As already mentioned, Microsoft first introduced Microsoft Cluster Service in Windows NT 4.0 Enterprise edition, but then changed the name to Microsoft Cluster Server (but left the acronym the same—MSCS). Since then many enhancements have been made to this product.
In a cluster the individual servers are referred to as nodes. This service helps primarily in solving the availability problem. A cluster service works by having two or more nodes in its cluster. If one node fails, the other (or others) takes over.
Windows 2000 servers can provide up to a four-node cluster in the Datacenter Server, whereas the .NET Server 2003 can host up to eight nodes.
The cluster represents itself on the network as a single server and is often called a virtual server. The cluster provides access for its clients to different resources like file shares, printers, or other services.
The servers in a cluster are connected physically as well as programmatically and can coordinate their communication when a client requests a service. The cluster provides a high degree of availability for its clients because each participating cluster server can supply redundant operations should a hardware or application failure occur.
The collection of components on each node that perform cluster activities is referred to as Cluster Service. The components, be it software or hardware components, that are managed by Cluster Service are called resources. A resource can be a physical hardware device such as a disk drive or network card as well as a logical item like an application, application database, or IP address.
We consider a resource to be online when it is available and providing service to the cluster. Resources have the following characteristics:
They can be owned by only one node at a time.
They can be managed in a server cluster.
They can be taken offline and brought online.
In Cluster Service, each server owns and manages its own local devices. Common devices in a cluster, like disk arrays and connection media, are selectively owned and managed by a single server at any given time. This way of referring to how a cluster manages and uses its local and cluster common devices and resources is called a shared-nothing cluster architecture.
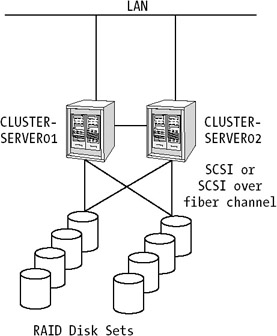
Figure 3-6 illustrates how a two-node cluster can be organized.
The cluster servers communicate with common external disk arrays by using a Small Computer System Interface (SCSI), or SCSI over fiber channel. While each server hosts and manages its own copy of the service provided by the cluster, common resources like files can be placed on a common disk array external to the cluster.
To better understand how this can be helpful, imagine a two-node database cluster. If each server has its own local copy of the database files, constant replication would be necessary to keep both copies an exact replica of the other. To avoid this, the database and its transaction log files are placed on external disk arrays, providing fault tolerance by using different RAID levels. The database server, however, still runs on each node; only the database files are placed on the common disk array. Because only one database exists when a failover occurs (one node fails and the other takes over), the database is not compromised in any way.
In the Windows Server 2003 family, it is also possible to configure a cluster on disparate places. This means you can deploy a cluster with eight nodes in two separate places with four nodes at each place. If an entire building vanishes, the application can still continue to work. We will include more about this Chapter 8.
Cluster Service can detect a software or hardware failure. When it does, it quickly assigns the responsibility of the application or service to another node in the cluster. This process is called failover. After the failing node has been fixed, it can come back online again. This is called failback.
If you need to upgrade the cluster—for example, when you want to apply a new operating system service pack or an upgrade to the service the cluster provides—you can easily do this. What you do is manually move the network service that the cluster is providing to another node. This procedure makes sure that client requests will not be interrupted during the upgrade. After the upgrade, you move the service back and take the node online again.
The failover procedure reduces single points of failure on the network and thereby provides a higher level of availability. But keep in mind that Cluster Service alone cannot guarantee server uptime; you need other maintenance and backup plans, too. But this is a great tool in helping administrators keep services up and running.
Cluster Service makes life easier for system administrators in other ways, too. One thing it does is provide a single point of control (remember, this is a good thing) for administration. Administrators can manage all devices and resources in the cluster as easily as if they had all been on one server. If necessary, administration can also be performed remotely.
And because administrators can take resources offline manually, they can perform maintenance and upgrades without interrupting the service. This is also good for the clients, as they still can access the resources they need without being disturbed in their work.
So when do you preferably use Cluster Service then? Well, one usage has already been mentioned. When you have an important database that needs to be available almost every second of the day, Cluster Service is a great tool to enhance availability. Imagine the chaos if medical records were only sporadically accessible to hospital staff due to a faulty database. You can also imagine the rage of bank customers if they could not withdraw their money when they need to, or access their Web-based bank services when they want to.
Another scenario where Cluster Service is useful is keeping e-mail services online. Microsoft Exchange Server works great on a Cluster Service. The concept is the same as for the database described previously.
| Note |
But keep in mind that Cluster Service is not the perfect technique for enhancing scalability. Other techniques exist to help you there. You have already taken a look at NLB earlier in this chapter, but there are others too, as this book will show. |