


Two programs doing exactly the same task may look entirely different. One may be highly readable, concise, and easily adjusted to carry out related tasks. The other may be impenetrable, lengthy, and difficult to modify. The same two may differ so much in execution time and storage needs that one program executes while the other aborts, having exceeded time or space restrictions. Experience has shown such differences to be traceable to choice of program structure and data structure.
Programs are written to solve real problems. Program structure breaks the problem and its solution down into simpler, more easily understood parts. The information to be processed is stored in data structures (arrays, records, lists, stacks, trees, and files) provided by the programming language. A data structure groups data. The right data structure for an operation can make it simple and efficient; the wrong one can make the operation cumbersome and inefficient.
Data structures contain information and are operated on during the execution of a program. Programs are said to process information when, in fact, they process data structures. Thus it is not surprising that data and program structure are important and need to be properly related to achieve the goal of successful programming. How this is done is the subject of this book. The story is fascinating and sometimes involved, but it has a happy ending: you master practical programming techniques. These techniques provide the programmer with the means to keep a tight rein on programs so that they remain understandable, maintainable, and efficient, even as they grow in size.
There is structure, then, in both the data and the program itself, and both program and data structure must be appropriate to their tasks. This book presents data structures, not as an isolated theoretical subject, but as an essential object of the problem-solving process leading to the creation of a good program.Three main themes are stressed.
1. Data structures and their impact on programs
2. Programming methodology and its impact on programs
3. Consolidation and extension of knowledge of a high-level language
Data structures are important because the way the programmer chooses to represent data significantly affects the clarity, conciseness, speed of execution, and storage requirements of the program. The text shows how to use particular data structures to create correct and efficient programs. You will see that the operations to be performed on the data determine the best data structures to use.
Developing programs is difficult, especially when done without good guidelines. Creating programs entails solving problems. Top-down programming, another name for structured programming, makes program development easier and leads to well-structured programs. It is the controlled breaking down of a complex task into simpler ones whose individual solutions easily combine to carry out the original task. This process gives structure to the development of programs (hence its name). The top-down, or structured, approach, combined with good programming style, is emphasized in this text. Elements of good programming style include the use of data abstractions and functional modularization, which significantly enhance the readability and changeability of programs.
Data abstraction treats a collection of data by abstracting its important aspects while ignoring as much detail as possible. A data abstraction reduces data to a collection, and to those processing operations directly allowed on that collection. The effect is as though the collection were in an impenetrable black box, the only access to the contents of the box being through the invocation of one or more of the allowed operations. How the collection is actually stored within the box, and how the operations are actually performed, become irrelevant details. Such details determine the efficiency of a program but do not affect its logic.
Functional modularization is the use of a special program unit to carry out a task. In FORTRAN such a unit would be a function or subroutine, in Pascal a function or procedure, in COBOL a paragraph, and in C a function. These program units are used to carry out meaningful processing tasks. C programmers use the word modularization in two ways. One means functional modularization, and the other has to do with packaging a data abstraction using one or more related files. When the first meaning is intended, this book uses functional modularization. The second interpretation appears only in Chapter 5 and will be addressed there.
Practice may not make perfect but seems to be the best way to make problem solvers and programmers out of computer science students. As a student you must repeatedly practice creating programs, because repetition is what facilitates learning. As in learning to dance, draw, or drive, no matter how closely you watch others perform, you can develop skills only by practice.
Finally, whatever high-level programming language you use, studying and understanding the material in this text will enhance your knowledge of that language and your ability to use it effectively. It is assumed that you are familiar with some high-level programming language. Such languages share many features, but each is unique. Although this text occasionally indulges in comparative investigations, all programs herein are written in VAX C, version 2.2, and run on a VAX 11/780 under VMS.
Horowitz [1983] is a collection of reprints of the landmark papers in programming languages. For background in C, see the introductory texts by Kelley and Pohl [1986], Miller and Quilici [1986], and the classic book by Kernighan and Ritchie [1978]. A good reference is Harbison and Steele [1987]. Advanced topics can be found in Berry [1986] and Lapin [1987]. For interesting reading in structured programming, the reader should study the texts by Dahl, Dijkstra, and Hoare [1972] and Wirth [1973].
A nucleus of commonly used data structures will be introduced. These include arrays and records, which are static structures that change only their values, and stack, lists, trees, and files, which are dynamic structures whose size and shape change as well as their values. Specific ways to implement each structure will be explained and typical and important operations on them investigated. These operations include selection, traversal, insertion, deletion, searching, and sorting. Although particular methodologies and data structures are important, it is more important to acquire skill in applying a methodology and in determining which data structures are appropriate for a given problem.
Programs are built from data structures. Yet the methodology an expert programmer uses makes the data structures invisible and makes the program structure clear and understandable. Neither good program structure nor good data structure selection alone produces good programs. Both must be done well, but they cannot be done independently. Obtaining a good program requires a well-designed solution, expressed first as an algorithm. The final step is writing the program in a programming language.
Determining what information is required to implement the algorithm and how to store it for efficient use and processing are perhaps the most crucial aspects of that facet of problem solving that is commonly called computer programming. The aim of this text is to illustrate good algorithm design, data structure selection, and programs.
If you do not know how to solve a given problem, then you cannot magically write a program to do so. In other words, if you don't know where you are going, then it doesn't matter how you get there. Moreover, as H. L. Mencken said, "Every complex problem has a simple easy-to-understand wrong answer." So before you begin writing a program, you will need to understand the problem and write a step-by-step solution, or algorithm.
Unfortunately, there is no algorithm for finding algorithms. There isn't even an algorithm for checking a candidate to see if it really is an algorithm. But there are some helpful techniques for developing algorithms. For example, it is useful to recognize when a known algorithm or program can be modified to give a solution to a new problem. One way to enhance this recognition is to solve problems in general or abstract terms. Sometimes a problem requires finding an object stored in computer memory that has certain properties. One technique is to search through the set of all objects until one with the desired properties is found. Alternatively, objects without the desired properties may be eliminated. The latter approach is used to develop a prime number algorithm in Section 1.3. At other times it may be possible to avoid searching altogether by constructing the desired object directly. Thinking up an algorithm is usually more difficult than programming it.
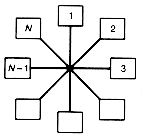
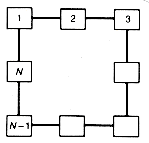
Imagine that you are a census taker charged with visiting all the homes in Spokesville and Squaresville (Figure 1.1). In each town, you must start and finish at home 1, after visiting each home once. All roads are the same length, and there are the same number of homes in each town. Nonetheless, in Spokesville you will travel a total distance exactly twice the distance required in Squaresville! The difference is due to structure.
It is easy to find the telephone number of a company whose name you know, even in the telephone directory of a large city. But finding the name of a company when you know only its telephone number is a tedious and time-consuming chore.The information in the telephone directory is structured in such a way that one task is easy while the other causes tension headache and eyestrain!
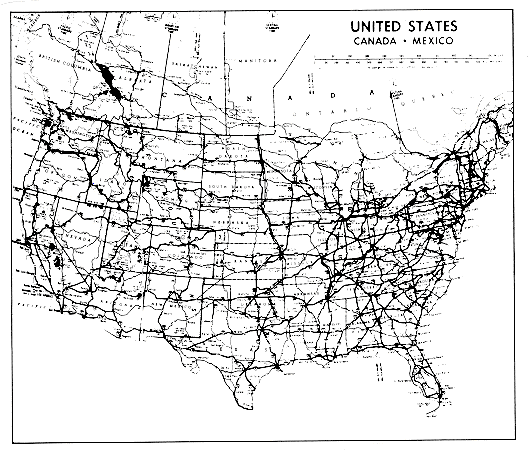
Two maps of the continental United States appear in Figure 1.2; part (a) gives a clear overview, while (b) gives a more detailed view. Structure clarifies, and detail obscures. Still, both are needed for a complete picture. Notice that drawing a border around and naming each state in the overview, in the absence of other distracting details, makes the composition of the country discernible. It is the plethora of detail and subordination of structure that is overwhelming in the other map. The less detailed map is analogous to a functionally modularized program, the other to an unmodularized program.
An algorithm for a given problem specifies a series of operations to be performed that eventually leads to a correct result. Algorithms express solutions step by step. In stating an algorithm, care must be taken to avoid ambiguity and to be sure that it is clear how each step is to be done. When the solution is translated into a programming language for execution by a computer, even more care and attention to detail are needed. But first, the solution is usually expressed in English or flowchart form, before the details required by the programming language are introduced. The next example illustrates the effect of structure in this context.
An integer larger than 1 is a prime number if it cannot be written as the product of two integers, each larger than 1. Suppose we must find a way to print all prime numbers between 2 and some integer n. Thus if n is 12, the primes are 2, 3, 5, 7, and 11. Compare the following two algorithms for accomplishing this task.
It is not difficult to see that if each step of the first algorithm can be carried out, the correct result will be printed. It is considerably more difficult to see that the same is also true of the second algorithm. The first is structured to provide clarity, while the second is poorly structured and provides too much detail. These examples indicate why structure is needed in each stage of program design. Structured solutions are easier to understand, expand, and alter, and structured data make the operations of the algorithm easier and faster to perform.
Well-designed, clear programs are based on the explicit underlying methodology called structured programming. As problems and their solutions become more sophisticated, the brute-force or ad hoc method of programming becomes much less effective. Compilers, operating systems, business management systems, and word processing systems consist of many thousands of program statements. Just as writing a lengthy book is several magnitudes more difficult than writing a paragraph, so is the process of developing a large programming system much more involved than writing a short program. There must be an overall structure.
An example of a large and complex program is an operating system. Many years ago it was thought that operating systems could not be implemented without errors. The immensity of the task was believed to cause inherent problems that could not be isolated and debugged in advance of system implementation. Hence system failure seemed inevitable and getting the system up and running meant a long trial-and-error period of testing and debugging. A new methodology of system design based on the concept of structured programming has demonstrated, however, that error-free operating systems are possible.
Since the programs you see as a student may be relatively trivial, the need for a well-founded methodology of programming may not be evident. However, imagine a large program (twenty pages long, and over a thousand lines of program statements) that you did not write. If you were assigned the task of modifying the program to add a new feature, how or where would you start? Certainly you must have a full understanding of what the program does, how it does it, and how it relates to other programs that use it or are used by it. Anyone who intends to read, write, modify, or correct any programming systems with more than a few dozen statements should use structured programming.
The example of prime numbers is presented here in more detail to illustrate the process and benefits of structuring and the concept of data abstraction. To do this a group of functions is developed from the first prime number algorithm:
primes(n)
1. Create a collection called candidates, consisting of all integers from 2 to n.
2. Remove all nonprime integers from candidates.
3. Print all integers that remain in candidates.
Consider first a simple function called primes.
Primes may be obtained directly from the prime number algorithm when create, remove, and print are interpreted as functions carrying out steps 1, 2, and 3 of the algorithm, respectively. Note that no assumptions about candidates have been made. At this point it is of type collection, which has not yet been defined. Later in the process of developing the algorithm and program, collection, and thereby candidates, will be defined, after the basic operations on candidates become clear. Note that collection is a type, whereas candidates is a variable whose type must be declared. The next step is to refine and verify each function of primes. Refine means to express or define in more detail; verify means to confirm that a refinement does indeed do its job. To refine and verify create and print is straightforward enough, but to refine and verify remove is more difficult. If you want to know more about a state than you see in the first map of Figure 1.2, you may consult another map containing more information on the state's geography. Similarly, if you want to know how to carry out remove, a more detailed description may be available. If not, as is the case here, remove may be treated as a new problem whose solution must be found. One solution is this:
remove(n, candidates)
Set factor to the first prime.
While (nonprimes remain in candidates),
Delete from candidates all integers that are multiples of factor, and
Increase factor by 1.
It is again easy to see that, as long as each step is done correctly, the desired effect is obtained.
Still, more examination is needed to determine whether "nonprimes remain in candidates." It can be shown that nonprimes may remain in candidates only when factor is less than or equal to the square root of n. Consequently the condition (nonprimes remain in candidates) may be replaced by the condition
Delete is refined next (Figure 1.3). You should verify that this function correctly performs its task as long as omit takes nextmultiple out of candidates. It may help to simulate the execution of delete when n is 40 and factor is 2, and then 3.
Each task of function primes has now been defined and is, in fact, a complete C function. All other tasks, except for set, insert, belongs, and omit, have also been defined. Primes and all other tasks have been written modularly (functionally), meaning that for each task there is a function. For example, new functions have been introduced for each of the three tasks of primes: create, remove, and print. Had primes along with remove and delete not been functionally modularized, it would appear as follows:
This version is also a refinement of primes, but instead of defining new functions for its three tasks, the tasks have been replaced by program segments. Thus there are two basic ways to refine any task: (1) define a new function for the task, or (2) replace the task directly by its refinement expressed as a program segment in code. Compare this version with the functionally modularized form, the simple function primes given earlier. Notice that functional modularization suppresses detail.
Deciding how to modularize a program functionally is often a matter of individual taste, but as this text unfolds, the process will become clearer, and you will be able to develop your own style. Functional modularization is intended to highlight and isolate important tasks. The advantage of using functions may not be apparent with this simple prime number problem but will be striking in more complex problems.
Finally, the low-level tasks set, insert, omit, and belongs must be coded. To do this requires deciding how to implement candidates--that is, deciding which data structures shall be used to store candidates and how to write the basic functions that operate on candidates. Recall that data structures such as candidates contain information and are operated on during the execution of a program. No matter how candidates is implemented, none of the functions already defined needs to be changed. They are independent of candidates implementation (except for the data declaration). As long as set, insert, omit, and belongs do their tasks correctly, no function invoking them needs to be changed. This is because we have written them treating candidates as a data abstraction. That is, we have assumed that candidates and the basic operations on it are available via functions (set, insert, omit, and belongs) and further, that any other operations on candidates have been expressed in terms of these functions. For instance, delete uses omit, and create uses insert. If, instead of calls to set, insert, omit, and belongs, the code defining them had been used, all functions containing these codes would be dependent on the implementation. Later, if we changed to a better implementation, it would be necessary to hunt through each function, find any code that would be affected by the change, and modify that code appropriately. A data abstraction consists of a data structure, to store data, and allowed operations on the data structure, to manipulate it. As a result, wherever one of these operations is invoked in a program, the data structure is being affected. Just as important, the data structure is not being affected unless one of these operations is invoked.
The use of data abstraction and functional modularization not only enhances understanding, but also simplifies maintaining a program. Maintenance is a crucial aspect of programming. It involves changing a program to do something new, to stop doing something, or to do better what it now does.
Using data abstractions as outlined above hides implementation details and makes the program independent of those details. On the other hand, the program's speed of execution and storage requirements will be greatly influenced by the implementation of the data abstraction. Consequently, the selection of an implementation should be based on the data abstraction's operations. Sometimes the choice that minimizes execution time and storage will be evident. More typically, conflicts arise, and the choice will involve trade-offs between time and storage. How to make this choice properly is a major focus of this text.
Consider two ways to implement candidates. It might be implemented as an integer array with the ith element of the array containing the value true if i is a prime and false if it is not. Alternatively, candidates could be implemented as an integer that is made up of contributions from each number in candidates. If the number i is in candidates, it contributes 2i. Thus if candidates consisted of 2, 3, 5, 7, and 9, its value would be 684(4 + 8 + 32 + 128 + 512). The integer is stored in an integer array of size one. Candidates could also be implemented as a dynamic list or tree and, indeed, one of these might be preferred. You might want to return to this problem after studying lists and trees, to verify that it can be converted to these structures. However, at this stage, arrays that are more familiar to you will be used. The code below defines the operations on candidates for the two array implementations. Each implementation should have its type declaration for collection global to primes and all its functions, as follows:
Note that the terms TRUE and FALSE are used in the boolean version. Since C does not have a type boolean, TRUE and FALSE must be defined before they are used in the program. In C, a true statement returns a non-zero value, and a false statement returns a zero. For consistency, write
TRUE and FALSE will be used for programming style in many places in the text. Programs that use them merely require the above statements. In the second version the function power (2,i) returns 2i.
Each implementation specifies a data structure for candidates and defines the same four basic operations allowed on it. Each entails some explicit restriction on the size of candidates. Such restrictions can be avoided by using the dynamic data structures introduced in later chapters.
The first implementation of candidates allows insert, omit, and belongs to be written so that they take constant time to execute. However, the amount of storage required will depend directly on n. The second implementation for candidates increases the execution times of the basic operations on candidates but reduces its storage requirement. In general, the choice of implementation for a data abstraction may be critical, determining whether a program will run to completion or abort because of insufficient time or storage. Section 1.8 discusses the selection of program and data structure in more detail. In any case, once the decision is made, the data declaration for candidates must appear in primes. The final result is a well-structured program. A complete program to run primes using the array implementation follows.
As noted, the first implementation for collection is used in the program. Notice that the declarations and definitions needed for the collection appear together in the program. Simply replacing that portion of the program with another implementation is all that is required to change to the new implementation. In Chapter 5 another way to package the collection and its operations for this program will be presented.
Abstraction allows us to focus on concepts rather than concrete details. The architects planning a building assume an elevator as part of the plan. They know the elevator will hold passengers and freight. They know the elevator will convey its contents between floors, respond to call buttons, and be warm in winter and cool in summer. The initial building plans can proceed using only these essential concepts regarding the elevator. Later, the detailed choices necessary to build the elevator will be made. They will determine its size, shape, and structure, as well as its speed, responsiveness, and reliability. Notice that, as long as the elevator is treated as an abstraction, any specific implementation can be substituted for another without requiring changes to the plan.
Similarly, data abstraction allows us to focus on what is needed rather than how it will be assembled and packaged. Planning a program, we assume that we have specific means to store and operate on data. Only later must an implementation be selected. The implementation determines how well the job is done, but does not affect its logical design. The longer this choice can be delayed in program development, the more independent of this specific choice our program will be. This is highly desirable, making program changes much easier to effect.
The richness and power of a language are related to the variety and ease of expression that the language allows. Thus high-level computer languages provide more expressive power than more limited languages, such as assembly languages. However, it is theoretically possible to state any algorithm using only three basic constructs and the rules for their combination. In this discussion three basic constructs have been chosen for the sake of conciseness, but others are used freely when appropriate.
The three constructs indicate different types of flow of control. Each construct determines the order in which its tasks are processed, and each was chosen for its logic and clarity.
The first is the sequence construct, in which each task follows the previous one without altering the order of the tasks. Each task is executed once. Notice that primes (Figure 1.3) is based on this construct. The second is the decision construct, which allows only one of two tasks to be carried out, depending on a controlling logical condition. The appropriate task is executed once. It is the true task when the condition is true and the false task when the condition is false. The final construct is the loop, which enables a task to be repeated until a controlling condition no longer holds. Obviously, the loop must at some point end so that the next task can be executed. Failure to change the value of the controlling condition in order to end the loop task results in the infamous "infinite loop." Examples of algorithms formulated according to the three basic constructs appear in Figure 1.4 as structured flowcharts, along with their structured English equivalents. The corresponding versions are obvious.
Each construct has exactly one entry and one exit point. The constructs may be combined only by making the exit arrow of one the entrance arrow of another. This results in complex constructs that are sequences of constructs. The only allowed modification of a construct is the replacement of any of its tasks by one of the three basic constructs. This amounts to incorporating the task's refinements into the construct, producing a more complex construct.
There are two different ways to express a solution using these constructs and rules for their combination. One is to start with a basic construct and repeatedly apply modifications to it. Each modification corresponds to the use of a program segment for its implementation. This results in a final unmodularized flowchart, English equivalent, or program. See the unmodularized version of primes for an example. The second is to start with a basic construct, and, instead of modifying it, express the solution for each of its tasks as a separate function. This amounts to functionally modularizing each task's refinement, with the complete solution consisting of the collection of individual solutions. This results in a final collection of functionally modularized flowcharts, their English equivalents, or program components. Usually a combination of the two is better than using one method only. It is wise to keep each part of a solution to a reasonable size, say one page. This can serve as a guide to whether or not functional modularization (the use of a function) or modification (the use of a program segment) is appropriate. But remember: the primary goal is clarity.
The purpose of structured programming is to create programs that are
Understandable, meaning the logic is readily followed
Reliable, so the program performs as intended
Adaptable, so modifications can be made with reasonable effort
Structured programming is a method of approaching a problem rather than adhering to a rigid set of rules.
As Dijkstra [1972] observed, the "art of programming is the art of organizing complexity, of mastering multitude and avoiding its bastard chaos as effectively as possible." The essential concept of structured programming is that dealing with complexity requires simplicity.
Regarding terminology, note that the tasks performed by a program solve problems. In this book the words task and problem are used interchangeably. Each programming task entails defining the input information to be processed, defining the output information to be produced, and stating clearly the precise instructions as to what, but not how, it is to be done.
Simplicity and clarity are achieved in a complex program by focusing attention on just one task at a time. To show how the task is done, it is broken down into smaller meaningful subtasks. The combination of smaller tasks to perform the given task is called a refinement of that task. The next step is verifying that the refinement is correct--that is, that the refinement indeed accomplishes the task, as long as each of its components does its job. This verification may be done even without knowing how each component works. This is important. How the components of a refinement work is irrelevant to verification. The goal is to ensure that, if they work correctly, then the refinement itself works correctly.
Top-down design begins with the original problem and involves a loop: repeated refining and verifying of the problem and its refinements until only implementable problems remain. Implementable means simple enough to be directly coded in a programming language. Review the development in Section 1.3.2 for primes to see that this loop was, in fact, being used. With this approach the programmer can be sure the final program is correct even though he or she has considered only one manageable piece at a time.
If the total number of tasks needed to complete a detailed solution is proportional to the complexity of the initial problem (as we hope), then the effort to create, understand, and verify a solution to a complex problem will also be proportional to its complexity. This is a very desirable situation. If the cost of a solution increased more drastically with complexity, then the complexity of problems we could solve would be much more severely limited.
Think about building a jigsaw puzzle. You probably use the top-down approach. You break up the picture conceptually into components--say, the border and recognizable objects with distinct shapes and colors. Then you build each component and combine them all. Surely the most difficult puzzles are those with no distinguishable objects. They prevent refinement, forcing one to deal with all the complexity at one time. Perhaps this is why all the problems humans solve have structure; they are the only ones we can handle.
Two caveats must be added:
1. At each level of refinement, keep the number of component tasks small and keep them independent. This is critical because human beings can deal well with only a few things at a time, and can do so more readily when the things are not intertwined. Psychological studies suggest a "magic number": a maximum of seven tasks, plus or minus two. Independence means that how one task is accomplished need not be a consideration in how another task is done. Sometimes independence must be given up for other considerations, such as efficiency. These trade-offs should be considered carefully.
2. Control carefully how tasks of a refinement are combined. Simplicity requires structure that makes the logic of a program easily discernible. Certain combinations or constructs foster such clarity. Some programs present a bewildering panorama of program statements, but what is needed are programs that appear as a logical sequence of tasks to be executed. Some ways of expressing the order in which tasks are to be executed are more understandable than others.Constructs that are well designed allow anyone working with a program to grasp quickly what is intended. This is the hallmark of the basic constructs--sequence, decision, and loop--introduced in Section 1.4.
High-level languages provide basic data structures and operations and the capability of using these to build more complex data structures and operations. With some languages it can be hard to realize this capability, while with others it is relatively effortless. In addition, languages have different idiosyncrasies and subtle shortcomings. In this text, the focus is not on the language but on the more general topics of program structure and data structure selection. Still, whatever background you have in high-level languages may be helpful.
A program written in a high-level language specifies a series of operations to be performed on data structures. Think of a high-level language as having an associated high-level computer that carries out those operations and stores those data structures in its memory. Such high-level computers are just a concept--normally they are not built. The conventional computer is not specifically a C, Cobol, Pascal, or FORTRAN machine; we rely on compilers to translate programs from high-level languages into the languages of existing computers. The translated version is then executed by the conventional computer. The compiler, in effect, makes the conventional computer appear to be a high-level computer for the high-level language.
To do this translation, the compiler must find a way to represent the program's data structures, using those in the conventional computer's language. lt must also apply operations of the conventional computer's language to these representations to simulate the program's operations on its data structures. How this is done, or what the actual computer is, does not affect the correctness of programs written in the high-level language. This is data abstraction par excellence! However, the way this is done will influence the storage requirements and execution time of the program. It can also cause problems for the unwary user.
Programs use variables to refer to storage elements in the memory of the high-level computer. Each variable has a name, which refers to its storage elements, and a value, which is the content of those elements. For example, the C assignment statement
uses two variables with names sum and increment. Individual variables, which correspond to a single storage element, are the simplest type of data structure. More complex structures are built from variables. In turn, operations on the more complex structures are built from operations on the simpler structures. High-level languages differ in the kinds of basic data structures they provide. For example, FORTRAN includes individual variables and dimensioned arrays. C adds records and pointers and, significantly, allows the definition of new data types and data structures. The Ada language allows new basic operations to be introduced as well.
Each variable must be defined by a declaration that gives its name and data type. The data type indicates the actual values that may by assumed by the variable. For example, the C declaration
specifies that sum and increment are the names of variables whose values will be integers, and that check is the name of a variable whose values will be a character.
Data types must be specified. An example will show why. Suppose a compiler represents integer and real variables (floats) using seven decimal digits. Then in storage that is designated type integer, the value 1230045 represents the integer number 1,230,045. In storage that is designated type float the value 1230045 represents the real number 0.30045 x 10l2. In general, the compiler interprets
d1 d2 . . . d7 of type integer as the integer number dl d2 . . . d7.
and
d1 d2 . . . d7 of type float as the real number 0.d3 d4 . . . d7 x 10d1d2
Given this situation, suppose the compiler must cause the contents of sum = 1230045 to be added to the contents of increment = 1250047,where they are both of type integer. The compiler might apply the usual column-by-column addition algorithm:
Here, 2480092, when stored in sum, represents the correct result. If sum and increment are of type real, then the content of sum represents the real number 0.30045 x 1012 and the content of increment represents the real number 0.50047 x 1012. Their sum is 0.80092 x 1012. However, if the above column-by-column addition algorithm is applied and the result stored in sum, then its contents will still be 2480092, but this now represents the real number 0.80092 x 1024. This is incorrect by a factor of 1012. To represent the correct result, sum should contain 1280092. The difficulty is, of course, that the same algorithm should not be applied for the addition of numbers of both type integer and type float. Two distinct algorithms are needed, because two distinct representations are used. In general, the algorithms used must depend on the data types of the variables involved. The compiler can choose the correct algorithm only when it knows the data types.
Thus it is essential to declare the data type of each variable so that the compiler can choose the proper algorithm to achieve the intended result. Type declarations also allow high-level language compilers to build in checks for validity. Such checks may generate error messages during compilation or during execution of the program. Languages with more restrictive rules for the manipulation of different data types, called strongly typed languages, allow more checking. For example, Pascal's strong typing prevents the contents of a variable of one type from being copied into a variable of a different type. C, FORTRAN, and COBOL allow this to be done in some cases but not in others.
The C data types integer, float, and char or their equivalents are now standard in most high-level languages. The values they may assume, and the operations that may be performed on variables of these types, are specified in each language.
Individual writers, even whole magazines or journals, have their own writing style. Often a glimpse at a few paragraphs can give clues to the author or the type of publication. Still, there are general rules to follow for acceptable style; entire books have been devoted to this subject. Style will always be in style.
Dress, carriage, and response are parts of personal style, as are straightness of teeth, polished or scuffed shoes, and a fast or slow gait. Program style is determined by overall appearance as well as by details of implementation. We want to see the logical structure of a program clearly; too many details cloud the picture. Data abstraction and functional modularization are tools for sharpening the picture. Hiding information, so that only parts of a program that need it can see it, also provides better focus. People react differently to unexpected situations: some become erratic while others remain calm, going cheerfully about their business. Programs should react to unexpected data with aplomb, letting us know about errors, but getting on with the job when possible. Details of a program should not affect its logical structure, only its efficiency. Details can make an otherwise stylish program sloppy, slow, and in need of repair, or they can finish the design so it is elegant, sleek, and well-tuned. What we see isn't always what we get, but stylish programs suggest a better thought-out design and product.
Since good programs must be written with style, guidelines are offered here for this purpose. A good program is correct, easy to read, and changeable through a reasonable amount of effort. Whether or not it should be efficient depends on the application. In some cases an efficient program may be written with the same effort as an inefficient one. In other cases it will be necessary to put in more effort to achieve efficiency, so the additional programming may be done only if it will bring substantial (or required) savings in computation time.
What's in a name? "A rose is a rose is a . . . ." "There's more form than substance." Perhaps these sentiments are true, but in a well-presented program there is a great deal in a name. One function is not another function, and understanding of substance is enhanced by form.
Indentation and proper spacing serve to delineate significant components of a program. Choosing names to convey and delineate purpose is also extremely important. Even without the descriptions given for the functions of Figure 1.3, the names of each function, variable, and constant almost provide, by themselves, enough information to see what each does. On the other hand, inappropriate names can be very misleading and distracting.
Reading identifiers to understand what a program does requires reading the entire program. This is too demanding. After all, when selecting a book, no one wants to be forced to read from cover to cover just to see what it is about. The same holds for a program, program documentation must be provided for this purpose. Good name selection is not enough. The main program and each of its functions must start with comments that allow users (including its author) to understand readily what it does and what its inputs, outputs, and parameters are. The main program's documentation then tells immediately what it does. No further reading is necessary unless someone wants to know how it is done. Similar comments can precede program segments that implement tasks of some complexity. To a great extent, the structure of a function, coupled with the documentation of each of its tasks, explains how the function does what it does. In this sense, structured programs (with proper comments) are self-documenting. Functional modularization and data abstraction help to elucidate structure by obscuring detail. Some programmers are free to develop their own style for delineation and documentation; for others it may be specified rigidly. The case study presented later gives a complete program with documentation as a guide for annotating your own programs. As a rule, complete documentation is not included in programs appearing in this book, since in effect the text itself serves as documentation, discussing completely each program presented. Still, programs will be annotated for clarity. Proper documentation is a prominent aspect of every good program and should become a habit of the programmer. Since the top-down approach requires a description for each task, the documentation for a task may be done as it is introduced, even before it is written.
High-level languages allow the definition of three kinds of variables: local, nonlocal and global. A C program consists of functions. A function of a program may reference
1. Local variables, to which it alone has access
2. Nonlocal variables, to which it and some other functions of the program have access
3. Global variables, to which all functions of the program have access
A variable is referenced by a function in order to copy, modify, or simply look at its value.
High-level languages treat variables in differing ways. FORTRAN, for example, considers variables to be local to a function unless they appear as formal parameters of that function (in which case they are nonlocal). Variables stored in special common areas of memory are global. C determines whether a variable is local, nonlocal, or global by using block rules. In Figure 1.3 candidates is local to primes, factor is local to remove, and nextmultiple is local to delete, while n is nonlocal or global to each.
Each high-level language has its own rules to give one function access to variables of another. Merely using the same variable name in two functions will not normally allow one to reference a variable in another. For example, i in create and i in print (Figure 1.3) do not represent the same variable; each is local to its function. If this were not so, functions could not be written independently. Once a complex problem has been refined, different individuals or groups should be able to develop components independently. Otherwise, each time a group used a new variable name, it would have to check that no other group used the same name.
The issue here is really communication between functions of a program. Communication between functions--allowing one to reference variables also used by another--occurs in two basic ways: using nonlocal or global variables, or using formal parameters in defining functions.
When a function changes the value of a variable used by another, and the variable is not communicated (or passed) between them as a parameter, a side effect has occurred. Side effects make it extremely difficult to understand what functions do. It is easier to see what a function does when we can be sure that only the parameters and the local variables will be affected by the execution of the function. The communication structure of a program is clearer when information is communicated explicitly by the use of parameters. This shows "who is doing what to whom." For example, in delete (Figure 1.3), no side effects can occur, since the only nonlocal variables factor, n, and candidates all appear as parameters. Thus the only variables not local to delete that it can reference are factor, n, and candidates.
At one extreme, it is possible to make all variables global--every function may then reference any variable. Making all variables global requires extremely careful adherence to the use of variable names and increases the probability of side effects. COBOL programs are typically written this way. However, such programs use well-defined file structures, deal with high-volume input and output, and use relatively simple algorithms, so this method may not cause difficulty.
The other extreme is to use only parameters between functions. This may not always be possible. For example, storage considerations may intrude, as with arrays in Pascal.
Communication between functions by using parameters may be a one-way or a two-way street. In some high-level languages, like FORTRAN, any change in the value of a parameter in a called function is passed or reflected back to the calling function. Other languages, such as C, allow one component to communicate information to another yet never reflect changes made to the parameter's value. Upon return, the parameter's value is the same as prior to the call. Also, upon return from a call, different languages treat local variables of functions differently. Some preserve their values between calls, while others do not. In FORTRAN it is possible to have local variables retain their values between invocations of a function; in Pascal it is not. In C either case may apply. Values may be preserved or erased as desired.
Functions receive and output data. In primes, what happens if n is negative or so large that it exceeds the storage capacity allocated to the data structure implementing candidates? Think how upset a company's personnel would be if no one received paychecks because the input data for one employee was not valid. Or suppose each employee received an output check equal to the entire payroll. Defensive programming is ensuring that your programs guard against such outcomes by checking for invalid data, incoming or outgoing, and doing something reasonable when such data are discovered. What is reasonable can vary from signaling an error and stopping further processing to simply outputting an error message, ignoring the invalid data, and continuing processing. Sometimes the correct data may be inferred from the invalid data, but this approach must be taken with great caution. The important point is to ensure that errors are discovered. It is safer to have no output than output that is in error but thought to be correct. Invalid data is a very serious problem, regardless of whether it is due to design or to happenstance. Validation functions for input and output should be used, even though it is not always easy to see how to guard against all possible errors. This text does not have space to dwell on the issue of data validation, but it should always be in your mind.
Consider a new problem: count and print the number of primes that are no greater than n. Instead of immediately attempting a solution, can you think of a program that already solves a related problem? You've already seen one: primes. Perhaps it can be changed to help with the solution. Looking at the refinement of primes (Figure 1.3), you can see that replacing function print by a count function that prints the proper count does the trick. The solution countprimes, using the changed primes and count, is as follows.
Solutions are rarely obtained so easily. Yet this example teaches us something. Programs that have been designed wisely, with an eye to generality, may often be used as tools in the solution of related problems. When beginning the development of a solution to a problem, see first if a program for a related problem is already known, and if so whether it can be adapted. This can save significant time, effort, and money compared to writing a new program or function.
It was easy to see what to change and how to change it in our example, because primes is functionally modular, with narrowly defined tasks and independent functions. Changes are rarely as straightforward as this; for contrast, consider changing the algorithm anotherprimes to a program for countprimes. In general, though, isolating functions that carry out a single narrowly defined task tends to generate lower-level functions that are clear, simple, and of moderate size. At higher levels, such single-task functions need not be simple. For example, a function to "Select the best next chess move" is such a function, but it is not simple. The lower the level of a function that needs changing, the less the effort required. However, the higher the level of the task for which one can adapt a known program, the greater the savings, since much refinement is avoided. In an ideal situation, changes require little effort and benefits are great.
Often a programmer's assignment or goal is to increase the efficiency of a program, and this will involve changing the way data are stored. If the program has been written using data abstractions, it is much easier to see exactly which functions need changing. For example, in primes, to change the implementation of candidates involves changing only its declaration and set, insert, omit, and belongs.
Verifying a solution means checking that program segments and functions do their tasks correctly. It is difficult to verify programs, although some formal methods are known. This text will illustrate how a program can be verified informally, but rigorously, for appropriate examples. For most of the small examples, verification is left to the reader.
Although only proper verification can ensure the correctness of a program, debugging can help in locating mistakes. Your goal should be not to run or even code programs until you are sure the algorithm is correct. Even if you are sure of the algorithm, debugging tools should be employed. Then, when your program fails to work correctly (as you know by now it will), you can track down the cause without the help of a Holmes or Watson.
In addition to debugging aids provided by your computer system and compiler, good programming techniques facilitate debugging. For example, it is important to learn to display appropriate error messages and information. The top-down approach includes debugging individual functions or program segments as they are refined, so that debugging proceeds as the program is developed. Verifying, debugging, and documenting all require basic understanding of the program and much the same information. To a large extent, then, they should be done concurrently with program development. During development you have the concepts and information fresh in your mind.
The main program and the other functions may each be debugged independently, just as they may be verified and documented independently. This requires stubs and drivers.
A stub takes the place of a function. It should have the same name and parameters as the function and, when called, should output a message indicating it was called. For example,
A driver plays the role of a function that calls another function, and is used to debug the called function. The driver should set up test values for the parameters used by the function it calls, output those values, call the function, and output the returned values. For example,
Using drivers and stubs allows any individual function to be tested and debugged even though the functions that call it and are called by it have not yet been written. Within the function, program segments that correspond to algorithmic tasks can be isolated. A statement can be inserted before and after each of these segments to output a message indicating that the segment was reached during execution, giving the values of variables it worked on, specifying that it was exited during execution, and giving the modified values of the variables.
In this way, you can see the progress of a program during its execution by studying the output of the drivers, stubs, and function being tested. With this approach, you never find yourself with a program that has not run correctly and for which you have no output, or output that gives no clue as to what went wrong or where. Suppose function M has just been refined and is to be tested and debugged. Its refinement may include calls to other functions not yet written or debugged. To test and debug M you must
1. Write a driver to call M and feed it test data on which to work
2. Replace each function of M's refinement by its own stub
For example, to test and debug remove (Figure 1.3) requires
1. A driver to call remove and feed it test values for n and candidates
2. Replacing nonprimes and delete by their individual stubs
This assumes that primes (which calls remove) and noprimes and delete (which remove calls) have not yet been verified or even written.
Instead, suppose primes has already been debugged. Primes, in conjunction with the driver used to debug it, could then be taken as the basis for remove's driver. Next, this driver plus remove could be used as the basis for delete's driver. This way of proceeding parallels the top-down development of the program. It amounts to inserting one new function at a time into an already debugged program.
To illustrate the proper way to use debugging statements, a complete listing and output is given for an execution of the case study program later in the chapter.
The discussion of good programming style may be summarized with the following guidelines.
1. Take care to present programs well.
Don't choose a name without a purpose.
Don't leave a component's purpose unspecified.
Descriptions should be simple even if tasks are not.
2. Communicate well.
Store data only where it is needed (use local variables).
Pass information explicitly when needed elsewhere (use parameters).
Avoid side effects.
3. Use data abstraction.
This is the basic way to make programs independent of data implementation, and it makes implementation changes easier and more reliable.
4. Functionally modularize programs.
Functions should execute a simple, narrowly defined task.
It should be possible to determine what a function does by looking only at it.
Changes to a function should not necessitate changes in other functions.
Prevent unreasonable input and output data by defensive programming.
5. Use debugging aids.
Also verify your programs.
Of course, strict adherence to rules may not always be possible or even yield the best results. Knowing how or to what extent to apply programming rules comes only from experience in using them and in studying their effects.
Sometimes the time of execution or the storage required by a program, or both, are limited. Analysis helps pinpoint parts of a program whose efficiency may be worth trying to improve, because they are executed frequently or require large amounts of storage. Such analysis can be very difficult, and simulation of the program may be needed for estimates. Simulation means that the program is executed repeatedly for appropriately chosen data, and the results are averaged or otherwise statistically analyzed. Sometimes it is possible to analyze how these requirements increase as the amount or size of the data increases, even though we cannot say what happens exactly for smaller amounts or sizes. This is called asymptotic analysis. When exact analysis cannot be done, we settle for bounds on the time and storage required.
The nonmathematically inclined reader may want to skip the following analysis of primes (Figure 1.3), which demonstrates how to go about informally analyzing a program and shows how trade-offs arise. Even such simple programs do not necessarily have simple analyses.
When a statement is said to take constant time, it means that the statement is always executed in the same amount of time, whatever the current values of the variables it processes. Clearly, the execution time of primes is given by the sum of the execution times of its three components. In what follows it is assumed that insert, belongs, and omit all take constant time (notice that for the array implementation for candidates (Section 1.3.2) this will be true, but set takes time proportional to n).
Create executes set once and insert exactly n - 1 times. Similarly, print executes its if statement n - 1 times. The amount of time the if statement takes depends on whether belongs is true or false but requires, at most, the time for belongs plus the time for printf.
Remove is more complex. Its initial assignment statement takes constant time, to which must be added the loop time. The loop is executed
Delete's own loop is executed for each multiple of factor between 2 x factor and m x factor, where m is the largest number of times that factor divides into n. m is the integer part of n/factor denoted by
or
But 1/2 + 1/3 + . . . + 1/n is roughly the natural logarithm of n, denoted by ln n.Thus the entire time for the loop of delete is a constant (for omit and the assignment statement) times
Adding everything, we get a good execution time estimate of
where C1, C2, C3, and C4 come from the times for condition evaluation, assignment statement execution, and set, insert, omit, and belongs.
For large n, this expression is dominated by the term C4n1n n. In fact, for large enough values of n, the expression will be no greater than C n1n n for an appropriate value of C. We describe this concisely by saying the expression is O(n1n n), read "order n1n n"; this notation will be used throughout the text.
By the storage requirements of primes is meant the total storage required for its data structures. Except for a few variables, the storage is required primarily for candidates and will be determined by its implementation. The analysis reveals that the bulk of the execution time for primes is spent executing the loop in delete. Consequently, to improve its time we speed up the time of the loop itself, or reduce the number of times it needs to be executed. For the array implementation, the storage required will be proportional to n, and this is where the bulk of the storage required is needed.
Primes can be improved in a number of obvious ways. Except for 2, no primes are even. Hence all other even numbers can be eliminated from consideration. This means that factor need never take on even values, so it can be increased by 2 instead of 1 in remove and can also be initialized to 3. Delete can be changed so that nextmultiple takes on only odd multiples of factor. With a little more work, candidates can be cut to roughly half its size by eliminating even integers. This will necessitate changes to set as well as changes to the for loops in create and print, but it reduces the storage needed by about one-half and the time by more than one-half.
Perhaps a less obvious improvement is to modify the increase of factor in remove so that, instead of increasing by 1 (or 2), factor increases to the value of the next prime in candidates (see Exercise 8). To realize this saving fully, it is necessary to use a new data structure, the list or the balanced binary tree, for the collection. Lists are discussed in Chapter 3, balanced binary trees in Chapters 7 and 9. These would save not only time but storage as well. Borrowing a result from mathematics about the distribution of prime numbers, we can state that any version of primes that stores all the primes from 2 to n in a collection will need n/ln n storage locations, since there are about that many such primes. Thus we will run out of storage before we run out of time!
Primes may be written so that its execution time increases but its storage needs decrease, or vice versa. Thus time is traded for storage, as is often done. Primes represents one extreme where all the primes are saved. A version of primes in which no primes are saved is at the other extreme (see Exercise 10). This version would require significantly more time.
Programs carry out certain basic operations. For example, primes executes assignment statements, evaluates conditions, and executes set, insert, omit, and belongs. In fact, its total execution time equals the number of times each of the operations is executed multiplied by the time taken by that operation. Determining the number of basic operations performed by a program to solve a problem allows evaluation of its practicality. For illustration, suppose that 1,000,000 basic operations can be carried out in 1 second by a computer. Then the number of basic operations that it can carry out in 1 year is
1,000,000 basic operations/second X 60 seconds/minute X 60 minutes/hour X 24 hours/day X 365 days/year
This is fewer than 1013 basic operations/year, and this is assuming that the computer is available for the exclusive use of the program and that it will never fail during the year. Thus 1013 can be taken as a benchmark figure--any program that requires a number of operations on this order to solve a problem is not feasible!
How much storage is available is determined by your computer system. The amount needed is surely not feasible when your program aborts during execution with a message indicating insufficient storage, or when the compiler tells you there is insufficient storage. If you run out of time or storage, you must then abandon the problem (and perhaps your job), find a more efficient program, or trade time for storage.
This section illustrates the way a flowchart and a program are developed for a problem connected with the game of bowling. The way in which the spirit of the structured programming philosophy is followed is more important than the particular development.
Bowling, as you may know, consists of ten frames. In each frame, there is a chance to knock down ten pins by throwing one or two balls down the bowling alley. To start, you roll the first ball of a given frame. If all ten pins are knocked down, a strike is achieved for that frame, and you earn a frame score of 10 plus the total number of pins knocked down on the next two rolls. If any pins remain standing, you roll a second ball for the frame. After this roll, if all pins are down, you have a spare, and a frame score of 10 plus the number of pins knocked down on the next roll. If any pins remain standing after the second roll, then the result is an open frame, and the frame score obtained is given by the total number of pins knocked down on the two rolls of the frame. A strike or spare occurring on the last (the tenth), results in two or one additional rolls, respectively. The total score for a game is the sum of all the individual frame scores.
Getting twelve strikes in a row results in the maximum attainable score of 300. In this case, twelve rolls are made. The least number of rolls possible is eleven and the greatest is twenty-one. In fact there is a correlation between the number of rolls in a game and the game score. Many rolls correspond to low scores and few rolls to high scores. The better a bowler you are, the fewer rolls you get!
Example 1.1
The problem is to print the total score for each of a series of games, as well as the minimum, average, and maximum scores. Assume the input is given as a series of roll scores for each game and includes at least one game.
An initial flowchart might be as shown in Figure 1.5(a). If the three tasks can be carried out correctly, in the sequence indicated, then the problem is solved. The flowchart breaks down the original problem into three smaller problems. Obtaining their solutions and sequencing them correctly provides the solution to the original problem. This is the top-down approach to problem solving. Next, it is applied to each of the three problems.
Problem 1 is transparent enough. Problem 3 is clearly solved by the expanded or refined flowchart shown in Figure 1.5(b).
Problem 2 needs to be refined. It seems clear that the basic structure for its solution is a loop, within which each game is processed. When all games have been processed, the loop should be exited. (See Figure 1.5(c).)
The new problem introduced as task 4 must be solved next. The input for this new problem will be the roll scores that must be processed for the new game. A basic looping structure can accomplish the task. The loop task will be executed ten times, once for each frame. Each execution calculates the score for the current frame and updates the game score and a frame counter, frame. Prior to entering the loop, frame must be initialized to 1, and gamescore to 0. Other initialization may be required. After the loop is exited, the game score must be printed, and proper updating must occur. This refinement is shown in Figure 1.6.
Suppose that each time the programmer expands a task, the expanded version of the task does in fact solve the problem introduced by that task. Then the programmer knows that, whatever the current structured flowchart, it must represent a solution to the original problem as long as each of its tasks can be carried out correctly. The detailed structured flowchart of Figure 1.7 is thus a solution to the problem, as long as each of its tasks can be carried out correctly. It is detailed enough so that we know how to carry out (or program) each of its tasks except for 5, 6, 7, and 8. However, if the high-level language chosen for the program allows direct implementation of those tasks, then no more detail is needed to complete the solution.
Instead of increasing the complexity of the flowchart of Figure 1.7, tasks 5-8 can be functionally modularized.
Functions for tasks 7 and 8 appear in Figures 1.8 and 1.9. The solution to the original problem will then consist of Figure 1.7 plus the functions for tasks 5-8. This illustrates the application of structured programming to a relatively simple problem. Note again the importance of choosing variable names that convey information about the meaning and use of the variables. Good names make the algorithm clearer. Note that C compilers normally treat names as distinct only when they differ in the first eight characters, so some care must be taken. In this text, however, this constraint is ignored for clarity.
When task 7 is entered, the variables rollscore and r1 must contain, respectively, the first roll score of the current frame and the next roll score. Consequently, before entering task 6, the first two roll scores of the game must be read into rollscore and r1. This is the "other initialization" required of task 5.
The conditions "strike" and "spare" (Figure 1.8) are actually implemented as "rollscore equals 10" and "(rollscore + r1) equals 10," respectively. To emphasize the fact that complexity in a flowchart should be limited, Figure 1.10 is the complete detailed flowchart for the solution as it could appear without functional modularization. Descriptions do not appear; the chart simply indicates the structure of the solution. The flowchart can be derived by adding the detailed expansions of tasks 5-8 to Figure 1.7.
The program now follows directly from the flowcharts. Notice that its structure parallels the flowcharts', that we have attempted to minimize side effects by passing information between components explicitly as parameters, and that information needed only by a component is kept local to that component.
The following is a complete listing and output of a version of the Bowling Scores program that contains statements used as debugging aids (the boxed lines). This listing demonstrates how to use such statements and what they can tell us as we peruse the output. The roll scores of the two games that served as input are
The prompts for input are in the program. They have been omitted from the output.
The output of the program is as follows.
Structure is important for algorithms, programs, and data. Structured programming is a philosophy as well as a defined methodology to guide the construction of algorithms and programs. It involves a top-down approach: starting with a given problem, then using stepwise refinement, and breaking problems into smaller component problems that then may be solved independently and subsequently combined. The overall goal is to write programs that are easily understood, debugged, and changed. Data abstraction and functional modularity are important elements of programming style to be incorporated into this approach. Algorithm and program structure have been stressed in this chapter and will continue to be emphasized throughout the book, as will the equally important choice of data structures. The next chapter discusses record and array information and pointers.
1. In Figure 1.1 suppose there are n = 100 houses and you must visit houses 3, 10, 50, 7, and 82 (in this order). How much distance must you travel in each town?
2. Why do no more nonprimes remain in candidates when factor >
3. Explain the difference between a function and program segment implementation of a refinement.
4. a. What determines the largest value of n for which each of the two array implementations for candidates will work?
b. Discuss any significant differences between set, insert, omit, and belongs for the two implementations of candidates.
c. Modify the second implementation so that it works for larger n--say 20 times its current limit.
d. Write a function copy with parameters c1 and c2. It must treat them as data abstractions with the operations set, insert, omit, and belongs and is to return with c2's contents identical to c1's and c1's contents unaltered.
5. Change primes so that even numbers are not considered as values for factor or nextmultiple.
6. Change your solution to Exercise 5 so that even numbers, except 2, do not appear in candidates. Use only enough storage for 2 and the odd numbers between 2 and n.
7. This is the same as Exercise 6 except that candidates must use only enough storage for 2 and the odd primes between 2 and n.
8. Change remove so that instead of increasing factor by 1, factor is increased to the value of the next prime in candidates. You may choose to do this by starting with remove from your solution to Exercise 7.
9. Analyze the time and storage required for your solutions to Exercises 5 to 8.
10. For the prime problem, find a solution that stores no primes.
11. Explain why we must know the data type of the information stored in variables A and B in order to multiply their contents correctly.
12. Suppose that integers are represented as in the example of Section 1.3.2. Write an algorithm, in English, that will allow someone who knows addition tables up to 9 to compute the correct sum of the contents of A and B. The algorithm must yield the correct result no matter what integers are stored in A and B.
13. This is the same as Exercise 12 except that reals are represented, and the algorithm should yield the correct sum represented as a real number.
14. Express the Bowling Scores program just as the prime number solution is expressed in Figure 1.3. What are its local, nonlocal, and global variables?
15. Modify the flowcharts and program for the bowling problem to obtain flowcharts and a program solving the same problem but also printing out the number of rolls for each game.
16. What functions might be inserted in Bowling Scores to check the validity of its input and output? Where would they go in the program?
17. What elements of style have been incorporated in the programs of Sections 1.9.2 and 1.9.3?
1. Write and run a program to print all perfect numbers no greater than n. A number is perfect if it is equal to the sum of its factors; thus 6 is a perfect number (6 = 1 + 2 + 3). The program is to create a collection candidates of all candidates for perfect numbers, remove those that are not perfect from candidates, and print the numbers remaining in it. The program must treat the collection with operations set, insert, omit, and belongs as a data abstraction.
2. Write a program to read in integers, store them in a collection, then read in more integers, remove each of these from it, and finally print all the integers remaining in it. The program is to treat the collection of integers as a data abstraction with the operations of set, insert, omit, and belongs.
3. a. Why does the Bowling Scores program require that the input consist of at least one game?
b. Change the program so that it handles the case of no games as input in a reasonable way.
1.2: A Look Ahead
1.3: The Need for Structure
(a) Spokesville
(b) Squaresville
Figure 1.1 A Tale of Two Cities
primes(n) anotherprimes(n)
1. Create a collection called candidates, 1. Set X1, X2, . . . , Xn to
consisting of all integers from 2 to n. zero.
2. Remove all nonprime integers from 2. Set k to 2.
candidates.
3. Print all integers that remain in 3. If Xk is 1, go to step 7.
candidates.
4. Print k.
5. Set m to the integer part of
n/k.
6. Set Xk, X2k, . . . , Xmk to 1.
7. Set k to k + 1.
8. If k
 sqrt n, go to
sqrt n, go to step 3.
9. If Xk is zero, print k.
10. Set k to k - 1.
11. If k
n, go to step 9.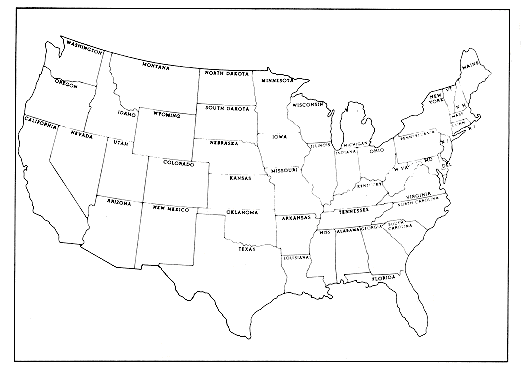
(a) Overview
Figure 1.2(a) Courtesy: Hammond Incorporated, Maplewood, NJ 07040.
(b) Detailed View
Figure 1.2(b) Courtesy: Hammond Incorporated, Maplewood, NJ 07040.
1.3.1 Using Structure
1.3.2 A Prime Example
primes(n)
int n;
{collection candidates;
create(n,candidates);
remove(n,candidates);
print(n,candidates);
}
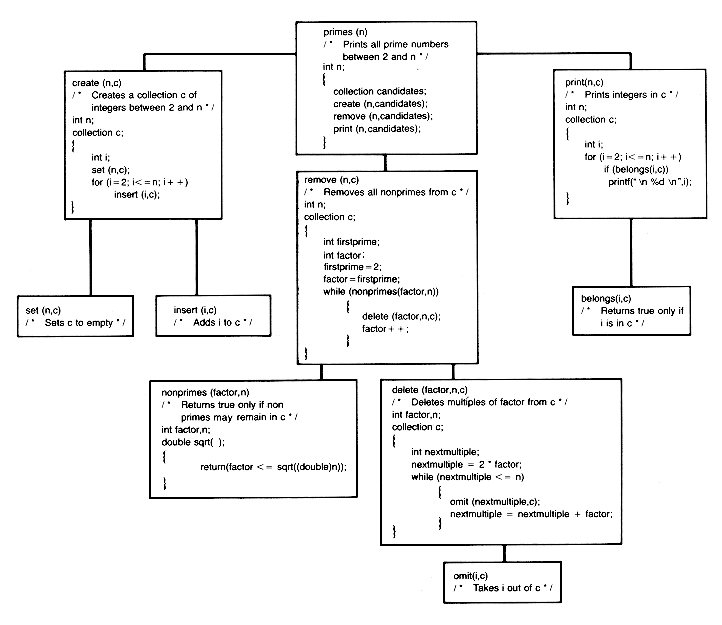
Figure 1.3 PRIMES Modularized
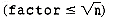 . But doing this will make remove more difficult to understand. It is better to consider the evaluation of the condition as a new task that must be refined. We are now ready to write the function for remove and to verify it. The three functions appear in Figure 1.3, where set initializes the collection candidates to empty, insert adds the integer i to the collection, nonprimes is a function assumed to return the value true when
. But doing this will make remove more difficult to understand. It is better to consider the evaluation of the condition as a new task that must be refined. We are now ready to write the function for remove and to verify it. The three functions appear in Figure 1.3, where set initializes the collection candidates to empty, insert adds the integer i to the collection, nonprimes is a function assumed to return the value true when 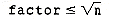 and false otherwise, delete removes all integers from candidates that are multiples of factor, and belongs returns the value true if i is in candidates and false otherwise.
and false otherwise, delete removes all integers from candidates that are multiples of factor, and belongs returns the value true if i is in candidates and false otherwise.primes(n)
int n;
{collection candidates;
int factor,i,nextmultiple;
int firstprime;
firstprime = 2;
double sqrt();
set(n,candidates);
for (i=2;i<=n;i++)
insert(i,candidates);
factor = firstprime;
while (factor <= sqrt((double)n))
{nextmultiple = 2 * factor;
while (nextmultiple <= n)
{omit(nextmultiple,candidates);
nextmultiple = nextmultiple + factor;
}
factor++
}
for (i=2;i<=n;i++)
if(belongs(i,candidates))
printf("\n %d\n",i);}
Candidates Implemented Candidates Implemented
as an Array as an Integer
typedef int collection[MAXN]; typedef int collection[1];
set(n,c) set(n,c)
/* Sets c to empty */ /* Sets c to empty */
int n; int n;
collection c; collection c;
{ { int i; c[0] = 0;
for (i=1;i<=n;i++) }
c[i] = FALSE;
}
insert(i,c) insert(i,c)
/* Inserts i into c */ /* Inserts i into c */
int i; int i;
collection c; collection c;
{ { c[i] = TRUE; int p,q;
} p = power(2,i);
q = (c[0]/p)%2;
c[0] = c[0] + (1-q)*p;
}
omit(i,c) omit(i,c)
/* Removes i from c */ /* Removes i from c */
int i; int i;
collection c; collection c;
{ { c[i] = FALSE; int p,q;
} p = power(2,i);
q = (c[0]/p)%2;
c[0] = c[0] - q*p;
}
belongs(i,c) belongs(i,c)
/* Returns true only /* Returns true ony
if i is in c if i is in c
*/ */
int i; int i;
collection c; collection c;
{ { return(c[i]); return((c[0]/power(2,i))%2);
} }
power (x,y)
/* Returns x to the power y */
int x,y;
{ int i,p;
p = 1;
for (i=1;i<=y;++i)
p = p*x;
return(p);
}
# define TRUE 1
# define FALSE 0
#include <stdio.h>
main()
{int n;
printf("\n n = ? \n");scanf("%d",&n);primes(n);
}
#define TRUE 1
#define FALSE 0
#define MAXN 500
typedef int collection[MAXN];
set(n,c)
/* Sets c to empty */
int n;
collection c;
{int i;
for (i=1;i<=n;i++)
c[i] = FALSE;
}
insert(i,c)
/* Inserts i in c */
int i;
collection c;
{c[i] = TRUE;
}
omit(i,c)
/* Removes i from c */
int i;
collection c;
{c[i] = FALSE;
}
belongs(i,c)
/* Returns true only
if i is in c
*/
int i;
collection c;
{return(c[i]);
}
primes(n)
/* Prints all prime numbers between 2 and n */
int n;
{collection candidates;
create(n,candidates);
remove(n,candidates);
print(n,candidates);
}
create(n,c)
/* Creates a collection of integers between 2 and n */
int n;
collection c;
{int i;
set(n,c);
for (i=2;i<=n;i++)
insert(i,c);
}
remove(n,c)
/* Removes all nonprimes from c */
int n;
collection c;
{int firstprime;
int factor;
firstprime = 2;
factor = firstprime;
while (nonprimes(factor,n))
{delete(factor,n,c);
factor++;
}
}
nonprimes(factor,n)
/* Returns true only if non
primes may remain in c
*/
int factor,n;
double sqrt();
{return(factor <= sqrt((double)n));
}
delete(factor,n,c)
/* Deletes multiples of factor from c */
int factor,n;
collection c;
{int nextmultiple;
nextmultiple = 2 * factor;
while (nextmultiple <= n)
{omit(nextmultiple,c);
nextmultiple = nextmultiple + factor;
}
}
print(n,c)
/* Prints integers in c */
int n;
collection c;
{int i;
for (i=2;i<=n;i++)
if (belongs(i,c))
printf("\n %d\n",i);}
1.4: Basic Constructs
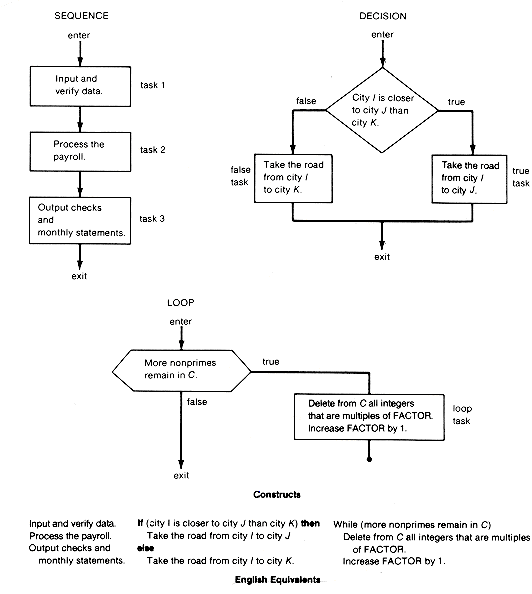
Figure 1.4 The Basic Control Constructs and Their English Equivalents
1.5: Top Down Design
1.6: High-Level Languages
1.6.1 Data Types
sum = sum + increment;
int sum, increment;
char check;
1.6.2 Data Representation
sum 1230045
+
increment 1250047
-------
2480092
1.7: Elements of Style
1.7.1 Expressing Purpose
1.7.2 Communication between Functions
1.7.3 Ensuring against Data Errors: Defensive Programming
1.7.4 Changing Programs
countprimes (n)
/* This function counts the prime
numbers between 2 and n
and prints the count.
*/
int n;
{collection candidates;
create (n, candidates);
remove(n,candidates);
count(n,candidates);
}
count(n,c)
/* Prints the number of integers
in c between 2 and n.
*/
int n;
collection c;
{int i,counter;
counter = 0;
for (i = 2; i<=n;i++)
if (belongs(i,c))
counter++;
printf ("\n The number of primes between 2 and %d is %d\n",n, counter);
}
1.7.5 Verification and Debugging
remove (n,c)
/* This is a stub for remove */
int n;
collection c;
{printf ("\n remove was called \n");}
removedriver ()
/* This is a driver for remove */
{collection candidates;
int n;
int sentinel = -1;
printf("\n enter a value for n between 2 and 27 \n");scanf("%2d",&n);while (n != sentinel)
{printf("\n remove has been called with n = %d\n",n);create(n,candidates);
print(n,candidates);
remove(n,candidates);
printf("\n remove returns n = %d ", n);printf("and candidates: \n");print(n,candidates);
printf("\n enter a new value for n or -1 to stop \n");scanf("%2d",&n);}
}
1.7.6 In a Nutshell
1.8: Time and Storage Requirements
1.8.1 Analyzing the Prime Example
 times, so the loop condition is evaluated
times, so the loop condition is evaluated  times. Assuming, for simplicity, that sqrt (n) takes constant time C, then
times. Assuming, for simplicity, that sqrt (n) takes constant time C, then  is the total time for the evaluation of the condition. If the loop task took constant time, then the total loop time would be the product of this constant and
is the total time for the evaluation of the condition. If the loop task took constant time, then the total loop time would be the product of this constant and  . Unfortunately delete's time varies, depending on the value of factor. Nonetheless, the total time for delete can still be derived.
. Unfortunately delete's time varies, depending on the value of factor. Nonetheless, the total time for delete can still be derived. n/factor
n/factor . Hence delete's loop is executed n/factor times for this value of factor. Since factor takes on values
. Hence delete's loop is executed n/factor times for this value of factor. Since factor takes on values  , the total number of delete's loop executions is
, the total number of delete's loop executions is

 . The condition of this loop contributes roughly its own constant times
. The condition of this loop contributes roughly its own constant times  . The initialization of nextmultiple in delete contributes its constant times
. The initialization of nextmultiple in delete contributes its constant times  .
.
1.8.2 Limits on Time and Storage
1.9: Case Study: Bowling Scores
1.9.1 Algorithm

(a) Initial Flowchart

(b) The Refined Flowchart

(c) A Loop for Processing the Games
Figure 1.5 Flowcharts of the Bowling Scores Algorithm

Figure 1.6 Refinement of Task 4

Figure 1.7 Refinement of Initial Flowchart

Figure 1.8 Refinement of Task 7

Figure 1.9 Refinement of Task 8
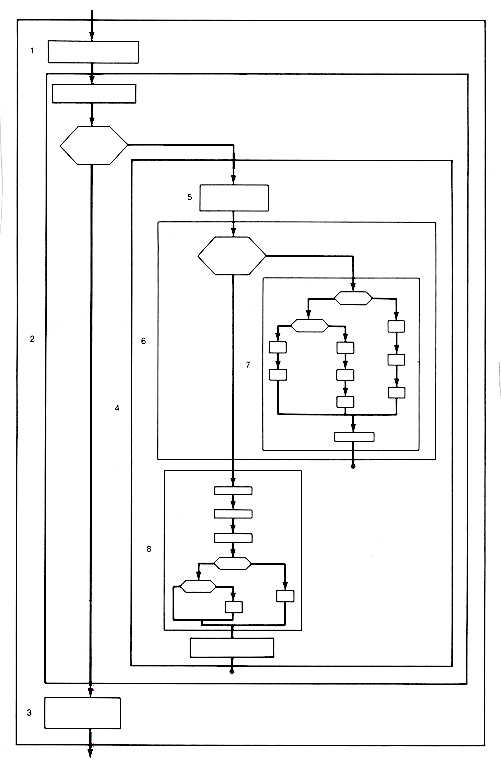
Figure 1.10 Too Detailed a Refinement
1.9.2 Program
#include <stdio.h>
#define TRUE 1
#define FALSE 0
main()
/*
Bowling Scores calculates and prints the game scores
for a series of bowling games. It also prints the
number of games bowled, the minimum, average, and
maximum of all game scores. The input consists, for
each game, of a sequence of roll scores. Each roll
represents the number of pins knocked down on the
corresponding roll. Its input must consist of at least
one game.
Main Variables
average - average of all game scores
gamescore - score for the current game
max - current maximum game score
min - current minimum game score
number - current number of games played
total - accumulated total of all game scores
*/
{int gamescore;
int number = 0, max = 0, min = 300;
int newgame = TRUE;
float average;
while (newgame)
{gamescore = gamecalc(gamescore);
update(gamescore,&number,&min,&max,&total);
printf("If you want to bowl another game enter a 1\n");printf("If you wish to stop enter a 0\n");scanf("%d",&newgame);}
average = ((float)total)/number;
printf("Minimum game %d\n",min);printf("Average game %f\n",average);printf("Maximum game %d\n",max);printf("Number of games %d\n",number);}
gamecalc (gamescore)
/* calculates gamescore for the current game.
Main variables
frame - the current frame
gamescore - score for the current game
rollscore - first roll score of the current frame
r1 - succeeding roll score after rollscore
*/
int gamescore;
{int frame, rollscore, r1;
gamescore = 0;
frame = 1;
printf("Please enter the number of pins down on this roll\n");scanf("%d",&rollscore);printf("Please enter the number of pins down on this roll\n");scanf("%d",&r1);while (frame <= 10)
framecalc(&gamescore,&frame,&rollscore,&r1);
return(gamescore);
}
framecalc(pgamescore,pframe,prollscore,pr1)
/* Calculates the framescore for the current game,
adds it to gamescore, increases frame by 1 and
updates rollscore and r1.
Main variables
pframe - pointer to the current frame
pgamescore - pointer to the score for the current game
prollscore - pointer to first rollscore of current frame
pr1 - pointer to next rollscore of current frame
framescore - score for current frame
r2 - rollscore after r1
*/
int *pgamescore,*pframe,*prollscore,*pr1;
{int framescore, r2;
if (*prollscore == 10) /* it is a strike */
{printf("Please enter the number of pins down on this");printf("roll\n");scanf("%d",&r2);framescore = 10 + *pr1 + r2;
*prollscore = *pr1;
*pr1 = r2;
}
else if ((*prollscore + *pr1) == 10) /* it is a spare */
{printf("Please enter the number of pins down on this");printf(" roll\n");scanf("%d",&r2);framescore = 10 + r2;
*prollscore = r2;
if (*pframe < 10)
{printf("Please enter the number of pins down");printf("on this roll\n");scanf("%d",pr1);}
}
else /* it is an open frame */
{framescore = *prollscore + *pr1;
if (*pframe < 10)
{printf("Please enter the number of pins");printf("down on this roll\n");scanf("%d",prollscore);printf("Please enter the number of pins");printf("down on this roll\n");scanf("%d",pr1);}
}
*pgamescore = *pgamescore + framescore;
*pframe = *pframe + 1;
}
update(gamescore,pnumber,pmin,pmax,ptotal)
/* This prints gamescore, and updates number, min, max,
and total to reflect gamescore.
Main variables
gamescore - current game score
pnumber - pointer to current number of games
pmin - pointer to current minimum game score
pmax - pointer to current maximum game score
ptotal - pointer to total of all game scores
*/
int gamescore, *pnumber, *pmin, *pmax;
int *ptotal;
{printf("gamescore \n");printf("%d\n",gamescore);*pnumber = *pnumber + 1;
*ptotal = *ptotal + gamescore;
if (gamescore < *pmin)
*pmin = gamescore;
if (gamescore > *pmax)
*pmax = gamescore;
}
1.9.3 Debugging
game 1--5, 4, 6, 4, 2, 4, 1, 4, 3, 4, 8, 1, 9, 0, 10, 10, 9, 0
game 2--9, 1, 10, 7, 3, 9, 0, 10, 10, 5, 4, 6, 4, 10, 10, 10, 8
#include <stdio.h>
#define TRUE 1
#define FALSE 0
main()
/* Bowling Scores calculates and prints the game scores
for a series of bowling games. It also prints the
number of games bowled, the minimum, average, and
maximum of all game scores. The input consists, for
each game, of a sequence of roll scores. Each roll
represents the number of pins knocked down on the
corresponding roll. Its input must consist of at least
one game.
Main Variables
average - average of all game scores
gamescore - score for the current game
max - current maximum game score
min - current minimum game score
number - current number of games played
total - accumulated total of all game scores
*/
{int gamescore;
int number = 0, max = 0, total = 0, min = 300;
int newgame = TRUE;
float average;
while (newgame)
{printf("\n CALLING GAMECALC FOR GAME #%2d",number+1);printf("\n-----------------------------\n");gamescore = gamecalc(gamescore);
printf("-===>RETURNING FROM GAMECALC WITH GAMESCORE");printf(" =%3d FOR GAME #%2d\n",gamescore, number+1);printf("CALLING UPDATE WITH; MIN TOTAL MAX NUMBER\n");printf("%26d%5d%5d%5d\n",min,total,max,number);update(gamescore,&number,&min,&max,&total);
printf("If you want to bowl another game enter a 1 \n");printf("If you wish to stop enter a 0 \n");scanf("%d",&newgame);printf("-===>RETURNING FROM UPDATE: MIN TOTAL MAX");printf("NUMBER\n");printf("%33d%6d%6d%5d\n",min,total,max,number);}
average = ((float)total)\number;
printf("FINAL RESULTS FOR ALL GAMES FOLLON:\n");printf("***********************************\n");printf(" ACCUMULATED TOTAL = %5d\n\n",total);printf(" MINIMUM GAME = %5d\n",min);printf(" AVERAGE GAME = %10.4f\n",average);printf(" MAXIMUM GAME = %5d\n\n",max);printf("NUMBER OF GAMES PLAYED = %3d\n",number);}
gamecalc(gamescore)
/* calculates gamescore for the current game.
Main variables
frame - the current frame
gamescore - score for the current game
rollscore - first roll score of the current frame
r1 - succeeding roll score after rollscore
*/
int gamescore;
{int frame, rollscore, r1;
gamescore = 0;
frame = 1;
printf("Please enter the number of pins down on this roll\n");scanf("%d",&rollscore);printf("Please enter the number of pins down on this roll\n");scanf("%d",&r1);while (frame <= 10)
{printf(" IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE");printf(" FRAME ROLLSCORE R1\n");printf("%49d%9d%9d%7d\n",gamescore,frame,rollscore, r1);framecalc(&gamescore,&frame,&rollscore,&r1);
printf(" IN GAMECALC, RETURNING FROM FRAMECALC WITH:");printf("GAMESCORE FRAME ROLLSCORE R1\n");printf("%53d%9d%9d%7d\n\n",gamescore,frame,rollscore,r1);}
return(gamescore);
}
framecalc(pgamescore,pframe,prollscore,pr1)
/* Calculates the framescore for the current game,
adds it to gamescore, increases frame by 1 and
updates rollscore and r1.
Main variables
pframe - pointer to the current frame
pgamescore - pointer to the score for the current game
prollscore - pointer to first rollscore of current frame
pr1 - pointer to next rollscore of current frame
framescore - score for current frame
r2 - rollscore after r1
*/
int *pgamescore,*pframe,*prollscore,*pr1;
{int framescore, r2;
printf(" STARTING FRAMECALC WITH: GAMESCORE FRAME");printf(" ROLLSCORE R1\n");printf("%36d%9d%9d%7d\n",*pgamescore,*pframe,*prollscore,*pr1);if(*prollscore == 10) /* it is a strike */
{printf("Please enter the number of pins down on this");printf(" roll\n");scanf("%d",&r2);framescore = 10 + *pr1 + r2;
*prollscore = *pr1;
*pr1 = r2;
printf("AFTER STRIKE, FRAMESCORE = %2d\n", framescore);}
else if ((*prollscore + *pr1) == 10) /* it is a spare */
{printf("Please enter the number of pins down on this");printf(" roll\n");scanf("%d",&r2);framescore = 10 + r2;
printf("AFTER SPARE, FRAMESCORE= %2d\n", framescore);*prollscore = r2;
if (*pframe < 10)
{printf("Please enter the number of pins down");printf(" on this roll\n");scanf("%d",pr1);}
}
else /* it is an open frame */
{framescore = *prollscore + *pr1;
printf("OPEN FRAME, FRAMESCORE %2d\n",framescore);if (*pframe < 10)
{printf("Please enter the number of pins");printf(" down on this roll\n");scanf("%d",prollscore);printf("Please enter the number of pins");printf(" down on this roll\n");scanf("%d",pr1);}
}
*pgamescore = *pgamescore + framescore;
*pframe = *pframe + 1;
printf(" LEAVING FRAMECALC WITH: GAMESCORE FRAME");printf(" ROLLSCORE R1\n");printf("%35d%9d%9d%7d\n\n",*pgamescore,*pframe,*prollscore,*pr1);}
update(gamescore,pnumber,pmin,pmax,ptotal)
/* This prints gamescore, and updates number, min, max
and total to reflect gamescore.
Main variables
gamescore - current game score
pnumber - pointer to current number of games
pmin - pointer to current minimum game score
pmax - pointer to current maximum game score
ptotal - pointer to total of all game scores
*/
int gamescore, *pnumber, *pmin, *pmax;
int *ptotal;
{printf("\n BEGINNING TO UPDATE WITH: GAMESCORE");printf(" NUMBER MIN MAX TOTAL\n");printf("%37d%8d%8d%4d%6d\n",gamescore, *pnumber, *pmin, *pmax, *ptotal);
*pnumber = *pnumber + 1;
*ptotal = *ptotal + gamescore;
if (gamescore < *pmin)
*pmin = gamescore;
if (gamescore > *pmax)
*pmax = gamescore;
printf(" LEAVING UPDATE WITH: GAMESCORE NUMBER");printf(" MIN MAX TOTAL\n");printf("%35d%8d%8d%5d%6d\n\n",gamescore,*pnumber,*pmin,*pmax,*ptotal);
}
CALLING GAMECALC FOR GAME # 1
-----------------------------
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
0 1 5 4
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
0 1 5 4
OPEN FRAME, FRAMESCORE = 9
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
9 2 6 4
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
9 2 6 4
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
9 2 6 4
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
9 2 6 4
AFTER SPARE, FRAMESCORE = 12
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
21 3 2 4
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
21 3 2 4
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
21 3 2 4
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
21 3 2 4
OPEN FRAME, FRAMESCORE = 6
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
27 4 1 4
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
27 4 1 4
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
27 4 1 4
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
27 4 1 4
OPEN FRAME, FRAMESCORE = 5
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
32 5 3 4
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
32 5 3 4
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
32 5 3 4
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
32 5 3 4
OPEN FRAME, FRAMESCORE = 7
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
39 6 8 1
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
39 6 8 1
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
39 6 8 1
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
39 6 8 1
OPEN FRAME, FRAMESCORE = 9
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
48 7 9 0
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
48 7 9 0
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
48 7 9 0
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
48 7 9 0
OPEN FRAME, FRAMESCORE = 9
LEAVING FRAMECALS WITH: GAMESCORE FRAME ROLLSCORE R1
57 8 10 10
IN GAMECALC, RETURNING FROM FRAMECAL WITH: GAMESCORE FRAME ROLLSCORE R1
57 8 10 10
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
57 8 10 10
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
57 8 10 10
AFTER STRIKE, FRAMESCORE = 29
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
86 9 10 9
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
86 9 10 9
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
86 9 10 9
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
86 9 10 9
AFTER STRIKE, FRAMESCORE = 19
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
105 10 9 0
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
105 10 9 0
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
105 10 9 0
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
105 10 9 0
OPEN FRAME, FRAMESCORE = 9
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
114 11 9 0
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
114 11 9 0
- = = = > RETURNING FROM GAMECALC WITH GAMESCORE = 114 FOR GAME # 1
CALLING UPDATE WITH; MIN TOTAL MAX NUMBER
300 0 0 0
BEGINNING TO UPDATE WITH: GAMESCORE NUMBER MIN MAX TOTAL
114 0 300 0 0
LEAVING UPDATE WITH: GAMESCORE NUMBER MIN MAX TOTAL
114 1 114 114 114
- = = = > RETURNING FROM UPDATE: MIN TOTAL MAX NUMBER
114 114 114 1
CALLING GAMECALC FOR GAME # 2
-----------------------------
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
0 1 9 1
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
0 1 9 1
AFTER SPARE, FRAMESCORE = 20
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
20 2 10 7
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
20 2 10 7
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
20 2 10 7
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
20 2 10 7
AFTER STRIKE, FRAMESCORE = 20
LEAVING FRAMECAL WITH: GAMESCORE FRAME ROOLSCORE R1
40 3 7 3
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
40 3 7 3
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
40 3 7 3
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
40 3 7 3
AFTER SPARE, FRAMESCORE = 19
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
59 4 9 0
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
59 4 9 0
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
59 4 9 0
STARTING FRAMECALS WITH: GAMESCORE FRAME ROLLSCORE R1
59 4 9 0
OPEN FRAME, FRAMESCORE = 9
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
68 5 10 10
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
68 5 10 10
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
68 5 10 10
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
68 5 10 10
AFTER STRIKE, FRAMESCORE = 25
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
93 6 10 5
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
93 6 10 5
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
93 6 10 5
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
93 6 10 5
AFTER STRIKE, FRAMESCORE = 19
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
112 7 5 4
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
112 7 5 4
IN GAMCALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
112 7 5 4
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
112 7 5 4
OPEN FRAME, FRAMESCORE = 9
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
121 8 6 4
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
121 8 6 4
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
121 8 6 4
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
121 8 6 4
AFTER SPARE, FRAMESCORE = 20
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
141 9 10 10
IN GARAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
141 9 10 10
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
141 9 10 10
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
141 9 10 10
AFTER STRIKE, FRAMESCORE = 30
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
171 10 10 10
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
171 10 10 10
IN GAMECALC, GOING TO FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
171 10 10 10
STARTING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
171 10 10 10
AFTER STRIKE, FRAMESCORE = 28
LEAVING FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
199 11 10 8
IN GAMECALC, RETURNING FROM FRAMECALC WITH: GAMESCORE FRAME ROLLSCORE R1
199 11 10 8
- = = = > RETURNTING FROM GAMECALC WITH GAMESCORE = 199 FOR GAME # 2
CALLING UPDATE WITH: MIN TOTAL MAX NUMBER
114 114 114 1
BEGINNING TO UPDATE WITH: GAMESCORE NUMBER MIN MAX TOTAL
199 1 114 114 114
LEAVING UPDATE WITH: GAMESCORE NUMBER MIN MAX TOTAL
199 2 114 199 313
- = = = > RETURNING FROM UPDATE: MIN TOTAL MAX NUMBER
114 313 199 2
FINAL RESULTS FOR ALL GAMES FOLLOW:
***********************************
ACCUMULATED TOTAL = 313
MINIMUM GAME = 114
AVERAGE GAME = 156.5000
MAXIMUM GAME = 199
NUMBER OF GAMES PLAYED = 2
1.10: Summary
Exercises
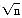 ?
?Suggested Assignments