|
|
< Free Open Study > |
|
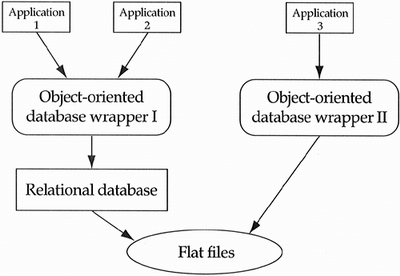
9.3 Persistence in an Object-Oriented SystemIn all of the preceding examples, we wanted to be sure that nonobject-oriented subsystems were placed in an object-oriented wrapper to ensure the consistent modeling of our object-oriented domain. One special type of wrapper is the database wrapper. Software developers quickly realized that relational databases were not sufficiently expressive to capture the detailed constructs of the object-oriented paradigm. While relational databases are able to capture data structures and their associations, they are inept at describing the bidirectional relationship between data and behavior, uses relationships, containment relationships, and inheritance. Many companies produced or acquired object-oriented database management systems with the goal that these subsystems would map more uniformly to the object-oriented problem model. These databases take a description of the logical design of the system and, from it, derive all the necessary information for mapping the logical design to flat files, with a possible intermediate mapping to a sophisticated database engine. An object-oriented database can be thought of as a wrapper for a relational database. The only task they eliminate from the object-oriented developer's job is the mapping of object-oriented constructs to something a relational database can understand. While this mapping is straightforward, it is an example of accidental complexity that should be eliminated. Much information is lost in the mapping to something less expressive, and there is always the chance of error when it is performed by a human. Many information-management companies (banks, insurance companies, mailing-list brokers, etc.) have invested millions of dollars in relational database software. Is it worth the money to move to an object-oriented database system? Most of these companies insist that it is not, and I tend to agree with them. Why spend large sums of money on database software that is not as well tested as some of the large relational databases that are available? It is often cheaper for a company to build its own object-oriented wrapper for its relational database, taking advantage of the in-house experience and software. Object-oriented databases are often used by developers building a system in which the database is an auxiliary subsystem not related to the main thrust of the system. For example, one company with which I worked was building a 3-D modeling tool. The tool would allow its users to save the 3-D model they designed. The obvious choice for designing this ability was to use an object-oriented database that could directly map the users' objects onto the flat files of the disk (see Figure 9.6). There is nothing wrong with an information-management application using an object-oriented database. It is just that these companies often have invested huge amounts of money in relational database software, and it should not go to waste. Most of this argument will disappear as soon as the large relational database vendors begin offering object-oriented extensions to their products. This is the general trend, with several third-party vendors already offering object-oriented database wrappers portable to a number of commercial relational databases. Figure 9.6. Architectures for object-oriented databases.
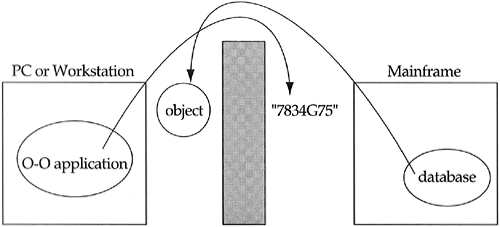
There is a trend within information-management companies to reduce the use of mainframe computers to large data-storage devices with high-bandwidth networks. These data-storage devices are then attached to a collection of PCs or Unix workstations. The workstations or PCs handle all of the user interface work, collecting and displaying information interactively. The mainframe acts as a high-speed retrieval and processing center. Eventually, most of these companies will question why they are spending 10 million dollars on a mainframe when they can get the same use from 1 million dollars of specialized file server hardware. Companies with this architectural mixture of PCs and mainframes are often faced with an object-oriented PC application talking to an database living on the mainframe. I dealt with an insurance company that was developing a worker's compensation claim system that had this particular problem. The first pass produced a logical design where many methods of the problem domain classes talked directly to the mainframe. I argued that the problem domain classes should not know anything about mainframes and their databases. All they know is that if they throw a claim number over a brick wall, a claim object will come back over the wall (see Figure 9.7). Where does it come from? Who cares! Maybe it is a brain-dead database on a mainframe, maybe it is from a local optical drive (because 15-gigabyte drives will be available for 8 dollars in 1998), or maybe a squirrel pulled it out of its nest. The point is that we do not want our object-oriented domain polluted with nonobject-oriented details. We build a wrapper (the brick wall) and then use that wrapper. Buy an object-oriented database, and you are paying someone else to write the wrapper. Figure 9.7. Hiding architectural details within wrappers.
The discussion of object-oriented database management systems brings up the whole subject of persistence. Persistence means that objects can live after the power has been turned off. It is important to note that object-oriented databases and/or object-oriented wrappers for relational databases are only the most common form of one type of persistence, called persistence in time. Traditionally, this has meant storage to a static medium, which for most people implies a database. There is an alternative method for saving objects to a static medium besides using a centralized database (object-oriented or not). Each object can have local knowledge concerning how it should be saved to a disk. This is common in systems with relatively few persistent classes. This book was not stored in an object-oriented database. Each object making up the book梚tems such as chapters, paragraphs, sentences, words, frames, floating headers, floating footers, graphical objects drawn within frames, etc.梬as told to store itself. Many people like to call this form of persistence local persistence (in time). If a class has an output operation that produces a description of the object in a form that can be parsed and used to build the equivalent object (via some input operation), then the class has local persistence. The important distinction is in whether the storage algorithm is decentralized across all of the persistent classes or centralized in some subsystem (e.g., a database) that knows how to store objects of a class based on a description of that class. There is a relatively new concept referred to as persistence in space. Persistence in space states that objects do not live after the power is turned off by saving themselves to static medium. Instead, they detect the power turning off and scurry across the network to a "safe" machine where they execute what they need or stay idle until their host machine's power returns, at which time they scurry back to the host. While this sounds a bit silly to some people, its uses go beyond the realm of writing distributed game programs. Many telecommunications companies are examining this form of persistence with the intent of applying its principles to routing algorithms. Routing algorithms are often very complex, unruly, and most interesting; they are centralized. The feeling is that decentralizing the routing algorithm will make them simpler. One can imagine a telephone packet finding a trunk line going down (or busy) and rerouting itself to a free trunk line. At this time, most of the work done in this field is in the research phase, with little practical application. It is expected to bring good results in decentralizing object-oriented applications across networked collections of machines. |
|
|
< Free Open Study > |
|