Most experienced developers are already familiar with SourceSafe's primary features: check-ins/check-outs, change histories, and branching. But not everyone is aware of all the creative ways to use these tools, especially when debugging and patching customer issues. Let's examine some of the most powerful SourceSafe debugging features.
If your code worked fine one day and failed the next, wouldn't your first thought be to ask what changed? Software follows the exact same set of steps every time it's run. It doesn't wear out, and it doesn't stop working without a reason. It only stops working when something changes, and the key to fixing the problem is to figure out exactly what that change was. Server administrators see this all the time—one day a server is working, the next day it's not. What changed? Did someone reset the password of an access account? Did someone alter the application settings? One of my company's best-selling products solves this problem by monitoring all changes on a server and notifying the administrator about any "unusual" changes. When the server breaks, the administrator knows exactly where to look.
The same change-centric approach works when debugging many types of bugs, too. Visual SourceSafe provides two tools for monitoring these changes: file diffs, which compare two versions of a file and highlight any differences, and change histories, which list the dates of each code change along with a descriptive comment and the name of the person who made the change. It's difficult to overestimate how valuable these tools are to developing and debugging.
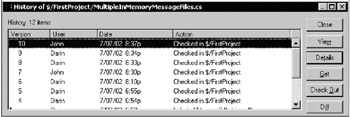
There's an unfortunately serious usability glitch in SourceSafe's change history that can make it difficult to rollback versions. SourceSafe displays the change history screen with a set of buttons on the right-hand side. Those buttons represent the options you can perform from this screen, as you can see in Figure 10-3.
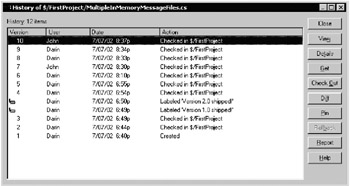
Notice there's no Rollback option on that list. New users may conclude that SourceSafe doesn't support rollbacks. Actually, the option is there, but you can't see it by default. Even though this window provides no indication that it's resizable, you need to resize it to display additional options. Move the mouse to the lower right-hand corner of the window, grab the corner, and expand the window. You'll then see additional options, including Rollback, as shown in Figure 10-4.
This problem is easily worked around once you know the trick, but is initially very confusing.
One common mistake developers make is to fetch mismatched sets of files. Say your project has 30 source files in it, and your coworkers modified 6 of those files since you last fetched the source. Even though you don't have the latest version of those 6 files, you do have a complete, matched set of the old files. Now suppose you check one of those modified files out—that implicitly fetches the latest version of that file, so now you have 1 new file and 29 old ones. Maybe this is OK if all the changes your coworkers made to that file were self-contained. But what if some of the changes to that file depend on changes made to the other new files that you haven't yet fetched?
A coworker of mine decided to move some error handling in one file to a different function in a second file. His change made our code much cleaner. But without even realizing it, I fetched the new version of the file where he removed the error handling, yet I didn't fetch the new version of the other file where he added it. The net result was that the version on my machine no longer had error handling anywhere, and all kinds of bugs therefore popped up when I ran the program. I wasted the next half hour debugging a problem that only existed because I had a mismatched set of files!
VS .NET has an option to avoid this issue, and every developer should turn it on. Go to the Tools menu and select Options ![]() Source Control. Enable the "Get everything when a solution is opened" checkbox. From then on, each time you open a project, VS .NET will ask if you want it to automatically fetch the latest version of every source file in your project. That way, each time you open your project, you can be sure you have the latest version of all files.
Source Control. Enable the "Get everything when a solution is opened" checkbox. From then on, each time you open a project, VS .NET will ask if you want it to automatically fetch the latest version of every source file in your project. That way, each time you open your project, you can be sure you have the latest version of all files.
Some programs "auto-correct" your words as soon as you type them. Microsoft Word, for instance, will automatically replace :-) with ![]() . I once implemented a similar feature on one of my programs. But a few weeks later, the feature was no longer working. Now, code doesn't just stop working for no reason—something must have changed. I had written all the code for this feature in a single file, so I immediately checked the change history, and sure enough, a coworker had made some changes. A quick diff of the before and after versions revealed the coworker had accidentally erased my function, so all I had to do was copy the deleted code from the old version into the new, and then everything worked again. I had the bug fixed with 5 minutes of first reading the PR.
. I once implemented a similar feature on one of my programs. But a few weeks later, the feature was no longer working. Now, code doesn't just stop working for no reason—something must have changed. I had written all the code for this feature in a single file, so I immediately checked the change history, and sure enough, a coworker had made some changes. A quick diff of the before and after versions revealed the coworker had accidentally erased my function, so all I had to do was copy the deleted code from the old version into the new, and then everything worked again. I had the bug fixed with 5 minutes of first reading the PR.
| Caution |
Make sure the clock on your computer is accurate. Source-Safe relies on the last modified timestamps of your files to determine whether you have the latest version. My coworker had incorrectly set the date on his computer, and was therefore able to accidentally overwrite my changes. |
I always feel a sense of accomplishment whenever I'm able to quickly solve a bug without even launching the debugger at all. The debugger requires you to patiently step over code and pay attention to details and generally use brain cells. But in this case, the diff utility literally highlighted the answer in bright red, without my having to show the least bit of concentration. Unfortunately, not every bug can be solved by viewing the change histories—only bugs that suddenly appeared one day when something changed. Still, change histories and file diffs are extremely powerful debugging aids in those situations, and those situations come up more often than you might think.
Have you ever unknowingly fixed a bug by side effect? Suppose a customer reports a bug in your 1.0 version after you've already begun work on the next version. You're unable to reproduce the bug with your latest code, but you find the bug reproduces easily with 1.0. Yet no one on your team ever knowingly fixed this issue, so where did the bug go? Usually, this means you fixed some other bug that took care of the customer's issue by side effect. If the customer demands a fix and the new version isn't ready yet, then you may need to give the customer a hotfix. If the changes between the two versions weren't too drastic, use the change histories of the relevant files to figure out when the bug disappeared. This may be easier than debugging the issue from scratch.
Another time, I had a similar situation where the product worked fine one day and was broken the next, but this time I had no idea which file contained the problem. SourceSafe can display a list of every file that changed within a specified date range, and based on the comments associated with those changes, I eliminated all but two files. I couldn't see anything wrong with either file, but since I knew it had to be the problem, I set a breakpoint on those two sections, debugged, and found the issue. Change histories might not always completely solve the bug, but they can at least narrow done your search to a very small area.
| Tip |
Unfortunately, SourceSafe uses modal dialog boxes for its change histories. You can see all the files that were changed in a project, but you can't see what specifically was changed in a particular file without first closing that change history window. To get around this annoyance, launch two instances of SourceSafe. Use one to see a list of all the changed files, and use the other to look at the change history of each of those files. |
The more often you work with change histories, the more opportunities you'll see to use them. Early in my career, I was asked to fix the memory leaks in a large C program. There were a billion places where the program leaked memory allocated by certain APIs, so I spent an entire day fixing them all… and a week later, I realized I'd misread the API documentation and in some of those billion places, not freeing the memory was the correct thing to do. I realized I'd have to reexamine each of my billion changes and undo many of them—but there had been so many that I risked missing one if I weren't careful. So I used the change histories to find all the files modified by me on that particular day—armed with that list, I knew exactly which files I had changed, and then I was able to review each change one by one.
In the final days before shipping, you should declare a "code freeze" where the code will not be modified except for major, showstopper bugs. This surprises many developers: "If a minor bug is easy to fix, why not do it?" The problem is that any code modifications risk introducing new bugs, bugs possibly even worse than the one you're fixing. I've seen cases where simply changing the text of an error message exposed a crashing bug that had lain dormant before. Now, that's rare—usually, you can make last-minute bug fixes with no problems. But sooner or later, a last-minute fix will make things far worse than they were before, and why run that risk just to fix a minor bug? So in the week or two before shipping, don't change the code for any reason except very, very major bugs.
Easier said than done. Until they've been personally burned by a last-minute fix, developers won't accept that logic. So many times, I've seen developers say, "Well, this tiny change can't possibly hurt anything" and then check in the change despite the code freeze. Project leaders need ways to prevent this, and change histories are a great first step. Right-clicking a project and selecting View history will show all the check-ins that occurred in a specified time period, along with the names of the responsible individuals. (SourceSafe can also output the information to a text file.)
During a code freeze, there should be few enough fixes each day that the leader can personally examine each one to make sure no one is sneaking in unauthorized changes. Often, the mere knowledge that this is being done is enough to send a message to the developers that code freezes are serious business and should not be violated.
And if the developers still don't follow the code freeze policies, then during the last week before shipping, you can set the permissions in SourceSafe to prevent check-ins from anyone but the lead developers. That way, you can be certain no one will add any unapproved changes. To change the SourceSafe permissions, use the SourceSafe Administrator tool. Of course, after the code freeze is over, don't forget to restore the permissions so the developers can start checking in code again!
Sometimes, the change history can answer your questions even when it contains no information at all. One of my products included a binary file from a third-party company, and we wanted to make sure we were shipping the latest version of the file. For uninteresting reasons, the usual methods for discovering file version didn't work here, so we checked the file history and saw that the last change was over a year ago. That didn't tell us what the version was, but at least it told us what the version wasn't—we knew we couldn't possibly be using the latest version since the timestamp in SourceSafe was too old.
The date of the change can sometimes be as interesting as the change itself. For example, if an employee was fired on the morning of January 21, you'd probably be very interested in reviewing any code changes she made later that same day—who knows if she might feel vengeful and deliberately introduce new bugs. The change histories can show you what changes he made. All in all, the more often you work with change histories, the more opportunities you'll see to use them.
Obviously, change histories work best when the developers are careful to always write descriptive comments for each check-in. Even without check-in comments, change histories would still be useful because you could use file diffs to see what happened with each check-in. But good check-in comments make it that much easier. Rather than having to study every single check-in, you can tell by the comments that some of the check-ins are clearly irrelevant to the issue you're investigating.
| Caution |
I can't emphasize enough how important it is to ALWAYS write a comment when checking in files. SourceSafe allows you to leave the comment field blank, so beginner developers often do. But for the change history to be useful, you must be able to quickly scan the list and see what each change was for. Blank comments ruin everything. Never, ever check in a file without a comment. |
A good check-in comment doesn't have to be long—a sentence or two is plenty. The important thing is that if you're viewing the change history with a specific bug in mind, you should be able to read each check-in comment and quickly tell whether that check-in might be relevant. If you're looking for a crash that occurs during program startup, for example, and if you happen to know that the PrintPage function is never called during startup, then you can probably ignore any check-ins with the comments "Fixed ___ with the PrintPage function". Of course, sometimes, things aren't clear-cut: "Improved performance of Foo function by doing ____" may or may not be relevant to the crash in startup. Better view the file diff just in case.
Disciplined, process-oriented teams often follow another convention when writing check-in comments. Even with good comments, more information is often needed when reading change histories. "Fixed a crash under low memory conditions" may be an acceptable check-in comment—but 6 months later, you might be curious as to exactly what the specific repro steps of the bug were. You could list those details in your check-in comments, but then the comments become much too long to skim.
That's why it's handy to mention a relevant PR with each check-in. Your defect tracking system is the central repository for all details about every bug, so why not cross-reference it with your check-ins? Most tracking systems automatically assign each PR a unique ID number, and it's good practice to note that number in your check-in comment: "PR #6832: Fixed a bug with blah blah blah". This is the best of both worlds: The comment is succinct enough for quick browsing in a change history, yet identifies exactly where to go for more information.
In Chapter 2, we talked about stepping over all new code in a debugger before checking it in because the debugger will help you view your code from a new perspective. It'll help you notice errors you didn't see when writing the code. This same rationale applies to another policy experienced developers employ—never check code in without first diffing the changes against the version that's currently stored in SourceSafe. Seeing the before and after code side-by-side is a new perspective that makes many bugs stand out.
| Note |
To diff your checked-out version against the version in SourceSafe, right-click the file in VS .NET and select Compare Versions. Or, you can compare the files directly from the check-in window. |
When you're checking in a file, are you certain you remember exactly what changes you made? Are you sure you remembered to remove that debugging-only test code you wrote? In addition to the primary change, did you also make some other minor change that needs to be mentioned on the check-in comment, too? Diffing your changes against the SourceSafe version gives you one last chance to verify your code before committing to the official source tree. If your organization requires code reviews by a second developer before checking in code, then the diff makes a great starting point for the review, because the second developer can focus only on what changed.
There's one final reason to always do a diff before check-in. SourceSafe is only as good as the people using it. If someone changes the dates of his computer or edits a source file without properly checking it out, or breaks the rules in any other way, then SourceSafe could potentially overwrite someone else's changes. Before checking in any code, do a diff to make sure that no block of code is inexplicably missing due to an overwrite. If code is missing, then manually merge the files to make sure you don't lose someone else's hard work.
Branching is another often-misunderstood feature of source control systems. It can be used for more situations than may at first seem apparent. Branching means splitting a project's code into two different copies so that you can work on one without affecting the other. Not everyone immediately sees the use for this—shouldn't you keep just one version of the code around and continuously improve it with whatever changes are necessary? In an ideal world, yes, but in the real world, that's not always possible. There are many situations where branches are necessary, but some of the most common are
Preparing hotfixes for an earlier version
Developing multiple versions at once
Making experimental changes
After shipping version 1.0 of a project, most teams take a brief break to recuperate and then usually begin work on the next version. By the time 1.0 obtains widespread deployment among customers, the main line code branch may have already undergone drastic changes in preparation for 2.0. Now what happens when customers report bugs in 1.0? What do you do? You can fix those bugs in the main line code branch, but that code is undergoing major changes for the next version and won't be ready to ship for quite some time. Yet your customers are demanding a bug fix for 1.0 now, so how should you address that?
One solution is to use SourceSafe to fetch the labeled 1.0 version of the code (you did label the code used to build 1.0, right?), fix the bug, and prepare a new build. But what do you do with your fixed 1.0 code now? You can't check it in because you don't want to overwrite the 2.0 code. On the other hand, if you don't check it in, then you'll lose this fix and the next time a customer reports a different bug, you'll fix the new bug but accidentally undo the fix for this first one.
We need a way to check in our bug fixes to version 1.0 without overwriting the new code in 2.0. What we need is an independent 1.0 branch that we can modify separately from the 2.0 branch.
Try to develop only one version of a project at a time. Try not to write versions 1.1 and 2.0 simultaneously. But you won't always be successful. Sometimes, most of your team will finish their work on schedule but a few individuals will fall behind on one area. What should the rest of the team do while those few individuals strive to finish? Some of the idle developers may be able to assist their slower teammates, but after a certain point, adding additional developers to a problem makes things run slower, not faster. So you can't assign all of the idle developers to the project.
It may be that the best option for those developers is to begin work on the next version. Sometimes, a last-minute spec change may complicate matters even further: I've been in situations where my team was simultaneously developing the next three versions, in addition to hotfixing the currently shipping version! Good teams will make every effort to avoid this situation, but it will sometimes happen anyway.
How should the 2.0 developers check in their code when the 1.1 developers aren't yet finished? Any changes checked in to the main line branch by the 2.0 team would appear in the 1.1 build, which is highly troublesome. There is no good way to deal with this situation, but the least bad solution is to create a separate branch for 2.0 development. The 1.1 team can continue to make their changes while the 2.0 team moves ahead. Once 1.1 is completed, then all those changes will be merged into the 2.0 branch to ensure that it has all the bug fixes of the previous version.
| Tip |
As projects get larger and have more and more branches, you may find yourself needing to locate a particular file and not knowing where it is. SourceSafe supports a wildcard search feature for finding all versions of a file that match certain criteria. Explore the options on the Search menu—in the right situations, they can be lifesavers. |
Shortly after shipping a release, my team discovered a rare but serious bug. We realized we might need to create a hotfix, but on the other hand, the bug occurred only under very rare conditions that we weren't even sure existed in the real world. So maybe we wouldn't have to bother with the hotfix. We agreed to make a decision 3 days later at the meeting of the product core team. Since there was nothing else I could do about the bug until then, I began working on a different issue and I assigned some other PRs to one of my developers.
I was very surprised by his reaction—he felt he couldn't check in fixes for those PRs because we needed to first make a decision about the hotfix and branch off the code if necessary. He reasoned that if he checked in his new fixes now, then there would be no way to build the hotfix without the new changes. He conceded that we could create a hotfix branch now and then fix our new bugs in the mainline branch, but what if we then decided to abandon the hotfix? We'd have a useless branch and that would be bad. Therefore, he couldn't work on those PRs until after the meeting.
Now it is true that there's not a "clean" way to handle this situation, but claiming that we would have to sit on our hands doing nothing for 3 days is ludicrous. Go ahead and create that branch—if it doesn't get used then just delete it and no harm is done. Or forget the branch and just check in your fixes on the main code base—if necessary, you can build the hotfix by fetching a past version of the file. When the only alternative is to waste time, then constructing the hotfix by manually merging one version of a file on top of another would still be preferable.
Don't be afraid to get your hands dirty with SourceSafe branches. Handling situations like this may get messy, but containing that messiness in an organized fashion is what SourceSafe is for.
When your team starts thinking about making major architecture changes, it's usually a good idea to prototype an experimental branch first. Architectural improvements often don't work out as well as planned, so try to make it easy to throw away the changes if needed. Maybe the plan is to add complicated multi-threading to improve performance, but midway through the implementation, a code profiler proves your changes will never be able to provide more than very minor performance gains. Lucky thing you discovered this early rather than investing further weeks of work! Back out those changes since the gains aren't worth the increased complexity and development time.
But suppose that experimental change took you and a couple teammates a week or two. What happened to the product in the meantime? Did the rest of the team ignore their PRs waiting for you to finish these major changes before checking their bug fixes in? It's not acceptable to make them do nothing while you work on experimental changes that might be aborted anyway. However, if they're checking code in while you are too, then you may end up having to rollback your changes, which would unfortunately rollback their bug fixes, too.
All in all, it's best to branch the code and do your experimental changes parallel to their normal bug fixing work. If you decide to abort your changes, then no one lost anything by branching because you can just delete the experimental branch. And if you decide to keep your experimental changes, then it's true you'll have to merge their fixes into your branch, but tools exist to help you with that. In any case, merging two branches is certainly better than letting half your team sit around idle for weeks on end.
My team was in that situation recently. We had a VB .NET application that we wanted to convert to a Windows service. The code wasn't structured to facilitate this, so the change was estimated at a couple months. There was a high degree of risk involved and our ship date was set in stone, so we knew there was a large chance this change would be cut if it started falling behind schedule. That would require rolling back the code to the original state. But we also had several other important features we needed to add and we couldn't afford to wait until half the team finished re-architecting the service code. We needed to be able to work on both sets of changes at once. The only realistic option we had was to branch the code and work on both branches simultaneously until we were certain the service changes would be accepted.
Earlier, we discussed the virtues of code freezes: Don't make unnecessary changes in the days before shipping. But what if you share common code with another team that isn't in code freeze? Suppose the other team feels it needs to add new features to this common code at precisely the moment when you don't want any changes made to your code at all. How can you best handle this situation? You want to allow the other team to make changes to the common code, yet you want to be sure that you're fetching the same version you've always known and trusted.
A pure branch isn't the best solution for this situation. Branching the common code would prevent the code from changing when you want it to remain static, but eventually your code freeze will be lifted and you'll want the new versions of the common code. It is possible to merge the two branches back into one, but there's an easier way. Use SourceSafe's pin command so that your team automatically fetches the pinned version while the other team continues to make changes. When your code freeze is over, just unpin the files and then your team will automatically get the latest version.
To pin files, first share the files as if you were going to branch them. But rather than branching, bring up the change history dialog box, point to the label of the files that you want, and click the Pin button. No matter what the other team does, your team will see only that version of the files until you make the conscious decision to unpin the files and fetch the new version.
The one problem with branching files is that it results in two versions of code that both need to be maintained. Bugs fixed in one branch will need to be fixed in the other branch as well, and that quickly gets tedious. You can work on parallel code branches for a while, but you should always have an "exit strategy" for eventually returning to a single branch.
One exit strategy is to let one branch gradually die as it becomes unnecessary. For instance, after shipping version 1.0, you split the code into a branch for holding hotfixes on top of 1.0 and another branch for going forward with the next version. At first, you'll fix many bugs in the 1.0 branch, and you'll port those fixes to the other branch as well. But eventually, all the crucial bugs in 1.0 will be fixed (or at least deferred until the next version) and you'll make fewer and fewer changes to that branch until it dies off. Then you're back to working on only a single branch again.
The other popular exit strategy is more powerful, but more work. Sometimes you create two branches and let them drift apart for a while, but always with the expectation that the branches will eventually be reunited. Under this approach, you can fix bugs in one branch without making the corresponding fix in the other branch, because you'll pick up those fixes automatically when the branches reunite. This strategy works best for parallel development of two active branches, such as when half the team is making experimental changes. The reunification process is called a merge, and it's not nearly as scary as you probably think.
| Note |
A third exit strategy is when you expect the two branches to drift apart so much that they're no longer related and require separate maintenance teams anyway. This usually happens when one team wants to maintain the code as is but another team wants to make major changes. Each team will maintain its own branch, and since the branches have become so different, there's no point in the teams communicating their changes since those changes would be incompatible with each other. |
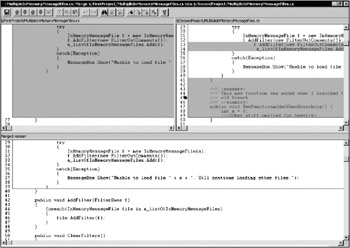
Merging two files by hand is annoying, so Visual SourceSafe includes a tool for automatic merging. Figure 10-5 shows what the merge tool looks like: The two file versions are shown side-by-side with differences highlighted, and the lower half of the screen is dedicated to SourceSafe's best guess about how the changes should be combined. If the two files contain unrelated changes (one adds a new function, the other changes some code in another function), then SourceSafe's best guess is usually very good. The only problem comes when both branches modify the same few lines of code—in that scenario, SourceSafe won't be sure which change to accept. But then the merge tool will notify you of the conflict and help you manually merge that section.
But be careful when merging. Never trust SourceSafe 100 percent to automatically merge your branches—you should always view the file diff of the two versions to be certain that the appropriate changes were picked up. Merging is an inherently risky proposition, so stay alert during the process. But the alternative to merging involves losses of productivity, so the risk is worthwhile. Just be careful, and everything will turn out fine.
A good source control system like Visual SourceSafe is essential for any development organization. Source control will enforce good software development processes, saving your bacon time and again. But even more than that, source control can serve as an excellent tool for finding and fixing bugs. Learn to love SourceSafe (or some other tool like it)—it's one of the most useful tools a developer has.