|
|
< Free Open Study > |
|
2.2 Messages and MethodsObjects should be treated as machines that will carry out operations in their public interface for anyone who makes an appropriate request. Due to the independence of an object toward its user, and the syntax of some of the early languages that implemented object-oriented concepts, the term "sending a message" is used to describe the execution of an object's behavior. When an object is sent a message, it must first decide it if understands the message. Assuming it understands the message, the object maps the message to a function call passing itself as an implied first argument. Deciding the understandability of a message is done at runtime in the case of an interpreted language and at compile time in the case of a compiled language. The name (or prototype) of an object behavior is called a message. Many object-oriented languages support the notion of overloaded functions or operators. This construct states that two functions in the system can have the same name as long as their argument types differ (intraclass overloading) or they are attached to different classes (interclass overloading). The alarm clock class might have two set_time messages, one that takes two integers and one that takes a character string. This would be an example of intraclass overloading. void AlarmClock::set_time(int hours, int minutes); void AlarmClock::set_time(String time); Alternately, alarm clocks and watches might both have a set_time message that takes two integers. This would be an example of interclass overloading. void AlarmClock::set_time(int hours, int minutes); void Watch::set_time(int hours, int minutes); It is important to note that a message consists of the function name, argument types, the return type, and the class to which it is attached. This is the primary information that a user of a class needs to know. In some languages and/or systems, additional information may be presented, such as the types of exceptions thrown from the message as well as any relevant concurrency information (e.g., whether the message is synchronous or asynchronous). The implementors of a class are required to know how a message is implemented. The implementation of a message梩he code that implements a message梚s called a method. Once the thread of control is inside a method, all reference to the data members of the object to which the message was sent is through the implied first argument. This implied first argument of the method is called the self object in many languages (C++ prefers to call it the "this" object). Finally, the list of messages to which an object can respond is called its protocol. There are two special messages to which classes/objects can respond. The first is an operation that users of a class call in order to construct objects of the class. This is called a constructor of the class. A class may have many constructors, each taking a different set of initialization parameters. For example, we may be able to construct alarm clocks by giving the class five integer arguments specifying the hours, minutes, alarm hours, alarm minutes, and alarm status; or we may want to pass two strings and an integer argument. Each string would be of the form "hour:minutes," signifying the time and alarm time, respectively, while the integer would specify the alarm status. Some classes have a dozen or more constructor functions. The second special message to which classes/objects can respond is an operation that cleans up an object prior to its removal from the system. This operation is called a destructor of the class. Most object-oriented languages have only one destructor per class since any decisions that need to be made at runtime can be stored as part of the object's state. There is no need to pass additional arguments into the method. We will refer to both constructors and destructors during various topics within this text. Consider them the initialization and clean-up mechanisms of the object-oriented paradigm. Heuristic 2.2
The rationale behind this heuristic is one of reusability. An alarm clock might be used by a person in a bedroom (see Figure 2.4). The person is obviously dependent on the public interface of the alarm clock. However, the alarm clock should not be dependent on the person. If the alarm clock were dependent on its user, namely the person, then it could not be used to build a timelock safe without attaching a person to the safe. These dependencies are undesirable, since we want to be able to lift the alarm clock out of its domain and deposit it into another domain with no user dependencies. It is best to view the alarm clock as a little machine having no knowledge of its users. It simply performs the behaviors defined in its public interface for whoever sends it a message. Figure 2.4. The use of alarm clocks.
Heuristic 2.3
The exact opposite of this heuristic was published some years back. The claim was that if a class implementor can think of some operation for a class, then someone will want to use it in the future. Why not implement it? If you follow this heuristic, then you will love my LinkedList class梚t has 4,000 operations in its public interface. The problem is that you want to execute a merging of two LinkedList objects. You assume the LinkedList class must have this operation so you scan its alphabetized list of messages. You cannot find an operation called merge, union, combine, or any other known synonym. Unfortunately, it is an overloaded plus operator (operator+ in C++). The problem with large public interfaces is that you can never find what you are looking for. This is a serious problem with reusability in general. By keeping the interface minimal, we make the system easier to understand and the components easier to reuse. Heuristic 2.4
If the classes that a developer designs and implements are to be reused by other developers in other applications, it is often useful to provide a common minimal public interface. This minimal public interface consists of functionality that can be reasonably expected from each and every class. The interface serves as a foundation for learning about the behaviors of classes in a reusable software base. We will discuss specific items for this minimal public interface in more detail in Chapter 9. Heuristic 2.5
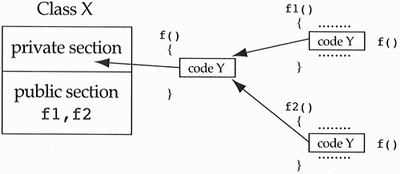
This heuristic is designed to reduce the complexity of the class interface for its users. The basic idea is that users of a class do not want to see members of the public interface which they are not supposed to use. These items belong in the private section of the class. A common-code private function is created when two methods of a class have a sequence of code in common. It is usually convenient to encapsulate this common code in its own method. This method is not a new operation; it is simply an implementation detail of two operations of the class. Since it is an implementation detail, it should be placed in the private section of the class, not the public section (see Figure 2.5). Figure 2.5. Example of a common-code private function.
In order to get a more real-world feel for common-code private functions, consider the class X to be a linked list, f1 and f2 to be the functions insert and remove, and the common-code private function f to be the operation for finding the location in the linked list for an insertion or removal. Heuristic 2.6
This heuristic is related to the previous one in that any common-code functions placed in the public interface are only cluttering that interface since users of the class do not want to call such functions. They are not new operations of the class. Some languages, such as C++, allow for the erroneous inclusion of other types of functions in the public interface of a class. For example, it is legal in C++ to place the constructor of an abstract class in the public interface of that class even though the user of the class will receive a syntax error if he or she attempts to use such a constructor. The more general heuristic (2.6) is included to preclude these problems. |
|
|
< Free Open Study > |
|