives are not reasonable. One of the problems with Nulls is that, with the exception of domains declared to be string or text data types, they might be forced to do double duty. A field declared as a DateTime data type can accept only dates or Nulls. If the corresponding attribute is defined as allowing both unknown and nonexistent values, and both are represented by Null, there is no way to determine whether a Null in any specific record represents "unknown" or "nonexistent." This problem doesn't arise for string or text data types, since you can use an empty, zero-length string for the empty value, leaving Null to represent the unknown value. In practice, this problem doesn't occur as often as one might expect. Few non-text domains permit the nonexistent value, so in these domains a Null can always be interpreted as meaning unknown. For those domains that do accept a nonexistent value, a sensible alternative can often be chosen to represent it. Note that I'm recommending an actual value here, not a conventional one. For example, even though a Product relation has a Weight attribute, a Service Call, which obviously doesn't have a weight, can use the value zero. (Zero is a good choice to represent empty for many, but not all, numeric fields.) The second and far more serious problem with Nulls is that they complicate data manipulation. Logical comparisons become more complex, and posing certain kinds of questions can get a bit hairy. We'll look at this in detail in Chapter 5. I don't take Nulls lightly, and when there's a reasonable alternative, I'd recommend taking it. But as I've said elsewhere, don't dent the data model just to make life easier for the programmers. Think it through, but if the system requires Nulls, use them. Violation ResponsesWhen defining the database schema, you must not only determine how a given integrity constraint might most effectively be implemented, you must also decide what action the database engine should take if the constraint is violated. In most cases, of course, the database will simply reject the offending command, returning an error in whatever using whatever method is appropriate. Sometimes, however, the database can take corrective action that makes the requested change acceptable. Examples of this include the provision of a default value for attributes that do not allow empty values, or performing a cascading update or cascading delete to preserve referential integrity. We'll discuss violation responses in detail in Part IV. Declarative and Procedural IntegrityRelational database engines provide integrity support in two ways: declarative and procedural. Declarative integrity support is explicitly defined ("declared") as part of the database schema. Both the Jet database engine and SQL Server provide some declarative integrity support. Declarative integrity is the preferred method for implementing data integrity. You should use it wherever possible. SQL Server implements procedural integrity support by way of trigger procedures that are executed ("triggered") when a record is inserted, updated, or deleted. The Jet database engine does not support procedural integrity. When an integrity constraint cannot be implemented using declarative integrity, and the system is using the Jet engine, the constraint must be implemented in the front end. Domain IntegritySQL Server provides a limited kind of support for domains in the form of user-defined data types (UDDTs). Fields defined against a UDDT will inherit the data type declaration as well as domain constraints defined for the UDDT. Equally importantly, SQL Server will prohibit comparison between fields declared against different UDDTs, even when the UDDTs in question are based on the same system data type. For example, even though the CityName domain and the CompanyName domain are both defined as being char(30), SQL Server would reject the expression CityName = CompanyName. This can be explicitly overridden by using the convert function CityName = CONVERT(char(30), CompanyName), but the restriction forces you to think about it before comparing fields declared against different domains. This is a good thing, since these comparisons don't often make sense. UDDTs can be created either through the SQL Server Enterprise Manager or through the system stored procedure sp_addtype. Either way, UDDTs are initially declared with a name or a data type and by whether they are allowed to accept Nulls. Once a UDDT has been created, default values and validation rules can be defined for it. A SQL Server rule is a logical expression that defines the acceptable values for the UDDT (or for a field, if it is bound to a field rather than a UDDT). A default is simply thata default value to be inserted by the system into a field that would otherwise be Null because the user did not provide a value. Binding a rule or default to a UDDT is a two-step procedure. First you must create the rule or default, and then bind it to the UDDT (or field). The "it's not a bug, it's a feature" justification for this two-step procedure is that, once defined, the rule or default can be reused elsewhere. I find this tedious since in my experience these objects are reused only rarely. When defining a table, SQL Server provides the ability to declare defaults and CHECK constraints directly, as part of the table definition. (CHECK constraints are similar to rules, but more powerful.) Unfortunately this one-step declaration is not available when declaring UDDTs, which must use the older "create-and-then-bind" methodology. It is heartily to be wished that Microsoft add support for default and CHECK constraint declarations to UDDTs in a future release of SQL Server. A second way of implementing a kind of deferred domain integrity is to use lookup tables. This technique can be used in both Microsoft Jet and SQL Server. As an example, take the domain of USStates. Now, theoretically, you can create a rule listing all 50 states. In reality, this would be a painful process, particularly with the Jet database engine, where the rule would have to be retyped for every field declared against the domain. It's much, much easier to create a USStates lookup table and use referential integrity to ensure that the field values are restricted to the values stored in the table. Entity IntegrityIn the database schema, entity constraints can govern individual fields, multiple fields, or the table as a whole. Both the Jet database engine and SQL Server provide mechanisms for ensuring integrity at the entity level. Not surprisingly, SQL Server provides a richer set of capabilities, but the gap is not as great as one might expect. At the level of individual fields, the most fundamental integrity constraint is of course the data type. Both the Jet database engine and SQL Server provide a rich set of data types, as shown in Table 4-1.
As we saw in the previous section, SQL Server also allows fields to be declared against UDDTs. A UDDT field inherits the nullability, defaults, and rules that were defined for the type, but these can be overridden by the field definition. Logically, the field definition should only narrow UDDT constraints, but in fact SQL Server simply replaces the UDDT definition in the field description. It is thus possible to allow a field to accept Nulls even though the UDDT against which it is declared does not. (Even after all these years, I've never been able to determine whether SQL Server lacks rigor, or I'm just stuffy.) Both SQL Server and the Jet database engine provide control over whether a field is allowed to contain Nulls. When defining a column in SQL Server, one simply specifies NULL or NOT NULL or clicks the appropriate box in the Enterprise Manager. The Jet database engine equivalent of the Null flag is the Required field. In addition, the Jet database engine provides the AllowZeroLength flag, which determines whether empty strings ("") are permitted in Text and Memo fields. This constraint can be implemented in SQL Server using a CHECK constraint. Simply setting the appropriate property when defining the field sets default values in the Jet database engine. In SQL Server, you can set the Default property when creating the field, or you can bind a system default to the field as described for UDDTs. Declaring the default as part of the table definition is certainly cleaner and the option I would generally recommend if you do not (or cannot) declare the default at the domain level. Finally, both the Jet database engine and SQL Server allow specific entity constraints to be established. The Jet database engine provides two field properties: ValidationRule and ValidationText. SQL Server allows CHECK constraints to be declared when the field is defined or system rules to be bound to the field afterwards. CHECK constraints are the preferred method. At first glance, the Jet database engine validation rules and SQL Server CHECK constraints appear to be identical, but there are some important differences. Both take the form of a logical expression, and neither is allowed to reference other tables or columns. However, a Jet database engine validation rule must evaluate to True for the value to be accepted. A SQL Server CHECK constraint must not evaluate to False. This is a subtle point: both True and Null are acceptable values for a CHECK constraint; only a True value is acceptable for a validation rule. In addition, multiple CHECK constraints can be defined for one SQL Server field. In fact, one rule and any number of CHECK constraints can be applied to a single SQL Server field, whereas a Jet database engine field has a single ValidationRule property. The Jet database engine Validation-Text property setting, by the way, is returned to the front end as an error message. Microsoft Access displays the text in a message box; it is available to Visual Basic and other programming environments as the text of the Errors collection. Entity constraints that reference multiple fields in a single table are implemented as table validation rules in the Jet database engine and table CHECK constraints in SQL Server. Other than being declared in a different place, these table-level constraints function in precisely the same way as their corresponding field-level constraints. The most fundamental entity integrity constraint is the requirement that each instance of an entity be uniquely identifiable. Remember that this is the entity integrity rule; all others are more properly referred to as entity-level integrity constraints. The Jet database engine and SQL Server support uniqueness constraints in pretty much the same way, but the support looks quite different. Both engines implement the constraints using indices, but SQL Server hides this from the user. Whether one explicitly creates an index (Jet database engine) or declares a constraint (SQL Server) is largely a mechanical detail. Both the Jet database engine and SQL Server support the definition of sets of fields as being unique. Both also support the definition of a set of one or more fields as being the primary key, which implies uniqueness. There can be only one primary key for a table, although it can consist of multiple fields. There can be any number of unique constraints. The other important difference between unique constraints and primary keys is that unique indices can contain Nulls; primary keys cannot. There are some differences in the way the two engines treat Nulls in unique indices. The Jet database engine provides a property, IgnoreNulls, which prevents records containing Null values in the indexed columns from being added to the index. The records are added to the table but not included in the index. This capability is not available in SQL Server. In addition, SQL Server allows only a single record containing NULL in the index. This is logically incorrect. It treats records with NULL values as being equal, which of course they are not. A Null is not equal to anything, including another Null. Interestingly, neither the Jet database engine nor SQL Server requires that a primary key be defined for a table or even that it have a unique constraint. In other words, it is possible to create tables that are not relations, since tuples in relations must be uniquely identifiable but records in tables need not be. Why one would want to do this escapes me, but I suppose it's nice to know that the possibility is there if you should ever need it. SQL Server also provides a procedural mechanism for providing entity-level integrity that the Jet database engine does not provide. Triggers are little bits of code that are automatically executed when a specific event occurs. In the current version of SQL Server, the code must be Transaction SQL. The next version, codenamed "Yukon," will allow triggers to be written in any .NET language. Multiple triggers can be defined for each INSERT, UPDATE, or DELETE event, as well as the new INSTEAD OF event, and a given trigger can be defined for multiple events. Referential IntegrityWhile their support for entity integrity is substantively the same, the Jet database engine and SQL Server implement different paradigms for supporting referential integrity. SQL Server allows foreign key constraints to be declared as part of the table definition. A foreign key constraint establishes a reference to a candidate key in another table, the primary table. Once the reference is established, SQL Server prevents the creation of orphan records by rejecting any insertions that do not have a matching record in the primary table. Nulls are not prohibited in foreign key columns, although they can be prevented if the column participates in the primary key of the table, which is usually the case. SQL Server also prohibits the deletion of records in the primary table if they have any matching foreign key values. The Jet database engine supports referential integrity through a Relation object within the database. Microsoft's terminology is unfortunate herethe Jet database engine Relation object is a physical representation of the relationship between two entities. Don't confuse the Relation object with the logical relations that are defined in the data model. The simplest way of creating Relation objects is in the Access user interface (using the Relationships command on the Tools menu), but they can also be created in code. The Data Access Object (DAO) Relation object's Table and ForeignTable properties define the two tables participating in the relationship, while the Fields collection defines the linked fields in each table. The manner in which the Jet database engine will maintain referential integrity for the relation is governed by the Attributes property of the relation, as shown in Table 4-2.
Note the attribute flags dbRelationUpdateCascade and dbRelation-DeleteCascade. If the update flag is set and a referenced field is changed, the Jet database engine will automatically update the matching fields in the foreign table. Similarly, the delete flag will cause the matching records to be automatically deleted from the foreign table. SQL Server 2000 introduced comparable automatic flags, and the more complex cascading behavior can easily be implemented using triggers. Other Kinds of IntegrityIn the data model, we define three additional kinds of integrity: database, transition, and transaction. Some transition constraints are simple enough to be declared as validation rules. Most, however, including all database and transaction constraints, must be implemented procedurally. For SQL Server databases, this means using triggers. Since the Jet database engine does not support triggers, these constraints must be implemented in the front end. |