Design patterns represent solutions to problems arising when developing applications within a particular context. Patterns represent a reuse of successful software architectures and designs. Patterns are often language independent, in contrast to a framework, which is an implementation of many different patterns. Patterns are a solution to common problems in a specific context. A framework, on the other hand, is an implementation of many patterns that functions as a reusable, "semicomplete" application. The last step is to develop class libraries containing "fully completed" classes that you can plug into your applications.
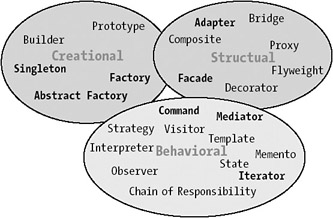
We divide the different patterns on the market today into three types: creational patterns, structural patterns, and behavioral patterns. The creational patterns deal with creation, initialization/deinitialization, and configuration of classes and objects.
The structural patterns take care of the structural issues, such as interface implementation between classes. The behavioral patterns describe how you handle dynamic interactions between classes and objects. Figure 5-8 shows some of the most well-known patterns divided into these three categories.
The bold patterns in Figure 5-8 are the ones used in the enterprise architecture presented in this chapter. We will, however, briefly describe all of the patterns in the figure and tell you roughly what they are intended to solve. We will start with the creational patterns that you use to solve creation-related problems in your enterprise application. Secondly, we will look at the structural patterns that help keep an structure easy to maintain and exchangeable. Finally, we will look at the behavioral patterns that help you with different behaviors you want your enterprise application to perform.
| Note |
For more information about design patterns, we recommend Design Patterns: Elements of Reusable Object-Oriented Software by Eric Gamma et al. (Addison-Wesley, 1995. ISBN: 0-201-63361-2.). |
In this section, we will describe the creational patterns that solve creation-related problems in your enterprise application: the Abstract Factory, Factory Method, Singleton, Prototype, and Builder patterns.
The function of the Abstract Factory is to provide a creation interface for related objects. The Factory Method is the "concrete factory" that actually creates the object. For example, our enterprise application in Chapter 9 needs to be able to work with different data providers. For instance, we need to be able to create an Oracle connection if we want the application to work with an Oracle database. We also need to be able to create a SQL Server connection if we want to work with Microsoft's SQL Server. However, we do not want to have to use different codes depending on which data provider we are using. The Abstract Factory simplifies the interface for the data access component by grouping all these different create methods within a single class. In Chapter 9, you will see the Abstract Factory pattern in action together with the Factory Method to ensure that our example enterprise application can easily switch between different data providers.
This is the pattern that serves as the "Concrete Factory" to the Abstract Factory pattern, and it defines an interface for creating an object. The Factory Method itself does not create the class, but passes the creation of the object down to subclasses. This pattern is also known as a Virtual Constructor pattern.
Instead of creating an object directly, you ask the Factory Method class to create the object for you. By doing so, you do not need to know how you create the specific object. The strength of this approach is that you can easily switch between related classes without changing the code that uses the class, as long as the different classes that the Factory Method returns to you support a known interface. The Factory Method in turn lets subclasses decide which class to instantiate. The Factory Method lets a class defer instantiation to subclasses. For example, in a data access layer, you can use the Factory Method pattern together with the Abstract Factory pattern to create data connections and data commands. For example, instead of creating a SQL Server connection directly in the data access component, you ask the createConnection method (Factory Method) to create an IdbConnection interface of type SQL Server. The createConnection method creates the connection and returns it via the interface IdbConnection. By using this abstraction, the data access component does not need to know how to create a database connection.
The Singleton pattern is used to ensure that only one instance of an object exists, and that you have a global point of access to it. Sometimes it is important to be sure that you have only one instance of a class and that instance is accessible throughout the system. The Singleton pattern solves this by making the class itself responsible for keeping track of its own instance.
A Prototype is a factory for cloning new instances from a prototype. This pattern is useful when a system should be independent of how its products are created, composed, and represented, and when the classes are instantiated at runtime.
This pattern can also be used when you want to avoid building class hierarchies of factories that parallel the class hierarchy of products.
A Builder separates the construction of complex objects from their representation so the construction process can be used to create different representations. All you need to do as a user of the Builder class is feed it with types that should be built and the content. This is a pattern for step-by-step creation of a complex object so that the same construction process can create different representations. The methods that are used for constructing complex objects are put together into a single class called a Director. This Director class is responsible for knowing how to create the complex objects.
The Builder pattern is similar to the Abstract Factory. The main difference between them is that when an Abstract Factory class method creates its own object, the client of the Builder class instructs the Builder class on how to create the object and then asks it for the result. How the class is put together is up to the Builder class.
Structural patterns focus on how classes and objects are constructed to work together in larger structures. Rather than composing interfaces or implementations, structural patterns describe ways to compose objects to realize new functionality.
The Adapter pattern is intended to provide a way for a client to use an object whose interface is different from the one expected by the client.
This pattern is suitable for solving issues such as the following: You want to replace one class with another and the interfaces do not match, or you want to create a class that can interact with other classes without knowing their interfaces at design time.
Let's take a look at an example: A client wants to make a specific request of an object (MyObject). This is normally accomplished by creating an instance of MyObject and invoking the requested method. In this case, however, the client cannot do so because the interfaces do not match. The client is working with an interface named IClient and MyObject has an interface named IMyObject. The Adapter pattern helps you address this incompatibility by providing classes that are responsible for redefining the interface and data types on the client's behalf. What the pattern does is actually work as a translator between the client and MyObject. To achieve this, you create a custom Adapter class that defines methods using the interface IClient, which the client expects. Also, the Adapter class subclasses the MyObject class, and provides an implementation of the client requests in terms that the MyObject expects. Adapter overrides the method and provides the correct interface for MyObject. By using the Adapter pattern, you do not need to modify the client to be able to talk to the MyObject class via the interface.
Adapter is a structural pattern, and you can use it to react to changes in class interfaces as your system evolves, or you can proactively use the Adapter pattern to build systems that anticipate changing structural details.
The Bridge pattern is used for the abstraction of binding one of many implementations to a class. Normally, an interface inheritance is tightly bound to the class that has implemented the interface. When you implement an interface, the class then needs to implement all methods and properties in the interface. This is the conventional way to reuse an interface, but sometimes you will want to do stuff that you cannot do with traditional inheritance. The Bridge pattern breaks the direct and permanent link between the interface and the class that implements the interface, which results in plug-and-play functionality for either the interface or the class that implements the interface. This can give you serious trouble if you are not using it the right way, but if you can control it (and know what you are doing), the main benefits of using the Bridge pattern instead of a traditional interface implementation are as follows:
You can implement only parts of interfaces.
You can provide an implementation that is not restricted to only one class module.
You can assign an implementation to an object at runtime.
You can easily modify, extend, or replace an interface during the Application Management (AM) phase without needing to mirror all the changes to the interface wherever the interface is implemented.
The Composite pattern is intended to allow you to compose tree structures to represent whole-part hierarchies, so that clients can treat individual objects and compositions of objects uniformly. Tree structures are often built where some nodes are containers of other nodes, and other nodes are "leaves." Instead of creating a separate client code to manage each type of node, the Composite pattern lets a client work with either, using the same code.
A Decorator pattern extends an object transparently and makes it possible to add extra functionality without having access to the source code.
Extending an object can be done with inheritance and subclassing the object. This is, however, sometimes impractical, and the Decorator pattern is intended to give you an alternative way to extend the behavior of an object, without needing to create a new subclass. By using the Decorator pattern, you can easily add behaviors to specific instances of objects, which is difficult to do if you subclass your components directly. Examples of Decorators are the custom attributes in .NET. The attributes you will be using for your serviced components, like object pooling, are actually Decorators to classes—they extend the classes' behavior.
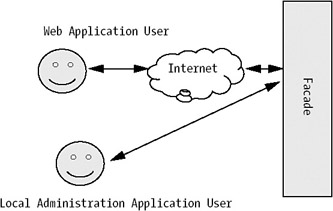
The Facade pattern simplifies the interface for a subsystem and decouples the client from the underlying subsystem. With the many classes and subsystems you use in the enterprise application, it is important to isolate the different layers and reduce coupling. The Facade pattern is intended to provide this via a unified interface to a set of interfaces in a subsystem. The facade defines a higher-level interface that makes the subsystems easier to use. There are several benefits to using Facade patterns. First, this pattern provides developers with a common interface to the underlying layers in the enterprise application, leading to more uniform code. Since the Facade object controls access to the underlying layers, the underlying system is isolated and provides a layer of protection from complexities in your subsystems as they evolve. This protection makes it easier to replace one subsystem with another because the dependencies are isolated. This pattern is used in the enterprise architecture illustrated in this chapter.
Many fine-grained objects can be shared in an efficient way by using the Flyweight pattern. The Flyweight pattern maintains the state of fine-grained objects internally or retrieves the state for the objects from the outside when they should be used.
This pattern is useful for situations in which you have a small number of different objects that might be needed a large number of times—with slightly different data that can be externalized outside those objects. The Flyweight pattern is intended to enable sharing to support large numbers of fine-grained objects more efficiently and reduce resource usage. The pattern references the intrinsic data of an object that makes it unique and extrinsic data that gets passed in as parameters. This pattern is useful for applications in which you may need to display icons to represent folders or some other object and do not want to add the overhead of creating new icons for each individual folder.
One object approximates another. Smart proxies represent an implementation of the Proxy pattern, and you use these when you are creating distributed applications in which the calls will pass many address spaces so that performance can be kept at a high level. An implementation of a smart proxy is actually a wrapper around the object you want to use that organizes write and read operations from the real object in an effective way.
Behavioral patterns mainly focus on describing and solving complex communications between objects. The behavioral patterns are designed to take care of difficult control flows through the application and let you focus on the way objects are connected instead of on the flow of control between different objects. In this section, we will discuss what we consider to be the most important behavioral patterns.
The Chain of Responsibility pattern is very useful when you want a workflow for the incoming requests that x number of objects should be part of. The idea with this pattern is to decouple the sender from the receiver(s). This pattern is useful for help and print functionality in your enterprise application, because the call will be raised higher and higher until a handler is found for the particular action.
The Command pattern is intended to encapsulate a request as an object. For example, consider a Windows application with menu items that need to make requests of objects responsible for the user interface. The client responds to input from the user clicking a menu item by creating a Command object and passing this object to an Invoker object, which then takes the appropriate action. The menu item itself makes the request to the invoker without knowing anything about what action will take place. By using this pattern, you are able to later change the action of the clicked menu item without changing the client itself. Practical uses for the Command pattern are for creating the mentioned dynamic menus, toolkits for applications, queues and stacks for supporting undo operations, configuration changes, and so on.
The Interpreter pattern is a language interpreter for a defined grammar that uses the representation to interpret sentences in the language. This pattern is useful in search queries, for instance. Instead of defining complex algorithms, you define a grammar that the user can use (AND/OR queries). Then you define a language interpreter that will interpret the sentences the user is writing.
The Iterator pattern provides a client with a way to access the elements of an aggregate object sequentially, without having to know the underlying representation. An Iterator pattern also provides you with a way to define special Iterator classes that perform unique processing and return only specific elements of the data collection without bloating the interface with operations for the different traversals. The Iterator pattern is especially useful because it provides the client with a common interface so the caller does not need to know anything about the underlying data structure.
Applications with many classes tend to become fragile, as communication between them becomes more complex. The more classes know about each other, the more they are tied together, and the more difficult it becomes to change the software. The Mediator pattern is intended to define an object that encapsulates how a set of objects interacts. This pattern promotes loose coupling by keeping objects from referring to each other explicitly, and lets you vary their interaction independently.
Client code often needs to record the current state of an object without being interested in the actual data values (for example, supporting checkpoint and undo operations). To support this behavior, you can have the object record its internal data in a helper class called Memento. The client code uses the Memento object for storing its current state, and restoring the previous state of the client is done by passing the Memento object back to the client object. The Memento object supports the client object with functionality to store its internal state, and it does this by violating encapsulation without making the object itself responsible for this capability.
The Observer pattern is useful when you need to present data in several different forms at once. This pattern is intended to provide you with a means to define a one-to-many dependency between objects, so when one object changes state, all its dependents are notified and updated automatically. The object containing the data is separated from the objects that display the data, and the display objects observe changes in that data.
This pattern is also know as the Publish-Subscribe pattern and is used frequently in SQL Server and also between components in Component Services, allowing such components to subscribe to events and publish events to each other.
The State pattern is useful when you want to have an object change its behavior depending on its internal state. To the client, it appears as though the object has changed its class. The benefit of the State pattern is that state-specific logic is localized in classes that represent that state.
The Strategy pattern is very useful for situations in which you would like to dynamically swap the algorithms used in an application. If you think of an algorithm as a strategy for accomplishing some task, you can begin to imagine ways to use this pattern. The Strategy pattern is intended to provide you with a means to define a family of algorithms, encapsulate each one as an object, and make them interchangeable. Strategy lets the algorithms vary independently from clients that use them.
The Template Method is a simple pattern. You have an abstract class that is the base class of a hierarchy, and the behavior common to all objects in the hierarchy is implemented in the abstract class. Other details are left to the individual subclasses. The Template Method pattern is basically a formalism of the idea of defining an algorithm in a class, but leaving some of the details to be implemented in subclasses. Another way to think of the Template Method pattern is that it allows you to define a skeleton of an algorithm in an operation and defer some of the steps to subclasses. Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm's structure.
The Visitor pattern uses an external class to act on data in other classes. This is a useful approach when you have a polymorphic operation that cannot reside in the class hierarchy. This pattern is also a useful way to extend the behavior of a class hierarchy, without the need to alter existing classes or to implement the new behavior in every subclass that requires it.
Phew! We just covered a lot of patterns, and even more exist on the market.
All enterprise applications have problems that will recur. All of them also require many steps to complete their tasks; therefore we will show you how to use patterns in your enterprise applications to make them stable and robust and changeable. Later in this chapter and in the next one, we demonstrate how to implement some of these patterns.
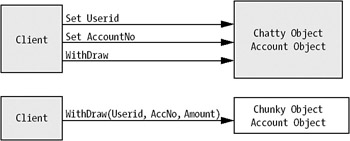
The architecture pattern and the framework we will describe here have many parts in common with the patterns from Sten and Per Sundblad. Their architecture has a common rule for all layers: Keep chunky calls rather than chatty ones. This is something we highly agree with because it results in less overhead between calls in layers, especially when the different layers are in different processes. (For more information about architectures for other kinds of application, please visit Sten and Per's homepage at http://www.2xSundblad.com.)
Here we will look at an enterprise application pattern. The enterprise architecture is based on chunky interfaces, which means that a call to an object is returning a chunk of data. This kind of approach is sometimes called services-based architecture, and is not as resource intensive as a chatty interface. A chunky interface returns chunks of information back to the caller, whereas a chatty interface follows a more traditional object model in that you have objects with properties you can read and set. A chatty interface is more resource- and time-consuming than a chunky one because each call to the object results in a round-trip to the server, and possibly to each layer in the application. See Figure 5-9 for a chatty- and a chunky-designed object.
The architecture we are describing here is based on the chunky approach. In all communication where functions are returning data (more than a single value), datasets are used as the carriers. Figure 5-10 shows an overview of the enterprise architecture and the different building bricks you should use to achieve a flexible and scalable architecture for an enterprise application.
The following sections describe the layers for this architecture.
The layer closest to the end user is the UI layer. This layer contains UI controls to handle interactions with the user. Here is where all the Web controls in a Web application will be located. These controls take care of rendering the data to suit the client. They also take care of validating the input from the user, such as checking for valid dates in a date field. The rule is to catch data errors as soon as possible, and this layer helps to do so.
The next layer, the facade layer, has mainly two purposes for the enterprise architecture:
The first is to encapsulate and isolate the business layers for the clients. By making clients independent of the internal structure in your application, you can change the internal structure in the future as long as you are keeping the same interface via your Facade classes to your clients.
The second is that the Facade class acts as a guardian for the application. It should authenticate all users who are calling the Facade methods in the application. When a facade has granted access to a user, the rest of the application should be able to trust the facade calls. We recommend that when you are designing an enterprise application with many different roles, try to keep the different roles and their methods in different Facade objects. This setup is easier to maintain.
One of the most difficult tasks when designing Facade classes for an application is to specify how many Facade classes you will have and what functionality should be put in into each of them. A good rule when deciding how many Facade classes an application should have is that every use case generates one Facade class. Each Facade class then exposes methods that cover all the actions the actors on the use case require. This is not always true, however; sometimes the same Facade class is used for several use cases and sometimes a use case employs many different facades. The latter scenario is one you should avoid, since it messes up the internal structure and makes it more difficult to maintain the application in the future.
The Facade class can either be a traditional class or a class that has been enabled for use as a Web service facade. We believe that all Facade classes should be developed in a Web service project in .NET to ensure that you can easily switch on the Web service support for a particular method by adding an attribute to it. By adding the Webmethod attribute, you are still able to call the method as a standard call and also able to call the method as a Web service, as shown in Figure 5-11. This makes it easier to scale out the application to meet future needs with as little impact as possible.
Even if you know that an incoming request is validated and granted by the facade layer (all incoming calls pass a facade layer), you often need to apply business rules to the request to decide if it is a valid action from a business perspective. The business layer contains code for verifying business rules and taking action with them.
Handling transactions in an easy and secure way is of high importance in enterprise applications. An enterprise application deals with data that is important to a particular company, and it would be dreadful if data integrity is jeopardized by lack of transaction support. .NET supports transactions via .NET Enterprise Services, which in turn uses COM+. Transaction support is also started here if the requested method requires it. You separate transaction-related business rules from the other business rules and place them in their own classes to ease the maintenance. It is also crucial that all starts and stops of transactions are collected in the business layer. Transaction support on classes managed as .NET Enterprise Services should only be enabled when necessary because it is a performance hit. Figure 5-12 shows the dataflow in the business layer.
Closest of the layers to the data is the data access layer. This layer contains functions that are doing the fetching and storing in the database. Data passing in .NET can mostly be done in two ways: by using data readers as data carriers between the layers and the client, or through datasets. The difference between these techniques from a performance point of view is not so big, but of importance from a scalable and distributed point of view. The data reader is marshaled by reference. The actual data is not returned to the caller; instead a reference to the data reader is returned. Each time the client moves forward in the data, a request is sent back to the server. You can easily imagine how this would slow performance on the network between the client and server or between the application layers.
The dataset, on the other hand, is marshaled by value. The data is returned to the client based on XML. This makes it more suitable for distributed applications and also fit to be used for Web services. We strongly recommend using only datasets for transporting data between the client and the server. You should also use datasets between the different layers, even if you have installed all layers on one machine initially. You never know when you need to scale out an enterprise application on more machines and thereby introduce cross-process problems, which will give you performance hits if you were using data readers between the layers. This will be true when you need to separate the different layers due to security reasons—for instance, placing the Web server in the DMZ and the application layer and data layer on the inside, as you see in Figure 5-13.
The data layer contains data access components that are based on an abstract database class that makes it easy (or at least easier) to switch between different database providers. The abstraction from the specific calls that are for SQL Server or Oracle does not matter for your data access components in the data access layer. They are working towards the same data factory. In our example in Chapter 9, you will see that we have database classes for SQL Server and how we can switch easily to a database class for Oracle. The database class for SQL Server will use stored procedures in the data source layer, whereas our database class for Oracle will use plain SQL strings. Since the base classes are quite easy to exchange, we can later implement a class for using MySQL, or some other database engine.
| Note |
The performance of exchangeable data access components versus vendor fixed data access components has a price. If you try to keep the data access components exchangeable to use different data source providers, you cannot for instance use stored procedures in the data source layer to achieve better performance compared to plain SQL queries. Instead, you need to write the code that does the retrieval and storing of data from the data source layer as plain SQL to be able to more easily switch between different providers. |
With the architecture of the enterprise application as we have outlined it in this chapter, you will be able to start with all layers on the same machine, with the possibility to scale the application by adding extra servers to the cluster (see Chapter 4, which discusses the different techniques to scale an enterprise application). If the need arises for placing different layers on different machines, you can easily do so.