Let's assume that we've accurately and thoroughly modeled all of the essential features of students via our Student class, and furthermore that we've programmed the class in C#. A simplified version of the Student class is shown here:
using System;
public class Student
{
private string name;
private string studentId;
// etc.
public string Name {
get {
return name;
}
set {
name = value;
}
}
public string StudentId {
get {
return studentId;
}
set {
studentId = value;
}
}
// etc.
}
In fact, let's further assume that our Student class code has been rigorously tested, found to be bug free, and is actually being used in a number of applications: our Student Registration System, for example, as well as perhaps a student billing system and an alumni relations system for the same university.
A new requirement has just arisen for modeling graduate students as a special type of student. As it turns out, the only features of a graduate student that we need to track above and beyond those that we've already modeled for a "generic" student are
What undergraduate degree the student previously received before entering their graduate program of study
What institution they received the undergraduate degree from
All of the other features necessary to describe a graduate student—attributes name, studentId, and so forth, along with properties to access these and the methods modeling a student's behaviors—are the same as those that we've already programmed for the Student class, because a graduate student is a student, after all.
How might we approach this new requirement for a GraduateStudent class? If we weren't well versed in object-oriented concepts, we might try one of the following approaches.
We could add attributes to reflect undergraduate degree information to our definition of a Student, along with properties to access these, and simply leave these attributes empty when they are nonapplicable: that is, for an undergraduate student who hadn't yet graduated.
public class Student
{
private string name;
private string studentId;
private string undergraduateDegree;
private string undergraduateInstitution;
// etc.
Then, to keep track of whether these attributes were supposed to contain values or not for a given Student object, we'd probably also want to add a bool attribute to note whether a particular student is a graduate student:
public class Student
{
private string name;
private string studentId;
private string undergraduateDegree;
private string undergraduateInstitution;
private bool isGraduateStudent;
// etc.
In any new methods that we subsequently write for this class, we'll have to take the value of this bool attribute into account:
public void DisplayAllFields(){
Console.WriteLine(name);
Console.WriteLine(studentId);
// If a particular student is NOT a graduate student, then the values
// of the attributes "undergraduateDegree" and
// "undergraduateInstitution" would be undefined, and so we would
// only wish to print them if we are dealing with a graduate student.
if (isGraduateStudent){
Console.WriteLine(undergraduateDegree);
Console.WriteLine(undergraduateInstitution);
}
// etc.
}
This results in convoluted code, which is difficult to debug and maintain.
We could instead create a new GraduateStudent class by (a) making a duplicate copy of the Student class, (b) renaming the copy to be the GraduateStudent class, and (c) adding the extra features required of a graduate student to the copy.
This would be awfully inefficient, since we'd then have much of the same code in two places, and if we wanted to change how a particular method worked or how an attribute was defined later on—say, a change of the type of the birthDate attribute from string to DateTime, with a corresponding change to the properties for that attribute—then we'd have to make the same changes in both classes.
Strictly speaking, either of the preceding two approaches would work, but the inherent redundancy in the code would make the application difficult to maintain. In addition, where these approaches both really break down is when we have to invent a third, or a fourth, or a fifth type of "special" student. For example, consider how complicated the DisplayAllFields method introduced in approach #1 would become if we wanted to use it to represent a third type of student: namely, continuing education students, who don't seek a degree, but rather are just taking courses for continuing professional enrichment.
We'd most likely need to add yet another bool flag to keep track of whether or not a degree was being sought:
public class Student
{
private string name;
private string studentId;
private string undergraduateDegree;
private string undergraduateInstitution;
private string degreeSought;
private bool isGraduateStudent;
private bool seekingDegree;
// etc.
Then, we'd also have to take the value of this bool attribute into account in the DisplayAllFields method:
public void DisplayAllFields() {
Console.WriteLine(name);
Console.WriteLine(studentId);
if (isGraduateStudent) {
Console.WriteLine(undergraduateDegree);
Console.WriteLine(undergraduateInstitution);
}
// If a particular student is NOT seeking a degree, then the value
// of the attribute 'degreeSought' would be undefined, and so we
// would only wish to print it if we are dealing with a degree-
// seeking student.
if (seekingDegree) {
Console.WriteLine(degreeSought);
}
else {
Console.WriteLine("NONE");
}
// etc.
}
This worsens the complexity issue!
We've had to introduce a lot of complexity in the logic of this one method to handle the various types of student; think of how much more "spaghetti-like" the code might become if we had dozens of different student types to accommodate! Unfortunately, with non-OO languages, these convoluted approaches would typically be our only options for handling the requirement for a new type of object. It's no wonder that applications become so complicated and expensive to maintain as requirements inevitably evolve over time!
Fortunately, we do have yet another alternative!
With an object-oriented programming language, we can solve this problem by taking advantage of inheritance, a powerful mechanism for defining a new class by stating only the differences (in terms of features) between the new class and another class that we've already established. Using inheritance, we can declare a new class named GraduateStudent that inherits all of the features of the Student class. The GraduateStudent class would then only have to take care of the two extra attributes associated with a graduate student—undergraduateDegree and undergraduateInstitution. Inheritance is indicated in a C# class declaration using a colon followed by the name of the base class being extended.
public class GraduateStudent : Student {
// Declare two new attributes above and beyond
// what the Student class declares ...
private string undergraduateDegree;
private string undergraduateInstitution;
// ... and properties for each of these new attributes.
public string UndergraduateDegree {
get {
return undergraduateDegree;
}
set {
undergraduateDegree = value;
}
}
public string UndergraduateInstitution {
get {
return undergraduateInstitution;
}
set {
undergraduateInstitution = value;
}
}
}
That's all we need to declare in our new GraduateStudent class: two attributes plus their associated properties! There is no need to duplicate any of the features of the Student class, because we're automatically inheriting these. It's as if we had "plagiarized" the code for the attributes, properties, and methods from the Student class, and inserted it into GraduateStudent, but without the fuss of actually having done so.
When we take advantage of inheritance, the original class that we're starting from—Student, in this case—is called the base class. The new class—GraduateStudent— is called a derived class. A derived class is said to extend a base class.
Inheritance is often referred to as the "is a" relationship between two classes, because if a class B (GraduateStudent) is derived from a class A (Student), then B truly is a special case of A. Anything that we can say about a base class must also be true about all of its derived classes; that is
A Student attends classes, and so a Graduate Student attends classes.
A Student has an advisor, and so a Graduate Student has an advisor.
A Student pursues a degree, and so a Graduate Student pursues a degree.
In fact, an "acid test" for legitimate use of inheritance is as follows: if there is something that can be said about a base class A that can't be said about a proposed derived class B, then B really isn't a valid derived class of A.
Note, however, that the converse isn't true: because a derived class is a special case of its base class, it's possible to say things about the derived class that can't be said about the base class; for example:
A GraduateStudent has already attended an undergraduate institution, whereas a "generic" Student may not have done so.
A GraduateStudent has already received an undergraduate degree, whereas a "generic" Student may not have done so.
Because derived classes are special cases of their base classes, the term specialization is used to refer to the process of deriving one class from another. Generalization, on the other hand, is a term used to refer to the opposite process: namely, recognizing the common features of several existing classes and creating a new, common base class for them all. Let's say we now wish to create the Professor class. Students and Professors have some features in common: attributes—name, birthDate, etc., and the properties/methods that manipulate these. Yet, they each have unique features, as well; the Professor class might require the attributes title (a string) and worksFor (a reference to a Department), while the Student class's studentID, degreeSought, and majorField attributes are irrelevant for a Professor. Because each class has attributes that the other would find useless, neither class can be derived from the other. Nonetheless, to duplicate their shared features in two places would be horribly inefficient.
In such a circumstance, we may want to invent a new base class called Person, consolidate the features common to both Students and Professors in that class, and then have Student and Professor inherit these common features from Person. The resultant code in this situation appears here:
// Defining the base class:
public class Person
{
// Attributes common to Students and Professors.
private string name; // See note about use of private accessibility
private string address; // with inheritance after this code example.
private string birthDate;
// Common properties.
public string Name {
get {
return name;
}
set {
name = value;
}
}
// etc.
// Common methods - details omitted.
}
// Deriving Student from Person ...
public class Student : Person
{
// Attributes specific only to a Student.
private string studentId;
private string majorField;
private string degreeSought;
// Student-specific properties.
public string StudentId {
get {
return studentId;
}
set {
studentId = value;
}
}
// etc.
// Student-specific methods - details omitted.
}
// Deriving Professor from Person ...
public class Professor : Person
{
// Attributes specific only to a Professor.
private string title;
private Department worksFor;
// Professor-specific properties.
public string Title {
get {
return title;
}
set {
title = value;
}
}
// etc.
// Professor-specific methods - details omitted.
}
| Note?/td> |
You'll learn in Chapter 13 that there are a few extra complexities about inheriting private features, and how another accessibility type—protected accessibility—comes into play, which we aren't tackling just yet because we haven't covered enough ground to do them justice at this point. |
Inheritance is perhaps one of the most powerful and unique aspects of an OO programming language because
Derived classes are much more succinct than they would be without inheritance. Derived classes only contain the "essence" of what makes them different from their base classes. We know from looking at the GraduateStudent class definition, for example, that a graduate student is "a student who already holds an undergraduate degree from an educational institution." As a result, the total body of code for a given application is significantly reduced as compared with the traditional non-OO approach to developing the same application.
Through inheritance, we can reuse and extend code that has already been thoroughly tested without modifying it. As we saw, we were able to invent a new class—GraduateStudent—without disturbing the Student class code in any way. So, we can rest assured that any client code that relies on instantiating Student objects and passing messages to them will be unaffected by the creation of derived class GraduateStudent, and thus we avoid having to retest huge portions of our existing application. (Had we used a non-OO approach of "tinkering" with the Student class code to try to accommodate graduate student attributes, we would have had to retest our entire existing application to make sure that nothing had "broken"!)
Best of all, we can derive a new derived class from an existing class even if we don't own the source code for the latter! As long as we have the compiled version of a class, the inheritance mechanism works just fine; we don't need the original source code of a class in order to extend it. This is one of the significant ways to achieve productivity with an object-oriented language: find a class (either written by someone else or one that is built into the language) that does much of what you need, and create a derived class of that class, adding just those features that you need for your own purposes; or buy a third-party library of classes written by someone else, and do the same.
Finally, as we saw in Chapter 2, classification is the natural way that humans organize information; so, it only makes sense that we'd organize our software along the same lines, making it much more intuitive and hence easier to maintain and extend.
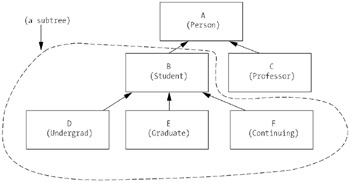
Over time, we build up an inverted tree of classes that are interrelated through inheritance; such a tree is called a class hierarchy. One such class hierarchy example is shown in Figure 5-6.
A bit of nomenclature:
We may refer to each class as a node in the hierarchy.
Any given node in the hierarchy is said to be derived (directly or indirectly) from all of the nodes above it in the hierarchy, known collectively as its ancestors.
The ancestor that is immediately above a given node in the hierarchy is considered to be that node's direct base class.
Conversely, all nodes below a given node in the hierarchy are said to be its descendants.
The node that sits at the top of the hierarchy is referred to as the root node.
A terminal, or leaf, node, is one that has no descendants.
Two nodes that are derived from the same direct base class are known as siblings.
Applying this terminology to the example hierarchy in Figure 5-5
Class A (Person) is the root node of the entire hierarchy.
Classes B, C, D, E, and F are all said to be derived from class A, and are thus descendants of A.
Classes D, E, and F can be said to be derived from class B.
Classes D, E, and F are siblings; so are classes B and C.
Class D has two ancestors, A and B.
Classes C, D, E, and F are terminal nodes, in that they don't have any classes derived from them (as of yet, at any rate).
Note that arrows are used to point upward from each derived class to its direct base class.
| Note?/td> |
In the C# language, the Object class (of the System namespace) serves as the ultimate base class for all other types, both user-defined as well as those built into the language.We'll talk about the Object class in more depth in Part Three of the book. |
As with any hierarchy, this one may evolve over time:
It may widen with the addition of new siblings/branches in the tree.
It may expand downward as a result of future specialization.
It may expand upward as a result of future generalization.
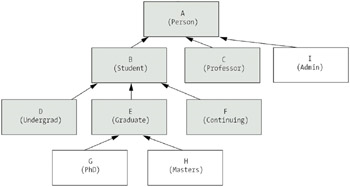
Such changes to the hierarchy are made as new requirements emerge, or as our understanding of the existing requirements improves. For example, we may determine the need for MastersStudent and PhDStudent classes (as specializations of GraduateStudent), or for an Administrator class as a sibling to Student and Professor. This would yield the revised hierarchy shown in Figure 5-7.
Association, aggregation, and inheritance are all said to be relationships between classes. Where inheritance differs from association and aggregation is at the object level.
As we've seen earlier in this chapter, association (and aggregation, as a special form of association) can be said to relate individual objects, in the sense that two different objects are linked to one another by virtue of the existence of an association between their respective classes. Inheritance, on the other hand, is a way of describing the features of a single object. With inheritance, an object is simultaneously an instance of a derived class and all of its base classes: a GraduateStudent is a Student that is a Person, all wrapped into one!
So, in looking once again at the hierarchy in Figure 5-7, we see that
All classes in the hierarchy—class A (Person) as well as all of its descendants B through I—may be thought of as producing Person objects.
Class B (Student), along with its descendants D through H, may all be thought of as producing Student objects.
and so forth.
This notion of an object having "multiple identities" is a significant one that we'll revisit several times throughout the book.
Once a class hierarchy is established and an application has been coded, changes to nonleaf classes (i.e., those classes that have descendants) will introduce "ripple effects" down the hierarchy. For example, if after we've established the GraduateStudent class, we go back and add a minorField attribute to the Student class, then GraduateStudent will inherit this new attribute once it has been recompiled. Perhaps this is what we want; on the other hand, we may not have anticipated the derivation of a GraduateStudent class when we first conceived of Student, and so this may not be what we want!
As the developers of the Student class, it would be ideal if we could speak with the developers of all derived classes—GraduateStudent, MastersStudent, and PhDStudent—to obtain their approval for any proposed changes to Student. But, this isn't an ideal world, and often we may not even know that our class has been extended if, for example, our code is being distributed and reused on other projects or is being sold to clients. This evokes a general rule of thumb:
Whenever possible, avoid adding features to nonleaf classes once they have been established in code in an application to avoid ripple effects throughout an inheritance hierarchy.
This is easier said than done! However, it reinforces the importance of spending as much time as possible on requirements analysis before diving into the coding stage of an application development project. This won't prevent new requirements from emerging over time, but we should avoid oversights regarding the current requirements.
When deriving a new class, we can do several things to specialize the base class that we are starting out with.
We may extend the base class by adding features. In our GraduateStudent example, we added four features: two attributes—undergraduateDegree and undergraduateInstitution—and two properties—UndergraduateDegree and UndergraduateInstitution.
We may specialize the way that a derived class performs one or more of the services inherited from its base class. For example, when a "generic" student enrolls for a course, the student may first need to ensure that
They have taken the necessary prerequisite courses.
The course is required for the degree that the student is seeking.
When a graduate student enrolls for a course, on the other hand, they may need to do both of these things as well as to ensure that their graduate committee feels that the course is appropriate.
Specializing the way that a derived class performs a service—that is, how it responds to a given message—as compared with the way that its base class would have responded to the same message, is accomplished via a technique known as overriding.
Overriding involves "rewiring" how a method or property works internally, without changing the interface to/signature of that method. For example, let's say that we had defined a Print method for the Student class to print out the values of all of a student's attributes:
public class Student
{
// Attributes.
private string name;
private string studentId;
private string majorField;
private double gpa;
// etc.
// Properties for each attribute would also be provided; details omitted.
public void Print() {
// Print the values of all of the attributes that the Student class
// knows about; note use of get accessors.
Console.WriteLine("Student Name: " + Name + "\n" +
"Student No.: " + StudentId + "\n" +
"Major Field: " + MajorField + "\n" +
"GPA: " + Gpa);
}
}
The Print method shown in the preceding code example assumes that properties have been created for all of the Student class attributes. The get accessor of each property is used to access the value of the associated attribute, rather than accessing the attributes directly.
| Note?/td> |
Using get accessors within a class's own methods reflects a "best practices" discussion that we had in Chapter 4; doing so allows us to take advantage of any value checking or other operations that the get accessor may provide. |
By virtue of inheritance, all of the derived classes of Student will inherit this method. However, there is a problem: we added two new attributes to the GraduateStudent derived class—undergraduateDegree and undergraduateInstitution. If we take the "lazy" approach of just letting GraduateStudent inherit the Print method of Student as is, then whenever we invoke the Print method for a GraduateStudent, all that will be printed are the values of the four attributes inherited from Student—name, studentId, major, and gpa—because these are the only attributes that the Print method has been explicitly programmed to print the values of. Ideally, we would like the Print method, when invoked for a GraduateStudent, to print these same four attributes plus the two additional attributes of undergraduateDegree and undergraduateInstitution.
With an object-oriented language, we are able to override, or supersede, the Student version of the Print method that the GraduateStudent class has inherited. In order to override a base class's method in C#, the method to be overridden first has to be declared to be a virtual method in the base class using the virtual keyword. Declaring a method to be virtual means that it may be (but doesn't have to be) overridden by a derived class.
The derived class can then override the method by reimplementing the method with the override keyword in the derived class's method declaration. The overridden method in the derived class must be declared to have the same accessibility, return type, name, and parameter list as the base class method it's overriding.
Let's look at how the GraduateStudent class would go about overriding the Print method of the Student class:
public class Student
{
// Attributes.
private sring name;
private string studentId;
private string majorField;
private double gpa;
// etc.
// Properties for each attribute would also be provided; details omitted.
// The Student class Print method is declared to be virtual so that it
// may be overridden by derived classes.
public virtual void Print() {
// Print the values of all the attributes that the Student class
// knows about; again, note the use of get accessors.
Console.WriteLine("Student Name: " + Name + "\n" +
"Student No.: " + StudentId + "\n" +
"Major Field: " + MajorField + "\n" +
"GPA: " + Gpa);
}
}
public class GraduateStudent : Student
{
string undergraduateDegree;
string undergraduateInstitution;
// Properties for each newly added attribute would also be provided;
// details omitted.
// We are overriding the Student class's Print method; note use of the
// override keyword to signal this intention.
public override void Print() {
// We print the values of all the attributes that the
// GraduateStudent class knows about: namely, those that it
// inherited from Student plus those that it explicitly declares.
Console.WriteLine("Student Name: " + Name + "\n" +
"Student No.: " + StudentId + "\n" +
"Major Field: " + GMajorField + "\n" +
"GPA: " + Gpa + "\n" +
"Undergrad. Deg.: " + UndergraduateDegree + "\n" +
"Undergrad. Inst.: " + UndergraduateInstitution);
}
}
The GraduateStudent class's version of Print thus overrides, or supersedes, the version that would otherwise have been inherited from the Student class.
The preceding example is less than ideal because the first four lines of the Print method of GraduateStudent duplicate the code from the Student class's version of Print. Redundancy in an application is to be avoided, because redundant code represents a maintenance nightmare: when we have to change code in one place in an application, we don't want to have to remember to change it in countless other places or, worse yet, forget to do so, and wind up with inconsistency in our logic. We like to avoid code duplication and encourage code reuse in an application whenever possible, so our Print method for the GraduateStudent class would actually be written as follows:
public class GraduateStudent : Student
{
// details omitted ...
public override void Print() {
// Reuse code by calling the Print method defined by the Student
// base class ...
base.Print();
// ... and then go on to print this derived class's specific attributes.
Console.WriteLine("Undergrad. Deg.: " + UndergraduateDegree + "\n" +
"Undergrad. Inst.: " + UndergraduateInstitution);
}
}
We use a C# keyword, base, as the qualifier for a method name:
base.methodName(arguments);
when we wish to invoke the version of method methodName that was defined in a base class. That is, in the preceding example, we're essentially saying to the compiler "First, execute the Print method the way that my parent class, Student, would have executed it, and then do something extra—namely, print out the values of the new GraduateStudent attributes."
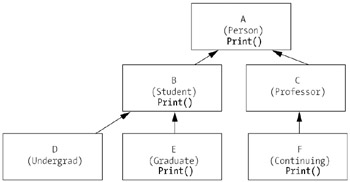
Sometimes, in a complex inheritance hierarchy, we have occasion to override a method multiple times. In the hierarchy shown in Figure 5-8
Root class A (Person) declares a method with the header
public virtual void Print()
that prints out all of the attributes declared for the Person class.
Derived class B (Student) overrides this method, changing the internal logic of the method body to print not only the attributes inherited from Person, but also those that were added by the Student class itself. The overridden method would have the following header:
public override void Print()
Derived class E (GraduateStudent) overrides this method again, to print not only the attributes inherited from Student (which include those inherited from Person), but also those that were added by the GraduateStudent class itself. The GraduateStudent version of the Print method would also use the override keyword.
public override void Print()
Note that, in all cases, the accessibility, return type, and method signature must remain the same—public void Print()—for overriding to take place.
Under such circumstances, any class not specifically overriding a given method itself will inherit the definition of that method used by its most immediate ancestor.
When deriving a new class, there are some things that we should not attempt to do. (And, as it turns out, OO languages will actually prevent us from successfully compiling programs that attempt to do most of these things.)
We shouldn't change the semantics—i.e., the intention, or meaning—of a feature. For example:
If the Print method of a base class such as Student is intended to display the values of all of an object's attributes on the computer screen, then the Print method of a derived class such as GraduateStudent shouldn't, for example, be overridden so that it directs all of its output to a file instead.
If the name attribute of a base class such as Person is intended to store a person's name in "last name, first name" order, then the name attribute of a derived class such as Student should be used in the same fashion.
We can't physically eliminate features, nor should we effectively eliminate them by ignoring them. To attempt to do so would break the spirit of the "is a" hierarchy. By definition, inheritance requires that all features of all base classes of a class A must also apply to class A itself in order for A to truly be a proper derived class. If a GraduateStudent could eliminate the degreeSought attribute that it inherits from Student, for example, is a GraduateStudent really a Student after all?
A derived class can override a base class property, but the type of the property must remain the same as the base class version of that property. For example, if the Person class declared a BirthDate property of type string:
public class Person
{
// Details omitted.
// Base class introduces a property.
public virtual string BirthDate {
get {
// details omitted.
}
}
}
then a Student class that derives from Person could not, in overriding the BirthDate property, change its type to, say, DateTime:
public class Student : Person
{
// Details omitted.
// Derived class overrides a property, attempting to modify its type in the
// process.
public override DateTime BirthDate { // this won't compile
get {
// details omitted.
}
}
}
If we tried to compile the Student class, the following compiler error would occur:
error CS0508: 'Student.BirthDate' cannot change return type when overriding inherited member 'Person.BirthDate'
| Note?/td> |
It turns out that a derived class can change the type of a base class property by hiding, rather than overriding, the base class property.We'll discuss property and method hiding in Chapter 13. |
For example, if the Print method inherited by the Student class from the Person class has the header public void Print(), then the Student class can't change this method to accept an argument, say, public void Print(int noOfCopies). To do so is to create a different method entirely, due to another C# language feature known as overloading, discussed next.
Overloading is a language mechanism supported by non-OO languages like C as well as by OO languages like C#. Overloading is sometimes mistakenly confused with overriding because the two mechanisms have similar names, but in reality overloading is a wholly different concept.
Overloading allows two or more different methods belonging to the same class to have the same name as long as they have different argument signatures (as defined in Chapter 4). For example, the Student class may legitimately define the following five different Print methods:
void Print(string fileName) - a single parameter void Print(int detailLevel) - a different parameter type from above void Print(int detailLevel, string fileName) - two parameters int Print(string reportTitle, int maxPages) - two different parameter types bool Print() - no parameters
and hence the Print method is said to be overloaded. Note that all five of the signatures differ in terms of their argument signatures:
The first takes a single string as an argument.
The second takes a single int.
The third takes two arguments—an int and a string.
The fourth takes two arguments—a string and an int (although these are the same parameter types as in the previous signature, they are in a different order).
The fifth takes no arguments at all.
So, all five of these headers represent valid, different methods, and all can coexist happily within the Student class without any complaints from the compiler! We can pick and choose among which of these five "flavors" of Print method we'd like a Student object to perform based on what form of message we send to a Student object:
Student s = new Student();
// Calling the version that takes a single string argument.
s.Print("output.rpt");
// Calling the version that takes a single int argument.
s.Print(2);
// Calling the version that takes two arguments, an int and a string.
s.Print(2, "output.rpt");
// etc.
The compiler is able to unambiguously match up which version of the Print method is being called in each instance based on the argument signatures.
This example also hints at why only the parameter types and their order, and neither the names of the parameters nor the return type of the method, are relevant when determining whether a new method can be added: because these latter aspects of a method aren't evident in a message. This is best illustrated with an example.
We already know that we can't, for example, introduce the following additional method as a sixth method of Student:
bool Print(int levelOfDetail)
because its argument signature—a single int—duplicates the argument signature of an existing method:
int Print(int detailLevel)
despite the fact that both the return type (bool vs. int) and the parameter names are different in the two headers.
Let's suppose for a moment that we were permitted to introduce the bool Print(int levelOfDetail) header as a sixth "flavor" of Print method for the Student class. If the compiler were to then see a message in client code of the form
s.Print(3);
it would be unable to sort out which of these two methods were to be invoked, because all we see in a message like this is (a) the method name and (b) the argument type (an integer literal in this case). So, to make life simple, the compiler prevents this type of ambiguity from arising by preventing classes from declaring methods with identical signatures in the first place.
Constructors, which as we learned in Chapter 4 are a special type of function member used to instantiate objects, are commonly overloaded. Here is an example of a class that provides several overloaded constructors:
public class Student
{
private string name;
private string ssn;
private int age;
// etc.
// Constructor #1.
public Student() {
// Assign default values to selected attributes, if desired.
ssn = "?";
// Those which aren't explicitly initialized in the constructor will
// automatically assume
// the zero-equivalent value for their respective type.
}
// Constructor #2.
public Student(string s) {
ssn = s;
}
// Constructor #3.
public Student(string s, string n, int i) {
ssn = s;
name = n;
age = i;
}
// etc. -- other methods omitted from this example
}
By providing different "flavors" of constructor, we've made this class more flexible by giving client code a variety of constructors to choose from.
The ability to overload method names allows us to create an entire family of similarly named methods that do essentially the same job, but which accept different types of arguments. Think back to Chapter 1 where we introduced the Write method, which is used to display printed output to the console. As it turns out, there is not one, but rather many Write methods; each one accepts a different argument type (Write(int), Write(string), Write(double), etc.). Using a single, overloaded Write method is much simpler and neater than having to use separate methods named WriteString, WriteInt, WriteDouble, and so on.
Note that there is no such thing as "attribute overloading"; that is, if a class tries to declare two attributes with the same name:
public class SomeClass
{
private string foo;
private int foo;
// etc.
the compiler will generate an error message:
SomeClass.cs(5,15): error CS0102: The class 'SomeClass' already contains a definition for 'foo'
So far, the inheritance hierarchies we've looked at are known informally as "single inheritance" hierarchies, because any particular class in the hierarchy may only have a single direct base class (immediate ancestor). In the hierarchy shown in Figure 5-9, for example,
Classes marked B, C, J, and I all have the single direct base class A;
D, E, and F have the single direct base B; and
G and H have the single direct base E.
If we for some reason find ourselves needing to meld together the characteristics of two different base classes to create a hybrid third class, multiple inheritance may seem to be the answer. With multiple (as opposed to single) inheritance, any given class in a class hierarchy is permitted to have two or more classes as immediate ancestors.
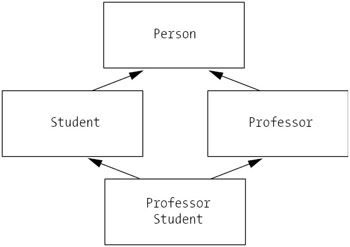
For example, we have a Professor class representing people who teach classes, and a Student class representing people who take classes. What might we do if we have a professor who wants to enroll in a class via the SRS? Or, a student—most likely a graduate student—who has been asked to teach an undergraduate-level course? In order to accurately represent either of these two people as objects, we would need to be able to combine the features of the Professor class with those of the Student class—a hybrid ProfessorStudent. This might be portrayed in our class hierarchy as shown in Figure 5-10.
On the surface, this seems quite handy. However, there are many complications inherent with multiple inheritance; so many, in fact, that the C# language designers chose not to support multiple inheritance. Instead, they've provided an alternative mechanism for handling the requirement of creating an object with a "split personality": that is, one that can behave like two or more different real-world entities. This mechanism involves the notion of interfaces, and will be explored in detail in Chapter 7. Therefore, if you're primarily interested in object concepts only as they pertain to the C# language, you may wish to skip the rest of this section. If, on the other hand, you're curious as to why multiple inheritance is so tricky, then please read on.
Here's the problem with what we've done in the previous example. We learned that, with inheritance, a derived class automatically inherits the attributes and methods of its base. What about when we have two or more direct base classes? If these base classes have no overlaps in terms of their attribute names or method signatures, then we are fine. But, what if the direct base classes in question
Have methods with the same signature, but with different code body implementations?
Have identical attributes (name and type the same)?
Have attributes with identical names, but with different types?
Let's explore these situations with a simple example.
First, say that we created a trivially simple Person class that declares one attribute, name, and one method, GetDescription, as shown here:
public class Person { string name; public virtual string GetDescription() { return name; // e.g., "John Doe" } }
Later on, we decide to specialize Person by creating two derived classes—Professor and Student—which each add a few attributes, as well as overriding the GetDescription method to take advantage of their newly added attributes, as follows:
public class Student : Person
{
// We add two attributes, major and id.
string major;
int id; // a unique Student ID number
// Override this method as inherited from Person.
public override string GetDescription() {
return name + " [" + major + "; " + id + "]";
// e.g., "Mary Smith [Math; 10273]"
}
}
public class Professor : Person
{
// We add two attributes, title and id.
// (Note that id has the same name, but a different
// data type, as the id attribute of Student.)
string title;
string id; // a unique Employee ID number
// Override this method as inherited from Person.
public override string GetDescription() {
return name + " [" + title + "; " + id + "]";
// e.g., "Harry Henderson [Chairman; A723]"
}
}
Note that both derived classes happen to have added an attribute named id but that in the case of the Student class, it's declared to be of type int and in Professor, of type string. Also, note that both classes have overridden the GetDescription method differently, to take advantage of each class's own unique attributes.
At some future point in the evolution of this system, we determine the need to represent a single object as both a Student and a Professor simultaneously, and so we create the hybrid class ProfessorStudent as a derived class of both Student and Professor. We don't particularly want to add any attributes or methods; we just want to meld together the characteristics of both base classes, so we'd ideally like to declare ProfessorStudent as follows:
// * * * Important Note: this is not permitted in C#!!! * * *
class ProfessorStudent : Professor and Student
{
// It's OK to leave a class body empty; the class itself is not
// really 'empty', because it inherits the features of its
// base classes.
}
But, we encounter several roadblocks to doing so.
First of all, we have an attribute name clash. If we were to simple-mindedly inherit all of the attributes of both Professor and Student, we'd wind up with the items shown in Table 5-1.
|
Attribute |
Notes |
|---|---|
|
string name; |
Inherited from Student, this in turn inherited it from Person. |
|
string ssn; |
Inherited from Student, this in turn inherited it from Person. |
|
string major; |
Inherited from Student. |
|
int id; |
Inherited from Student; this conflicts with the string id attribute inherited from Professor (the compiler won't allow both to coexist). |
|
string name; |
Inherited from Professor, which in turn inherited it from Person; a duplicate! The compiler won't allow this. |
|
string ssn; |
Inherited from Professor, which in turn inherited it from Person; another duplicate! The compiler won't allow this. |
|
string title; |
Inherited from Professor. |
|
string id; |
Inherited from Professor; this conflicts with the int id attribute inherited from Student (the compiler won't allow both to coexist). |
Making a compiler intelligent enough to automatically resolve and eliminate true duplicates, such as the second copy of the name and ssn attributes, wouldn't be too difficult a task; but, what about int id vs. string id? There's no way for the compiler to know which one to eliminate; and, indeed, we really shouldn't eliminate either, as they represent different information items. Our only choice would be to go back to either the Student class or the Professor class (or both) and rename their respective id attributes to be perhaps studentId and/or employeeId, to make it clear that the attributes represent different information items. Then, ProfessorStudent could inherit both without any problems. If we don't have control over the source code for at least one of these base classes, however, then we're in trouble.
Another problem we face is that the compiler will be confused as to which version of the GetDescription method we should inherit. Chances are that we'll want neither, because neither one takes full advantage of the other class's attributes; but even if we did wish to use one of the base class's versions of the method versus the other, we'd have to invent some way of informing the compiler of which one we wanted to inherit, or else we'd be forced to override GetDescription in the ProfessorStudent class.
This is just a simple example, but it nonetheless illustrates why multiple inheritance can be so cumbersome to take advantage of in an OO programming language.