Now that you know how the internals of SQL Server work and how database design affects performance, we are going to introduce you to some performance tuning topics of interest.
Here we will discuss some of the performance counters you might want to keep an eye on to ensure your SQL Server is working like it should.
When SQL Server reads data from tables, it uses Windows system I/O calls to perform this. SQL Server decides when and how this access is performed, but the operating system actually performs the work.
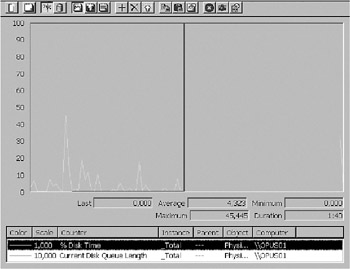
Disk I/O is the most frequent reason for performance bottlenecks, so you should not forget to monitor this activity on your server. As always, use System Monitor (or Performance MMC, as it is called in Windows XP/Windows Server 2003) to monitor your system. Figure 8-15 shows two performance counters:
PhysicalDisk: % Disk Time, which is the percentage of time the disk is busy with read/write operations.
PhysicalDisk: Current Disk Queue Length, which shows the number of system requests waiting for disk access.
If the PhysicalDisk: % Disk Time value is above 90 percent, you should monitor PhysicalDisk: Current Disk Queue Length to see how many system requests are waiting in line for disk access. This value should be no more than 1.5 or 2.0 times the spindles making up the physical disk, so check out the hardware before counting. If both of these counters are consistently high, you probably have a bottleneck in your system. To solve this problem, consider using a faster disk drive or moving some files to an additional disk or even a different server. You could also add additional disks to your RAID system if you use one.
These counters are used if you only have one disk partition on your hard drives. If you have partitioned your disks, you should monitor the LogicalDisk counters instead of the PhysicalDisk counters (the names of the corresponding LogicalDisk counters are similar to those just mentioned for PhysicalDisk).
As you saw in Chapter 4, you should avoid paging on your server. To monitor this, use the Memory: Page faults/sec counter.
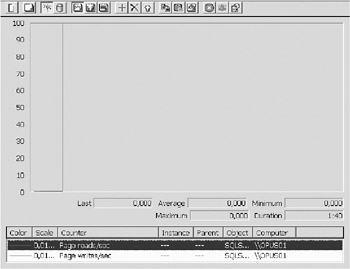
If you want to isolate the disk writes/reads that SQL Server is responsible for, monitor the following two counters (see Figure 8-16):
SQLServer: Buffer manager page reads/sec
SQLServer: Buffer manager page writes/sec
If the values for these two counters are near the capacity of the hardware, you should try to reduce them by tuning your databases or applications. You can do this by reducing I/O operations: Check your indexes so they are accurate or try normalizing your databases even more. If this still does not help, try increasing the I/O capacity of your hardware or adding more memory.
You could monitor how much memory SQL Server is using by checking the value for SQL Server: Memory Manager Total Server Memory (KB). Compare this to how much memory the operating system has available by checking the counter Available Kbytes from the Memory object. This could give a clue to deciding if there is a need to restrict how much memory SQL Server is allowed to use.
Next, we will move on to clustering SQL Server.
In previous chapters, you have seen the two ways you can cluster Windows servers: Network Load Balancing (NLB) and Microsoft Cluster Service (MSCS). You can only use MSCS with SQL Server, but as you will see, several servers can share the workload of a database server in a similar way as NLB. First, we will start with a look at using MSCS with SQL Server.
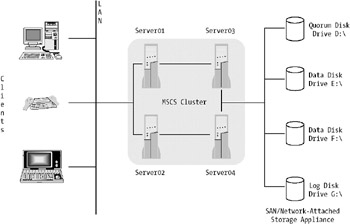
SQL Server is built as a cluster-aware application and can therefore use MSCS to provide high availability. In Windows Server 2003, you can have up to eight nodes in a cluster, and you can also disperse the nodes across geographic locations. By using MSCS with SQL Server, you can build a back-end data store solution that provides your applications with a secure and highly available data feed. Figure 8-17 shows a typical four-node cluster exposed as a single virtual server to the clients.
The disks used to store the database and its transaction log(s) are shared between the nodes in the cluster.
| Note |
To avoid a single point of failure, duplicate all fiber channels and other communications hardware your cluster uses. |
Remember that only one instance of SQL Server can access the database at a time, and when a node fails, it takes a little time before the failover node is online and processing requests. If the failure depends on a corrupt database, obviously the failover node will not work either. Database corruption like the kind a user can make, called logical corruption, and the type that occurs within a database, called internal corruption, is not prevented by clustering. This means you must always provide a disaster recovery plan, and also make certain that it works when you need it.
This sounds so logical and easy, but this is not always the case. One time, a client of ours experienced an erroneous update in their sales batches during the night, which corrupted 25 customer databases. All of the customers had regular database backups scheduled, but only 15 of them were able to perform a restore operation. We ended up writing scripts and doing tricks so the databases were rolled back to an earlier date, and all batches were then inserted again, this time with correct data. That took us close to a week. Do not put yourself in this situation—we can guarantee it is not pleasant.
Indexes are one of a database designer's best friends. Efficient index design is a crucial part of achieving good performance. An index reduces the amount of I/O necessary to retrieve requested data by helping SQL Server to quickly determine where data is stored, hence making retrieval quicker.
If you do not have an index in your table, all data must be read and compared to what you are looking for. Compare this to how hard and slow it would be to find a certain topic in a book without a table of content or index, and you soon understand the importance of good indexing. By using indexes, you speed up the process of finding what you are looking for.
There are two kinds of indexes that SQL Server uses:
Clustered indexes
Nonclustered indexes
A clustered index can be compared to a phone directory. All data is sorted alphabetically, in the phone directory by last name and first name, and in a database depending on what column(s) the index is created on. There can only exist one clustered index in a table, since the clustered index dictates the physical storage order of the data.
A nonclustered index can be compared to an index in a book. The data is stored in one place and the index, with pointers to the data, is stored in another. The index and the items it consists of are stored in the order of the index key values. The data in the table can be stored in a different order. You can, for instance, store it in the order of a clustered index, but if you do not have a clustered index in your table, it can be stored in any possible way. SQL Server searches the index to find the location of the data, and then retrieves it from that location. You can have multiple nonclustered indexes in a table, and use different ones depending on your queries.
If you have a column in a table where data is unique for every row, you should consider having a clustered index on that column. An example of this is a column with Social Security numbers or employee numbers. Clustered indexes are very good at finding a specific row in this case. This can be effective for an OLTP application, where you look for a single row and need access to it quickly.
Another great opportunity for using clustered indexes is when you search a table for a range of values in a column(s). When SQL Server has found the first value in the range, all others are sure to follow after it. This improves performance of data retrieval.
If you have columns often used in queries that have a GROUP BY or ORDER BY clause, you can also consider using a clustered index. This eliminates the need for SQL Server to sort the data itself, since it is already sorted by the index.
| Tip |
We have learned from experience that it is not a good idea to have a clustered index on a GUID (or any other random value). The clustered index works well for columns you know will be sorted a particular way (according to last name, for example), because you do not need to perform a sort after retrieval. You will rarely (if ever) sort or seek data according to their GUIDs (or random values for that matter) because that would only increase the overhead during and after data retrieval, since you then would have to resort the data to be able to use it properly. |
Nonclustered indexes are used to great advantage if a column or columns contain a large number of distinct values. (Refer to a combination of last name and first name here to get the picture. There can be many John Smiths in a table, for example.)
You can also use the nonclustered indexes when queries do not return large data sets. The opposite is, of course, true for clustered indexes.
If you have queries that use search conditions (WHERE clauses) to return an exact match, you can also consider using nonclustered indexes on the columns in the WHERE clause.
| Note |
SQL Server comes with a tool called the Index Tuning Wizard, which can be used to analyze your queries and suggest the indexes that you should create. Check it out on a few queries and tables, and do some testing. We will cover this feature more later in this chapter. |
SQL Server 2000 comes with a built-in query optimizer that in most cases chooses the most effective index to use. When you design your indexes, you should provide the query optimizer with a carefully thought-out selection of indexes to choose from. It will in most cases select the best index from these.
The task of the query optimizer is to select an index when it attempts to optimize performance. It will not use an index that will degrade performance. The truth is that having an index does not necessarily mean you get the best performance, especially if an index is designed poorly. So you should be grateful that there is logic built into the query optimizer to help you out. The rule is to test your indexes as you test all other solutions to find the most effective ones.
As you saw in the previous section, in SQL Server you do have available a tool that helps you analyze your queries and suggest indexes for your tables. If you were going to do this manually, you would have quite a task in front of you. First of all, you would need to have an expert understanding of the database. If you are the database designer, this would not be a problem, but that is not always the case. You would also need to have deep knowledge of how SQL Server works internally. If you are like most developers, you just do not want to dig that deep into the tools you use, and you should not need to either. That is why it is good to have tools that make your lives easier.
To use the Index Tuning Wizard, you need a sample of the normal workload your SQL Server has to deal with. You can use this as input on how you should design your indexes, so you know they will be effective. Only it will be the Index Tuning Wizard that makes the recommendations for you.
To create the sample, you use another tool that ships with SQL Server: the SQL Profiler. Once you are satisfied with the trace SQL Profiler creates, you can let the Index Tuning Wizard analyze the workload and a sample Transact-SQL statement. When done, the wizard will recommend an index configuration that will improve the performance of the database. At this moment, you can choose to let it implement the suggested changes immediately, schedule the implementation for later, or save it to a SQL script that you can run at any time.
| Note |
Run the Index Tuning Wizard against a test SQL Server. It consumes quite a lot of CPU from the server, which could create problems in a production environment. Also, try to use a separate computer to run the wizard from, so it is not running on the same server where the SQL Server instance is installed. |
You cannot use Network Load Balancing to distribute the workload for a SQL Server. Another method lets you accomplish the same thing, however, or at least something similar.
Take a look at an example. If you have a customer database that only stores information about your customers A–Z, you can partition the data. One partition could hold all customers in the range from A–E, another F–I, and so on. Once you have decided which way to partition the data, you must select one out of two following choices of storing it for best performance:
Local partitioned view
Distributed partitioned view
A local partitioned view stores all partitions in the same instance of your SQL Server. (See the section "Separating Read Data from Write Data" later in this chapter for a discussion on when this is a good solution.)
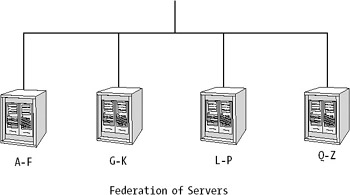
A distributed partitioned view uses a federation of servers to store data. Although this sounds like something out of Star Wars, it is really quite simple. A federation of servers consists of two or more servers, each holding one partition of the data (see Figure 8-18).
Every server runs a separate instance of SQL Server. The servers are administered independently of each other, but they cooperate to share the processing load of the data. The horizontally partitioned table is exposed as a single table through the use of partitioned views.
On every server, the other SQL Servers are added as linked servers so you can execute distributed queries on them. You then create a distributed partitioned view on each of the servers as the code listing that follows shows, so that clients can access this view on any of the servers and still get the view of the full table. As you see, the view is a set of SQL statements whose individual result sets are combined into one, using the UNION ALL statement in Transact-SQL.
create view CustomerView as
select * from server01.MyDatabase.dbo.Customers_01
union all
select * from server02.MyDatabase.dbo.Customers_02
union all
select * from server03.MyDatabase.dbo.Customers_03
union all
select * from server04.MyDatabase.dbo.Customers_04
You can also make the view updatable if you want to, which further adds to the flexibility of this solution.
Remember that you can use the servers for storing other data at the same time as they store a partition. The servers are not dedicated to this partition in any way. You might only need to partition one large table, in which case it would be a pity not to use the servers' capacity to their full extent.
By using this method, you can let several servers share the burden of handling a large table. Clients can access any of the servers and get results from all of them by using one single view, allowing this solution to scale even though you do not use NLB. Since you can use a MSCS cluster behind each of the participating servers, you can also achieve high availability with this technique.
| Note |
Most common way of implementing distributed partitioned views is by letting the client applications access the member server that has most of the data required by the SQL statement. This is called collocating the SQL statement with the data it requires. |
There is a way to reduce the impact locking has on your database. As you may recall, locking can reduce performance, and if you have a lot of read activity, a write command should not lock these reads. By defining vertical partitions, you can separate read columns from write columns and place them in different tables. This can improve performance in your applications.
You could also use horizontal partitioning to separate read data from write data. Say you have a table that stores sales data for your company. Data is written on a daily basis, and all other data is maintained for reporting purposes. This kind of table could grow extremely large and unmanageable. By partitioning the data horizontally, you can enhance performance on write and read operations. You could create a table for the current month, another for the current year, and a third for the rest of the data. How you do the partitioning is determined by the way the table is used. After that, you create a view that lets you display data from all tables.
By partitioning this way, you also enhance backup performance, since you do not need to back up all historical data every day.
During the design phase, you should carefully consider how your data is going to be accessed so you minimize locking.
Even if you have top-of-the-line hardware and it is tuned extremely well, you might still experience performance troubles. It is as important to optimize your queries as it is to optimize your hardware. Although writing queries is quite easy, if you have no knowledge of query design issues, your queries could degrade performance. Resources are used intensively especially in two particular cases: queries returning large result sets and highly nonunique WHERE clauses. We have seen some horrible queries in our times (not to mention the embarrassing queries we ourselves have produced over the years), despite the fact that the developers who wrote them should have known better.
Sometimes you cannot avoid using very complex and resource-intensive queries; however, you could try to move the processing of these to a stored procedure, where such a query probably would execute better than if the application issued it. This would also reduce network traffic if the query returned a large result set.
If this still does not help, you could also add more CPUs to your server if your hardware allows this possibility. This way SQL Server can execute queries in parallel, and performance will increase.
What you should do first of all is to go over the design of the query one more time. Is there really no way you can rewrite it to make it perform better? If you use cursors in your query, you should definitely see if you can make them more effective. It might also be possible to exchange the cursor for a GROUP BY or CASE statement instead.
If your application uses a loop that executes a parameterized stored procedure, every time you travel down the loop, a round-trip is made to the SQL Server. This slows down performance. Instead, you should try to rewrite the application and the stored procedure to create a single, more complex query using a temporary table. This way the SQL Server query optimizer can better optimize the execution of the query. A temporary table causes a recompile of the stored procedure, however, which negatively affects performance. So if you find it causing problems, you could use a table variable instead. Try to avoid getting too large of a result set back, since this also degrades performance. This can be like walking on the edge of a blade, so test, test, and test.
| Note |
Stored procedures are not all good, unfortunately. See the section "Stored Procedures" later in this chapter for specifics. |
A long-running query costs a lot since it might prevent others from getting their queries executed. It also consumes a lot of resources. You can stop these queries by setting the query governor configuration option. The default is that the query governor allows all queries to execute. You can set the query governor to not allow queries that will take more than a specified number of seconds to execute. It also allows you to control this type of query execution on each separate connection, or on all if you wish. The query governor estimates the cost of the queries and stops long-running queries before they have even started executing. Since it does not allow them to run, the overhead of this process is quite low.
There are several ways you can connect to a SQL Server, named pipes and TCP/IP being the most common. In certain situations, one of these may be preferable to the other if you want to get the best performance out of your solution.
If you have a fast LAN, not much differs between these two approaches. On a slower network, like a WAN or dial-up network, the difference becomes apparent. Named pipes is a very interactive protocol—it sends a lot of messages before it actually begins reading any data. Named pipes communication starts when a peer requests data from another, using the read command. After they have exchanged pleasantries, data is read. On a fast network, this communication will not be noticed much, but on a slower connection this costs performance because the network traffic consists of many messages. Obviously, this affects clients on the network negatively.
TCP/IP sockets have more streamlined data transmissions with less overhead than named pipes. Windowing, delayed acknowledgements, and other features of TCP/IP sockets help you improve performance. This is very useful on a slow network for providing significant performance benefits for your client applications.
Our suggestion is to use TCP/IP on WANs and dial-up connections; it will save a lot of complaints on slow data retrieval.
If the application using the SQL Server is located on the SQL Server itself, you can use local named pipes, which can result in great performance. Local named pipes run in kernel mode, making them extremely fast. Use this option if you are planning to implement the data access component on the same server as the SQL Server database.
To summarize what we have just covered:
Use TCP/IP on slower network connections.
Use local named pipes when data access components are running on the SQL Server itself.
Use either TCP/IP or named pipes on a fast connection.
A good way of optimizing how your data access components talk to SQL Server is through stored procedures. Because they are compiled on the server, they execute much faster than if you had used a Transact-SQL statement to retrieve data. You do not want to move business logic to the database in most cases; you only want to use the enhanced performance you get from including parameterized stored procedures.
| Note |
All database interaction can benefit from using stored procedures. Your insert, select, and delete operations could, and should in most cases, be implemented as stored procedures. However, even stored procedures can negatively affect performance. Try to avoid stored procedure recompiles because they cost performance. One good thing to remember is to be careful with the use of temporary tables in stored procedures, since they cause a recompile of the stored procedure every time it is executed. In the case of temporary tables, you could try using a table variable instead. If you want to learn more about troubleshooting stored procedure recompilations, you can find a good document on this topic at http://support.microsoft.com/default.aspx?scid=kb;en-us;243586. |
Another benefit is that stored procedures utilize the network more efficiently than an ordinary SQL statement does. For example, say you have an INSERT statement that inserts a large binary data value into an Image data column. If you do not use a stored procedure, the application issuing the Insert statement must convert the value to a character string. This doubles the statement's size. Only after this conversion can it send the data to the server. The server in turn converts the statement back to binary format and stores it in the image column. If you instead use a stored procedure, the image would stay in binary format all the way to the server. This would greatly reduce overhead on the server and the client, as well as cutting down on network traffic.
Sometimes it can be of great use to move the business rules from the business logic into the database server. You must carefully consider your use of this, however, so you do not lose control of your application. The benefits of moving processing to a stored procedure are purely performance related. Instead of moving a large set of data to where the processing usually occurs, you bring the processing functionality to the data, which increases performance. The complexity of your application increases, however, so you should think twice before using this technique. The best way to see if the performance gains outweigh the increased complexity is to test the solution in the lab.