|
|
< Free Open Study > |
|
9.2 The Construction of Object-Oriented WrappersThe notion of a software wrapper is not new, but like so many other concepts in the object-oriented paradigm, its name is new. In the past we referred to the notion of software layering. Consider the seven famous layers in a network architecture (e.g., the connection layer, the transport layer, the physical layer). They serve as a mechanism for separating levels of concern in networks, with each layer having control of a particular level of detail. If this architecture were defined today, I am sure it would be called the seven wrappers of a network architecture. Wrappers are simply layers of software written in an object-oriented fashion. There are many examples of the need for such a construct. The first occasion when I become acquainted with the need for wrappers was at a software developers conference back in the mid-1980s. The conference featured a panel on the reusability of software. Each panelist was a representative of a particular programming language (C++, SmallTalk, Lisp/Flavors, and Eiffel) discussing patterns of reuse among the users of their language. After the panelists had delivered their position papers and a number of language-based questions had been answered, a gentleman approached the microphone and made the following statement (which I found to be one of the more enlightening):
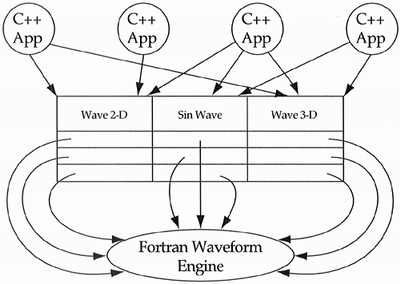
It was the first time I had considered the problem. Based on the panel's response, it was the first time for a lot of people. This brought up the subject of reusing nonobject-oriented code in an object-oriented application via a wrapper. The idea was to create a collection of classes that modeled the Fortran code in an object-oriented manner. The methods of these classes are function calls into the Fortran library. Of course, the new problem was to find this collection of classes. One technique of finding classes from a collection of existing functions is to examine the arguments passed into each function. Each record type argument is a good candidate for a class, since the corresponding function will end up a method with that record type passed as an implied first argument. Of course, Fortran IV does not even have the notion of record, so it was necessary to look for patterns of arguments being passed to a collection of functions within the library. For example, three integers followed by six real numbers followed by a character string might imply the numeric description of a waveform. Once the classes are found, they can be easily implemented through calls to the Fortran library (see Figure 9.3). If, at a later date, the company decides to rewrite the Fortran waveform engine in C++, the applications will be completely isolated from the Fortran. Object-oriented applications get to talk to the same object-oriented waveform engine. They are users of the engine and could care less how that engine is implemented. Figure 9.3. A C++ wrapper for a Fortran engine.
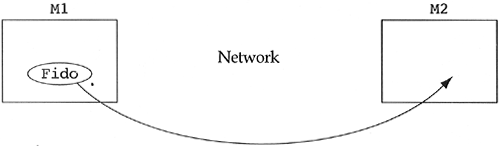
Another example of the need for a wrapper brings me back to my early days of corporate education. Back in 1985/1986, I gave design and C++ courses to four different companies involved with telecommunications networks. Companies involved with telecommunications were among the first to jump into object-oriented programming. This was due to the fact that there exist national standards for telecommunications devices. They are documented in publications with statements like, "If you want to build a T-1 network, then it must have the following abstract behavior, but you are free to implement it as you wish." The objects in the domain of telecommunications were obvious; however, the architecture of the systems that used them were not so obvious. All four companies ran into the same interesting problem. How do we tell an object called Fido of the class Dog to move from machine M1 to machine M2 over a network? (See Figure 9.4.) In addition, we expect to be moving many objects of different classes from machine to machine. Figure 9.4. Moving Fido from M1 to M2.
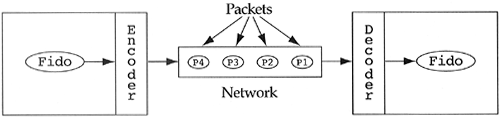
Discussing this task was trivial during logical design. We simply send Fido the Dog the move message along with the machine object to which it is to move itself, e.g., Fido.move(M2). Unfortunately, along comes physical design with the question, "What does a method like move look like?" This raises the interesting question of how we go about moving objects over networks. This network doesn't know about dogs, cats, tables, chairs, and T-1 objects. What do networks know about? At the lowest level they work with bits, then come bytes, and if we are lucky, packets of bytes. This brought up the need for an encoder, which turned a Dog (and any other object wishing to move from machine to machine) into a collection of packets, and a decoder, to decode the packets on the other machine (see Figure 9.5). Figure 9.5. A solution to moving Fido.
The problem with this solution is evident when we look at the internals of the decoder. It must check some field of the first packet to determine what object the packet stream is representing. Based on the value of this field, it will create the appropriate object. The companies involved with this design realized they were performing explicit case analysis on the type of an object, a violation of an important heuristic. They assumed their design was flawed and searched in vain for a better solution. Their design is not flawed in this example; the network is simply not object-oriented. Whenever an object-oriented application interfaces to a nonobject-oriented subsystem, explicit case analysis is often the result. In this example, an object-oriented application is using a nonobject-oriented network. This network along with an encoder and a decoder can be viewed as an object-oriented network to the objects in the problem domain. Some will argue that the explicit case analysis still exists since only our view (i.e., partitioning) of the system has changed. However, the same argument can be made for polymorphism. Someone must perform an analysis on the exact type of the object. If users of the system need to perform the analysis, it is considered explicit case analysis; if the system performs the analysis, then it is considered implicit case analysis. At the time in question, there existed no object-oriented networks. Each of these companies was left to build its own object-oriented wrapper (i.e., encoder/decoder), which was difficult to maintain due to its explicit case analysis. In addition, the case analysis is dependent on the data types allowed across the network. The eventual solution is to build generic object-oriented networks that require only a description of the data in order to pass that data across the network in an object-oriented fashion. An architecture for such a network has been proposed by the Object Management Group, and is known as CORBA (Common Object Request Broker Architecture) [13]. It addresses not only the problem of object-oriented networks but the need for objects to send remote messages to objects that live on other machines. Of course, we need not stop there. Why not let C++ objects send remote messages to SmallTalk objects which live on another machine? This creates truly seamless, distributed systems. Another example of the explicit case analysis problem with respect to object-oriented systems interfacing with nonobject-oriented subsystems can be found in our previously explored fruit basket example. Consider an application that allows users interactively to build a custom fruit basket object by first prompting them for the number of fruit desired, followed by a prompt for each of the fruit as to type and other fields. In a menu-driven system, the application will have to perform explicit case analysis on the type of the fruit. This explicit case analysis is necessary due to the user interface's not being object-oriented. In a graphical user interface environment, we could envision a different icon for each type of fruit. The user would simply click a mouse over the appropriate icon in order to build that type of fruit object. One can argue that case analysis is still required. The code within the graphical user interface will check if the mouse was clicked between certain x and y coordinates. However, this case analysis is implicit since the user of the system is not performing it. It is all a matter of perception; where do the "system" and "outside the system" begin and end? |
|
|
< Free Open Study > |
|