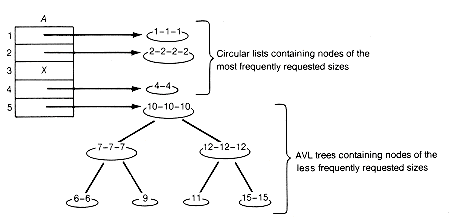
At this point each of the two approaches, circular lists and buddy systems, seems to solve half the problem. Circular lists using the best-fit method utilize storage very efficiently, causing little internal fragmentation. Buddy systems produce significant internal fragmentation but offer fast allocation by narrowly focusing the search for a proper size node. The question is whether it is possible to achieve good storage utilization and allocation time by combining their features. As you would guess, it is. It can be done by using the appropriate structures. The means to do it is called the indexing approach. The indexing approach breaks up the list of available space into collections of two-way circular lists. Each of these circular lists contains nodes of just one size. Each node on the circular list represents a block of consecutive memory locations available for the storage of a record of the size of the node. Assuming that requests for nodes of sizes (say, 1 to 4) are very frequent, an array a contains pointers to each of the four lists corresponding to these sizes. The last array entry contains a pointer to an AVL tree. The nodes of this tree are circular lists, each list corresponding to nodes of specific size that are requested much less frequently. Thus a[2] contains a pointer to a circular list containing four blocks or nodes, each of size 2. In the AVL tree pointed to by a[5], the root node is a circular list containing three blocks of size 10. The tree is ordered on the basis of node sizes. A typical configuration might be as shown in Figure 13.5.
In this way, a specific request for a node of length less than 5 can be quickly satisfied if the exact matching list is not empty. If it is empty, the next nonempty greater-size list can be used, with one of its nodes truncated to satisfy the request. Any leftover is inserted on the appropriate list. For instance, with the situation of Figure 13.5, a request for a node of size 3 will be satisfied by deleting a node of size 4 from the list pointed to by a[4]. This node will be split into a node of size 3 to satisfy the request, and the leftover node of size 1 inserted on the list pointed to by a[1]. In the infrequent case when the requested node size is 5 or greater, the AVL tree must be searched similarly. It is clear that this scheme can cause internal fragmentation, but the search times should be fast on the average. In fact the indexing approach is a compromise. It is not as fast as the buddy system but faster than simple circular lists. Likewise, the fragmentation is less than with the buddy system but more than with simple circular lists.
Thus choosing the appropriate scheme of storage management is a difficult task. It requires insight into the kind of request and return distribution involved in a given application. In the worst case all schemes may fail miserably. Intuitively, good performance should result when the distribution of node sizes on the list of available space reflects the distribution of requests and returns. In turn, this distribution should be reflected in the distribution of node sizes actually in use. This is analogous to the situation mentioned in Chapter 12 for the distribution of letters in printer's boxes. The distribution of letter requests is reflected in actual text, and the printer's ordering policy for letters should have caused the contents of the letter boxes to reflect this distribution.
The three techniques considered in this section, and other techniques, are compared extensively in Knuth [1973a] and Standish [1980]. See also Tremblay and Sorenson [1984].