A clever way to do this requires two pointers, upper and lower. Initially, upper is set to i, the first array index, and lower to j, the last array index. The initial situation is shown in Figure 8.16(a).
Lower is now moved upward until an entry larger than data [upper].key is encountered. In this case, 15 will be that entry. It is then interchanged with data[upper]; see Figure 8.16(b). At this point, attention is shifted to upper, which is moved downward until an entry smaller than data[lower].key is encountered. This entry will be 10, and it is interchanged with data[lower], yielding Figure 8.16(c).
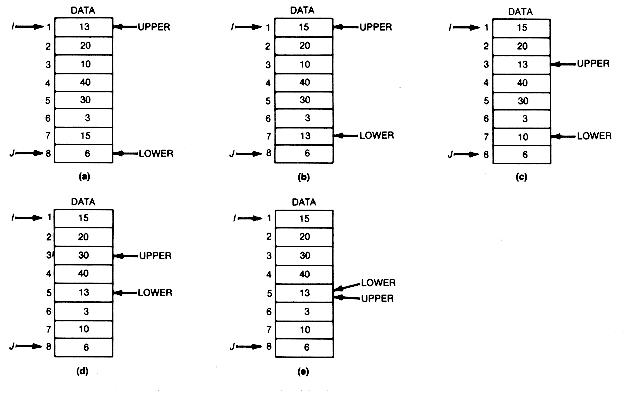
Figure 8.16 Sorting an Array by Means of a Partitioning Function
Attention now shifts back to lower, which is again moved upward until an entry greater than data[upper].key is encountered. This will be 30, and it is interchanged with data[upper], resulting in Figure 8.16(d).
Upper is then moved downward until an entry smaller than data[lower].key is encountered. In this case no such entry appears, and when upper reaches lower, no such entry can appear. This is so because, at all times, any entries above upper are greater than the original first entry (13 in the example), and any entries below lower are less than the original first entry. Hence, whichever pointer is being moved, only entries between upper and lower can result in an interchange. When upper and lower coincide, no entries are left to interchange. Furthermore, when upper and lower coincide, they must be pointing to the original first entry or basis, since at all times at least one of them points to it. The final situation, then, is as shown in Figure 8.16(e).
This procedure clearly carries out the task of partition(i,j), which is to return the value of upper(or lower). Notice that, whether upper or lower is the focus of attention, it is always the original first entry (13 here) that is the basis for comparison.
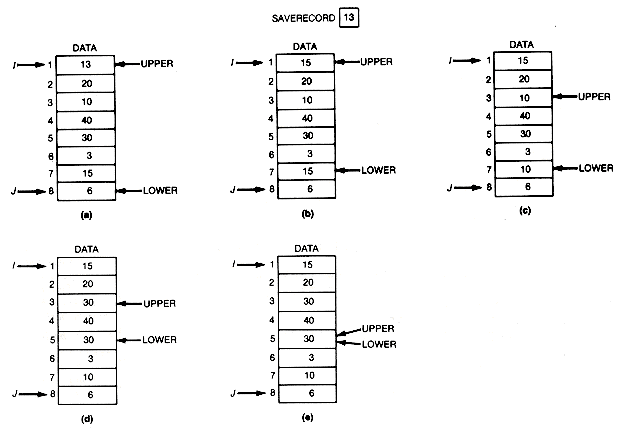
Figure 8.17 Partitioning an Array by Means of a Temporary Variable, SAVERECORD
A slight modification makes partition more efficient. Instead of interchanging the basis with the larger or smaller entry that has been found, simply move the larger or smaller entry to the position pointed to by the current stationary pointer. This is the position that would have been occupied by the basis (13 in the example). However, the basis does not now appear in the array but is saved in a temporary variable, saverecord. For the example, this would generate the sequence shown in Figure 8.17. When upper and lower meet, the record stored in saverecord must be copied into data[upper]. This version of partition is faster because a move is carried out much faster than an interchange, and many such operations are required as the algorithm executes. It is therefore the algorithm implemented below.
partition(i,j)
/* Rearranges the entries in array
data between positions indexed by
i and j and returns an array index
which guarantees that all entries
above it are larger than the entry
it indexes, and all entries below it
are smaller.
*/
int i,j;
{
int upper,lower;
record saverecord;
upper = i;
lower = j;
copy(&saverecord,&data[i]);
while(upper != lower)
{
while((upper < lower) && (saverecord.key >=
data[lower].key))
lower--;
if(upper != lower)
copy(&data[upper],&data[lower]);
while((upper < lower) && (saverecord.key <=
data[upper].key))
upper++;
if(upper != lower)
copy(&data[lower],&data[upper]);
}
copy(&data[upper],&saverecord);
return(upper);
}
It is important to recognize that whenever partition (i,j) is invoked, it processes only entries between i and j of the data array and deals with each of these entries exactly once. Each entry is compared with saverecord, and perhaps copied into data [upper] or data [lower]. Consequently, a call to partition (i,j) takes time O(j - i + 1), since there are j - i + 1 entries between i and j.