We have been working with SQL Server since version 6.5 or so. Back then, we would never have suggested to a customer that they should use SQL Server in a business-critical application. SQL Server has fortunately grown since then, and with the 2000 edition, it has become one of our most commonly suggested applications to customers these days. We cannot wait for the next version to come out, as it looks very promising on paper.
SQL Server still has a reputation to fight against, however. A lot of people think it cannot perform as well as many of its competitors. That is not true if it is configured correctly, and if it is deployed on a good platform.
| Tip |
For those interested in SQL Server performance, check out http://www.tpc.org to see the latest test results and database system configurations. |
SQL Server's ease of use has also been an issue over time. The general misconception has been that something that is easy to use with a graphical user interface is as worthless as a Steven Seagal movie. This in effect has led many companies to give someone like a department secretary the responsibility of setting up and managing a SQL Server, while the database administrator handles an Oracle database or the like. Now we do not intend any disrespect to the secretary, but this is not a good solution, since getting great performance out of SQL Server requires the skills of a trained and experienced database administrator.
Many database administrators have not had an interest in working with SQL Server because it is so easy to use and not much configuration has to be done once it is set up. Setting up a new SQL Server takes a good deal of planning, however, and knowledge about how to do it the right way.
Fortunately, much of this attitude has changed, and nowadays trained IT staff handle most SQL Servers in enterprises.
Several versions of SQL Server are available. To help you choose the most suitable for your solution, we will present an overview of the different versions and their intended use in the following sections.
SQL Server, like Windows Server, comes in various editions to suit a large number of uses:
SQL Server 2000 Enterprise Edition
SQL Server 2000 Enterprise Edition (64-bit)
SQL Server 2000 Standard Edition
SQL Server 2000 Developer Edition
SQL Server 2000 Personal Edition
SQL Server 2000 Desktop Engine (MSDE)
SQL Server 2000 Windows CE Edition (SQL Server CE)
We will explore each edition and see what its intended use is. As you learn about each edition, you will soon see that now you actually do have a version for your department secretary, another for your developers, and others for your database administrators. Now you do not have to compromise—you can have the database you need for every occasion. Let us start with a look at the Enterprise Edition.
SQL Server 2000 Enterprise Edition is the top-of-the-line of SQL Server. It includes all features that SQL Server offers. The Enterprise Edition comes in both 32-bit and 64-bit versions, so you can use it on most hardware available. This edition includes tools that let you not only store data, but also extract and analyze it.
SQL Server 2000 Enterprise Edition is a suitable solution for large Web sites, Online Transaction Processing (OLTP) systems, and data warehouses. Good platforms for running the Enterprise Edition are Windows Server 2003 Datacenter and Windows 2000 Server Datacenter. You should definitely let an experienced database administrator handle this edition.
SQL Server 2000 Standard Edition includes the core functionality of SQL Server. It does not include all the advanced tools that the Enterprise Edition does, but it does have some great tools that let you analyze data, too.
The Standard Edition is intended for small and medium-sized organizations. Recommended platforms include Windows Server 2003 Enterprise Edition and Windows Server 2003 Standard Edition, and the equivalent Windows 2000 Server Editions. We still recommend an experienced database administrator for handling this edition, however.
Basically, SQL Server 2000 Developer Edition is the Enterprise Edition in disguise. It is intended for developers to use when new applications and solutions are developed. By offering all the features of SQL Server, a developer can use it to develop all kinds of applications. It also includes licenses and download rights for the CE Edition, just to make everything SQL Server has to offer available at a reasonable price.
Most companies have mobile users, such as salespeople, who on their business trips need to have large sets of data available. SQL Server 2000 Personal Edition is the ideal choice to install on a laptop, for it lets users sync data with the company database when they are at the office.
| Note |
The Personal Edition is only available with the Enterprise and Standard Editions. It is not available separately. |
The Personal Edition can also be of use for the department secretary (you knew this was coming) when he or she requires an application that needs to store data on a local database. It does not offer the scalability and flexibility of the previously mentioned editions, but it is nevertheless a great tool in some cases.
The Desktop Engine is a redistributable version of the SQL Server Database Engine (MSDE). It is not available separately. On the Enterprise, Standard, and Developer Edition CD-ROMs it is included in the MSDE catalog in the root directory. Developers can include it with their applications when local data is needed and requiring a stand-alone database would be overkill.
| Tip |
Check http://www.microsoft.com/sql/ for more information about obtaining MSDE, and the licensing issues that may come with it. There you will find all the information you need about the various SQL Server editions. |
If you need to, you can use SQL Server Enterprise Manager to access the Desktop edition, and this way get a graphical user interface to it. Otherwise, this edition does not include any GUI.
SQL Server 2000 CE Edition is intended for use on PDAs and other Windows CE devices. It has a small footprint to enable it to run smoothly on these devices, but it still provides tools that let you store data on a Pocket PC, for instance. It also includes APIs so you can develop applications for your Windows CE devices that use a full-fledged SQL Server as a data store, instead of flat files or any other solution.
Table 8-1 shows the system requirements of the various SQL Server Editions.
|
Edition |
Operating System |
Scalability |
|---|---|---|
|
Enterprise Edition (64-bit) |
Windows Server 2003 Enterprise Edition; Windows Server 2003 Datacenter Edition |
Max 64 CPUs, max 512GB RAM, max 1,048,516TB database size |
|
Enterprise Edition (32-bit) |
Windows Server 2003 Standard Edition, Enterprise Edition, Datacenter Edition; Windows 2000 Server, Advanced Server, Datacenter Server; Windows NT 4.0 Server, Enterprise Edition |
Max 32 CPUs, max 64GB RAM, max 1,048,516TB database size |
|
Standard Edition |
Windows Server 2003 Standard Edition, Enterprise Edition, Datacenter Edition; Windows 2000 Server, Advanced Server, Datacenter Server; Windows NT 4.0 Server, Enterprise Edition |
Max 4 CPUs, max 2GB RAM, max 1,048,516TB database size |
|
Developer Edition |
Windows Server 2003 Standard Edition, Enterprise Edition, Datacenter Edition; Windows XP Professional; Windows 2000 Professional; Windows 2000 Server, Advanced Server, Datacenter Server; Windows NT 4.0 Server, Enterprise Edition |
Max 32 CPUs, max 64GB RAM, max 1,048,516TB database size |
|
Personal Edition |
Windows Server 2003 Standard Edition, Enterprise Edition, Datacenter Edition; Windows XP Professional; Windows 2000 Professional; Windows 2000 Server, Advanced Server, Datacenter Server; Windows NT 4.0 Server, Enterprise Edition |
Max 2 CPUs, max 2GB RAM, max 1,048,516TB database size |
|
Desktop Engine |
Windows Server 2003 Standard Edition, Enterprise Edition, Datacenter Edition; Windows XP Professional; Windows 2000 Professional; Windows 2000 Server, Advanced Server, Datacenter Server; Windows NT 4.0 Server, Enterprise Edition |
Max 2 CPUs, max 2GB RAM, max 2GB database size |
|
Windows Edition CE |
Windows CE 2.11 or later, Handheld PC Pro (H/PC Pro), Palm-size PC (P/PC), Pocket PC |
Max 1 CPU, max 2GB database size |
We have already mentioned that SQL Server is quite easy to use, but this can also be one of its drawbacks when it comes to people's perceptions of this product. As long as you understand what it does and when it behaves in a wrong way, we argue that there is no value in having to tune a database server manually when you can let the built-in logic do it. You want your database administrators and IT staff spending time on other stuff, like designing, planning, and deploying applications. Obviously such staff would still need to provide maintenance and surveillance of your existing SQL Server system; if it behaves strangely, they must have the knowledge to troubleshoot it. This should not be their main occupation, however. A database that requires IT staff to spend hours and hours just to get it up and running takes too much time from the IT staffs' other tasks.
To get a better understanding of SQL Server, we will outline its architecture in the following sections.
Memory management is one of the things that in SQL Server requires little or no manual work, at least not in most cases. SQL Server by default dynamically allocates and deallocates memory as needed. This way SQL Server itself optimizes memory for best performance, based on the amount of physical memory it has to work with.
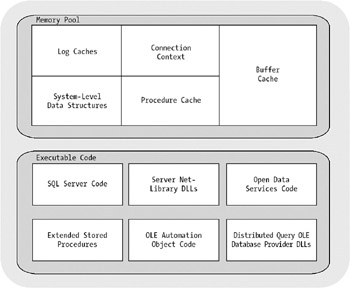
SQL Server uses the virtual memory in Windows for two main components (see Figure 8-5):
The memory pool
Executable code
The memory pool is an area of memory from which some objects allocate their memory. These components are as follows:
System-level data structures: These hold data that is global to the SQL Server instance, such as database descriptors and the lock table.
Buffer cache: This cache stores data and index pages read from a database. If these items need to be accessed again, they can be found in the cache, which speeds up processing.
Procedure cache: This holds the execution plans so that they can be reused for stored procedures and Transact-SQL statements.
Log cache: The log cache is used to hold pages that are read from and written to the log. Each database has one log cache.
Connection context: This constitutes a set of data structures that keeps a record of the current state of a connection.
Determined by the number of user requests, the size of the memory pool varies, simply because the objects within it vary in size. When a new database is defined, the different data structures are allocated. The same goes for when a table or view is referenced.
The buffer cache, log cache, and procedure cache are constantly managed and adjusted by SQL Server to optimize performance so it fits the current workload. So if the procedure cache needs to have more memory, SQL Server dynamically increases the whole memory pool size. It does so by allocating more memory from the physical memory. If no more physical memory exists, it tries to resize the other objects in the memory pool.
You can control the size of the memory pool by setting minimum and maximum values for it. You do not need to control the size of the objects within the memory pool, as SQL Server handles this best alone.
The executable code is more or less the SQL Server engine. It includes the code for the engine itself, as well as the DLLs and executables for Open Data Services and Net-Libraries.
Let us take a closer look at the buffer cache, since this is an important part of SQL Server. The buffer cache consists of a number of memory pages that are initially free when SQL Server starts up. When SQL Server starts reading a page from disk, this page is stored in the first page of the buffer cache's free list. When this page is read or modified by the same process or another, it is read from the cache instead of from disk. This reduces the amount of physical I/O required for the operation, and performance increases.
A page that has been modified in the buffer cache but not yet written to disk is called a dirty page. Whether a page is dirty or not is written to each buffer page's header information. A reference counter also resides in the header, which is incremented and decremented with each reference to the page. The buffer cache is scanned periodically, and if a page has been referenced less than three times since the last scan and is not dirty, the page is considered to be free. It is then added to the free list, which we talked about in Chapter 4. If the page is dirty, the modifications are written to disk first. This work is done by the worker processes of SQL Server.
To prevent the free list from being too small, a worker process called the lazywriter periodically checks to see that the free list does not fall below a certain size. The size depends on the size of the buffer cache. If the free list is becoming too small, the lazywriter scans the cache and reclaims unused pages and pages that have a reference counter set to zero.
| Note |
The lazywriter is mostly used in very I/O-intense systems, because the other threads can handle these tasks on less heavily used systems. |
To allow the buffer cache to have as much memory as possible, you should see to it that your system has enough physical memory (RAM) for the task it performs. Memory is cheap these days, so this does not have to be too expensive even for small companies.
As we have mentioned, SQL Server dynamically adjusts the memory for the memory pool. It not only allocates memory for its parts, but it also deallocates memory if other applications need it. But it only deallocates memory if another process asks for it; otherwise it maintains memory at the current size.
The virtual memory SQL Server uses is maintained at 5MB less than the available physical memory. This stops excessive memory swapping to disk, while still giving SQL Server the largest memory pool possible. SQL Server always tries to keep 5MB of free physical memory on the system by deallocating memory from its pool, if another process tries to access these megabytes.
To make sure SQL Server always has a certain minimum memory pool, you can set the min server memory option so SQL Server does not release memory less than this value. The min server memory option is always set in megabytes.
You can also set the max server memory option so that SQL Server does not steal too much memory from other applications running on the server.
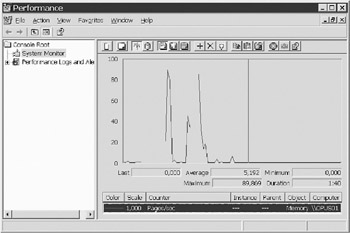
Carefully use these options so that no application (including SQL Server) starts any excessive swapping. You can keep an eye on this by using the Performance MMC (see Figure 8-6) and the Pages/sec counter of the memory object. This counter shows the paging on the system. A value between 0 and 100 is considered normal.
The best approach is to let SQL Server handle memory usage and not to set the manual options. This is especially true when only SQL Server runs on the machine. When you have other applications running, you might need to manually configure these settings, however. With all the consolidation going on these days, it is not unlikely that SQL Server has to share room with other applications, so it could be nice to know these options are available. The following code shows how to set these values from Transact-SQL:
sp_configure 'show advanced options', 1 go sp_configure 'min server memory', 256 go RECONFIGURE WITHOUT OVERRIDE go
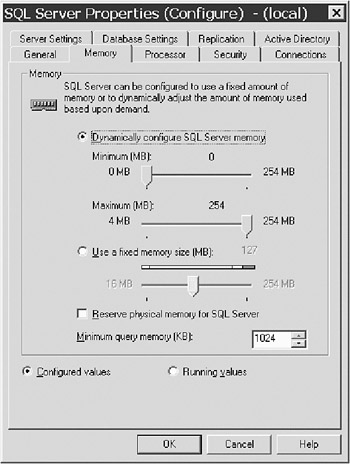
You can also set minimum and maximum memory values from Enterprise Manager if you want to, as shown in Figure 8-7.
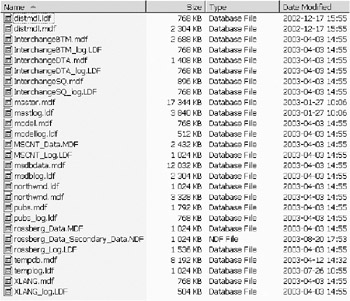
No database manager would be of any value if you did not store your data somewhere. SQL Server stores its data in a set of operating system files. Each file is made up of smaller parts called pages. There are three kinds of files that SQL Server uses (see Figure 8-8):
Primary data files
Secondary data files
Log files
Primary data files contain different database information like startup information for the database, pointers to the other files of the database, system tables, and objects. These files can also contain database data and objects. There is one primary data file for every database, and the file extension through which you can identify this file is .mdf.
Secondary data files, which sport the extension .ndf, are an option for every database. You do not need to have one of these, but can instead use the primary data file if you want. Secondary data files hold data and objects that are not in the primary file. Here we find tables and indexes. The reason you might want to use secondary files is that you can spread the data on separate disks, thereby improving I/O performance.
Log files are files that hold all the information about the transactions in the database, and they cannot be used to hold any other data. You can have one or more log files (like the ones shown in Figure 8-8 with an extension of .ldf), but our recommendation is to use one only. This is because the log file is written to sequentially, and hence does not benefit from being separated on several physical disks. To enhance performance, you should instead try to use RAID 1+0, and place the log file on such hardware.
One important thing to understand about the log file is that it actually consists of several files, regardless of whether you use only one or not. These files are called virtual log files (VLFs) and are created by SQL Server (see Figure 8-9). Of these virtual log files, only one is active at a time. When a backup of the log is performed, all inactive VLFs are cleared. The active VLF is never cleared, so contrary to what you might have been told, a log backup does not clear the whole log. But do not worry, this is not a problem.
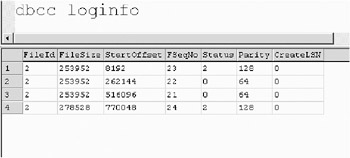
If you have too many VLFs, the overhead of maintaining them can degrade performance. To view how many VLFs exist in your databases, you could use an undocumented DBCC command, which returns as many rows as there are VLFs in the database. Execute DBCC LOGINFO and have a look at how your database appears. In Figure 8-10, we have run DBCC LOGINFO against the Northwind database on our system. As you can see, a total of four VLFs exist in our database.
To reduce the number of VLFs, you should perform frequent log backups. You also do not want to forget to shrink the log file through the command DBCC SHRINKFILE (logfilename, truncateonly), otherwise the number of VLFs will not be reduced.
When designing a log file, you should make a good estimate for the size of the log file and create it with that size. If auto-growth is enabled on a small log file, new VLFs are created every time the log is increased. So it is important to make it as close to the size you will need as possible.
A simple database might only hold a primary data file and a log file. A more complex and larger database, on the other hand, often consists of secondary files and more log files as well.
By building filegroups, you can create your secondary data files in these groups for data placement purposes. When you create your database, you specify in which filegroup you want to place your database objects. This way, you can have control of where you place your objects, since you also know on which disk the filegroups are placed. You can even create a table or other object across multiple filegroups to increase performance. (This obviously is true only when the filegroups are created on separate disks.)
To better understand this, imagine a database that has two tables, Table_A and Table_B. The database also has two RAID disk arrays, as you can see in Figure 8-11. Table_A is constantly accessed sequentially with read-only requests, whereas Table_B is accessed only occasionally with write requests (perhaps only once every minute or so).
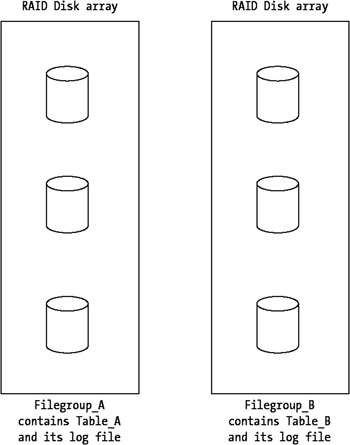
In this scenario, it would be great for performance to place a filegroup on each disk array and then place each table in separate filegroups. This way you separate the heavily accessed table from the less accessed one, which improves performance. If one of the disk arrays had more disks than the other, you should also place the read-only table on that array, because doing so also improves read performance.
If some of your disks are too heavily accessed despite this, you could create only one filegroup and place it on both disk arrays. You then place both tables on this filegroup, which spreads I/O on both arrays. Table data will be written to both disk arrays, because the filegroup spans the two.
Since the best way to optimize disk I/O is to distribute your data on as many disks as possible, you should consider this during the physical design phase (as you will see later in the section "Physical Design"). By using filegroups, we can even further distribute I/O evenly, because when the data is written to a table on a filegroup that spans many disks, the data is spread in proportion across all the files in the filegroup.
You can use three kinds of filegroups:
Primary filegroups
User-defined filegroups
Default filegroups
The primary filegroup contains the primary data file. It also contains all the files not specifically put into another filegroup. All system tables are always placed on the primary filegroup. The primary data file must also always be placed in the primary filegroup.
User-defined filegroups are the filegroups you create yourself. The default filegroup is where all tables and indexes are placed if not specifically put in another filegroup. The primary filegroup is the default filegroup, if you do not specify otherwise. You can, if you want, switch the default filegroup with the ALTER DATABASE command in Transact-SQL.
Another benefit of using filegroups is that you can perform backups on separate filegroups independently of each other. You can also restore them separately. This can speed up backup and restore operations considerably.
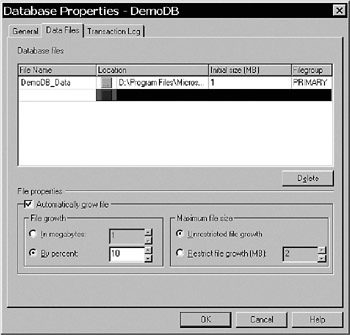
A cool feature of SQL Server is that you do not have to expand the files manually when they run out of space. SQL Server handles this by itself, if you specify this when creating the file (see Figure 8-12).
As you can see, you need to do some planning before you set these options, but with a little careful thinking, it will prove to be a great help for you.
If you have a database accessed by many users or applications, you need an option to prevent the same data from being modified by two or more processes at the same time. By using locks, you can make sure a process has a dependency on a resource, and as a result have access rights to it. This means other processes cannot modify the resource until the first process releases the lock. Locking ensures that multiple users can read and write to the same database without getting inconsistent data and without overwriting each other's modifications by accident. All locks are managed on a per–SQL Server connection basis.
| Tip |
If you want to learn more about SQL Server and the way it handles locks, please see the document "Understanding Locking in SQL Server" at the following URL: http://msdn.microsoft.com/library/default.asp?url=/library/en-us/acdata/ac_8_con_7a_7xde.asp. |
Different levels of locks can be used with SQL Server. They vary in granularity from the finest, which is the Row Identifier (RID) lock, to the coarsest, which is the database lock. Table 8-2 describes the locks from the coarsest to the finest. The finer the lock, the more concurrency among users you have.
|
Lock Type |
Description |
|---|---|
|
Database |
Simply locks the entire database. No other user is allowed in the database. |
|
Table |
Locks a table, including indexes. |
|
Extent |
Locks a 64KB unit. An extent is a contiguous group of eight pages. |
|
Page |
A page is 8KB and a page lock locks 8KB. |
|
Key |
This is a row lock in an index. |
|
RID (Row Identifier) |
Locks a single row in a table. |
| Note |
The finer the lock you use, the more overhead you need to maintain it. So consider carefully the kind of lock to use. |
There are also different kinds of locks you can use. SQL Server uses six different kinds of modes, as you see in Table 8-3.
|
Mode |
Description |
|---|---|
|
Shared |
Used for read-only operations |
|
Exclusive |
Used when modifying data |
|
Update |
Used on updatable resources |
|
Intent |
Used to establish a locking hierarchy |
|
Schema |
Used for instance when modifying tables or the schema |
|
Bulk update |
Used for bulk-copying data into a table |
Luckily, you do not have to consider which mode to use since SQL Server does this for you. It chooses the most cost-effective lock for the current operation.
Now we have come to the final part of the SQL Server architecture—threads. SQL Server 2000 uses Windows threads and fibers to execute tasks. We have covered threads earlier (in the section "Threads" in Chapter 4), but the fiber concept is new. Before we take a look at fibers, you will need to understand the concept of context switching and why this occurs. When SQL Server does not use fibers, it uses threads. These are distributed evenly across the available CPUs on the system. If you want, you can specify which CPUs SQL Server should use, but in most cases SQL Server handles this better than you can. When one thread is moved off a CPU and another is moved on, a context switch occurs. This is a very performance-costly operation, since the switch is between user mode and kernel mode (we covered this switching process earlier in Chapter 4). To get the most out of your system, you should minimize context switching, and fibers is one way of doing this.
A fiber is a subcomponent of a thread, and is something you must enable for your SQL Server to use. Fibers are handled by code running in user mode. This means that switching fibers, and thereby switching tasks, is not as costly as switching threads. The reason for this is that the switch does not occur from user to kernel mode, but instead takes place in only one mode.
As opposed to threads, fibers are handled by SQL Server and not by the operating system. One thread is allocated per CPU available to SQL Server, and one fiber is allocated per concurrent user command. There can be many fibers on one thread, and fibers can also be switched on the thread. During the switch, the thread still remains on the same CPU, so no context switch occurs. By reducing the number of context switches, performance is increased.
| Note |
Use fibers only if the server has four or more CPUs, and only use them when the system has more than 5000 context switches per second. |
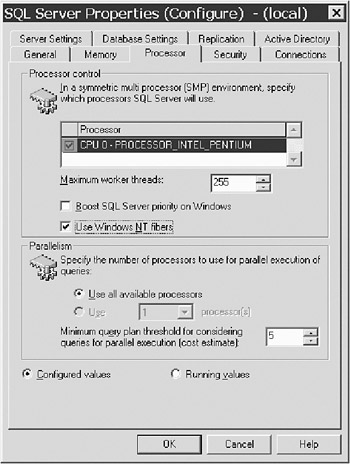
You can use SQL Server Enterprise Manager to enable fiber mode (see Figure 8-13), or you can run sp_configure to set the lightweight pooling option to 1.
SQL Server keeps a pool of threads or fibers for all user connections. These threads or fibers are called worker processes. You can limit the number of worker processes by setting a maximum value for this. When this value is reached, SQL Server begins thread pooling. As long as the maximum worker process value has not been reached, SQL Server starts a new thread for the user commands, but as soon as the limit is reached and thread pooling has begun, each new request has to wait for a thread to be available. You should not set the maximum value too high (default is 255) because the more worker processes you have, the more resources are consumed. This eventually affects performance. Experiment with it in the lab, and find the best setting for your system.