|
|
< Free Open Study > |
|
4.6 The Containment RelationshipThe meal class that we created in Figure 4.8 to reduce the number of collaborations between the restaurant patron and the pieces of the meal is a good example of the containment relationship. Containment occurs whenever a class has as one of its attributes an object of another class. In our example, we claim that a meal contains a melon. Does this imply that all melons are contained inside meals? Of course not?there are melons contained in grocery stores, fields, and garbage cans. This makes containment an object-based relationship, since not all objects of the classes have to obey the relationship. Heuristic 4.5
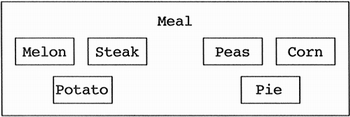
The rationale behind this heuristic is that contained objects that are not sent messages by the containing class are useless information (since data hiding precludes their use by others), or else there is some get method to return the contained object for use by others. The latter is a violation of keeping related data and behavior in one place, except in the case of container classes. Container classes are generic classes used as a temporary holding space for other objects. Their interesting behavior is the insertion and removal of other objects. Unless we are dealing with a container class, the contained object needs to be removed and placed in its appropriate abstraction. That is, the data decomposition model is flawed at this point in the design. Consider the design of a meal class shown in Figure 4.10. It is an example of a broad and shallow containment hierarchy, namely, lots of data members in the class but little depth. Figure 4.10. A broad and shallow meal class.
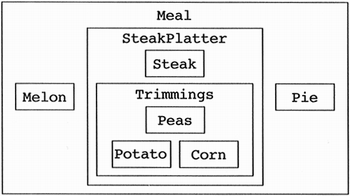
An alternative design for the meal class is shown in Figure 4.11. It is an example of a narrow and deep containment hierarchy. Figure 4.11. A narrow and deep meal class.
The key question is, "Which design is better?" There are always two groups to consider when asking such a question: the users of a class and the implementors of a class. For the users of the meal class, which design is better? If you answer design #1, you are wrong, and if you answer design #2, you are wrong. Why? As a user of the meal class, you should not care which design is used. If you have a preference, it means that you are dependent on the implementation of the meal class, a clear violation of data hiding. It has been my experience that this question will solicit many votes for design #1. This shows the typical action-oriented designer's obsession with knowing implementation details when designing a high-level design, a cause of many extensibility problems. In the object-oriented world, if a user of a meal object wants to know the cost of the meal, he or she simply sends the cost message to his or her object. Any other knowledge of the containment hierarchy will cause maintenance problems. Now ask the same question to the implementors of the class. Again, the question solicits many votes for design #1. Why? In most procedural languages, the heuristic has been to favor broad and shallow data structures as opposed to deeply nested structures. Developers were concerned with memorizing the path names to get access to a particular piece of data. They did not want to write statements like "obj1.first.x.p.q.mydata = 10;". Instead, they wanted to write statements like "obj1.mydata = 10;". This inconvenience is not a problem in the object-oriented world. Users of data structures never access data directly. Thanks to data hiding, we can nest structures as deeply as we wish without increasing the complexity for our users. Given that we have removed the perceived advantage of shallow over deep structures, why are deep structures better? Consider the following heuristics. Heuristic 4.6
If this is not true for a given class, then it is probable that the designer has captured two or more abstractions in one class. A class should capture only one meaningful abstraction within a domain. In the grossest violation, half of a class's methods will use half the data members while the other half of the methods are using the other half of the data members. The class should be split along these lines due to it having too much noncommunicating behavior. For an example of this construct, see the dictionary example in Chapter 2 (Section 2.3). Heuristic 4.7
The rationale behind this heuristic is that most of the methods defined on a class should be using most of the data members most of the time. Assuming this is true, implementors of a method will need to think about all of the data members while writing the method. If the developer cannot keep all of the data in his or her short-term memory, then items will be omitted and bugs will creep into the code. The standard number of seven plus or minus two is widely accepted in the world of psychology as the number of items most people can keep in their short-term memory. We choose six to take into consideration people with poor short-term memories and the fact that most methods take an argument or two, which must be considered in addition to the data members. In short, this heuristic is a complexity metric on a class. (Emphasizing a point: If few methods use most of the data members most of the time, then we have a noncommunicating class that may need to be split.) [8] How does one reduce the number of data members within a class? When a class contains more than six items, it is time to start grouping logical collections of the data members within a new containing class. In the case of the meal, we determine that the steak platter class can contain the steak, potato, peas, and corn. Likewise, the trimmings class can further reduce the complexity by encapsulating the potato, peas, and corn. Consider the implementor of the cost function for the first meal. He or she is thinking about six items, while the implementor of the second meal considers only three. Imagine the result if our meal gets more interesting; for example, we may decide that the meal contains an appetizer (melon or shrimp cocktail), an entree (steak platter or shrimp platter), and a dessert (pie, cake, or jello). The implementor of the cost method for the first meal is now thinking, "If the appetizer is a melon, add 75 cents to the sum; but if it is a shrimp cocktail, then count the number of shrimp in the shrimp cocktail, multiply by 65 cents, then check if there is cocktail sauce because we charge 15 cents extra for sauce …." Our lazy object-oriented implementor simply asks the appetizer, entree, and dessert for their cost and sums them up. It is true that someone has to decide which appetizer is in the meal, and if that appetizer happens to be a shrimp cocktail, then they need to perform some functionality to compute its cost. But at least in this stage of implementation, we can put off the work of thinking about that portion of the problem. It has been my experience that lazy programmers have the easiest time producing narrow and deep containment hierarchies. They simply pretend that any work that can be spun off into another class is not their responsibility. Heuristic 4.8
This heuristic goes together with distributing system intelligence horizontally across the top-level classes. Both are important heuristics, although horizontal distribution is more important than vertical distribution. An improper horizontal distribution affects the entire application, while an improper vertical distribution affects only the implementation of the class in question. One perceived problem with the narrow and deep hierarchies is that of efficiency. Computing the cost of the broad and shallow meal amounts to the overhead of seven function calls, while the narrow and deep design has a total of nine function calls. The impact of function call overhead is greatly exaggerated. If the language of implementation is an interpreted language (e.g., Smalltalk, CLOS), then this level of efficiency has been thrown out the window. If you are dealing with a compiled language, in particular C++, by definition you are worried about efficiency. In languages such as these, mechanisms known as inline functions are usually available to eliminate the function call overhead of tiny (one line) functions. In short, either you do not care about the overhead, or you do care and your language provides an escape. A side benefit of narrow and deep hierarchies is that you get more hooks for software reuse. Let us assume we want to build a turkey dinner for some other domain. It is natural for us to look to the meal for reuse. We realize the entire meal class cannot be reused, but maybe we can find some interesting items inside its black box. We open the black box of the first design and lots of little pieces fall out. We pick up the potato, peas, and corn, realizing that we will need them in the turkey dinner as well. Now we try to strip out the method code that deals exclusively with these three data members. We quickly find that it is a frustrating job trying to break up the abstraction, so we throw the whole mess away and build our abstraction from scratch. Using the second design, we open the black box and find three other black boxes. We discard the melon and pie as useless in our new domain, but we find the steak platter interesting. We open its black box and find another black box called trimmings, which captures the abstraction we need for our turkey dinner. Now we can grab the trimmings structure with its methods and look no further into the design. The ability to reuse a particular section of a containment hierarchy can be very beneficial toward the development of new designs. |
|
|
< Free Open Study > |
|