The following UML, object-oriented, and other concepts are cited in this chapter. For a more complete discussion and more rigorous definitions of UML concepts, refer to Booch et al. [1999]. In this chapter we also cover many concepts that are not discussed in UML books and specifications that currently exist; these are part of the information in the UML Profile for Database Design. A profile is an extension to the UML that keeps the UML metamodel intact. The Profile for Database Design adds stereotypes and tagged values that are attached to the stereotypes but does not change the underlying metamodel for the UML. The Profile also includes some icons to more easily visualize the database elements that are created and rules to enforce about the creation of a relational database design.
In this chapter, we cover the first part of the Profile, how to model the database structures. In the next chapter, we will cover some of the more physical database elements involved in storage modeling. The database is created with tables, columns, and relationships. There are several elements that extend the database, like triggers, stored procedures, constraints, user-defined types (do mains), views, and others. The Profile covers how to model all of these elements and where in the model they are defined.
The following diagram elements are described below. Figure 7-3 shows their associated icons.
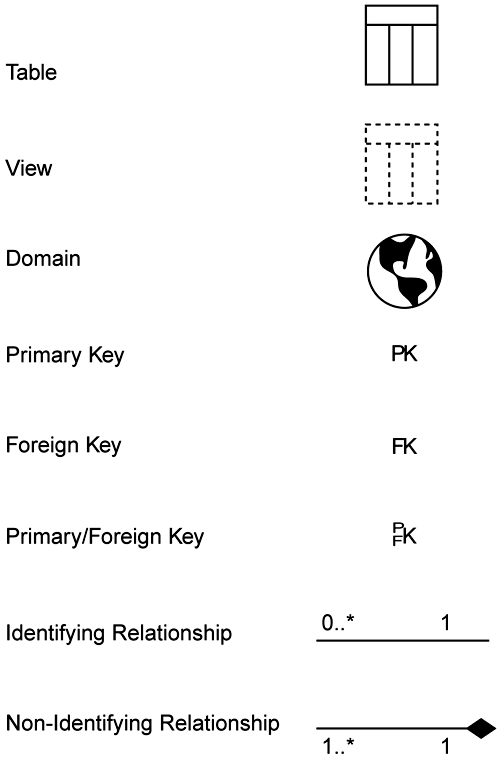
Table?/b>? a grouping of information in a database about the same subject, made up of columns
Column?/B>? a component of a table that holds a single attribute of the table
Primary key?/b>? the candidate key that is chosen to identify rows in a table
Foreign key?/B>? a column or set of columns within a table that map to the primary key of another table
Identifying relationship?/b>? a relationship between two tables in which the child table must coexist with the parent table
Non-identifying relationship?/b>? a relationship between two tables in which each table can exist independently of the other
View?/b>? a virtual table that, from the user's perspective, behaves exactly like a typical table but has no independent existence of its own
Stored procedure?/b>? an independent procedural function that typically executes on the server
Domains?/b>? the valid set of values for an attribute or column
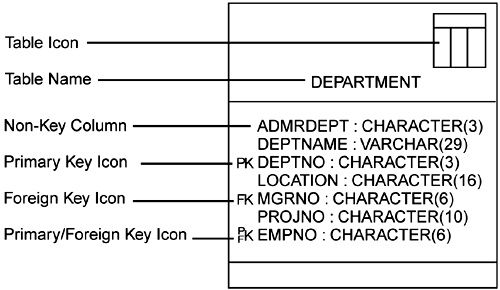
A table is a container composed of columns to store and organize the data in the system. A table is modeled as a class with the stereotype of table viewed as <<Table>>. The stereotype of table on class automatically causes all of the attributes on the class to become columns and automatically stereotypes the attribute as <<Column>>.
A column can be designated as a key or non-key column. A key column can be primary, foreign, or a combination of both primary and foreign. A primary key column is a column (or group of columns) that uniquely identifies its table or the row within its table. A foreign key is a column that was a primary key in a parent table that migrates to the child table and identifies the relationship between the tables. The foreign key can participate as a key or non-key column within the child table. The type of foreign key depends on the type of relationship involved between the two tables. An identifying relationship between tables makes the foreign key part of the primary key in the child table; a non-identifying relationship makes the foreign key a non杙rimary key column. There are icons that help to visualize the tables, columns, and type of keys (see Figure 7-4).
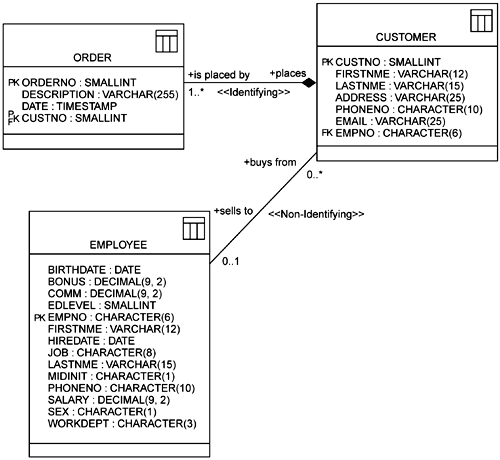
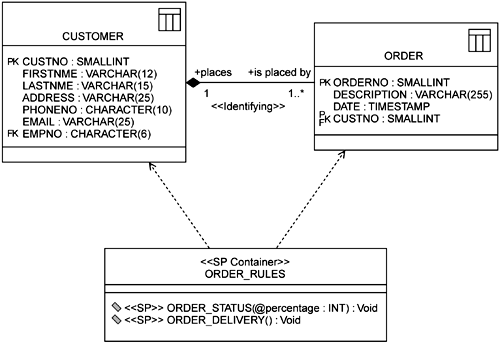
There are two basic types of relationships when modeling the database: identifying (also known as mandatory) and non-identifying. The identifying relationship means that the child table cannot exist without the parent table. An example of an identifying relationship is that between Order and Customer; without a customer, the order doesn't exist. A non-identifying relationship occurs when the child table can live on its own. An example of a non-identifying relationship is that between Customer and Employee. A customer can exist without an employee, but often when an employee makes the sale that employee is assigned to the customer. With new technologies of the Internet and older technologies of catalogs, you may not have an employee who sold the product; the customer may have purchased it without employee assistance. Therefore it is not mandatory that a customer exist only when associated to an employee. The identifying relationship is created with a stereotype of <<Identifying>> on a composite aggregation, and a non-identifying relationship is created with a stereotype of <<Non-identifying>> on an association.
When creating relationships, there is a need to define the relationship with cardinality. Cardinality is a numerical range defined on the relationship on how many times the relationship can occur. An example using cardinality is one customer can place one or more orders. The UML shows the cardinality directly on the relationship. For this example it would look like a 1 on the customer end of the relationship and 1..* on the order end of the relationship. Because it is a 1 and not 0..1 on the parent end of the relationship, this means that the relationship cannot be null and that each customer must have at least one order. You can also define roles on a relationship. A role describes the relationship textually. For this same example, the roles would be read as a customer places one or more orders, with places being the role on the customer (see Figure 7-5).
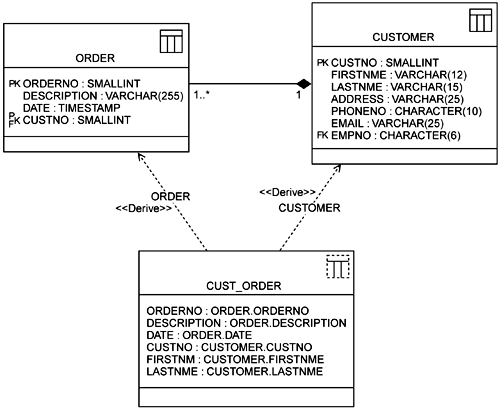
Database views are defined as a database component that behaves exactly like a table but has no independent existence of its own. A view is also known as a virtual table. Views may have different rules depending on the database server. For example, in Oracle a view can be updated, whereas in SQL Server Version 7 it cannot. A view is defined in the UML as a class with the stereotype of <<view>>. The view can be derived from one or more tables or views. A view's relationship to its parent tables and views is modeled with a dependency with the stereotype of <<Derived>> (see Figure 7-6).
Another one of the many advantages of using the UML for your database de sign is the ability to model standard elements that are not generally modeled in traditional ER notations but have great value in being modeled. One such element in the database design is the stored procedures. A stored procedure can be de fined in different ways, again based on the database server. The stored procedure can be defined as a procedure within the database, from an external file or as a function. Some databases support the concept of a stored procedure package or container. A stored procedure container is a grouping of one or multiple stored procedures within a group and currently is supported in the Oracle 8i database. The container is modeled as a class with the stereotype of <<SP Container>>. Within a <<SP Container>> are stored procedures, which are modeled as operations on the container with the stereotype of <<SP>>. Another advantage of showing the procedures on the diagram is that you can visualize what the parameters are and the procedures dependency on tables within the database (see Figure 7-7).
When building a database design, it is important to enforce standards and enable ways to reuse elements as much as possible. The use of domains, also known as user-defined datatypes, gives the modelers the power to reuse elements. A domain has all of the properties of a column except the column's name. The domain is assigned to one or more columns and the column inherits all of the domain's properties. If you change the properties of the domain, it will change the properties of all columns that inherit from that domain. A domain can be used as a standard to be reused within one or several models. A domain is a class that has the stereotype of <<Domain>>. A domain has attributes, which pertain to a column's property. A composite domain can also be used, which is a class that has the stereotype of <<Domain>> but has multiple attributes. When a domain has multiple attributes and it is assigned to a column in a table, the additional attributes become columns as well. An example of a composite domain would be address. The domain address has attributes of street1, street2, city, state, country, and postal code. A table for customer has a column called address with the domain of address assigned to it. When the table is expanded for code generation, it will contain all of the columns of the address domain. This will enable a standard address to be used everywhere in the model.
A table can contain many items in addition to the columns that have already been described. In the same way, columns contain many elements that have to be described as well as some that appear directly on the diagram. The elements of tables and columns that appear in the diagram are
Constraints?/B>? a rule that limits the value of or actions on the specified data field
Key?/b>? a constraint that defines a type of key and its column(s)
Check?/B>? a constraint that defines rules against the database
Unique?/b>? a constraint that defines a column or set of columns as containing unique data
Trigger?/B>? a code that tells the database what actions to perform
Index?/b>? a file that enables faster data access
Datatype?/B>? a type whose values have no identity
Precision?/b>? the maximum number of digits allowed for a numeric data item
Scale?/b>? the number of digits in the fractional part of a numeric data item
Length?/b>? the maximum number of letters allowed for a character data item
Null?/b>? a column that is not mandated to contain data
Not null?/b>? a column that must contain data
Other elements that are part of the tables and columns as tagged values but may not appear in the diagram themselves are
Owner?/B>? the creator of the database or specific element of the database
Comment?/b>? a description in a database
Identity?/b>? a column that has data automatically added by the database, generally for primary key columns
The UML supports the concept of tagged values. They can differ based on the stereotype of an element and the type of element. The stereotype inherits its own tagged values and can include some or all of the tagged values on the base element prior to the stereotype. As always, some of these tagged values vary depending on the database server, but within this book, we try to stay generic and stick to standard ANSI SQL rules.
There are three basic types of constraints and they can be assigned to a column, but generally they are owned by the table itself. The key constraint de fines the primary and foreign keys for the table and can contain one or more columns. There are two different types of key constraints: primary key and foreign key. They are modeled as operations on a table with the stereotypes of <<PK>> and <<FK>> (see Figure 7-8). A check constraint is a rule on a column or table that can consist of calculations, a valid set of values, or a range of values. A check constraint is modeled as an operation on a table with a stereotype of <<Check>>. The last type of constraint is a unique constraint. A unique constraint designates that the data in a column or set of columns data must be unique. If a set of columns is grouped within a single unique constraint, the data when combined for the entire set of data must be unique, but the data within a single one of those columns are not required to be unique. A unique constraint is modeled as an operation on a table with the stereotype of <<Unique>>.
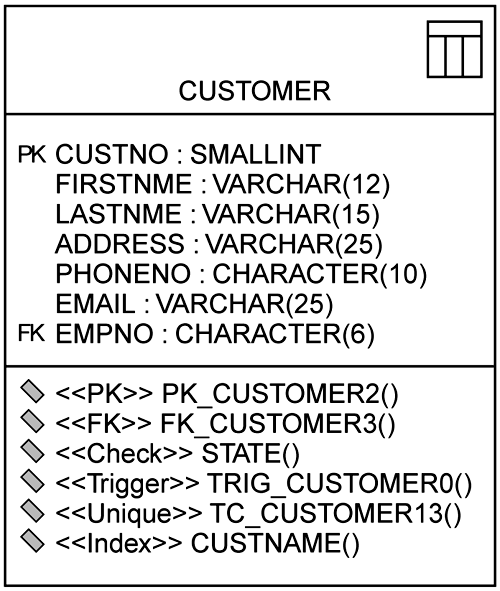
There are two types of triggers, one that is modeled and defined on a particular table and another that is part of a relationship to ensure proper referential integrity. This section covers the table-level triggers. They are created to trigger events to happen when something is done to a specific table. The trigger is database code that tells the database what other actions to perform after certain SQL statements have been executed. The table-level trigger is modeled as an operation on a table with the stereotype of <<Trigger>>. A trigger can have many tagged values that get stored in the model, but they vary significantly based on the database server and version being used. You can create the necessary tagged values as needed based on your particular database needs.
The final operation that is modeled on a table is the index. An index is a pointer used to locate rows in a table rapidly. You can think of an index as the folder tabs in a filing cabinet梐n index allows you to file information in a certain place and makes it very quick to find the information you are seeking be cause it organizes what you need in a single place. An index is modeled as an operation on a table with the stereotype of <<Index>>. There may be some tagged values on an index, for example, an index can be unique and therefore it would contain the tagged value of unique.
Datatypes, precision, scale, length, and nullability are tagged values on columns but may be displayed on the diagram as well. It is quite useful to visualize these tagged values on the diagram so that you can easily understand what the values of a column are. It is just as important to be able to not display these values on the diagram so that when using the diagram for specific needs, it is less cluttered, easier to read, and less technical for some of the nontechnical viewers. There are no specific stereotypes for tagged values, but the list of values available depends on several items, including the stereotype and to what database server the table is attached.
Additional tagged values that may not be as useful on the diagram but are very important to the model itself are owner for the table, comment on all elements of the model, and identity, which is available to many databases as a rule on a column that automatically generates a sequence of unique values for a key column. Different databases call identity something different, but the concept is similar, so we have chosen one word to describe them all. An identity column generally can be an assigned tagged value of only certain datatypes and should be available for use only with those datatypes.