Consider the list l in Figure 3.8(a). The task is to write a function reverse, to reverse such a list. This means that when reverse is applied to l, the result should be as shown in Figure 3.8(b). n
At first glance, this may seem to be a complicated task involving a great deal of record and pointer manipulation. However, there is a simple solution: the information fields of each record need not be considered at all. Instead, as in Figure 3.8(c), the link field of F can be set to null, the link field of O can be set to point to F, the link field of R can be set to point to O, and so on. Finally, l itself can be set to point to D. The result would be as sketched in Figure 3.8(c), the correct reversed list. This procedure can be stated more generally:
1. Set the link field of the first record to null.
2. Set the link field of each record to point to its original predecessor.
3. Finally, set the list head to point to the original last record.
Even without the details of implementing the list and carrying out the procedure,it is easy to be certain that this procedure, when successfully carried out, does solve the problem. This is so except for the case of a null list; the procedure does not specify what is to be done, since there is no first or last record in a null list. Since the first record of any list has no predecessor, the procedure can be specified somewhat differently.

(a) The Original List
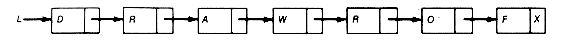
(b) The Reversed List

(c) The Procedure for Reversing the List
Figure 3.8 A List before, after, and during Reversal
1. Set the link field of each record to point to its original predecessor.
2. Then set the list head to point to the original last record, or to predecessor if the list is null.
Now we have a procedure that is correct for all cases, the first record's predecessor being assumed null.
The next step is to detail how this procedure is actually to be done. The basic structure involved is a loop, since the same process is to be carried out repeatedly, but on a different record each time. In general, loops need a beginning (initialization) and an end (finalization). The finalization here is specified explicitly in the procedure: namely, set the list head to point to the original last record, or to predecessor if the list is null. The initialization, as usual, cannot be specified until the loop is specified in more detail. Refining task 1 makes the algorithm read as follows:
1. Initialization
While (there is a current record)
a. set the link field of the current record to point to its original predecessor, and
b. update the current record.
2. Set the head of the list to point to the original last record, or to predecessor if the list is null.
To implement the loop requires a pointer (call it recordpointer) to keep track of the current record to be processed within the loop by its loop task. Imagine that the first three records have already been processed correctly and the fourth is about to be processed. It is pointed to by recordpointer, as depicted in Figure 3.9(a).
Processing W requires setting its link field to point to W's predecessor R. To do this requires knowing where its predecessor R is located. Thus another pointer, predecessor, is needed. It is so named because it will contain a pointer to the predecessor of the current record to be processed. (See Figure 3.9(b).)
Suppose someone attempts to process W now, copying predecessor into W's nextpointer field to set it properly. The result is shown in Figure 3.9(c).
Predecessor and recordpointer must now be updated so that they point to W and A, respectively. Then A can be processed next when the loop is repeated. However, the link field of W no longer points to A, but instead to R. Thus the location of A has been lost. Care is required when changing pointer values so that such important information is not lost. To remedy this, introduce another pointer hold in which the pointer to A can be saved before changing W's link field value. The processing of the record pointed to by recordpointer may now be done by sequentially
1. copying its link field value into hold,
2. copying predecessor into recordpointer's link field
3. copying hold into recordpointer.
This produces the result depicted in Figure 3.9(d).
The test or condition for another repetition of the loop becomes (recordpointer ! = null). The initialization involves setting recordpointer to 1, to make it point to the first record, and setting predecessor to null. Why is it unnecessary to initialize hold?
When the loop is exited, predecessor will point to the original last record, and the finalization can be completed by copying predecessor into l. Refining again:
1. Set predecessor to null.
Set recordpointer to l.
While (recordpointer is not null),
a. set hold to the link field value of the record pointed to by recordpointer, and
set recordpointer's link field to predecessor,
b. set predecessor to recordpointer, and
set recordpointer to hold.
2. Set l to predecessor.
This algorithm actually involves a complete traversal through the records of the list l. As it is carried out, recordpointer accesses each record of l in turn and processes it within the while loop. The processing is done by the loop task. In order for the loop to work correctly, some initialization had to be done, and some finalization was required after each record of the list had been processed.

Figure 3.9 Achieving Proper Loop Implementation