A detailed version of the heapsort algorithm can now be developed. You have now seen a number of ways to create a heap and to reheap. We will use the second heap creation algorithm for phase I and the second reheaping algorithm for phase II. Both algorithms use the shift function.
To proceed we must decide on an implementation of the binary tree data structure. The binary tree used in heapsort is initially complete. The required processing involves predecessors and successors of nodes. Sequential representation for the binary tree is ideal, so we use it. The binary tree is stored in the data array and consists of n records.
Storage is needed for the sorted version of data. Although another array may seem necessary for this purpose, we will use only the data array. The algorithm, after creating a heap (in data), continually takes the root record as the next record in the sorted output and then reheaps. Before reheaping, the rightmost record at the lowest level of the heap is placed at the root. The storage vacated by that rightmost record will no longer be needed. We choose to store the output record there. You should convince yourself that this will result in the records appearing in data in reverse sorted order upon termination. To remedy this, we write shift so that it produces min heaps. The records will then appear in correct sorted order upon termination.
Shift has parameters data, root, and last. Root points to the root of a subtree, and last points to the node of the original heap that is currently the rightmost node at greatest depth. The nodes last+1 to n are currently storing the already sorted n-last output records. Whenever shift is invoked, the left and right subtrees of root (excluding nodes last+1 to n) are assumed to be heaps. Shift returns after reheaping, by allowing the root record to move down to its final position. This is done by first storing the key value and record of the initial root record in keyvalue and recordvalue, respectively. Ptr points to the node currently being considered as the final position for the initial root record. This will be the final position if either of the following two conditions is met.
1. The successor record of ptr with minimum key value has a key value greater than or equal to keyvalue, or
2. Ptr points to a terminal node or to a node whose successors are nodes among last+1 to n.
Condition 2 can be recognized by the test (succ<=last), where succ points to the left successor node of ptr. Condition 1 requires finding the minimum key value for the successors of ptr. Ptr may not have a right successor, or that successor may represent an output record. This can be tested for by the test (succ<last).
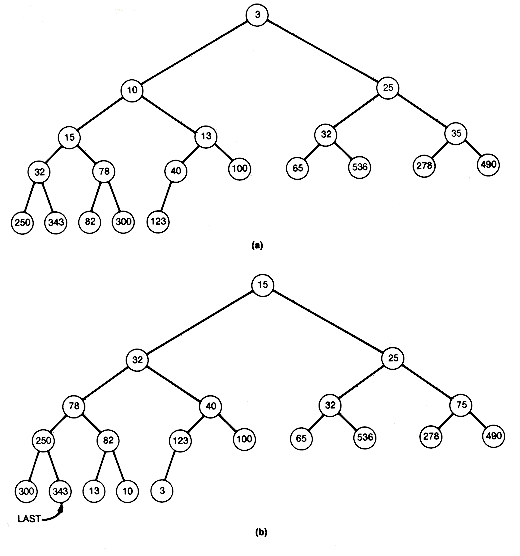
Copy copies the contents of the record pointed to by its second parameter into the record pointed to by its first parameter. When shift determines that ptr is not the final position, it moves the record at ptr to its predecessor node. This is why the original record at root is saved. When the final position is found, the saved record is placed there. The initial heap and the situation after the first three entries have been output are shown in Figure 8.13 for the tree of Figure 8.7.
The implementation for heapsort follows.
at this point, succ points to the smallest of ptr's successors
the purpose of the while loop is to determine the proper place for the original root record; ptr will
point to that location when the loop is exited
#define MAX 100
typedef struct
{int key;
}record;
typedef record recordarray[MAX];
heapsort (data,n)
/* Sorts the n records stored in array data
in descending order.
*/
recordarray data;
int n;
{int root,last;
root = n/2;
last = n;
while (root > 0)
{shift(data,root,last);
root--;
}
root = 1;
while (last > 1)
{interchange(data,1,last);
last--;
shift(data,root,last);
}
}
shift (data,root,last)
/* Makes the subtree of root into
a heap (min heap). The left and
right subtrees of root must be
heaps. All subtrees are stored
in array data in sequential
representation. Only the nodes
between root and last are
considered to be in the subtrees.
*/
recordarray data;
int root,last;
{int ptr,succ;
int keyvalue;
record recordvalue;
ptr = root;
succ = 2 * ptr;
if (succ < last)
if (data[succ + 1].key < data[succ].key)
succ++;
keyvalue = data[root].key;
copy(&recordvalue,&data[root]);
while((succ <= last) && (data[succ].key < keyvalue))
{copy(&data[ptr],&data[succ]);
ptr = succ;
succ = 2 * ptr
if (succ < last)
if (data[succ + 1].key < data[succ].key)
succ++;
}
copy(&data[ptr],&recordvalue);
}