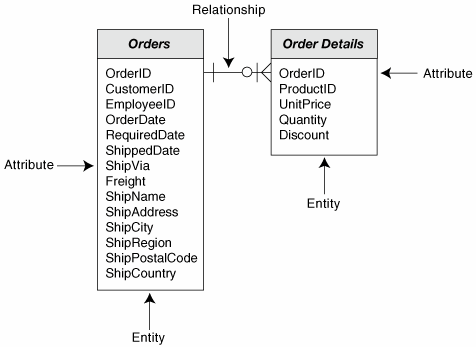
The Dimensional Database ModelRelational databases based on the entity-relationship model often support the operational aspects of an organization, such as order processing or payroll management. They answer questions such as "how many screwdrivers did Mary Smith order on the 5th of June?" or "How much did we pay Jimmy Jones in January 2003?" The "grain" of the data in these databases is a single transactiona single order line item (the number of screwdrivers), or a pay stub (Jimmy Jones' pay in January)and the systems are thus often called On-Line Transaction Processing (OLTP) systems. This label can be useful, but it's also inaccurate, since schemas based on the entity-relationship model are also the best structure for storing static datathe current holdings of a library (the "card catalog") or a mailing list, for example. Database schemas based on the dimensional model, on the other hand, are almost always used for analyzing the state of an organization. They answer questions such as "What product groups are most profitable?" or "How do sales vary with the season?" For this reason, they are often called On-Line Analytical Processing (OLAP) systems. Again, OLAP is a useful but slightly inaccurate term. While OLAP systems are rarely used for anything other than analysis, OLTP systems can be, and often are, used for analysis as well. Thus the two types of system are not mutually-exclusive. Further, in the same way that it's important to keep the logical and physical design of a database distinct, it seems to me more than a little muddled to use functional terminology to make structural distinctions. For these reasons, I'm going to use the terms "normalized" and "dimensional" to distinguish between schemas developed using the two sets of rules. But be aware that these are my terms. In the literature, the two types of database schemas are rarely discussed together, so the distinction simply isn't made. What I call normalized databases are simply referred to as "databases," while dimensional databases are called either "dimensional databases" or "OLAP databases." For the purposes of this book, however, we do need to distinguish between the two types. So I'll use the term normalized database to refer to the traditional relational structures we examined in Part I, defined in terms of entities, attributes and relationships, as shown in Figure 6-1. Figure 6-1. Two Tables from a Normalized Database Schema
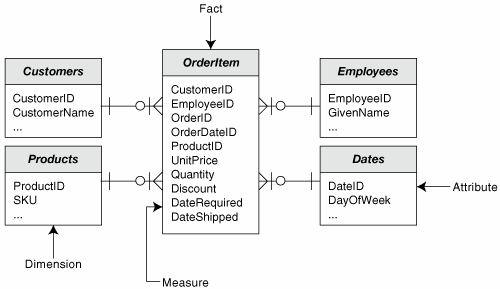
Note that the two entities shown in Figure 6-1 are not a complete schema; the Customer and Employee and Product entities are missing. This makes the diagram easier to understand than the complete database is likely to be. (I once worked with an analyst who created her initial schemas using little yellow sticky notes and string. One of her schemas took up the better part of a 12-foot-long hallway. Try teaching that to the Vice President of Marketing!) Figure 6-2 shows a dimensional database equivalent to Figure 6-1 defined in terms of facts tables, facts and dimensions. As you can see, there is some overlap between the two models. We are, after all, still dealing with relational databases. The schema still consists of logical relations (although they're universally called "tables" in dimensional design), but the relations are divided into two quite distinct types: a single fact table, and multiple dimension tables. Figure 6-2. A Dimensional Schema
Notice that, unlike the normalized version, Figure 6-2 contains all the relations in the schema. For readability, the dimension tables don't show all of their attributes, but all of the dimensions are shown. This structure is far simpler for an end user to understand than the equivalent normalized schema. The single fact table models the data being used for reporting. It contains two distinct types of attributes: key attributes, all of which are foreign keys relating the fact table to the dimension tables, and facts, the attributes that contain the actual data being measured. Notice that the fact table is placed in the center of the diagram with the dimension tables arranged around it. This is the conventional arrangement of these schemas. Someone, somewhere, decided this arrangement looks like a star and so these are called star schemas. I confess that I do not see any great resemblance here, but perhaps I leave my poetry at home when I do database design (and perhaps I would be a better analyst if I didn't). In any event, these are called star schemas, whether or not the diagram is arranged in this fashion.
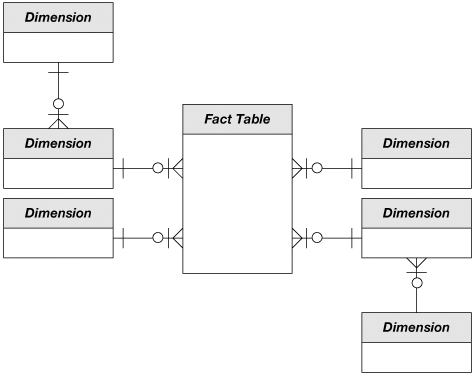
The technical definition of a star schema is that it consists of a single fact table and multiple dimension tables, all of which are related directly to the fact table, and not, as a general rule, to other dimensions. However, there are some relatively rare situations in which it's appropriate to split the dimensions into multiple relations as shown in Figure 6-3. Figure 6-3. A Snowflake Schema
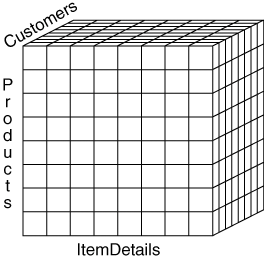
This structure is known as a snowflake schema. The snowflake schema in effect normalizes the dimensions. As a general rule, normalization simply doesn't apply to dimensional databases, but there are a few exceptions that we'll discuss in Chapter 8. Another way of conceiving the data stored in a dimensional database is as a cube, as shown in Figure 6-4. Indeed, many people refer to the dimensional database as "the cube." In fact, this is the term used by Microsoft in its documentation and products, and the one I will use to refer to the physical data store. Figure 6-4. A Dimensional Cube
Technically, it's an "N-Cube" because it can have more than three dimensions, but the "N" is typically dropped. (You probably recall that the same is true of n-tuples, which are usually referred to simply as tuples.) Using the term "cube" doesn't imply a different database schemathe schema is still defined by the rules we'll examine in the next few chaptersit merely reflects a different way of thinking about the data. |