As we discussed earlier in this chapter, dot notation can be used to access an object's attribute values, as in the following simple example:
Student x = new Student(); // Set the value of the name attribute of Student x. x.name = "Fred Schnurd"; // Retrieve the value of x's name so as to print it. Console.WriteLine(x.name);
In reality, however, objects often restrict access to some of their features (attributes in particular). Such restriction is known as information hiding. In a well-designed object-oriented application, an object publicizes what it can do—that is, the services it is capable of providing, or its method headers—but hides the internal details both of how it performs these services and of the data (attributes) that it maintains in order to support these services.
We use the term accessibility to refer to whether or not a particular feature of an object (attribute or method) can be accessed outside of the class in which it is declared. The accessibility of a feature is established by placing an access modifier keyword at the beginning of its declaration:
public class ClassName { // Attribute declaration. access-modifier-keyword attributeType attributeName; // etc. // Method declaration. access-modifier-keyword returnType methodName(arguments) { ... } // etc. }
C# defines five different access modifier keywords: public, private, protected, internal, and protected internal.
When a feature is declared to have public accessibility, it's freely accessible by the method code in any other class; that is, we can access public attributes from client code using dot notation.
For example, if we were to declare that the name attribute of the Student class were public, which we do by placing the keyword public just ahead of the attribute's type declaration:
public class Student
{
public string name;
// etc.
then it would be perfectly acceptable to write client code as follows:
using System;
public class MyProgram
{
static void Main() {
Student x = new Student();
// Because name is a public attribute, we may access it via dot
// notation from client code.
x.name = "Fred Schnurd";
// or:
Console.WriteLine(x.name);
// etc.
}
}
| Note?/td> |
Since we first introduced the notion of a class wrapper in Chapter 1, recall that we've also been using the public access modifier on all of our class declaration examples:
public class Student { ...
public class SimpleProgram { ...
etc.We'll discuss what it means to define a class's accessibility, and in particular, what other accessibility modifiers make sense for a class besides public, in Chapter 13. |
Similarly, if we were to declare the IsHonorsStudent method of Student to be public, which we do by again inserting the keyword public into the method header:
public class Student
{
// Attributes omitted.
// Methods.
public bool IsHonorsStudent() {
// details omitted.
}
// etc.
}
it would then be perfectly acceptable to invoke the IsHonorsStudent method from client code as follows:
public class MyProgram
{
static void Main() {
Student x = new Student();
// Because IsHonorsStudent() is a public method, we may access it
// via dot notation from client code.
if (x.IsHonorsStudent()) {
// details omitted.
}
// etc.
When a feature is declared to have private accessibility, on the other hand, it's not accessible outside of the class in which it's declared.
For example, if we were to declare that the ssn attribute of the Student class were private:
public class Student
{
public string name;
private string ssn;
// etc.
then we are not permitted to access it directly via dot notation from client code, as illustrated here:
public class MyProgram
{
static void Main() {
Student x = new Student();
// Not permitted from client code! ssn is private to the
// Student class, and so this will not compile.
x.ssn = "123-45-6789";
The following compilation error will result:
MyProgram.cs(8,3): error CS0122: Student.ssn is inaccessible due to
its protection level
The same is true for methods that are declared to be private: that is, they can't be invoked from client code. (We'll discuss why we'd ever want to declare a method as private a bit later in this chapter.) For example, if we were to declare the PrintInfo method of Student to be private:
public class Student
{
// Attributes omitted.
// Methods.
private void PrintInfo() {
// details omitted.
}
// etc.
}
then it would not be possible to invoke the PrintInfo method from client code:
public class MyProgram
{
static void Main() {
Student x = new Student();
// Because PrintInfo() is a private method, we may not access it
// via dot notation from client code; this won't compile:
x.PrintInfo();
// etc.
The following compiler error would result:
error CS0122: 'Student.PrintInfo()' is inaccessible due to its protection level
We'll defer a discussion of the other three C# access modifiers—protected, internal, and protected internal—until Chapter 13, because there are a few more object concepts that we have to cover first. For now, it's perfectly appropriate to think of accessibility as coming in only two "flavors"—public and private.
If we don't explicitly specify the accessibility of a feature when we declare it, it will be private by default:
public class Student
{
private string age;
string name; // Since accessibility is not explicitly specified for
// the "name" attribute, it will be private by default.
// The same is true for this method.
void DoSomething() {
// details omitted
}
// etc.
}
Note that we can access all of a given class's features, regardless of their accessibility, from within any of that class's own method bodies; that is, public/private designations only affect access to a feature from outside the class itself, i.e., from client code.
In the following example, the Student class's PrintAllAttributes method is accessing the private name and ssn attributes of the Student class:
using System;
public class Student
{
private string name;
private string ssn;
// etc.
public void PrintAllAttributes() {
Console.WriteLine(name);
Console.WriteLine(ssn);
// etc.
}
// etc.
}
Furthermore, note that we needn't use dot notation to access a feature of a class when we're inside the body of one of the class's own methods; it's automatically understood that the class is accessing one of its own features when a simple name—that is, a name without a dot notation prefix (aka an unqualified name)—is used. This language feature is illustrated by the following (abbreviated) Student class code:
public class Student
{
// A few private attributes.
private double totalLoans;
private double tuitionOwed;
// other attributes omitted
public bool AllBillsPaid() {
// We can call upon another method that is defined within this
// SAME class (see declaration of MoneyOwed() below) without using
// dot notation.
double amt = MoneyOwed();
if (amt == 0.0) {
return true;
}
else {
return false;
}
}
public double MoneyOwed() {
// We can access attributes of this class (totalLoans and
// tuitionOwed) -- even though they are declared to be private! --
// without using dot notation.
return totalLoans + tuitionOwed;
}
}
| Note?/td> |
Note that the order in which methods are declared within a C# class doesn't matter; that is, we're permitted to call a method B from within method A even though the definition of method B comes after/below A in the class declaration. In particular, in the preceding code example, we call MoneyOwed from within AllBillsPaid despite the fact that MoneyOwed is declared after AllBillsPaid. |
As it turns out, methods of a class are typically declared public because an object (class) needs to publicize its services (as in a Yellow Pages ad!) so that client code may request these services. By contrast, most attributes are typically declared private (and effectively "hidden"), so that an object can maintain ultimate control over its data; we'll go into significant detail later in this chapter about how an object does so.
| Note?/td> |
The notion that a class is "guaranteed" to do what it advertises that it's going to do is often referred to as programming by contract; for more information, see Object-Oriented Software Construction by Bertrand Meyer (Prentice Hall). |
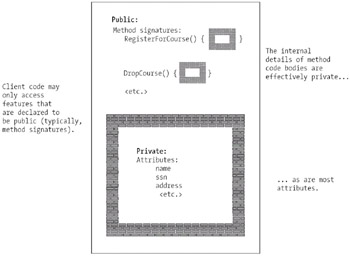
Although it isn't explicitly declared as such, the internal code that implements each method (that is, the method body) is also, in a sense, implicitly private. When a client object A asks another object B to perform one of its methods, A doesn't need to know the "behind the scenes" details of how B is doing what it's doing; A needs simply to trust that object B will perform the "advertised" service (see Figure 4-6).
Previously in the book, we've introduced the Camel and Pascal capitalization styles and discussed how they are applied to C# programming elements. Now that we've touched on accessibility, let's refine our understanding of when to use these two alternate styles.
Pascal casing (uppercase starting letter) is used for all class and method names, regardless of their accessibility. It's also used for the names of public attributes.
Camel casing (lowercase starting letter) is used for the names of nonpublic attributes.
Here is an example class to illustrate these rules:
public class Student // uppercase S for class name
{
private string name; // lowercase n for private attribute
public string Major; // uppercase M for public attribute
// etc.
public void DoSomething() { // uppercase D for method name
// A local variable; while not explicitly private, it is not accessible
// from outside this method, and so begins with a lowercase letter.
int x = 0;
// details omitted ...
}
private void DoSomethingElse() { // Uppercase D, even though private, because
// details omitted ... ALL methods are named using Pascal casing.
} // regardless of their accessibility.
// etc.
}
Going back to our definition of method header from a bit earlier in the chapter, let's amend that definition to also include the accessibility modifier for a method. That is, a method header actually consists of the following:
A method's return type—that is, the data type of the information that is going to be passed back by object B to object A, if any, when the method is finished executing.
A method's (accessibility) modifier(s).
| Note?/td> |
There are also other types of modifiers on methods besides accessibility modifiers.We'll talk about some of the other modifiers that can be applied to methods in Chapters 7 and 13. |
A method's name
An optional list of comma-separated formal parameters (specifying their names and types) to be passed to the method enclosed in parentheses
As an example, here is a typical method header that we might define for the Student class:
public bool RegisterForCourse (string courseID, int secNo)
accessibility return type method name comma-separated list of formal
modifier parameters, enclosed in parentheses
(parentheses may be left empty)
| Note?/td> |
There is actually one more aspect to a method's header, having to do with what are referred to as modifiers on individual parameters, that is beyond the scope of this book to address. |
If private features can't be accessed outside of an object's own methods, how does client code ever manipulate them? Through public features, of course! Good OO programming practice calls for providing public accessors by which clients of an object can effectively manipulate selected private attributes to read or modify their values. Why is this? So that we may empower an object to have the "final say" in whether or not what client code is trying to do to its attributes is "okay." That is, letting an object determine whether or not any of the business rules defined by its class are being violated. Before we go into an in-depth discussion of why this is so important, we'd like to first discuss the "mechanics" of how we create accessors.
There are two general approaches to providing accessors:
The generic OOPL approach is to provide what are known informally as "get" and "set" methods (or, collectively, accessor methods) for reading/modifying attributes, respectively.
The C# preferred approach is to use a language construct called a property for accessing (reading/modifying) attributes. A property defines what are known as get and set accessors (note that these are not methods, despite the similarity of their names) that can return the value of an attribute to client code or modify the value of an attribute value at the request of client code, respectively.
Because our goals in this book are twofold—namely, to introduce you to general object concepts as well as to teach you basic C# syntax—and because both of these goals are equally important in our opinion, we're going to cover both of these approaches—conventional OOPL "get"/"set" methods and properties—in this section. Please realize, however, that the .NET programming community favors the use of properties over "get"/"set" methods for reasons that will become clear a bit later.
| Note?/td> |
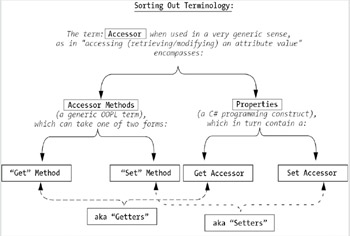
Sorting Out Terminology Throughout the book, whenever we're talking generically and collectively about all of the various OOPL ways of accessing an attribute value—whether via "get"/"set" methods or properties—in the "loosest" sense, to mean "accessing an attribute," we'll use the informal generic term "accessor." If we wish to refer informally about "getting" the value of an attribute via either a "get" method or a property's get accessor, we'll use the informal term "getter." If we wish to refer informally about "setting" the value of an attribute via either a "set" method or a property's set accessor, we'll use the informal term "setter." Otherwise, we'll use the more precise terminology "get method," "set method," "get accessor," or "set accessor," as appropriate. All of these various terms and their interrelationships are illustrated in Figure 4-7. |
The following code, excerpted from the Student class, illustrates the conventional "get" and "set" methods that we might write for a private attribute called name:
public class Student
{
// Attributes are typically declared to be private.
private string name;
// other attributes omitted ...
// Provide public accessor methods for reading/modifying
// the private "name" attribute from client code.
// Read ("get") the value of the name attribute.
public string GetName() {
return name;
}
// Modify ("set") the value of the name attribute.
public void SetName(string newName) {
name = newName;
}
// etc.
}
The nomenclature "get" and "set" is stated from the standpoint of client code: think of a "set" method as the way that client code stuffs a value into an object's attribute (see Figure 4-8) …
… and the "get" method as the way that client code retrieves an attribute value out of an object (see Figure 4-9).
For an attribute declaration of the form
accessibility* attribute-type attributeName; * typically private
e.g.,
private string majorField;
the recommended accessor method headers are as follows:
"get" method: public attribute-type GetAttributeName()
For example, public string GetMajorField()
Note that we don't pass any arguments into a "get" method, because all we want an object to do is to hand us back the value of one of its attributes; we don't typically need to tell the object anything more for it to know how to do this.
Also, because we're expecting an object to hand back the value of a specific attribute, the return type of the "get" method must match the type of the attribute of interest. If we're "getting" the value of an int attribute, then the return type of the method must be int; if we're "getting" the value of a string attribute, then the return type of the method must be string; and so forth.
"set" method: public void SetAttributeName(attribute-type parameterName)
For example, public void SetMajorField(string major)
In the case of a "set" method, we must pass in the value that we want the object to use when setting its corresponding attribute value, and the type of the value that we're passing in must match the type of the attribute being set. If we're "setting" the value of an int attribute, then the argument that is passed in must be an int; if we're "setting" the value of a string attribute, then the argument that is passed in must be a string; and so forth.
However, since most "set" methods perform their mission silently, without returning a value to the client, we typically declare "set" methods to have a return type of void.
Note that we devise the names for both types of method by capitalizing the first letter of the attribute name and sticking either Get or Set in front of it. There is one exception to this method naming convention: when an attribute is of type bool, it's recommended that we name the "get" method starting with the verb "Is" instead of with "Get". The "set" method for a bool attribute would still follow the standard naming convention. For example:
public class Student
{
private bool honorsStudent;
// other attributes omitted ...
// Get method.
public bool IsHonorsStudent() {
return honorsStudent;
}
// Set method.
public void SetHonorsStudent(bool x) {
honorsStudent = x;
}
// etc.
}
All of the "get"/"set" method bodies that we've seen thus far are simple "one liners": we're either returning the value of the attribute of interest with a simple return statement in a "get" method, or copying the value of the passed-in argument to the internal attribute in a "set" method so as to store it. This isn't to imply that all "get"/"set" methods need be this simple; in fact, there are endless possibilities for what actually gets coded in accessor methods, because as we discussed earlier, methods must implement business rules, not only about how an object behaves, but also what valid states its data can assume.
We already know how to utilize dot notation to invoke methods on objects from client code:
Student s = new Student();
// Modify ("set") the attribute value.
s.SetName("Joe");
// Read ("get") the attribute value.
Console.WriteLine("Name: " + s.GetName());
As mentioned earlier, C# also provides a programming construct for accessing attributes called a property. In a nutshell, a property is a way of "disguising" accessor logic so that, from the perspective of client code, it appears that we're accessing a public attribute:
// Client code for setting Student s's name via a property it APPEARS as though // we're accessing a public attribute, but we are not! s.Name = "Melbito"; // or, for getting s's name via a property: Console.WriteLine(s.Name);
when in fact we are invoking behind-the-scenes accessor code, albeit not in the explicit "get"/"set" method-calling sense.
Let's learn how to declare and use properties.
We use the following general syntax for declaring a property:
access-modifier-keyword type propertyName {
get {
// code body of get accessor
}
set {
// code body of set accessor
}
}
For example, if we wish to declare a property associated with the private attribute name in lieu of "get"/"set" methods in our Student class, we might write the following code:
public class Student
{
// We're still declaring the name attribute in the same way as we did before.
private string name;
// etc.
// However, we're now defining a property called "Name" in lieu of writing
// "get"/"set" methods for the "name" attribute.
public string Name {
// This takes the place of a "get" method.
get {
return name;
}
// This takes the place of a "set" method.
set {
// "value" is an implicit input parameter that is automatically
// passed to the set accessor.
name = value;
}
// etc.
}
}
Some noteworthy features about properties:
The convention for a property name is that it should match the name of its associated attribute, but should begin with a capital letter (property names use the Pascal capitalization style). Recall that, since C# is a case-sensitive language, name and Name are treated as different symbols by the compiler.
The type of a property must match the type of its associated attribute. Our Name property is defined to be of type string, which indeed is the type of the name attribute.
A property defines get and set accessors, which work very much like "get"/"set" methods, but which are syntactically quite different, both in terms of how they are declared and how they are invoked from client code (the latter of which we'll see in a moment).
Analogous to a "get" method, a get accessor is used to return the value of the corresponding attribute to client code.
Note that there is no need to declare a return type for a get accessor as we must do for a "get" method, because a get accessor implicitly returns the same type as the property in which it is defined.
get {
return name;
}
Analogous to a "set" method, a set accessor is used to change the value of the corresponding attribute at the request of client code.
Note that there is no need to declare a parameter list for a set accessor as we must do for a "set" method because a set accessor implicitly takes a single parameter, named value, which represents the new value being suggested for the attribute by client code:
set {
name = value; // value is implicitly declared
}
Note that there is also no need to declare a return type for a set accessor, as it implicitly has a return type of void.
The preceding example featured a property with simple, "one-liner" get and set accessors. Of course, as we mentioned for "get"/"set" methods earlier, there are endless possibilities for what actually gets coded in get and set accessors because they must implement the appropriate business logic for the attribute that they control. We'll see more complex examples of property accessors later in the chapter.
Let's place the code used in the two different approaches to declaring accessors—"get"/"set" methods vs. properties—side-by-side, to emphasize the differences in their syntax:
|
Student Version with Get/Set Methods |
Equivalent Student Version Using a Property |
|---|---|
public class Student {
private string name;
public string GetName() {
return name;
}
public void SetName(string n) {
name = n;
}
}
|
public class Student
{
private string name;
public string Name {
get {
return name;
}
set {
name = value;
}
}
}
|
Property syntax is a bit more streamlined, as follows:
By declaring a type for the property as a whole—string—we don't have to redundantly declare the return type of the get accessor or the type of the value being handed in to the set accessor: they will automatically derive the string type from the property.
By declaring accessibility of the property—public—we don't have to redundantly declare the accessibility of the get accessor or set accessor: both will derive public accessibility from the property.
Now, let's take a look at how we access a property from client code. We'll continue our example using the Name property defined earlier:
// Client code:
Student s = new Student();
// Modify ("set") the attribute value.
// Note that it LOOKS LIKE we're accessing a public attribute.
s.Name = "Joe";
// Read ("get") the attribute value.
// Again, it LOOKS LIKE we're accessing a public attribute.
Console.WriteLine("Name is " + s.Name);
From the standpoint of client code, properties are accessed via dot notation as if they were declared to be public attributes. That is, from client code, when we see an expression such as
s.Name = "Joe";
we can't tell whether Name represents a property or a public attribute! But, behind the scenes, there is quite a difference, in that with public attributes, no code is being executed beyond the direct assignment … whereas with property accessors, whatever code we've written is transparently executed behind the scenes. We'll return to this critical distinction later in the chapter.
Let's place the code used in the two different approaches to accessing attributes from client code—"get"/"set" methods vs. properties—side-by-side, to emphasize the differences in their syntax:
|
Client Code Version Utilizing Get/Set Methods |
Equivalent Client Code Utilizing a Property |
|---|---|
Student s = new Student();
// Modify ('set') the attribute value.
s.SetName("Joe");
// Read ('get') the attribute value.
Console.WriteLine("Name: " +
s.GetName());
|
Student s = new Student();
// Modify ('set') the attribute value.
s.Name = "Joe";
// Read ('get') the attribute value.
Console.WriteLine("Name is " +
s.Name);
|
Client code is a bit more streamlined when properties are used.
The elegance of property syntax is touted as one of the major advantages of C# (.NET languages as a whole) over other OOPLs. In the .NET world (as in its predecessor Visual Basic and ActiveX worlds), virtually all data is exposed as properties.
Properties are logically equivalent to (and impossible to distinguish from) attributes, but are syntactically easier to use than "get"/"set" methods. In a sense, properties give us the "best of both worlds": the ease of access of a public attribute from client code, but with the programmatic control over data integrity that we get with private attributes and "get"/"set" methods.
| Note?/td> |
When working with OO programming languages that don't support the notion of properties—e.g., C++, Java—one must be "savvy" in the use of "get"/"set" method syntax to reap all of the benefits of encapsulation and information hiding—benefits that we'll cover in depth a bit later in this chapter. Because of the "favored status" of properties when programming in C#, however, we'll illustrate all remaining OO principles throughout the book in detail using properties, but will remind you that many of the same benefits can be achieved in other OOP languages using "get"/"set" method syntax. |
Because we haven't explicitly stated so before, and because it may not be obvious to everyone, let's call attention now to the fact that an object's attribute values persist as long as the object itself persists in memory. That is, once we instantiate a Student object in our application:
Student s = new Student();
then any values that we assign to s's attributes, whether via "set" methods or properties:
s.Name = "Steve";
will persist until either (a) such time as the value is explicitly changed:
// Renaming Student s. s.Name = "Mel";
or (b) such time as the object is destroyed and its memory is recycled (we'll talk about ways of destroying an object and recycling its memory in Chapter 13). So, as long as the memory allocated to Student object s stays around (or, to return to our analogy from Chapter 3, as long as the "helium balloon" representing s stays "inflated"), whenever we ask s for its name, it will remember whatever value we've last assigned to its name attribute.
Even though it's generally true that
Attributes are declared to be private;
Methods are declared to be public; and
Private attributes are accessed through either public properties or methods
there are numerous exceptions to this rule.
An attribute may be used by a class strictly for internal housekeeping purposes. (Like the dishwashing detergent you keep under the sink, guests needn't know about it!) For such attributes, we needn't bother to provide public accessors. One example for the Student class might be an attribute:
private int countOfDsAndFs;
This attribute might be used to keep track of how many poor grades a student has received in order to determine whether or not the student is on academic probation. We may provide a Student class method as follows:
public bool OnAcademicProbation() {
// If the student received more than three substandard grades,
// they will be put on academic probation.
if (countOfDsAndFs > 3) {
return true;
}
else {
return false;
}
}
This method uses the value of private attribute countOfDsAndFs to determine whether a student is on academic probation, but no client code need ever know that there is such an attribute as countOfDsAndFs, and so no explicit public accessors are provided for this attribute. Such attributes are instead set as a "side effect" of performing some other method, as in the following example, also taken from the Student class:
public void CompleteCourse(string courseName,
int creditHours,
char grade) {
// Updating this private attribute is considered to be a
// "side effect" of completing a course.
if (grade == 'D' || grade == 'F') countOfDsAndFs++;
// Other processing details omitted.
}
Some methods/properties may be used strictly for internal housekeeping, as well, in which case these may also be declared private rather than public. An example of such a Student class method might be UpdateGpa, which recomputes the value of the gpa attribute each time a student completes another course and receives a grade. The only time that this method may ever need to be called is perhaps from within another method of Student—for example, the public CompleteCourse method—as follows:
public class Student
{
private double gpa;
private int totalCoursesTaken;
private int totalQualityPointsEarned;
private int countOfDsAndFs;
// other details omitted ...
public void CompleteCourse(string courseName,
int creditHours,
char grade) {
if (grade == 'D' || grade == 'F') {
countOfDsAndFs++;
}
// Record grade in transcript.
// details omitted ...
// Update an attribute ...
totalCoursesTaken = totalCoursesTaken + 1;
// ... and call a PRIVATE housekeeping method from within this
// public method to adjust the student's GPA accordingly.
UpdateGpa(creditHours, grade);
}
// The details of HOW the GPA gets updated are a deep, dark
// secret! Even the EXISTENCE of this next method is hidden from
// the "outside world" (i.e., inaccessible from client code) by
// virtue of its having been declared to be PRIVATE.
private void UpdateGpa(int creditHours, char grade) {
int letterGradeValue = 0;
if (grade == 'A') letterGradeValue = 4;
if (grade == 'B') letterGradeValue = 3;
if (grade == 'C') letterGradeValue = 2;
if (grade == 'D') letterGradeValue = 1;
// For an 'F', it remains 0.
int qualityPoints = creditHours * letterGradeValue;
// Update two attributes.
totalQualityPointsEarned =
totalQualityPointsEarned + qualityPoints;
gpa = totalQualityPointsEarned/totalCoursesTaken;
}
}
Client code shouldn't be able to directly cause a Student object's GPA to be updated; this should only occur as a side effect of completing a course. By making the UpdateGpa method private, we've prevented any client code from explicitly invoking this method to manipulate this attribute's value out of context.
We needn't always provide both a "getter" and a "setter" for private attributes.
If we provide only a "getter" for an attribute, then that attribute is rendered effectively read-only. We might do so, for example, with a student's ID number, which once set, should remain unchanged.
public class Student
{
string studentId;
// details omitted
// We define a read-only property by only writing a get accessor
public string ID {
get {
return studentId;
}
// The set accessor is omitted.
}
}
| Note?/td> |
How do we ever set such an attribute's value the first time? We've already seen that some attributes' values get modified as a side effect of performing a method (as with countOfDsAndFs). We'll also see how to explicitly initialize such a "read-only" attribute a bit later in this chapter, when we talk about constructors. |
By the same token, we can provide only a "setter" for an attribute, in which case the attribute would be write-only.
If we provide neither a "getter" or "setter," we've effectively rendered the attribute as a private "housekeeping" data item, as previously discussed.