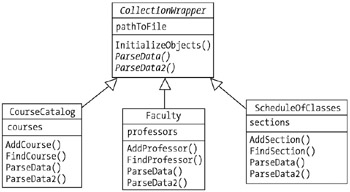
The UML diagram in Figure 15-4 illustrates the design approach that we're going to take with regard to populating the CourseCatalog, Faculty, and ScheduleOfClasses collections.
We'll first create an abstract base class called CollectionWrapper. CollectionWrapper will define a single attribute: namely, a string that holds onto the full path to the file that is currently being read, for example: C:\SRS\Faculty.dat.
CollectionWrapper will also prescribe three behaviors:
The ability to read a generic ASCII file using a combination of a StreamReader and a FileStream.
Two different flavors of "parse" methods to allow for the fact that at least two of the three subclasses will need to read two separate data files, as we've just discussed.
As we'll see in a moment, the InitializeObjects method will be a concrete method, whereas the ParseData and ParseData2 method signatures will be abstract.
The three derived classes will each extend this abstract class as follows:
They will each encapsulate a Collection of their own choosing:
The CourseCatalog class will call its collection courses, and will use it to store handles on Course objects as these are instantiated from the appropriate data file.
The Faculty class will call its collection professors, and will use it to store handles on Professor objects as these are instantiated from the appropriate data file.
The ScheduleOfClasses class already had a collection attribute as of the Chapter 14 version that we built, called sections, used to store handles on Section objects as these are instantiated from the appropriate data file.
They will all inherit the InitializeObjects method "as is," because it will be generic enough to handle routine file I/O.
They will all need to override the abstract ParseData and ParseData2 methods in order to provide concrete method bodies; otherwise, as we learned in Chapters 7 and 13, we wouldn't be able to instantiate these three classes.
We'll step through each of these four classes, reviewing significant aspects of their class structure and method logic. We encourage you, however, to download the full set of C# source files for all of these classes from the Apress web site (http://www.apress.com) if you haven't already done so; please refer to Appendix D for the instructions on how to do this.
Since we started out this discussion talking about the CollectionWrapper class, let's proceed with a discussion of its methods.
We'll declare a method called InitializeObjects that accepts a value for, and initializes, the pathToFile attribute (the file path is determined and handed in to this method from the client code, that is, from the SRS class's Main method). The purpose of this method will be to step through the data file of interest, processing its contents one record at a time until the end of the file is reached.
We'll present the full code of the method first, and then we'll talk through it in detail.
public bool InitializeObjects(string pathToFile, bool primary) {
this.pathToFile = pathToFile;
string line = null;
StreamReader srIn = null;
bool outcome = true;
try {
// Open the file.
srIn = new StreamReader(new FileStream(pathToFile, FileMode.Open));
line = srIn.ReadLine();
while (line != null) {
if (primary) {
ParseData(line);
}
else {
ParseData2(line);
}
line = srIn.ReadLine();
}
srIn.Close();
}
catch (FileNotFoundException f) {
outcome = false;
}
catch (IOException i) {
outcome = false;
}
return outcome;
}
The method expects two arguments; the second of these is a bool flag, to indicate whether we're going to read a primary file or a secondary file—in other words, whether we should invoke ParseData (primary == true) or ParseData2 (primary == false):
public bool InitializeObjects(string pathToFile, bool primary) {
After initializing a few temporary variables, we attempt to open the file with the technique of using a combination StreamReader/FileStream as discussed earlier in the chapter. Note that we must wrap this code in a try-catch block, because as mentioned earlier, there are many environmental issues that can pose problems when accessing a computer's file system (the file may not exist; it may exist, but be locked against the attempted access; etc.).
this.pathToFile = pathToFile; string line = null; StreamReader srIn = null; bool outcome = true; try { // Open the file. srIn = new StreamReader(new FileStream(pathToFile, FileMode.Open));
We use the ReadLine method of the StreamReader class to successively read in one line/record's worth of data at a time. The ReadLine method will set the value of string variable line to null as a signal when the end of the file has been reached, so we use a while loop to check for this condition. Within the while loop, we make a call to one of two "flavors" of Parse method—either ParseData or ParseData2— depending on whether the value of primary, passed in as an argument when the InitializeObjects method was called, is set to true or false. We'll talk about what the ParseData and ParseData2 methods need to do shortly.
line = srIn.ReadLine();
while (line != null) {
if (primary) {
ParseData(line);
}
else {
ParseData2(line);
}
line = srIn.ReadLine();
}
After the end of file has been reached, the while loop will automatically terminate. We then close the StreamReader (which closes the FileStream, which closes the file itself) with the command
srIn.close();
}
Our error handling in this example isn't very sophisticated! We simply print out an error message, then set the outcome flag to false to signal that something went wrong, so that we may return this news to whatever client code invoked the InitializeObjects method in the first place. In an industrial-strength application with a GUI, for example, we might pop up a window containing a more elaborate error message; we might record such an error in an error log file; or we might have some alternative means of recovering "gracefully." (An exercise at the end of Chapter 16 will request that you enhance error handling for the GUI version of the SRS application.)
catch (FileNotFoundException f) { Console.WriteLine("FILE NOT FOUND: " + pathToFile); outcome = false; } catch (IOException i) { Console.WriteLine("IO EXCEPTION: " + pathToFile); outcome = false; }
Finally, we return a true/false status just prior to exiting. Note that outcome was initialized to the value true when this method first started, and will still have a true value unless something went wrong that in turn caused one of the catch blocks to execute.
return outcome; }
Now, back to the ParseData and ParseData2 methods. What do these methods need to do in order to process a record from a data file? Generally speaking, for each record, we'll need to
Break apart the record along tab-separated boundaries.
Call one or more constructor(s) to construct the appropriate object(s) whose attributes have been parsed from the record.
Create links between objects, if appropriate.
Finally, insert the newly created object(s) into the appropriate encapsulated collection.
The details of how these steps take place will differ widely from one data file to the next, however:
In the case of the CourseCatalog.dat file, for example, we need to break each record into three different values—two string values and a double numeric value—along tab boundaries. Then, we'll use those values as inputs to the Course class constructor. Finally, we'll insert the newly created Course object into the courses collection, an attribute of the CourseCatalog class.
We'll then read a second file—Prerequisites.dat—to determine how the various Courses that we've created are to be linked together to represent prerequisite interdependencies.
For the Faculty.dat file, we need to break each record into four different string values. Then, we'll use those values to construct a Professor object. Finally, we'll insert the newly created Professor object into the professors collection of the Faculty class.
We'll then read a second file—TeachingAssignments.dat—to determine how Professor objects should be linked to the Section objects that they are assigned to teach, and vice versa.
and so forth for the remaining files. Since we can't easily write a universal parsing method that can handle all of the different permutations and combinations of record formats and desired outcomes, we'll instead declare two abstract methods with the following signatures:
public abstract void ParseData(string line); public abstract void ParseData2(string line);
and leave the job of working out the details of these two methods' respective behaviors to the various classes that extend the abstract CollectionWrapper class. Let's tackle these classes next.