Now we get to the point where the database designers begin to work within their subject matter expertise and the application developers begin working within theirs. Remember that this is an iterative process; the diagrams will not stay stagnant but should be expected to evolve as time passes, as new requirements are uncovered, and as the schedules change, causing feature changes.
There are two basic philosophies on where to go next. One camp says to change the logical design to become the object/class diagram that will represent the application directly, then map that part of the model directly to the data model. We have chosen to follow the second philosophy, which we present in this chapter. The appropriate teams continue to maintain the logical analysis model and the other models already created, but during this time the teams also move in two new directions: The development team builds its application design model based on the logical analysis model, and the database de sign team builds its model based on the same logical analysis model. This ensures that everybody is using the same base artifacts and that the metadata captured throughout the process continues forward.
To understand how models change and mature over time based on the needs of the resulting application or database, it is important to maintain a mapping between the different diagrams. There are multiple ways to map models. In our scenario, we will map both the application and database design models to the logical analysis model, and we'll also map the application design model directly to the data model. This will give us the ability to understand some important information: how the models change based on how the subject matter experts see changes needed for their areas, how the iterations made to the requirements affect the logical design model, and how to map the object model to the data models to help build data access in later iterations.
Specifically, it is not really the model you are mapping but the elements within the models. You will be mapping classes to tables, attributes to columns, types to datatypes, and associations to relationships, which will help the teams understand how the application will interact with the database. Not all elements in each model will be mapped. Only classes that are persistent will map to the database, and there may be derived attributes within those persistent classes that don't map to columns. For example, often there are attributes, such as Total_Sales, that are sums of multiple columns in the database but are never stored anywhere in the database. Rather than storing the attribute, it is just a calculation in the application.
There are four basic ways to map classes to tables: one-to-one, one-to-many, many-to-one, and many-to-many. You may map them differently for various reasons, including performance, security, ease of querying, database administrator preference, corporate standards, database-specific needs, or other reasons that you may have experienced.
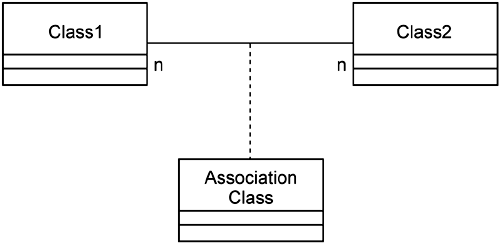
There are also some mappings that occur based on general relational database methodologies: many-to-many associations, subtypes, supertypes, and association classes. Many-to-many associations must be broken into one-to-many relationships by creating an association table. It is good practice to have additional columns in an association table over and above the foreign keys based on the relationships with the parent tables. If you don't have a need for additional columns, generally you do not need the many-to-many and can just create a one-to-many relationship or an additional table that is not really an association table. If an association table exists in the data model and does contain columns in addition to the foreign key, there should be a related association class in the logical analysis model. One advantage to using the UML over traditional entity-relationship (ER) notations for the logical model is the support for an association class while still showing the many-to-many association (see Figure 6-1). Traditionally, in ER notations, you would either have just the association table, without the many-to-many, or not show the association table at all until you get to the physical database design model.
When mapping subtype classes to tables, you have three basic choices:
One table per class
One table per concrete class
One table per hierarchy
One table per class is quite simple. Each class is mapped directly to a corresponding table. One table per concrete class is also known as 搑olling down?the supertype table into its subtypes. You take the attributes from the superclass and make them columns in tables that map to the subtype classes. One table per hierarchy is also known as 搑olling up?the subtypes to the supertype. When rolling up the subtypes, you take the attributes in the subtype classes and map them to columns in a single table that maps to both the supertype and subtypes. Most of the time when rolling up tables, a new column or multiple new columns are created in the table to describe the original subtype tables. For example, there may be a set of classes with Employee as the parent and subclasses of PartTime and FullTime (see Figure 6-2). In the data model you may roll the tables all into the one Employee table, but there will be a new column created that doesn't really map to any attributes in the classes梕mp_type. There may be a check constraint on emp_type of two valid values, part-time and full-time. This will allow the application to define the type of Employee without having to waste time querying three tables to find the Employee information. The application can just query one table and include the emp_type column.

There are many ways to map attributes to columns. They don't affect just the column mapping; they also may affect the class-to-table mapping. You may have attributes that don't exist in the database or columns that are never really shown or even cared about in the application, but they are there for database-specific needs. At times you will have an attribute, or possibly even a class, that maps to multiple columns in a database. For example, an Address class may map into Address1, Address2, City, State, Country, PostalCode, and so on.
When mapping the attributes to columns, database performance may be taken into account, but more often the needs of the data drive the process. You may even involve database views in this scenario so that you can map attributes as part of a class to a table or just some columns. This is done mainly for easy access to the columns that are frequently queried or for security reasons. In most databases, you cannot assign security to an individual column but only to the entire table. Therefore, views become very important to secure the data. Employee information such as salary is not something that is going to be given to everyone who needs to access employee information. Thus there may be a view for specific users which has only the specific employee information needed. That way these users cannot access the salary information.
Mapping attributes to columns does come in partly under the class-to-table mapping, and both must be considered in either case. You cannot change columns without affecting tables, and you cannot change tables without affecting columns. You may have a class that has methods for looking up address information based on the input of a postal code. The database doesn't care about the lookup algorithm, just that it needs all the address information. The application, on the other hand, may have this setup in two classes, one for the address and one for postal code lookup (Figure 6-3).

An application may contain a calculation for computing total sales, but this never exists in the database. The database is concerned with sales specific to a product or region, and the application calculates any other combinations needed for data retrieval. Attributes that base their value on calculations of data retrieved from the database are called derived attributes and do not persist within the database.
When mapping attributes to columns, it is important not just to map the column name(s) but also to understand how analysis datatypes will map to the datatypes specific to your database choice. Analysis datatypes are meant to be generic, or logical, so that you do not need any expertise in specific software (for example, Oracle, IBM DB2, Microsoft SQL Server, and so on) but just the subject knowledge of types on your attributes. These may include such generic types as String, Date, Currency, and Integer, among others. When involved in analysis, it isn't as important to always understand the lengths for precision needed on a datatype as to begin the definition of the attribute.
When mapping these attributes to the specific database columns, you will then need to expand the columns to include these elements as well as possibly check constraints to further define the columns. For example, you may have a column, Country, for which you want to create a valid value check constraint that lists all countries that can be entered within that column. This is also when you may need to make an architectural call about where the business rules really get enforced. You can enforce them in the application as a method or group of methods, in the database as check constraints, or in a business layer so that you can change the rule without changing either the application or the database.