


Now that the context in which problems will be solved and programs written has been presented, it is time to start studying seriously the effect of choice of data structure on the problem solution. Before we explore some simple examples, the two basic data structures--records and arrays--must be understood, along with the two basic operations on them--selection and traversal.
A record is a data structure made up of a fixed number of information items, not necessarily of the same type. In C records are of the type structure. In the text the two words record and structure will be used interchangeably. An array is a data structure made up of a fixed number of information items in sequence; all items are required to be of the same type. Records and arrays have boundless applications. Records are useful when the items are to be referred to by name, while arrays are useful when the items are to be referred to by their positions in the sequence. The fundamental importance of the array was recognized quite early in the development of programming languages; the structure, or record, has only recently been incorporated in many languages. Pointers are variables that
1. Refer or point to memory locations for variables
2. Point to data structures, or
3. Link the components of a data structure together
Records and arrays are the bricks out of which more complex data structures are built, and pointers are the mortar holding them together.
Just as a builder asks for bricks and mortar, programmers in a high-level language ask for data structures to help build their solutions. A data structure is specified by declaring a variable name to be of a specific type. Some languages restrict the choice of type to individual variables or to arrays of type int, float, or char. C includes these, plus other types such as records, pointers, and unions. However, it does not have type boolean, which is found in other languages. C does allow the user to give new names to types.
Records and arrays allow related items of information to be treated as a group. The individual pieces of information in a record (structure) are called members in C. In most languages they are termed fields, but this word has a special meaning in C. Since that meaning is never utilized in this text, both member and field will be used for the elements of a record. In the case of arrays the individual pieces of information are called entries. The merit of records and arrays lies in the fact that they allow random access to any one of their fields or entries. Random access is accomplished by direct location of the desired piece of information, without regard to sequence. This means that access to an item may be accomplished in a fixed amount of time, no matter what item was previously accessed. This contrasts with sequential access, where the time required to access an item depends on the number of items stored between that item and the last item accessed, since each of the intermediate items must be accessed. With random access, any member of a record or any entry of an array may be accessed in a fixed amount of time, typically a few millionths or billionths of a second.
Both records and arrays provide the means to treat related items as a unit, and both generalize the idea of variables containing one item to variables containing many items. Records will be discussed next, then arrays.
In C, memory can be thought of as consisting of storage elements of different length and complexity. Their complexity is determined by their type. The simplest storage elements have one of the three basic types, int, float, and char. Up one level in complexity are storage elements that have type structure. Among these, the simplest have exactly one member, which in turn has one of the basic types. A storage element of type structure for a book would be more complex; it might include members for its title, author, cost, and number of pages. Members are not restricted to one of the basic types but may themselves have type structure.
Consider the following C declarations:
Storage for the three variables amount, bankbalance, and text may be pictured as in Figure 2.1. From the figure it is clear that storage must differ in complexity for different variables. The simplest is obviously the one that stores only one piece of information, as does the storage element for the variable amount. The structure bankbalance is obviously more complex; it could also be made longer by adding more fields such as lastdeposit and lastwithdrawal. Of course, more memory is needed to store the variable text than to store bankbalance. The type structure generalizes the idea of an individual variable containing only one piece of information to variables containing related pieces of information. The amount of storage required determines the length of a record, while the record's structure determines its complexity.
It is now possible to write C statements that refer to the entire record text, its author field, or its last field, using the names text,text.author, and text.author.last, respectively. In earlier versions of C it was not possible to write statements that referred to entire structures.
Arrays provide another way to group either individual items or records. An array stores a sequence of entries; an entry in an array is referred to and located by its position in the sequence. An array has a fixed size and is homogeneous (that is, its entries must all be of the same type--say, of type integer or book). This contrasts with a record, whose fields may be of different types. An array entry is identified by qualifying the array name by the entry's position. To identify a member in a structure, the structure name is qualified by the member name. (Note that arrays can have entries of type structure, and structures can have members of type array.)
Consider the following declarations:
The declaration specifies the name of each variable (e.g., book_number) and its type for each of four variables. It also specifies the range of values for an array index for each of the four arrays. An array index refers to a position of the array. Book_number,author,prices, and library have array indexes that may take on values in the range 0 to 79, 0 to 39, 0 to 79, and 0 to 29, respectively. In C the first position in an array is always the zero position. Book_number[3], author[9], and prices[5] refer to the fourth, tenth, and sixth entries, respectively, and library[12] refers to the thirteenth character in the character string library.
It has already been mentioned that arrays are very useful when entries must be accessed randomly. This occurs when the order in which requests for access to entries cannot be predicted. Suppose an array stores the initial mileage for each car of a fleet of rental cars. As a car is returned, its initial mileage is needed to prepare a bill based on mileage used. The next car to be returned can be any rented car. To access its initial mileage directly requires the random access capability of arrays. Processing time is saved, since the information entry is located directly--no time is lost searching through other entries to find it. When information is accessed directly, in a constant time, it is said to be selected. Thus any array entry whose position is known can be selected.
Instead of accessing a single array entry, a programmer may wish to process an entire array by accessing and processing each entry in turn. Moving sequentially through the entries is a traverse. In this case, the program is said to traverse the array. Such a traversal would be required in order to print out, in order, the initial mileage of each car in the fleet. A complete traversal is accomplished when each entry has been processed exactly once. A simple loop, starting at the first entry and finishing at the last, will accomplish this. Another use of traversal is to find an array entry whose position is unknown. In this case, the loop is terminated when the entry is found. If the traversal is completed, it means the desired entry was not present.
Selection and traversal are two ways to access an array entry. If the entry's position is known, selection is the efficient way to access it. When successive array positions must be examined to find the entry, selection is not possible, but traversal may be used.
If the traversal terminates at the ith entry (because it is the desired one), then a time proportional to i is required, since the i - 1 preceding entries must be accessed before the ith entry is obtained. Selection, on the other hand, takes constant time. This is an important distinction between these two basic operations on arrays. Selection means you can go directly to what is wanted; traversal means you must rummage around to find it. Use selection when one or more accesses must be made in arbitrary order and traversal when each entry is to be accessed in sequence.
Example 2.1
Suppose that data, such as integers in the range 1 to 100, are stored in an array a, as shown in Figure 2.2. Given any valid index value in the variable i, print the number stored in the ith position of the array a.
This may be done by executing the C statement
This is a concise, easy-to-understand solution to Example 2.1. It takes a constant amount of time to execute, since it selects the desired entry of a. Note that when the value of the index i is 7, then the array entry with the value 87 is printed; when the value of i is 5, then the entry with the value 3 is printed. The index i is avariable that points to a particular entry of a. The current value of the index i determines the entry currently selected. Changing the value of i changes the entry to which it points. Thus the solution can be interpreted as the command "Print the entry of a to which the index i currently points."
Example 2.2
Let a be an array of length n, and let k be a variable containing an integer in the range 1 to 100. If there is some value of i for which a[i] contains k, then print that value of i; if there is more than one such value, print any one of them. If the value of k is nowhere in a, then print "-1."
Array a might represent the information kept by a car rental agency. For each i, array entry a[i] contains the account number, k, of the individual or firm currently renting car i. Example 2.1 thus requires finding the account now leasing car i. Example 2.2 requires finding the car being used by account k.
Example 2.2 could certainly be solved by traversing the array a, searching for an entry whose value equals the value of k. If one is found, its position in a would be printed. If the traversal is completed without success, "-l" would be printed. This solution is easy to code and could be written as follows:
Although this program segment for array traversal is simple, it is more complex than that for Example 2.1. Its execution time is proportional to the number of entries searched before the number in k is found, and if it is not found, the execution time is proportional to n.
Is it possible to find another way to solve this problem, one that will be as concise and clear as that for Example 2.1 and also execute in constant time? The answer is yes, if the information stored in a is represented in such a way that the program can select the correct value to print.
Such a program would start with creation of an array pointer of length 101, as follows. For each integer k (account number) between 1 and 100, if k does not appear in a, place "-1" in pointer[k]. If k does appear in a (it is an active account), place in pointer[k] the position of an entry of a that contains k. That is, place in pointer[k] the index value of an entry in a containing k. Thus, in Figure 2.3, pointer[3] contains 5, since a[5] contains 3.
With the array pointer available, the solution to Example 2.2 may be written as
This is the concise, easy-to-understand solution desired, and it executes in constant time. Again, the way in which the relevant information was represented in the program--that is, the way in which the data was structured--allows this solution to be achieved. Even in such a simple example, the way data is represented has a substantial impact on the resulting program.
Note that the use of the pointer array instead of a may cause some information available in a to be lost. This is because pointer captures only one of a's positions that contains a specific number, even though that number may appear in a more than once. Finally, a price in execution time must be paid to create pointer from a in the first place. However, if the solution to Example 2.2 needed to be executed repeatedly, for many values of k, then it probably would be worth the price. It is frequently the case that prior processing to extract or restructure data saves later processing time.
In terms of storage required, a takes up n storage entries, and pointer takes up 101 storage entries. If n is much larger than 101, then pointer even saves storage; if n is much smaller, it requires more storage. Thus it is possible to trade time for storage. It will become apparent that this is generally true: saving execution time requires more storage, and vice versa.
When the choice of data structure was the array a, Example 2.1 was solved using selection, but traversal was required to find a solution to Example 2.2. When the pointer array was chosen to represent information, selection could be used to solve Example 2.2 more efficiently. However, if we had wanted to know all the cars leased by account k, pointer would not have been sufficient. It would have been necessary to traverse a to find all the occurrences of account number k. Can you find a way to avoid this traversal?
Until now we have discussed one-dimensional arrays. High-level languages also provide arrays of more than one dimension. Thus the C declaration
defines a two-dimensional array of 5 X 3 or 15 entries, each of type integer. This array a can also be viewed as a collection of 5 one-dimensional arrays, each of length 3, or 3 one-dimensional arrays, each of length 5. Again, we can think of two variables i and j of the correct index type as pointing to an entry of the array. Thus a[i][j] refers to the entry of the ith row and jth column, or to the entry of a currently pointed to by i and j. We assume that the (i,j)th entry can be accessed in constant time, no matter what the value of i or j . That is, the (i,j)th entry may be selected. Traversal of two-dimensional arrays is also easy.
A two-dimensional array is symmetric if a[i][j] and a[j][i] contain the same value for all i and j between 0 and n - 1. Suppose a collection of n2 numbers, representing the distances between n(
Example 2.3
Suppose a programmer wished, perhaps as part of an input validation function for the data of an array, to check the array for symmetry. The programmer might choose to write a function check to return the value true if the array is symmetric and false otherwise. A simple traversal, as follows, will do the checking.
This program does a complete traversal of the appropriate n entries of the array a. However, it is inefficient as a solution for a number of reasons. First, it does not exit immediately from the loops, even though it may have just found that a was not symmetric. Second, it checks the diagonal elements, which will always satisfy a[i][j] = a[j][i]. Finally, it double-checks each off-diagonal entry. For instance, when i = 2 and j = 3, it checks a[2][3] against a[3][2], and when i = 3 and j = 2, it checks a[3][2] against a[2][3] again. A better version would be a modified traversal, such as
Be sure you understand why the modified lines of code eliminate the inefficiencies.
In C the record, or structure, is a basic data structure. In some languages the record is not a built-in feature but must be constructed from the data structures (such as arrays) that are available. To see how this construction might be done, assume C designers had provided the integer, float and char data types, and only one-dimensional arrays. Not only would records have to be constructed, but so would arrays of more dimensions if they were needed. There are two reasons for looking at ways to build data structures.
1. It affords insight into how compilers implement records and higher-dimensional arrays.
2. It demonstrates how programmers build new structures from those that are given in order to tailor data structures to specific needs.
Moreover, even though records and higher-dimensional arrays are available in C, there are times when programmers may find it preferable to use these construction techniques.
Let us consider how to represent n records, each composed of m fields of the same fixed type. Suppose m is 3. A natural solution is to take an array of length 3Xn, of the same type as the fields, and store the records in the array. The first record takes up the first three entries, the second record the next three entries, and so on, as in Figure 2.5. Each field of a record will be stored in the corresponding one of its three entries.
The ith record begins in position 3*(i - 1) of the array. Thus we may select the ith record. To access a specific field of the ith record (say, the third) requires that position 3*(i - 1) + 2 of the array be accessed. Although this is the (3*(i - 1) + 2)th array element, it contains the third field value of the ith record. Thus we may select any field of any record too.
It is also easy to traverse the records, using a loop. For example, the following function traverses the n records stored in the array a and prints the value in their kth field, where k may be 1, 2, or 3.
array is the name for the type: array of fieldtype of size 30
In C, since arrays must be homogeneous (consisting of entries of the same type), this method is applicable only to homogeneous records--those whose fields are all of the same type. How then to handle the more general case of records whose fields are not homogeneous? The following example demonstrates the general concept and then how it is achieved in C.
Example 2.4
Consider Figure 2.6, which represents an array cars containing a record for each car of an automobile rental agency. The record for each car has an entry for the make (characters), monthly rate (a real number), current mileage (an integer), and the rentee (characters). As noted, this array, with entries of different types, could not be constructed in C. For the sake of simplicity, the following discussion does not deal with the actual storage taken by a character, float, or integer variable, but assumes that each takes one element of memory. All the records in the array are 42 elements long, using 15 elements for the make, 1 element each for the monthly rate and current mileage, and 25 elements for the rentee field.
An offset gives the position of a data item with respect to a given reference point. When you say, "the third house from the corner," you are using an offset reference point. Each field has a field offset from the beginning of the record. In this case, the field offsets are 0, 15, 16, and 17, respectively, for make, monthly rate, current mileage, and rentee. The ith record has a record offset of 42X(i - 1) from the beginning of the array. The offset for its rentee field from the beginning of the array is 42X(i - 1) + 17, the sum of the record offset for the ith record and the field offset for the rentee.
In order to reference, for example, the current mileage field of the ith record, the programmer may refer to cars[42*(i-1)+16], assuming the first record starts in element zero of the array. Only the fields may be referred to by the programmer; the record itself cannot be dealt with directly as a unit. In C the task is simplified for the programmer by the use of structures and arrays of structures. Carrecord is defined as a structure and cars[100] as an array of 100 carrecords.
Then the C programmer may refer to the (i + 1)th record as a unit as cars[i], and to its mileage field by cars[i].mileage. Treating a record as a unit allows intentions to be stated more clearly in a program. It also allows for the contents of one record to be assigned to the storage for another record more efficiently. This is analogous to being able to refer to an automobile and say "Move that automobile from here to there," rather than specifying the automobile or the move by referring to each of its parts individually. Languages that do not provide the record data structure prevent the programmer from referring to a record as a unit in this way.
Note that the record referred to during the execution of a program may be changed merely by changing the value of i, but the field referred to cannot be changed, since field names may not be changed during execution. The variable names cars[i].mileage shows this. The value of array index i can be changed, but the name cars cannot be. This means that code referring to the ith position of an array, such as cars[i], may refer to different array entries as aprogram executes, by computing a new value for i. Code using a field name will always refer to that particular field.
This example gives a technique for sorting records in languages without strong typing constraints. Even in languages with such constraints, the compiler might implement cars in the actual computer memory as illustrated in Figure 2.6. In this case, if the initial array address in memory is 100 rather than 0, then the offset (or relative position) for the (i + 1)th record is added to 100 instead of to 0. The compiler can produce commands that calculate the actual position in memory of any field of the ith record by adding the record offset and field offset to 100. Then a programmer's reference to cars[1] is interpreted as a reference to the 42 consecutive locations 142 to 183. Similarly, cars [1].rate refers to the entry in location 157. This assumes the array starts at memory location 100. The offsets are independent of the starting location. When applied to homogeneous records, this method requires that cars be defined to be the same type as the record's fields.
Observe that the cars array preserves the homogeneity of type that is required of all arrays in C. Its entries are now all of the same specific record type. The array entries just happen to be of type carrecord, even though a record itself is not homogeneous. C allows operations to be performed directly on structures, treating them as a unit. Of course, the compiler hides the details of the records' implementation from readers of the program and provides facility in handling records.
The method just discussed is a single-array implementation. The second method of representing the n records is a multiarray implementation, shown in Figure 2.7. The method simply uses a different array for each field. Each array then contains information of the appropriate type only. There is no direct way to refer to the collective notion cars[2]. Instead, its data are given by make[2],rate[2], mileage[2], and rentee[2]. Selection of the ith record and traversal through the records is also possible for this method.
The single-array technique may cause problems when all entries are not of the same type. As noted, however, Example 2.4 shows offset calculations of the type that may be used by a compiler but are invisible to the programmer. The multiarray technique is useful in any language that provides arrays. Both techniques fail to give the programmer means to refer directly to, or to manipulate as a unit, an entire record composed of more than one field. The C approach provides the record data structure and makes the underlying details transparent to the C programmer, thus providing an elegant solution to the problem of treating information of different types as a unit.
When the records of a collection are not necessarily of the same length, they are called variable-length records. Looking back at the single-array and the multiarray representations for a collection of records, it is clear that selection of the ith record was possible only under the tacit assumption that the records were all the same length.
Suppose a field is added to carrecord for each previous rentee. Surely some newer cars will have few previous rentees, while older cars will have a long history of rentees. The programmer could decide to represent each car's record by using a single-length record large enough to accommodate the largest possible number of past rentees. This would aid in processing, as uniformity always does, but would waste a great deal of storage if many records actually have short histories.
With variable-length records, shorter records use fewer locations than longer records, as shown in Figure 2.8. Details of the implementation of such a collection of records must somehow specify where one record ends and the next starts. Separators between records would do, or a field associated with each record could give its total length. Using separators, the last element of the storage for a record would contain a special value denoting the end of the record's storage. If associated fields are used, the first storage element of each record would contain the record's length and would allow a determination of the last element of its storage. In either case, the ith record may no longer be selected, because its location cannot be calculated. However, given the position of the ith record, one can calculate the position of the (i + 1)th record.
Assuming the first element of each record contains its length, as in Figure 2.8, the following function accomplishes the traversal. A record of zero length is used as a sentinel to indicate that there are no more records in the array.
The record array here is simply an array of individual elements. The programmer imposes the record structure. Each field of the record must thus have the same type in C. Process is a function that does whatever processing is called for. Thus, traversal through the records can be used to access the ith record, but this takes time proportional to i.
No facility is provided in C to handle variable length records directly, though unions do afford a means of handling some variability. A union in C may contain data that can have different types and sizes at different times. Thus unions provide a means of using a single storage area for distinct purposes. Unions are declared in the same manner as structures. The compiler allocates enough memory to hold the largest member that can be stored in the union. Unions are consequently of fixed size but allow variation in the type of data stored. The programmer has to keep track of which type is currently stored in the union. Unions would not be of significant help in Example 2.4 with the list of rentees. In this case there can be more than a few distinct rentees for each car, and unions do not fit this type of variability. Lists, the topic of the next chapter, would be used for this example.
Variables of type book_lookup could contain either the title of a book or its location in a library (based on the Dewey Decimal System). Unions thus give some measure of variability in records. However, the records do not have variable lengths; they are of fixed length.
Unions may occur in structures, and structures may occur in unions.
Each individual structure of the catalog array can contain an "i.d." number and either a real number or character strings of length 50 in any of its entries. Then, for example, catalog[40].information.title refers to the member title in entry 40 of catalog.
Calculating the address of an item of data is not the same thing as accessing the item of data. The address of an item is its storage position, not its value. To access the item means to read its current value from memory or to store a value in its memory location.
Many authors associate the process of selection with the idea of access to an item, rather than with the calculation of the storage address of the item. They say that the ith item of a structure can be selected if, given the value of i, the program can access the item in a time that is independent of i. Such a structure is called a random access structure. This definition served well for early computers, in which arrays could reside in a single homogeneous memory. However, current practice includes radically different memory architectures.
Modern computers have memory hierarchies--that is, different kinds of memory--whose access times vary by one or two orders of magnitude from one level of the hierarchy to the next. It may well be the case that some portion of an array is stored in fast memory, such as high-speed cache memory, and some portion in slower central memory. Then the access time for an array element would depend on the index of the element (that is, its position in the sequence of the array), but the time required to compute the storage address would still be independent of the value of the index. Consequently, the process of address calculation should be thought of as separate from the process of access to the data. Selection thus denotes address calculation without access. Although it is important to grasp this distinction between address calculation and actual access, it is generally ignored in the explanations here, as in other texts, for convenience of exposition.
Our interest in the effect of data structures on program efficiency concerns the timing of various algorithms. Because access times may vary, depending on features of the physical computer that are completely hidden from the language, time will be measured here as if each program were executed on a computer that has a single homogeneous central memory.
The special techniques necessary to write efficient programs for computers with hierarchical memories are not within the scope of this text. Some computers even allow the exploitation of any parallelism inherent in an algorithm, which means that more than one operation may be carried out at a time. This text also largely ignores this possibility of parallel processing, although it is currently a topic of computer research.
If this array of material leaves you in disarray, keep going. Pointers will point the way!
In C, records can be stored in arrays. They can also be stored in an area of memory called the dynamic memory. Dynamic memory is managed automatically for the programmer, who can request and release storage as needed. Pointers are variables that point to data items. Those that point to array entries, as noted earlier, are called array indexes. Those that point to individual data items, or structures, are called pointer variables. By following a pointer, you can access a record. Sometimes it is necessary to access a record by following a sequence of pointers.
Pointers and pointer variables afford flexibility in structuring data but must be used with great care, since they can introduce subtle errors that cause difficulty in the debugging of a program. The errors are problems that arise when collections of records can expand or contract in unpredictable ways. Storage for such records must be managed carefully.
To understand pointers and pointer variables, it is practical to examine them in a more static context. They are useful even then, in solving problems involving variable-length records and the representation of arrays. A good way to become familiar with the workings of pointers and pointer variables is to solve the following promblem: Is there a way to store n variable-length records in a one-dimensional array so that traversal through the records is possible, and, more important, so that the (i + 1)th one can be selected?
The solution is not difficult conceptually. Suppose a pointer array pa is created, as in Figure 2.9. The information in pa[i] should state where the base, or origin, of the (i + 1)th record is in a. Thus pa [3] is 13, because the fourth record begins in a[13]. One describes this by saying that pa[i] contains a pointer to the (i + 1)th record in a. The variable i can be thought of as pointing indirectly to a record in a; to get to it requires an access to pa along the way.
Recall that records are represented by a sequence of consecutive entries, so pa[i] points to the first entry of the (i + 1)th record, its base. Once the base of a record and its field offsets are known, any field of the record can be selected. This technique of using pointer arrays is an old and very important technique in computer science. This kind of pointer is just an array index; it is also known as a relative pointer, because it indicates the position of the record in relation to the other records within the same array. This is different from the other type of pointer, the pointer variable, which refers to actual memory locations.
Selecting the (i + 1)th record is now possible by accessing pa[i] and following the pointer found there to the entry of a in which the (i + 1)th record begins. The base of this record has the name a[pa[i]]. Note that selection is being applied first to array pa, and then to array a. Each takes constant time, which is why we say the (i + 1)th record may be selected. It is also easy to traverse through the records using pa, as shown by the following program.
Using the pointer array costs additional storage but solves the problem posed for variable-length records. Relative pointers to records stored in an array are easy to use when language typing constraints are not violated.
As a programmer you may need to store a collection of records that are not all of the same type. In C they cannot be kept in a single array, since that would violate the array typing constraint, but there is a way out: simply declare each different type to correspond to one of the members of a union occurring in the record. With this trick, C treats records of different types as records of the same type. Another difficulty in C is how to store a collection of records of the same type when the maximum number of such records is not known in advance. Storing them in an array requires specifying the length of the array, but the programmer may not know what this should be. A practical solution to this problem is provided by the dynamic memory.
So far, by grouping records in arrays, it has been possible to refer to a record by its position in the array. This eliminates the need to attach a separate name to each record of the group. Dynamic memory may be viewed as a collection of storage elements that are on call for the storage of information. However, records stored in dynamic memory do not have individual names or array positions to be used for their reference. Instead, pointer variables are used to point to an individual record. A record in dynamic memory can be accessed only through its pointer variable. A pointer is like a string attached to a record: follow it and you get to the record. The pointers previously examined point to a record's position in an array, whereas pointer variables point to a record's location in dynamic memory. Both play the same role: they lead to a record.
Declaring a record type for records to be stored in dynamic memory is the same as for individual records or records stored in arrays. However, an associated variable of type pointer must be declared and used to refer to the record. For example, to store a record of type carrecord to be referenced by the pointer variable pcar 1 requires the following declaration:
An important distinction exists between the variable pcar1, which is a pointer, and car2 of type carrecord. The variable car2 is not stored in dynamic memory. Storage is allocated to car2 as soon as the component of the program in which it is declared is executed. The programmer need do nothing other than declare it to ensure this allocation of storage; statements assigning values to it may immediately be written.
This is not the case for the record pointed to by pcar1, which is to be stored in dynamic memory; pcar1 itself is not stored in dynamic memory, but the record it will point to is. This is because pcar1 was declared to be a pointer. The prefix, *, denotes this. No storage is allocated for the record that pcar1 will point to until a specific request made by the programmer is executed. This is done by an invocation of the C function malloc. Thus,
when executed, places a pointer value into pcar1 and also allocates storage in dynamic memory for a record of type carrecord to which that pointer points. Until this is done, pcar1's value is undefined. After the function is executed, the situation may be pictured as in Figure 2.10.
The record may be referenced by pcar1 and its members referenced by pcar1->make, pcar1->rate, pcar1->mileage, and pcar1->rentee. At this point, though, the contents of the fields are undefined. Storage has simply been allocated for them in dynamic memory. They may be assigned values by using the assignment statement. Each field of the record pointed to by pcar1 can be given a value. Thus
assigns a value of 20.25 to the rate field of the record pointed to by pcar 1. You must be sure before assigning values to a record stored in dynamic memory that you have assigned a value to the pointer variable pointing to that record.
One advantage of pointer variables in C is that the value of a pointer can be printed. It means that a programmer can see the value of a pointer for debugging purposes. Other advantages of using pointer variables (that is, of storing records in dynamic memory) will soon become apparent.
Selection and traversal of a collection of records stored in dynamic memory may be accomplished using an array of pointers. The array entries are pointers that point to records in dynamic memory.
Example 2.5
The definition
establishes an array of 100 pointers that can address 100 records stored in dynamic memory. A reference to a member of a record is done by first specifying the pointer to the record, pcar[i], and then the desired member of the record, say make. The resultant reference would then be written as pcar[i]->make. This references the make member of the (i + 1)th record.
Arrays of pointers to records in dynamic memory are not as easy to use as relative pointers to records in an array, but they provide significant flexibility. You shall see, though, that considerable care is needed to use them properly.
It is time to return to the problem of how to represent higher-dimensional arrays in terms of one-dimensional arrays. For simplicity, only two-dimensional arrays are discussed, but the techniques can be readily extended for higher dimensions. Two techniques will be studied: 1) rowwise and columnwise representation and 2) pointer array representation.
What exactly is meant by representing a two-dimensional array a in terms of a one-dimensional array (say, data), and why is it done? The idea is that the problem to be solved may involve the use of a, but the language being used may not provide two-dimensional arrays, or the programmer may choose not to use them for some other reason. Instead, the entries of a are stored in data. This must be done so that whenever reference is to be made to the entry in position (i,j) of a in the program, the corresponding position of data in which it is stored is referenced instead. For example, the check functions of Example 2.3 referred to a two-dimensional array a. If its information were stored in data, then the functions would have to be rewritten, replacing each reference to a[i][j] with a reference to the correct entry in data that corresponds to it. Of course, the declarations involving a would also have to be replaced by declarations involving data.
Suppose a has r rows and c columns, with row index range 0 . . . (r - 1) and column index range 0 . . . (c - 1). A rowwise representation for a uses a data array of length r X c and stores the first row of a in the first c consecutive entries of data, the second row in the next c entries, and so on.
Rowwise representation in arrays is similar to the first method discussed for storing records. In fact, it is logically the same as viewing each row as a record of length c. Thus the offset of the entry in position (i,j) of a is i * c + j in data. This is because rows 0, 1, . . . , i - 1 precede the ith row in data, and take up i X c entries. The jth position of the ith row is offset an additional j entries.
For the array a shown in Figure 2.11, with c = 5, the offset of a[2][3]is 2 * 5 + 3, or 13, and the third row of a starts at data[10]. a[2][3] is represented by data[13]. In C the offset and index are the same, since index values start at zero.
With this representation, function check of Example 2.3 would be written as
Obviously, this representation in data allows a to be traversed, as well as allowing its (i,j)th entry to be selected.
The columnwise representation of a two-dimensional array is similar, except that the columns rather than the rows of a are stored sequentially in data. The offset for the entry in position (i,j) with the columnwise representation is j*r + i.
Example 2.6
Suppose a program involves an n X n array a that is always symmetric. In other words, it is initially symmetric, and any processing performed on a does not disturb its symmetry. When n is small, both the rowwise and columnwise representations are feasible, even though roughly one-half of the information being stored is superfluous. For large values of n (say, 400), the computer system may not provide the required 160,000 storage elements, so the program could not execute. One remedy may be to store only the diagonal entries of a and the entries below the diagonal (those whose row index i exceeds the column index j). This requires ((n X n) + n)/2 entries, or 80,200 instead of 160,000.
Although high-level languages could have provided a data-type, symmetric array to be used in this way, no language does. Instead, the programmer can construct a data array of length ((n X n) + n)/2 to store the entries. The idea is the same as for a rowwise representation, except that only those entries of a row in the lower half or on the diagonal of a are stored. Thus for the row in position i, entries a[i-1][0], a[i-1][1], . . . , a[i][i] are stored in consecutive entries of data, each row's entries following those of the preceding row.
To use this representation of a, the programmer needs to be able to refer, for given i and j, to the proper position of data that corresponds to a[i][j], just as was done in the check function. Finding the offset formula is a little more complex than for the rowwise representation but is done in the same way.
Preceding the entries for the row in position i are the entries for rows in positions 0, 1, . . . , i - 1. The entry in position j of this row is then an additional j entries down in data. Thus the offset for a[i] [j] is 1 + 2 + 3 +. . . + i + j . Any reference we want to make to a[i] [j] is made, instead, by a reference to data [1 + 2 + ... + i + j]. This, of course, is true only for i
The polynomial (1 + 2 + . . . + i + j) (or ((1 + 2 + . . . + i) + j) appears at first glance to require a loop for its calculation, requiring time proportional to i. However,
The division is integer division, so the polynomial may be evaluated in constant time. This means that the entry in position (i,j) of a can be selected using the index,
Traversal may also be accomplished easily. Consider that the entries are stored in data for each row as records of variable length, yet they can be selected and traversed conveniently with no pointer array. The reason is that their lengths, and the order in which they are stored, are regular enough that the requisite calculations for positions can be made. In the general case of variable-length records, there is no way to do this.
The second technique for representing a two-dimensional array in terms of one-dimensional arrays uses a pointer array p. Pointer arrays have pointers as their entries. The entries of the pointer array point to the rows of a, which may be stored in one of two ways: in data (a one-dimensional array) or in the dynamic memory. The number of rows, r, of a must be known. Then p, data, and r represent a when the array is used, and p and r represent a when dynamic memory is used. In the array case, p is of integer type, as in Section 2.2.1. In fact, this is just an application of that method.
Clearly, there is no need to store the rows one after another in data; they can be anywhere in the array as long as they do not overlap. This feature provides considerable flexibility in the use of storage.
A variation of the array technique would treat the rows stored in data as row records. In the dynamic memory case, p is of type pointer, and the row records are stored in dynamic memory. Selection and traversal are thus both easily achieved. The corresponding versions (storing rows in data, storing row records in data, storing row records in dynamic memory) of the function check would appear as follows.
Version 1--Storing Rows in Data
Version 2--Storing Row Records in Data
The third version (storing row records in dynamic memory) is a complete program with a driver for check(p,r). It illustrates reading and printing of r and the array represented by r and p. The input and output from its execution might appear as follows.
The program reads the two-dimensional input array, represents it, checks it for symmetry, and outputs the result.
Version 3--Storing Row Records in Dynamic Memory
The pointer array technique may be used storing columns instead of rows. Then p's entries point to the column records.
Example 2.7
It is often desirable to store information in an array in a specific order. Algorithms to rearrange the information to achieve the order may require repeated interchange of rows. Suppose the programmer wants to interchange the ith and jth rows of the array a when it is represented using the pointer array p. This can be accomplished quickly, taking advantage of the pointers, by executing
Note that the data in each row are not moved; only the pointers change. The time it takes the computer to switch rows is independent of their length. Contrast this with the processing involved for the rowwise method of representing a (Section 2.3.1). Even if a actually is available directly as a two-dimensional array, the pointer array representation is more efficient. Swapping columns, of course, is a much more involved task, unless the programmer has chosen to store columns rather than rows.
The pointer array method offers the advantage of convenience in storing rows of different lengths. Thus it can be used to construct arrays with rows of different lengths easily. Also, if many rows of a are the same, they need not be duplicated in data or in dynamic memory. Their pointer entries in pointer array p need merely point to the same record, resulting in significant storage savings. The means should fit the ends as much as possible! In programming, the ends (the desired operations) determine the means (the data structures to be used).
If you think of the rows (or columns) of a two-dimensional array as records, then what has been demonstrated amounts to five basic ways to store records so that selection and traversal are possible. The methods for storing a collection of records are as follows:
1. Fixed-length records of the same type are stored sequentially in a single array and accessed by calculating record and member offsets.
2. In the C structure, each array entry is a record, perhaps including unions.
3. Fixed-length records of the same type are stored in multiarrays, each of appropriate type to match a member type.
4. Use relative pointer arrays to records stored in an array.
5. Use pointer variable arrays to records stored in the dynamic memory.
The first approach is enlightening because it makes explicit the offset calculations that are usually provided invisibly by the compiler. A severe disadvantage of this approach is that the representation of different type records causes difficulties--awkward in some languages, and impossible in others.
The second approach is the elegant form of this representation. It is possible in a language that provides the record data structure in which calculations are provided by the compiler. The disadvantage of the first approach then disappears.
The method of multiple arrays is applicable to all languages that provide arrays, whether or not they have strong typing or the record data structure. This method, and the first, sacrifice the ability to refer to an entire record by a single term, as provided by the newer C compilers.
The two pointer-oriented methods work for collections of variable-length records but are convenient only when the number of distinct lengths is small. (The more general case is treated in the next chapter.) Relative pointers are easy to use but have the drawback that embedding records in an array raises the problems of data types clashing.
Pointers to dynamic memory are more difficult and dangerous to use, for reasons mentioned later, but they provide extra flexibility. In any event, storing records in an array or in dynamic memory eliminates the need to declare a variable name for them at the outset of a program; records can thus be created dynamically during program execution.
The array is limited in the number of records it can store by its fixed length, which must be declared prior to program execution. The capacity of dynamic memory can be much larger and need not be declared a priori, but it is determined by the computer system. As will become more apparent, dynamic memory allows more efficient use of available storage.
In solving a problem, the programmer is free to use any data abstraction that is helpful. In deciding which data structure to use for its implementation, one must consider such factors as the possibility of carrying out the required operations, storage efficiency, execution time, and proneness to error. There is often a trade-off between storage efficiency and execution time. For example, pointers use extra storage and require some time to maintain, but they typically give fast access. Developing your appreciation of such trade-offs in programming is one of the goals of this text.
To bring together the concepts presented in this chapter, a case study on stable marriages will now be analyzed. The aims of this study are to
1. Show how a program is designed using the top-down approach
2. Show that storing the "right" information in the "right" way has an important effect on the design of a program, on the execution time, and on the memory requirements
3. Demonstrate the concept of data abstraction by treating data and basic operations on it as a unit
4. Illustrate the treatment of arrays and array indices
Consider Table 2.1. It represents the preferences that each of five men and five women has expressed for the five members of the opposite sex. For example, the first man has ranked the women in the order 2, 4, 3, 1, 5.
Now suppose the group has paired off and married, as in Table 2.2. Mi is said to be stable with respect to Wj if there is no other woman preferred by Mi to Wj who, in turn, prefers Mi to her mate. Similarly, Wj is stable with respect to Mi if there is no other man Wj prefers to Mi who prefers Wj to his mate. Any pair (say, Mi-Wj) is stable if each is stable with respect to the other. An entire pairing is stable if all its pairs are stable; an entire pairing is not stable if there exist a man and a woman who are not mates but who prefer each other to their mates.
Consider the pair M3-W1 of Table 2.2. Since M3 prefers W1 to all others, he is stable with respect to W1. W1 prefers M1 and M5 to M3. M1 is married to W4 and does not prefer W1 to W4. M5 is married to W5 and does not prefer W1 to W5. Thus W1 is also stable with respect to M3. Hence the pair is stable. The entire pairing is not stable. For instance, M2 and W3 are paired, but W3 prefers M4 to her mate, and M4 prefers W3 to his mate, so M2-W3 is not a stable pair. Determining whether or not an entire pairing such as that of Table 2.2 is stable may appear frivolous as stated, but there are other applications. Instead of using the terms men, women, and marriage preferences, we might consider tasks, employees, the employees' preferences for performing the tasks, and the ranking of employees by how well they perform the tasks. Or students might provide their preferences for majors while each department gives its preferences for each student.
Suppose the problem is to write a program to check whether or not a given entire pairing is stable for a given set of preferences. After this is done the problem of generating a stable entire pairing from a set of preferences will be considered. Assume that there are n men and n women.
To determine whether an entire pairing is stable, the solution must traverse through all the pairs, testing each for stability. The following high-level algorithm does this.
Set stable to true.
For each man, as long as stable is true
set stable to false if the man is not stable with respect to his wife or the wife is not stable with respect to her husband.
The next question is how to determine whether a person is stable. A person is stable if every individual preferred by the person to the person's mate prefers his or her mate to the person. Let stable hold the result of this determination and refine the task:
1. Set individual to whoever is most preferred by person.
2. While (stable and individual
If the individual prefers person to individual's mate, then
set stable to false
else
set individual to whoever is next most preferred by person.
This assumes stable is initially true. Note that the refinement requires
Determining the mate of any person
Choosing the individual most preferred by a person
Determining whether an individual prefers a person to the individual's mate
Finding the individual next most preferred by a person
To follow the dictates of good programming style, the pairings and preference tables should be treated as data abstractions, with their implementation put off until the basic operations on them have become clear. These operations correspond to the four tasks required by the refinement. They will be developed, respectively, as the functions mate, mostpreferred, prefers, and nextpreferred. Before these functions can be written, the implementation of the pairings and the preference data must be decided upon.
Task 1 is to determine a person's mate. This requires the data for the entire pairing, which is given as input to the program and must be read in. However, how should this data be stored? If the mens' pairings are kept in an array mpairs, relating a man to his mate, then the mate of a man can be selected from the array. For the data of Table 2.2, mpairs would be
Thus the mate of man 3 is woman 1. More generally, the mate of man i is found in mpairs[i], the position of mpairs indexed by i. To find the mate of a woman, however, requires a traversal of mpairs. For example, the mate of woman 1 is found by traversing mpairs until an entry with value 1 is located. The array index of this entry, 3, gives the woman's mate. Rather than spending time traversing whenever a woman's mate is needed, storage can be traded for time. To do this, create another array, wpairs, so selection may be used in this case too. Of course, one traversal will still be necessary to generate wpairs, but this is done just once. The wpairs generated from mpairs would be
Task 2 is to find out who is most preferred by a person. Suppose the preferences are implemented as two-dimensional arrays mpref and wpref. If the given preferences are those of Table 2.1, then mpref and wpref would be
Task 2 is then straightforward and can also be done by selection. In each row of these arrays the first entry is the most preferred mate and the last entry is the least preferred. Thus for man 3, mpref[3][1] contains his most preferred mate.
To perform task 3, determining if an individual prefers a person to the individual's mate, the row for that individual in the proper preference array (mpref for a man and wpref for a woman) may be traversed until either the person or the individual's mate is encountered. If the person is encountered first, prefers must return true, and false otherwise.
Finally, task 4, finding the next preferred individual, can be done by using an index to point to the current individual and, after increasing the index by 1, selecting the (person, index) entry from the appropriate preference array.
The task, determining whether a person is stable, can now be further refined.
1. Set individual to mostpreferred (person, pref).
2. Set index to 1.
3. While (stable and individual
a. set individual's mate to mate (individual, pairs),
b. if prefers (individual, person, individual's mate, pref), then
set stable to false
else
i. Increase index by 1,
ii. Set individual to nextpreferred (person, index, pref1).
This assumes that the person's mate is initially set correctly. The implementation for the functions used follows.
To get an idea of the time required for this solution, note that the while loop used in determining stable can require a traversal through a row of pref. This loop may thus be executed (n - 1) times, since rows of pref are of length n (recall that there are n men and n women). During each of these executions, prefers is invoked and can traverse through a row of pref, which is also of length n. The determination of stable can thus take O(n2) time. Since stable may need to be calculated 2n times (twice for each pair), the total time of this solution could be O(n3). We can do better!
The traversal through pref in prefers can be eliminated. It is done simply to determine if the current individual prefers person to individual's mate, and this information can be ferreted out beforehand from pref and summarized in a priority array. This needs to be done only once. Thus the priority array can be produced before the algorithm is invoked, or can be created initially in the main function. One priority array must be created from mpref and another from wpref. The mpriority array can be created from mpref by traversing mpref and processing its (i, j)th entry by setting mpriority [i] [mpref [i] [j]] to j. Similarly, wpriority can be obtained from wpref. Then an individual prefers person to individual's mate if
priority [individual][person] < priority [individual][individual's mate]
For our example, these arrays are as follows:
This version of prefers may be expressed as follows:
When person is male, the parameter priority must be wpriority, and when person is female, priority must be mpriority. The priority arrays result in O(n) time for determining stable, since one traversal is avoided. This reduces the total time of the solution to O(n2). Again, storage has been traded for time. Extracting precisely the relevant information and implementing it properly, just as was done in Example 2.2, is what produced this time saving. Also, this version is clearer and more concise.
The algorithm, expressed as a function stabilitycheck, is implemented in the following program. The program first inputs n. Next it reads in mpairs, creates wpairs from it, reads in mpref and wpref, then creates mpriority and wpriority, calls stabilitycheck to check the pairings, and finally prints the result along with the pairings.
At this point let's review the process followed in creating the program. First an algorithm was conceived and refined, moving from the original problem to the subtasks into which it was broken down: the four tasks for operating on the data abstractions, plus the task of determining stable. The refinement for this last task was specified, treating the pairings and preferences as data abstractions. Next the functions embodying the operations on the data abstractions were specified. In doing so, the trade-off between storage (adding the priority arrays) and execution time (requiring a traversal of rows of mpref or wpref if there were no priority arrays) came into play. This led to the "right" information to be stored and the "right" choice of data structure in which to store it--the priority arrays.
Finally, the solution was packaged into a main program that (1) created and input data to the data structures chosen; (2) called stabilitycheck to check the entire pairing. The functions main and stabilitycheck were written, treating the pairs and preferences as data abstractions. As a result, should their implementations need to be changed, the changes are localized to the data structure definitions and the functions operating on them.
As explained earlier, the program only checks a particular entire pairing for stability. It does not generate, for given preferences, an entire pairing that is stable. The task of generating such a stable entire pairing is known as the stable marriage problem.
Some simple cases allow a stable entire pairing to be written by inspection:
1. People have a unique way of looking at the world. This case comes up when the first column of mpref has n distinct entries: every man most prefers a different woman. Simply pair each man with his heart's desire. The case where wpref has this property is similar.
2. People are all the same. This case occurs when the rows of mpref are all exactly alike: every man has exactly the same preferences. Pair the most preferred woman with the man she most prefers. Pair the next most preferred woman with the man she most prefers among those not yet paired, and so on. For example:
Pair W2 with M3, W4 with M4, W3 with M2, and W1 with M1. The case where wpref has this property has a similar solution.
Not only is an algorithm for generating a stable entire pairing not apparent; it is not even evident that one always exists. The following algorithm does construct one; you might try your hand at convincing yourself that it always does so.
1. Set man to 1.
2. While (man is not paired)
a. find the woman most preferred by man who is not yet paired, or, if paired, prefers man to her current mate
b. if the woman is not yet paired, then
i. pair man to woman,
ii. set man to an unpaired man if there is one
else
i. break the pair between the woman and her current mate,
ii. pair woman to man,
iii. set man to her ex-mate
To illustrate this algorithm, apply it to the preferences of Table 2.1. The sequence of pairs generated by the algorithm is as shown in Table 2.3. Asterisks indicate conflicts that cause breaks when they occur. The final pairings are then 3-1, 4-3, 2-5, 5-2, 1-4.
This is a good example of a correct algorithm that surely requires both a proof of correctness (produces the proper result) and a proof that it will eventually stop. These are the essential ingredients of an algorithm. (The proofs are left as exercises.)
1. a. Do users of the subway system of a large city reach their destinations by a process analogous to selection or a process analogous to traversal? Why?
b. Do users of the telephone system of a large city reach their parties by a process analogous to selection or one like traversal? Why?
2. Suppose you are interested in processing English text in the following way:
a. Input is in the form of an English sentence.
b. The program is to check the sentence looking for violations of the spelling rule, "'i'" before 'e' except after 'c'." (Do not worry about exceptions such as neighbor, weigh, etc.) Would an array be a convenient data structure to use in your program, and would traversal be a relevant process?
3. Write a program to print out how many elements of an integer array (of length n) contain even integers. Did you use the process of traversal?
4. In Example 2.2 suppose the pointer array were stored in memory and there were no a itself. If you are told that a[5] and a[9] have been interchanged, then what changes would you have to make to pointer to reflect this interchange? What if a[2] and a[5] were interchanged?
5. Write a function to update the pointer array of Example 2.2 to reflect the fact that the ith and jth columns of a have been interchanged.
6. a. Suppose the cars array (Example 2.4) represents the fleet information for the cars of one rental agency. For a group of several such agencies, would the record data structure be convenient to represent all the information?
b. Assume the information is represented in an array that stores records, with each record containing all the information for a particular agency. In general, are these records fixed or variable length?
7. For Example 2.4 assume the alternate multiarray implementation. Write a function to interchange the ith and jth records.
8. Create a function that prints out the rentees of all cars that have been driven more than 50,000 miles for the multiarray implementation of Example 2.4.
9. Write a function to read in a sequence of at most twenty characters into an array. They are all digits (0, or 1, or 2, . . . , or 9) except for one character that will be a decimal point. After execution of the function the variable dp should point to the array element that contains the decimal point, and variable 1 should point to the last digit of the input sequence. The decimal point will always have at least one digit on each side.
10. Produce a function similar to that of Exercise 2.3 except that the array of integers is two-dimensional.
11. Suppose a checkerboard is represented as a two-dimensional array. Write a function that is given the current configuration of the board and the move to be made by the player whose turn it is. The function is to return the value true if the move is legal and false otherwise. (Do not forget that a move can consist of many jumps.)
12. a. Is there an analogy between tabs in your home telephone directory and pointers?
b. If a song on a tape cassette is like a record data structure type, can a particular song be indexed, or must a traverse be used to find it? How about a song on a phonograph record?
13. Explain the differences between a record stored in an array and in dynamic memory.
14. Define a function to copy the array of Example 2.5 into an array indexed by a pointer array of integers.
15. Write a function to interchange two records of the array of Example 2.5.
16. Assume the row representation for two-dimensional arrays has been extended to three-dimensional arrays. Determine the formula for the offset of a[i][j][k].
17. The array a with r rows and c columns is stored using the rowwise representation, with a[0][0] corresponding to the actual base location of a, abase. Given an integer number k (abase
18. An antisymmetric array a is a square array that satisfies the condition that a[i][j] = -a[j][i] for all 0
19. An array a is said to be tridiagonal if the nonzero entries of a fall along the three diagonals a[i] [i], a[i] [i+1], and a[i] [i-1], where i goes, respectively, from 0 to n - 1, 0 to n - 2, and 1 to n - 1.
a. Construct a rowwise representation of the nonzero entries of a, and find a formula for the offset of a[i] [j] in this array.
b. Construct a diagonal representation of the nonzero entries of a tridiagonal array, and find a formula for the offset of a[i] [j] in the array.
20. Write a function that takes a two-dimensional array represented in terms of p and data, as in Section 2.3.3, and changes p so that any duplicate rows of a are stored only once in data. Thus, if rows 2 and 7 are identical, the contents of p[1] and p[6] are made equal.
21. Define a function to output the n diagonal elements of the array a of Section 2.3.3 when the array is represented in terms of p and data.
22. Produce a function to print out the jth column of array a when it is represented in terms of p and data as in Section 2.3.3.
23. Write a function to interchange a[i][j] and a [j][i], for all i, j, when a is represented in terms of p and data as in Section 2.3.3.
24. Create a function that takes any array a of integers with at most twenty entries and creates a pointer array p that has in p[i] a pointer to the (i + l)th largest entry of a. Thus p[0] points to the largest entry of a.
25. Do the same as in Exercise 24, except the array a will be two-dimensional and the ith record in p must contain two pointers, one for the row and one for the column of a's ith largest entry.
26. Do Exercises 20 to 25, except use pointers and dynamic memory. Print the pointers.
27. What pairs are not stable in the example pairings?
28. Give a function to create wpairs from mpairs.
29. Write a function to create a priority array, given a pref array.
30. What function will create a pref array given a priority array?
31. a. Give a function to produce stable marriages.
b. How much time does your answer to Exercise 31a require?
32. a. Why must the algorithm to produce stable marriages terminate eventually?
b. Why does it produce stable marriages?
1. a. Implement the collection data abstraction of Chapter 1 using an array to store the actual integers in the collection. That is, implement the operations set, insert, omit, and belongs.
b. Implement a collection c of carrecords as a data abstraction with the operations set (c), insert (p,c), omit (i,c), and printrecord (i,c). Use the carrecords defined in Section 2.1.3 but add an additional field for an identification number for each car. Then, insert (p,c) adds the carrecord pointed to by p to the collection c, omit (i,c) deletes the carrecord with the identifier i from c, and then printrecord (i,c) prints the contents of the carrecord with identifier i.
c. This is the same as (b), except the records are to be stored in dynamic memory with a pointer array used to contain pointers to them.
2. Suppose the amount of precipitation has been recorded over a region at n locations. In general each record consists of one to five numbers. You are to write and run six programs. Each is to produce the average precipitation. For example, if the input is
the output should be the sum [(3.6 + 2.1 + 2.7) + (.67 + 1.2) + 1.9] divided by 6. Always echo print the input (that is, output the input as it is read in), and annotate all output so that you, or anyone, will know what the output means. Assume n
a. Two of the programs should assume all records are of the same length (say, 3). Program 1 will represent the records as fixed-length homogeneous records stored in a single array (method 1 of Section 2.4). Program 3 will represent them as fixed-length records stored in multiarrays (method 3 of Section 2.4). For method 3, assume an additional record field giving the specific location where it was recorded.
b. Three of the programs should assume the general case of C structures that contain a union and store them in an array (method 2 of Section 2.4). Program 4 will use a relative pointer array whose entries point to records stored in an array (method 4 of Section 2.4). The fifth program uses pointer variable arrays whose entries point to records stored in dynamic memory. For methods 4 and 5, output the contents of the pointer arrays and the records to which each pointer points. Your programs 4 and 5 should work correctly no matter where the records are stored in the one-dimensional array.
c. Finally, one program should assume all records are of length 1 and represent entries in an n X n symmetric array. This program uses the symmetric array representation of Example 2.6. No two-dimensional array should be used in your solution.
The input and output for each program might appear as follows:
3. Modify the program of Section 2.5.2 so that its input consists of the men's and women's preferences and then a series of entire pairings. For each of the pairings, it is to call stabilitycheck and print the result for the pairing.
2.1.1 Structures or Records in C
float amount; struct book struct book text;
{char title[35];
struct name author;
float cost;
int pages;
};
struct balance struct name
{ {float amount; char last[15];
}bankbalance; char middleinit;
char first[15];
}
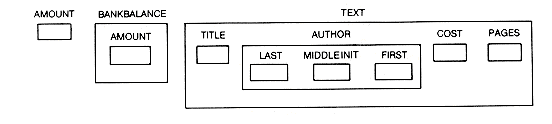
Figure 2.1 Three Variables
2.1.2 Arrays in C
int book_number[80];
struct name author[40];
float prices[80];
char library[30];

Figure 2.2 The Array for Example 2.1
printf("%d\n",a[i]);found = FALSE;
loc = 0;
while (found != TRUE && loc <= n)
if (a[loc] != k)
loc++;
else
found = TRUE;
if (found)
printf("\n %d\n",loc);else
printf("\n - 1 \n");printf("%d\n",pointer[k]);
Figure 2.3 A Pointer Array for Example 2.2
2.1.3 Two-Dimensional Arrays
int a[5][3];
 50) cities, is stored in a two-dimensional array a. Thus a[i][j] contains the distance between city i and city j. For this example, which involves distances, the array must be symmetric. However, the array a shown in Figure 2.4 is not symmetric, because a[2][3] does not equal a[3][2]. The n entries a[0][0], a[1][1],..., a[n - 1][n - 1] are called its diagonal entries. In the city-distance array, the diagonal entries must, of course, be zero.
50) cities, is stored in a two-dimensional array a. Thus a[i][j] contains the distance between city i and city j. For this example, which involves distances, the array must be symmetric. However, the array a shown in Figure 2.4 is not symmetric, because a[2][3] does not equal a[3][2]. The n entries a[0][0], a[1][1],..., a[n - 1][n - 1] are called its diagonal entries. In the city-distance array, the diagonal entries must, of course, be zero.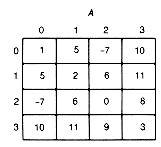
Figure 2.4 An Asymmetric Two-Dimensional Array
typedef int collection[50][50];
check(a,n)
/* Returns true only if the first n
rows and columns of a represent
a symmetric array
*/
collection a;
int n;
{int i,j,ck;
ck = TRUE;
for (i = 0; i<n; i++)
for (j = 0; j<n; j++)
if (a[i][j] != a[j][i])
ck = FALSE;
return(ck);
}
typedef int collection[50][50];
check(a,n)
/* Returns true only if the first n
rows and columns of a represent
a symmetric array
*/
collection a;
int n;
{int i,j,ck;
ck = TRUE;
for(i=1; i<n && ck; i++)
for(j=0; j <i && ck; j++)
if(a[i][j]! = a [j][i])
ck = FALSE;
return(ck);
}
2.1.4 Representation of Records in Arrays
typedef int fieldtype;
typedef fieldtype array [30];
printfield(a,n,k)
/* Prints the contents of the
kth field of each of the first
n records stored in array a.
*/
array a;
int n,k;
{int length = 3, i;
for(i=0; i<n; i++)
printf("\n %d\n",a[length * i + (k-1)]);}
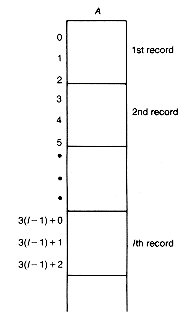
Figure 2.5 An Array of Records (of Length 3)
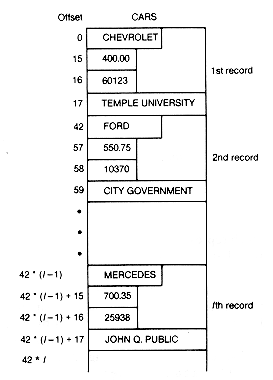
Figure 2.6 Records of a Car Rental Agency Stored in an Array CARS
struct carrecord
{char make[15];
float rate;
int mileage;
char rentee[25];
}cars[100];
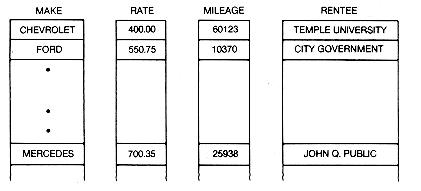
Figure 2.7 A Multiarray Storage of Records of a Car Rental Agency
2.1.5 Variable-Length Records
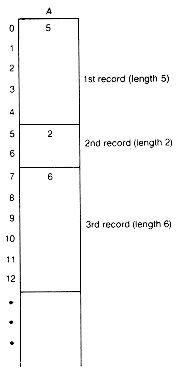
Figure 2.8 Variable-Length Records Stored in Array A
#define SENTINEL 0
traverse(a)
*/ Traverses an array a */
int a[];
{int i;
i = 0;
while(a[i] != SENTINEL)
{process(a,i);
i =i+a[i];
}
}
2.1.6 The Use of Unions in C
union book_lookup
{float location;
char title[50];
};
struct
{int library_id;
union book_lookup information;
}catalog[100];
2.1.7 Address Calculation without Access
2.2: Mortar
2.2.1 Pointers
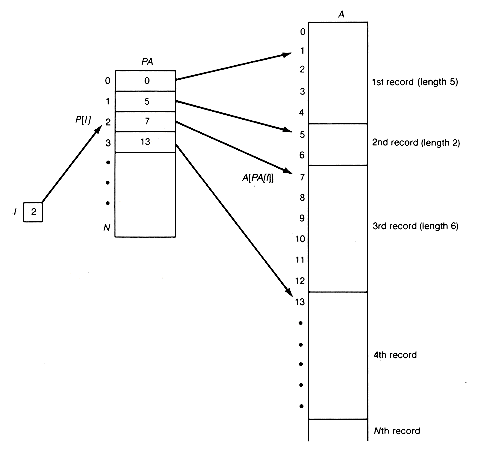
Figure 2.9 Pointer Array PA, with Pointers Stored in A
traverse(a,pa,n)
/* Traverses through the n
records stored in a which
are pointed to by indices
stored in the pointer array pa
*/
int a[],pa[],n;
{int i;
for (i=0; i<n; i++)
process(a,pa,i);
}
2.2.2 Pointer Variables and Dynamic Memory
struct carrecord *pcar1,car2;
pcar1 = malloc(sizeof(struct carrecord));
pcar1->rate = 20.25;
struct carrecord *pcar[100];
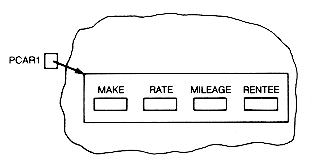
Figure 2.10 Dynamic Memory
2.3: Representations of Two-Dimensional Arrays
2.3.1 Rowwise and Columnwise Representation
#define TRUE 1
#define FALSE 0
check(data,n)
/* Returns true only if an nxn
two-dimensional array stored in
rowwise representation in array
data is symmetric
*/
int data[];
int n;
{int i,j,ck;
ck = TRUE;
for(i=1; i<n && ck ; i++)
for(j=0; j<i && ck ; j++)
if(data[(i*n+j)] != data[(j*n+i)])
ck =FALSE;
return(ck);
}
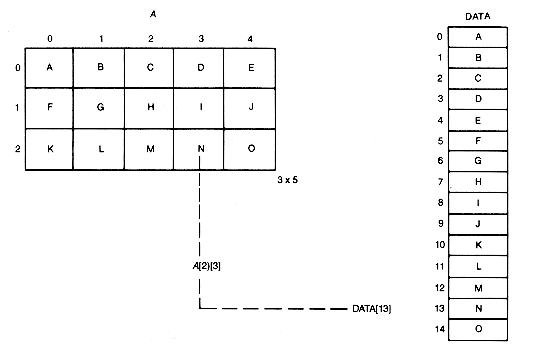
Figure 2.11 Representing a Two-Dimensional Array as a One-DimensionalArray
2.3.2 Symmetric Array Representation
 j, since a[i] [j], when i < j, is not stored in data directly. Its symmetric entry in a, a[j][i], is stored in data [1 + 2 + ... + j + i]. So if i < j, a reference to a[i] [j] must be achieved by referring to a[j] [i].
j, since a[i] [j], when i < j, is not stored in data directly. Its symmetric entry in a, a[j][i], is stored in data [1 + 2 + ... + j + i]. So if i < j, a reference to a[i] [j] must be achieved by referring to a[j] [i].
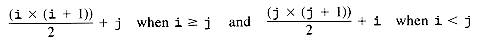
2.3.3 Pointer Array Representation
#define TRUE 1
#define FALSE 0
typedef int pointerarray[50];
typedef int dataarray[2500];
check(p,data,r) /* storing rows in data */
/* Returns true only if the rxr
two-dimensional array, whose rows
are stored in data and are pointed to
by pointers stored in p, is symmetric.
*/
pointerarray p;
dataarray data;
int r;
{int i,j,ck;
ck = TRUE;
for(i=1;i<r && ck;i++)
for(j=0;j<i && ck;j++)
if(data [p[i]+j]! = data[p[j]+i])
ck = FALSE;
return (ck);
}
#define TRUE l
#define FALSE 0
typedef struct
{int row[50];
}rowrecord;
typedef int pointerarray[50];
typedef rowrecord dataarray[50];
check (p, data, r) /* storing row records in data */
/* Returns true only if the rxr
two-dimensional array, whose rows
are stored in row records in data and
are pointed to by pointers stored
in p, is symmetric.
*/
pointerarray p;
dataarray data;
int r;
{int i,j,ck;
ck = TRUE;
for(i=1;i<r && ck;i++)
for(j=0;j<i && ck;j++)
if(data[p[i]].row[j] !=
data[p[j]].row[i])
ck=FALSE;
return(ck);
}
Typical Input and Output
Enter an integer between 1 and 50 for r
4
Enter the next rowrecord
3 4 -67 8
Enter the next rowrecord
4 5 23 57
Enter the next rowrecord
-67 23 -6 4
Enter the next rowrecord
8 57 4 0
r is 4
The row records are:
3 4 -67 8
4 5 23 57
-67 23 -6 4
8 57 4 0
The array is symmetric
#include <stdio.h>
#define TRUE 1
#define FALSE 0
typedef struct
{int row[50];
}rowrecord, *rowpointer;
typedef rowpointer pointerarray[50];
main()
/* Driver for check(p,r) */
{pointerarray p;
int r;
int i,j;
rowpointer malloc();
printf("Enter an integer between 1 and 50 for r\n");scanf("%d",&r);for(i=0;i<r;i++)
{p[i]=malloc(sizeof(rowrecord));
printf("Enter the next rowrecord\n");for(j=0;j<r;j++)
scanf("%d",&(p[i]->row[j]));}
printf("\n r is %d \n",r);printf("The row records are: \n");for (i=0;i<r;i++)
{printf("\n");for (j=0;j<r;j++)
printf("%3d",p[i]->row[j]);}
if(check(p,r))
printf("\n The array is symmetric \n");else
printf("\n The array is not symmetric \n");}
check(p,r) /* Storing row records in dynamic memory */
/* Returns true only if the rxr
two-dimensional array, whose rows
are stored in row records in dynamic
memory and are pointed to by pointers
stored in p, is symmetric.
*/
pointerarray p;
int r;
{int i,j,ck;
ck=TRUE;
for(i=1;i<r && ck;i++)
for(j=0;j<i && ck;j++)
if (p[i]->row[j] != p[j]->row[i])
ck=FALSE;
return (ck);
}
temp = p[i];
p[i] = p[j];
p[j] = temp;
2.4: Advantages and Disadvantages of the Techniques
2.5: Case Study: Stable Marriages
Table 2.1 Preferences
Men's Women's
------------------------------------
M1 2 4 3 1 5 W1 1 5 3 4 2
M2 3 5 2 1 4 W2 4 5 3 2 1
M3 1 5 4 2 3 W3 3 1 4 2 5
M4 3 1 2 5 4 W4 4 2 5 1 3
M5 2 5 1 4 3 W5 1 3 2 4 5
Table 2.2 Pairings
Men Women
----------
1 4
2 3
3 1
4 2
5 5
2.5.1 The Problem--Stability of an Entire Pairing
2.5.2 The Algorithm
 person's mate)
person's mate)mpairs
------
4
3
1
2
5
wpairs
------
3
4
2
1
5
mpref wpref
-----------------------------
2 4 3 1 5 1 5 3 4 2
3 5 2 1 4 4 5 3 2 1
1 5 4 2 3 3 1 4 2 5
3 1 2 5 4 4 2 5 1 3
2 5 1 4 3 1 3 2 4 5
person's mate)mate(person,pairs)
/* Returns person's mate
as specified by pairs.
*/
int person;
pairings pairs;
{return(pairs[person]);
}
mostpreferred(person,pref)
/* Returns the mate most
preferred by person as
specified by pref.
*/
int person;
preferences pref;
{return(pref[person][1]);
}
prefers(individual,person,individualsmate,pref)
/* Returns true only if individual prefers person
to the individual's mate as specified by pref.
*/
int individual,person,individualsmate;
preferences pref;
{int index,next;
index = 1;
next = pref[individual][1];
while(next != person && next != individualsmate)
{index++;
next = pref[individual][index];
}
if(next == person)
return (TRUE);
else
return(FALSE);
}
nextpreferred(person,index,pref)
/* Returns the mate next most
preferred by person as specified
by pref.
*/
int person,index;
preferences pref;
{return(pref[person][index]);
}
mpriority wpriority
-----------------------------
4 1 3 2 5 1 5 3 4 2
4 3 1 5 2 5 4 3 1 2
1 4 5 3 2 2 4 1 3 5
2 3 1 5 4 4 2 5 1 3
3 1 5 4 2 1 3 2 4 5
prefers(individual,person,individualsmate,priority);
/* Returns true only if individual prefers person
to the individual's mate as specified by priority.
*/
int individual,person,individualsmate;
preferences priority;
{return(priority[individual][person]<
priority[individual][individualsmate]);
}
2.5.3 The Program
#include <stdio.h>
#define MAXN 50
typedef int pairings[MAXN];
mate(person,pairs)
/* Returns person's mate
as specified by pairs.
*/
int person;
pairings pairs;
{return(pairs[person]);
}
read_mens_mates(n,pairs)
/* Reads the n mates of the
men into pairs.
*/
int n;
pairings pairs;
{int i;
printf("\n mpairs = ? \n");for(i=1;i<=n;i++)
scanf("%d",&pairs[i]);}
create_womens_mates(n,pairs1,pairs2)
/* Creates in pairs2 the women's mates
based on the men's mates as specified
by pairs1.
*/
int n;
pairings pairs1,pairs2;
{int i,j;
for(i=1;i<=n;i++)
{for(j=1;pairs1[j] != i;j++)
{}
pairs2[i] = j;
}
}
typedef int preferences[MAXN] [MAXN];
mostpreferred(person,pref)
/* Returns the mate most
preferred by person as
specified by pref.
*/
int person;
preferences pref;
{return(pref[person][1]);
}
nextpreferred(person,index,pref)
/* Returns the mate next most
preferred by person as specified
by pref.
*/
int person,index;
preferences pref;
{return (pref[person][index]);
}
prefers(individual,person, individualsmate,priority)
/* Returns true only if individual prefers person
to the individual's mate as specified by priority.
*/
int individual,person,individualsmate;
preferences priority;
{return(priority[individual][person]
< priority[individual][individualsmate]);
}
read_preferences(n,pref)
/* Reads n rows of
preferences into pref.
*/
int n;
preferences pref;
{int i,j;
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
scanf("%d",&pref[i][j]);}
create_priorities(n,pref,priority)
/* Creates n individual priorities in
priority based on the individual
preferences specified by pref.
*/
int n;
preferences pref,priority;
{int i,j;
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
priority[i][pref[i][j]] = j;
}
#define TRUE 1
#define FALSE 0
main()
{pairings mpairs,wpairs;
preferences mpref,wpref,mpriority,wpriority;
int i,j,n;
printf("\n n=?\n);scanf("%d",&n);read_mens_mates(n,mpairs);
create_womens_mates(n,mpairs,wpairs);
printf("\n Enter mens preferences \n");read_preferences (n,mpref);
printf("\n Enter womenspreferences \n");
read_preferences (n,wpref);
create_priorities(n,mpref,mpriority);
create_priorities(n,wpref,wpriority);
if(stabilitycheck(n,mpairs,wpairs,mpref,wpref,
mpriority,wpriority))
printf("The pairings are stable \n");else
printf("The pairings are not stable \n");printf("The pairings are: \n");printf("man wife \n");for(i=1;i<=n;i++)
printf("%d %d \n",i,mate(i,mpairs));}
stabilitycheck(n,mpairs,wpairs,mpref,wpref,mpriority,wpriority)
/* Checks the entire pairing specified by
the parameters and returns true only
if it is stable.
*/
int n;
pairings mpairs,wpairs;
preferences mpref,wpref,mpriority,wpriority;
{int man,wife,individual,individualsmate,index,stable;
stable = TRUE;
for(man=1;(stable && man<=n);man++)
{wife = mate(man,mpairs);
individual = mostpreferred(man,mpref);
index = 1;
while(stable &&(individual != wife))
{individualsmate = mate(individual,
wpairs);
if(prefers(individual,man,
individualsmate,wpriority))
stable = FALSE;
else
{index++;
individual = nextpreferred(man,
index,mpref);
}
}
individual = mostpreferred(wife,wpref);
index = 1;
while(stable &&(individual != man))
{individualsmate = mate(individual,
mpairs);
if(prefers(individual,wife,
individualsmate,mpriority))
stable = FALSE;
else
{index++;
individual = nextpreferred(wife,
index,wpref);
}
}
}
return(stable);
}
2.5.4 Review of the Program's Development
2.5.5 Generating Stable Pairings
mpref wpref
----------------------
2 4 3 1 3 1 2 4
2 4 3 1 3 1 4 2
2 4 3 1 4 2 1 3
2 4 3 1 4 3 2 1
Table 2.3 Sequence of Pairs
Man Active Pairs
--------------------------
1 1 2
1 2 2 3*
3 3 1
4 4 3*
--------------------------
1 2*
2 3 1
4 3
2 2 5
5 5 2*
--------------------------
3 1
4 3
3 2 5
5 2
1 1 4
Exercises
k abase + r X (c - 1)), write formulas that will yield the row and column of a to which actual location k corresponds. That is, if a [i] [j] is stored in k, then your formula for the row will yield i and for the column will yield j. i, j < n. Hence the diagonal elements must be zero. Storing the antisymmetric array can be done just as storing the symmetric array was done, except that now the diagonal entries can be omitted, since they are known. Determine the formula for the offset of a[i] [j].Suggested Assignments
3.6
2.1
2.7
record sentinel
.67
1.2
record sentinel
1.9
record sentinel
final sentinel
100. Input Output
------------------------------------------------------------------------------
Programs A 1. 3.6 Echo print of the precipitation records:
2.1 3.6, 2.1, 2.7
2.7 .67, 1.2, 1.9
RS The average precipitation of the 6 values is
.67 2.028 inches. The number of records is 2.
1.2
1.9
RS
FS
3. White House Echo print of the precipitation records:
3.6 White House 3.6, 2.1, 2.7
2.1 Lincoln Memorial .67, 1.2 , 1.9
2.7 The average precipitation of the 6 values is
RS 2.028 inches. The number of records is 2.
Lincoln Memorial
.67
1.2
1.9
RS
FS
Input Output
-----------------------------------------------------------------------------
Programs B 2. 3.6 Echo print of the precipitation records:
2.1 3.6, 2.1, 2.7
2.7 .67, 1.2
RS 1.9
1.2
RS The average precipitation of the 6 values is
1.9 2.028 inches. The number of records is 3.
RS
FS
4. 3.6 Echo print of the precipitation records:
2.1 3.6, 2.1, 2.7
2.7 .67, 1.2
RS 1.9
.67 Pointer array Data array
1.2 1 10 10 3.6
RS 2 1 11 2.1
1.9 3 16 12 2.7
RS
FS 1 .67
2 1.2
16 1.9
-------------------------
The average precipitation of the 6 values is
2.028 inches. The number of records is 3.
5. This is the same Records in dynamic storage
as for 4, except 3.6 2.1 2.7
it will print the .67 1.2
pointer array 1.9
(that is, the
actual pointers).
Programs C 3.6 2.1 2.7 Echo print of the precipitation records as a
.67 1.2 1.9 3 X 3 array:
0.0 1.1 .15 3.6 2.1 2.7
.67 1.2 1.9
0.0 1.1 .15
The average precipitation of the 9 values is
2.028 inches.