


So far in this book, records in lists have had information members and link members. These are simple records. The lists themselves have looked like chains of records. Such lists may be used to store the records only or to store them and also impose an ordering on them. This chapter presents complex records, which contain members that are themselves names of lists. The members are called sublist members. Lists composed of such records have more complex structure than chains and are known as complex lists. Several such lists are depicted schematically in Figure 6.1. The following examples illustrate the use of complex lists and show how they provide one means of organizing data to capture certain inherent relations among the list records.
Example 6.1
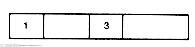
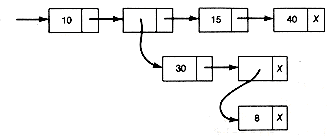
The accounts list in Figure 6.1(a) consists of three records. The first two are complex, the third simple. The first record points to a sublist consisting of two records; the first of these is complex and the second is simple. Accounts might actually represent three companies' user accounts. The first user account is billed for two distinct computer services, $100 for last month's computing and $75 for this month's software consulting. The second user account owes $200 for the month's computing and $250 for the month's consulting. The third user account has a credit of $46. The X in the sublist member of the complex record "200" means its sublist is null.
Example 6.2
A programmer asked to simulate a card game with n players might choose to represent the current configuration of the n individual hands by using a list composed of complex records. A typical configuration is shown in Figure 6.1(b) for four poker players. The sublist that makes up each complex record contains all the cards of a particular player's hand, each card represented as a record. Insertions and deletions into an individual hand require insertions and deletions from the appropriate sublist.
Example 6.3
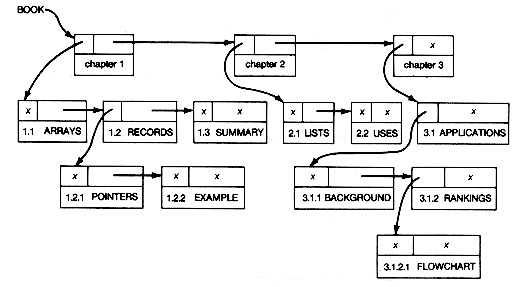
A book might be represented as the book list shown in Figure 6.1(c). Records for the individual lines of text would be simple; the records for paragraph, chapter,and page would be complex.
The data processing for word processing or text editing might involve inserting and deleting chapters, paragraphs, or lines. Creating an index for the book would require even more complex processing. This could be done by making a special "dictionary" that lists the key words relevant to the book's topic, then searching the text for all instances of key words. If the book were a computer science text, then the dictionary would include all key technical computer science words. The index could be created by accessing and processing each page. This processing would involve checking the page for occurrences of the key words and keeping track, for each such word in the dictionary, of the pages on which it occurred. (Unfortunately, such automatic indexing creates too large an index and one that may not be very useful, since not every mention of a key term is especially relevant.)
Example 6.4
A polynomial in x, y, and z may be represented using a list-structure. Suppose the polynomial P(x, y, z) is 3zx5 + 5z3yx + 20. We can write this as
P(x, y, z) = z3(y(x(5))) + z(x5(3)) + 20
This, in turn, can be represented as p of Figure 6.1(d).
Each record of p has four fields, as shown in Figure 6.2(a). A tag field value of 1 indicates that the record is complex, while a tag field of 0 indicates that the record is simple.
Each sublist, including the main list, has a header record and represents a polynomial. The main list, for example, is a polynomial in z composed of three terms. The record (Figure 6.2(b)) on the main list indicates that this term contains z to the power 3 and a coefficient that is pointed to by the pointer in the coeff field. Its successor record is similarly expressed. The last record on the main list (Figure 6.2(c)) is simple, meaning that the value in the coeff field is to be interpreted as a constant. Sublists are interpreted in the same way.
Example 6.5
Each record on brokerage's main list in Figure 6.1(e) represents a sales representative (a financial advisor) of a brokerage firm. The sublist of each salesperson contains information about each of his or her clients. Each client's sublist is the client's stock portfolio.
Each of the example lists organizes information by collecting related data on sublists. They are a step up in complexity from the chains of Chapter 3 but do not illustrate the most complex lists, which allow sharing of records and sublists. Sharing means that more than one record can point to another record or sublist. Records can also have additional pointer fields linking records to form intertwined lists. However, this chapter concentrates primarily on list-structures. They may be defined formally by either of two equivalent definitions:
A list-structure is a collection of simple and complex records linked by pointers in the following way.
The link and sublist fields of each record contain pointers to records of the collection.
Each record of the collection has no more than one pointer to it from any record of the collection.
Or recursively:
A list-structure is a list of simple and complex records whose complex record's sublist fields point to distinct list-structures called sublists. The predecessor of each record must be unique.
The first definition treats list-structures as a collection of linked records but does not convey their inherent structure. The recursive definition emphasizes this structure, making clear how a list-structure is itself built from other list-structures.
It is evident that each list of Figure 6.1 satisfies the first definition. To see that they also satisfy the recursive definition, consider the accounts list. The main list consists of a list of simple and complex records, so it is necessary to check that the complex record's sublists are themselves list-structures. The first main-list record's sublist is a list-structure since the sublist's main list satisfies the definition and its complex record points to a list-structure, a single list record. The second main-list record's sublist is itself a list whose complex record's sublist is a list-structure, the null list-structure.
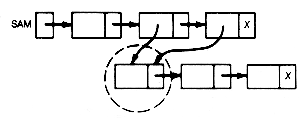
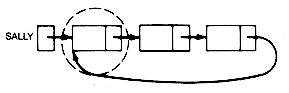
The lists sam and sally in Figure 6.3 are not list-structures, since they fail to satisfy the definitions. Sam has shared sublists; sally has a loop.
Inserting or deleting a record from a list-structure is done using the same procedures as in Chapter 3. Determining where to insert or delete involves a traversal through the records to locate the desired position. Unlike the chain, for which there is a natural order in which to traverse the records, list-structures have no simple natural order. Instead, the order in which records are to be accessed and processed is defined as follows:
To traverse a list-structure,
Access each record on the main list in order and
1. Process the record
2. If the record is complex, then traverse the complex record's sublist.
Notice that the definition is actually recursive, since a complex record's sublist is itself a list-structure. To see how to apply it, consider formula in Figure 6.4. The records are numbered for ease of reference.
To determine the order in which records are accessed and processed in a traversal of the list-structure formula, apply the definition. It specifies that records 1 and 2 on the main list be accessed and processed in sequence. Since record 2 is complex, sublist 1 must be traversed. At the finish of traversal of sublist 1, it will be necessary to continue where processing left off on the main list. To know where to resume, save P1. To traverse sublist 1, apply the definition to it, and access and process records 3 and 4 in order. Since record 4 is complex, traverse sublist 2. Save P3 to know where to resume when its traversal is complete.
To traverse sublist 2, apply the definition of traversal to it, and so access and process records 5 and 6. Since the link field of record 6 is null, no records remain on this sublist, so its traversal is complete.
Which task should be done now? Step 2 of the traversal definition has just been applied to sublist 2. The next record of some sublist must now be accessed. What record? It is the successor record of the complex record--record 4--whose sublist traversal was just completed. P3, which was saved for just this moment, points to record 7, so let the program follow it. Since P3 is no longer needed, discard it. Since record 7 is complex, traverse sublist 3. Continuing in this way, the program would access and process the records in the order in which they are numbered.
From this example it can be seen that whenever the link field of the record just accessed and processed is null, the traversal of some sublist has been completed and the program must determine where to go next. Each time the processing of a complex record was finished, the content of its link field was saved before traversing its sublist. In formula, this leads to saving P1, then P3. After record 6 comes a null link field signifying the completion of the traversal of sublist 2. P3 then tells the program where to go next. Once followed, it can be forgotten. Pl is still remembered, and P5, P7, and P9 need to be remembered in turn. After dealing with record 14, the program encounters its null link value, which signifies completion of sublist 4's traversal. Where does it go? It follows P9 and needs to remember only P7, P5, and P1, and so on.
Each pointer that is saved represents an obligation that must be postponed. It is the obligation to apply steps 1 and 2 of the definition of traversal of list-structures to successive records on the list pointed to by the pointer. The definition requires that the corresponding complex record's sublist be traversed immediately. In carrying out the traversal of that sublist, further obligations may be incurred and subsequently fulfilled. Each time step 2 is completed, the most recently saved pointer provides the information to determine what record to deal with next. When the record is selected for processing, the pointer is discarded. This implies that pointers saved during the complex records' traversal will be discarded when its traversal is complete. Consequently, the most recently saved pointer must point to the record to be processed each time step 2 is completed. If there is no remaining saved pointer, it means that the entire traversal is complete.
Traversing a list-structure thus requires retention, recall, and deletion of information in a specific order. The pointer information retained represents postponed obligations. These obligations must be fulfilled in reverse order from that in which they were incurred. This is the precise situation in which the stack data abstraction is very convenient. Notice how a stack can be used to store the pointers so that the list-structure can be traversed correctly. Each pointer saved is pushed on the stack and popped when needed. It is a typical LIFO situation.
It is important to recognize that the definition of a list-structure traversal does not merely explain how to traverse a specific list-structure, such as formula, but describes a procedure that may be applied to any list-structure. This is, of course, true for any algorithm or program. Programs and algorithms specify a procedure for any input, not just for a specific input. The definition of traversal of list-structures is really an algorithm, an initial description of a procedure for list-structure traversal.
We will now develop a program traverse to traverse a list-structure ls. In applying the definition it became clear that such a traversal may be described by the following algorithm.
1. Initialize the current record.
2. Initialize the stack of postponed obligations to "empty."
3. While there is a current record or a postponed obligation,
if there is a current record, then
a. process the current record, and
b. update the current record to the next record to be processed
else
c. remove the top obligation from the stack and update the current record to it.
To update the current record, the loop task 3b needs to be specified in greater detail. If the record just processed was simple, then the next record to be processed is the successor of the current record. Otherwise--if the record just processed was complex--its successor record represents a postponed obligation that must be placed on the stack. In that case the next record to be processed is the first record on the current record's sublist. This gives a refinement for task 3b that is incorporated in the revised algorithm.
1. Initialize the current record.
2. Initialize the stack of postponed obligations to "empty."
3. While there is a current record or a postponed obligation,
if there is a current record, then
a. process the current record, and
b. if the current record is complex, then
i. save an obligation to its successor record on the stack
ii. update the current record to the first record on its sublist,
else
update the current record to its successor record
else
c. remove the top obligation from the stack and update the current record to it.
A variable (call it ptr) is needed to contain a pointer to the current record. The stack can be treated as a data abstraction with the usual operations set-stack, empty, push, and pop as was done in Chapters 4 and 5. The details for implementing the stack are built into the routines implementing these operations.
Assume that during the traverse each record is processed by calling a routine process. It will clearly need the pointer to the record to be processed, ptr. It will also need access to the list name ls . For example, if its task involves deleting the first record of ls, then it must be able to change the contents of ls. To treat the list-structure as a data abstraction, we need the basic functions complex, next, and sublist, each with ptr as a parameter. Complex returns a value true if the record to which ptr points is complex, the value false otherwise. Next and sublist return, respectively, a copy of the link and sublist field value of the record pointed to by ptr.
A more detailed refinement of the algorithm can now be written.
1. Set ptr to ls
2. Setstack(s)
3. While ptr is not null or not empty(s)
if ptr is not null, then
a. Process(ls,ptr)
b. If complex(ptr), then
i. Push(next(ptr),s)
ii. Set ptr to sublist(ptr)
else
Set ptr to next(ptr)
else
c. Pop(s,ptr)
Notice that if all records of ls are simple, then tasks (i), (ii), and (c) will never be invoked. This procedure is then essentially the same as the list traversal of Chapter 3, as it should be. As written, it does not provide for partial traversal (done is not involved in the loop control) but could be easily modified when necessary.
Traverse may be implemented as in the following iterative (nonrecursive) function. This implementation uses data abstraction and has been written using functional modularly.
Nonrecursive Version
It is important to see that the program is functionally modular and independent of the implementation of the data abstractions to which it refers. Data abstractions for the stack with its operations, and for the list-structure and its operations (which must include complex, next, sublist, and setnull) are needed in order to use traverse. The programmer must either be given these or else must write them.
A recursive implementation can also be developed for traverse. Begin with a recursive algorithm for traversing a list-structure; this is obtained directly from the recursive definition of a list-structure traversal.
1. Initialize the current record.
2. While there is a current record,
a. process the current record;
b. if the current record is complex, then
i. traverse the current record's sublist;
c. update the current record to its successor record.
Once more we need the variable ptr to point to the current record, and the variable nextsublist to point to a sublist. Again, the list-structure is treated as a data abstraction. Also, to modularize functionally, assume that a function traverse is available to implement task (i). The algorithm can now be refined:
1. Set ptr to ls
2. While ptr is not null,
a. Process z(ls, ptr);
b. if complex (ptr), then
i. Set nextsublist to sublist (ptr),
traverse (nextsublist);
c. Set ptr to next (ptr).
This refinement is implemented in the following recursive procedure.
Recursive Version
Notice that this program, at the point when it encounters a complex record and hence must traverse its sublist, does so by simply invoking a module that does that traversal--itself. After that traversal is complete, it merely resumes where it left off. In contrast, the nonrecursive version must perform its own bookkeeping to keep track of where to resume each time it encounters a complex record and then retrieve that information when it is needed.
A number of comments are in order about the two implementations of traverse. First, imagine that the recursive procedure traverse is presented to you with the statement that it is a refined version of the definition of traversal of a list-structure. It is easy to see that this is so. Contrast this with the effort involved in seeing that the nonrecursive version of traverse is also a refined version of the same defining algorithm. Second, the recursive version is more concise than the nonrecursive. Third, the recursive traverse is almost a direct translation of the defining algorithm. It required very little effort to achieve it in this case, because the definition is itself a recursive description.
These comments usually hold for algorithms that process data structures that can be defined recursively, such as list-structures. This is not an accident but can be expected when we deal with complex data structures. Recursive definitions allow concise descriptions of complex algorithms and data structures. Concise descriptions allow us to deal more easily with their complexity. ln fact, it is difficult to develop a definition for a list-structure traversal that has no vagueness, is applicable to any list-structure, and does not involve recursion. Recursive definitions are especially useful to the programmer dealing with complex data structures, because they lead systematically and directly to recursive programs for their processing.
Use of the general list-structure traversal functions just developed is illustrated in the following examples. The examples are intended to convey the flavor of list-structure applications and their processing.
Example 6.6
Print the information field of each stock record of the list-structure brokerage (shown in Figure 6.1(e)) which was bought prior to a specified date and which we store in date. A solution may be obtained by traversing brokerage and printing the relevant stock records. To do this requires only that we write the process function invoked by traverse. Either the recursive or the nonrecursive version may be used. The function process must be written to turn traverse into a solution to this problem.
The task is straightforward except for the determination, within process, of whether the record it is to process is currently a stock record. Since only stock records are simple, a test for complexity of the current record will provide this nformation. Process may be written as where prior returns true if datebought of the record pointed to by ptr is prior to date, and false otherwise, and printinfo prints the information field value of the record pointed to by ptr.
Example 6.7
Consider again the list-structure brokerage in Figure 6.1(e). The task now is to print, for each client, the total value of his or her portfolio.
In detail, what has to be done is
1. To traverse brokerage, and each time a client's record is encountered
2. Print the name
3. Then accumulate the total value of the portfolio as it is being traversed
4. Print this total when the portfolio has been completely traversed
While this seems straightforward and simple enough, some details require attention. We can apply the traverse function to this task. To do so, process must be written to turn traverse into a solution. Thus process must be able to recognize when the record it is to work on is a client's record. At this point, it must initialize the accumulated total to zero. For each ensuing record of the client's portfolio, it must then update the accumulated total by the value of that record's stock. Finally, process must recognize the end of the portfolio list and print the accumulated total.
If total is used to store the accumulated value, then it must be preserved between calls to process. This can be achieved by making total a static variable in process or by making total global. We choose the former. Process may be written as follows.
The if conditions are used to determine if this is the first call to process for a portfolio and, if so, to initialize and print the client's name or, after updating a client's total, to see if the record is the last of a portfolio. Assume null is nonlocal to process. Process will work with either version of traverse.
Example 6.8
Suppose book, the list-structure shown in Figure 6.1(c), stores the current version of a text that you wish to modify by replacing the current paragraph p of page pg of chapter c with a new paragraph. The new paragraph is stored as a list newp. To solve this problem we will write a new nonrecursive traverse function, called paragraphinsert, tailored to the situation. Since not all records of book need to be accessed, we do not want to traverse the entire list-structure as we have done in the previous two examples. Two versions of the function are presented. In both versions the idea is to
1. Traverse the main list searching for chapter c
2. Traverse that chapter's sublist searching for page pg
3. Traverse that page's sublist searching for paragraph p
4. Finally, replace that paragraph with newp
The first version assumes that records representing chapters, pages, or paragraphs have a number field. In the case of a chapter record the field contains the number of that chapter; for a page record it contains the number of that page; and for a paragraph it contains the number of that paragraph. These field values are shown in Figure 6.1(c). The program keeps track of whether it is currently looking for a chapter, a page, or a paragraph by using a variable currentlist. The value stored in currentlist will be CH (denoting that the search is now for a chapter), PAGE (denoting that the search is for a page), or PAR (denoting the search is for a paragraph) . Similarly, a variable currentnumber will keep track of the particular chapter, page, or paragraph number currently being sought by the search. A variable ptr keeps track of the record currently being processed. Once the search for a chapter or a page is complete, currentlist, currentnumber, and ptr must be updated. Once the search for a paragraph has completed, the searching terminates and the new paragraph replaces the old.
Version 1
Setsublist sets the sublist field of the record pointed to by its first parameter to the value of its second parameter. Just before setsublist is invoked, code (not shown here) could be inserted to reclaim the storage used by the replaced paragraph. This is also true for the second version.
The second version assumes no number field, so the records are indistinguishable. Hence they must be kept in order--that is, chapters are in order on the main list, pages are in order on their lists, etc. Note that this ordering is not required by the first version. Now a count of list records must be maintained, to determine when the appropriate record number has been encountered. In the second version below only the differences between it and the first version have been annotated. Notice that this second program requires less storage for the list-structure (as the number fields are not needed), but it does somewhat more processing. Also, the sublists must be kept in order. This is another example of trading storage for time.
Version 2
Example 6.9
Consider again the list-structure formula shown in Figure 6.4. It may be interpreted as representing the formula
Notice that each complex record's sublist is an arithmetic expression that must be evaluated. Thus the operand each represents must be obtained before the operator represented by the list on which it appears may be evaluated. For example, the sublists of complex records 2 and 22 must be evaluated before QT of record 1 can be applied to them.
The task is to write a function evaluate to return the value of an arithmetic expression represented by a list-structure. As with formula, the evaluation can be accomplished by traversing the expression's main list and, whenever a complex record is encountered, evaluating its sublist. When the last list record has been processed in this way, the operator and each of its operands are known. The final result is obtained by applying the operator to its known operands. Of course, in evaluating an operand, more complex records may be encountered, such as record 4, and they must then be evaluated before continuing. A process function can be written to turn either the recursive or the nonrecursive traversal program into evaluate.
One important detail remains: how to store the operands that are generated during the traversal so that they are available when needed. Suppose each operand encountered by process is stored in an operand stack, and each operator encountered is stored in an operator stack. If the current record being processed is the last record of a list (its link value is null), then the operator currently at the top of the stack will have its operands at the top of the operand stack. Process can then pop both these stacks, apply the operator to the operands, and place the result back onto the operand stack. If the record being processed represents the last record on the main list (the operator stack will then be empty), instead of placing the result on the operand stack it should copy it into evaluate.
A detailed description of process follows.
If next(ptr) is not null and the record pointed to by ptr is simple, then
if it contains an operator, then
place the operator on the operator stack
else
place the operand on the operand stack
else
pop the operator stack, remove the top k operands from the operand stack (k is
the number of operands of the operator just popped), and apply the operator to
the k operands.
If the operator stack is not empty then
push the result onto the operand stack
else
set evaluate to the result.
This solution may also be applied to the evaluation of logical or boolean expressions. In fact, it forms the basis of the interpretive language LISP.
We have now seen a number of applications of traverse to examples involving list-structures. The example, presented next, is not discussed in detail but points out another possible application.
Example 6.10
Suppose polynomials are represented as p is in Figure 6.1(d). It is then possible to write functions to perform important algebraic operations on polynomials such as the addition and multiplication of two polynomials. Even symbolic differentiation can be performed. Note that traversal of the list-structures representing the polynomials would form the heart of such functions.
The graphic depictions of list-structures mirror the conceptual image of them. To implement list-structures in a language such as C, you may store their records in dynamic memory or in an array of records. Wherever the records are stored, it must be possible to distinguish simple records from complex ones. The main difference in the format of the records, compared to those of a chain, is that an additional field becomes necessary for the sublist pointer when the record is complex. We also assume that the record contains a field whose value will establish whether the record is simple or complex. The actual implementation of a list-structure record may be done in three ways:
1. Declare two types of records:
one to be used for simple records
another to be used for complex records
2. Declare one record type that consists of a fixed part and a union, which has
one format for simple records
another format for complex records
3. Declare one record type, used for both simple and complex records, but containing a kind or tag field to indicate whether the record stored is simple or complex
The first way is undesirable because it requires that a program deal with two distinct pointer types, one for simple records and another for complex records, so we dismiss it. The second method is feasible and also requires a kind field, which we can put in the fixed part. However, even though the two distinct union formats may have significant differences in the amount of storage they require, C will always allocate the larger amount. Thus this method does not save storage over the third way, which we now choose to use.
To implement the accounts list-structure of Figure 6.1(a), the following definitions could be used when the records are to be stored in dynamic memory.
When the records are to be stored in an array of records, the implementation should be changed to
This change is needed because now listpointer, link, and sublistptr will each be an integer index into the array of records rather than a pointer variable containing an absolute memory address.
As a second illustration, consider the records for the polynomials of Figure 6.1(e). Notice that a complex record in that list-structure has two possible formats, depending on whether the record is a header or not. If it is a header record, the second field contains a character; otherwise it contains a sublist pointer. Using a union, the polynomial records can be implemented as follows.
The tag field indicates whether the record is simple or complex. In this implementation the union allows the same storage to be used to hold the unknown (for a header record) or a sublist pointer. It was used here because a complex record has two distinct possible second fields and the union allows them to share the same storage. The alternative is to avoid the use of the union and keep separate fields for both the unknown and the sublist pointer in each record. This just wastes storage.
When the records are to be stored in an array of records, the implementation should be changed to
It is also possible to implement the main list and sublists of a list-structure as two-way lists. This is convenient, just as for chains, when it is necessary to go back and forth during the processing of a list-structure or to make the predecessor of any record easily accessible. In this case an additional field would be needed for the backward pointer.
The following program creates and prints the records of a list-structure to illustrate its implementation with records stored in dynamic memory. It also demonstrates two applications of the traverse function. The input consists, first, of an integer to indicate whether the list being created is null, and, second, a sequence of data for each record. This sequence is assumed to be in the order in which the records are accessed in a traversal of the liststructure. For example, input corresponding to accounts of Figure 6.1(a), would be as follows. (Program output is not shown, nor are program prompts for input.)
The Program
Although the stacks have been given distinct names, since s1 is local to create and s2 is local to traverse, they could have both been named s. Note that either create or traverse could be replaced by recursive versions.
List-structures that share list records as well as sharing sublists are frequently needed to fit the demands of a problem. These structures are more complicated than those presented thus far and may require large amounts of storage for their implementation. A natural idea is to avoid the duplication of identical sublists or records. At times it is convenient to use additional fields linking records or sublists so that the resultant structure contains records with more than one pointer to them, and the structure may even contain loops. That is, by following pointers from a record we can arrive back at the record. You will see examples of this in the case study that follows. Whenever these possibilities occur, the structures created are still lists but are no longer list-structures. These more general lists provide extensive flexibility but lead to difficult storage management problems, which are considered later in the text.
We now present a case study to illustrate the versatility of lists intertwined with pointers. When the name of a record or a pointer to it is known, retrieval of the record is simple. It may be directly accessed and processed to suit our needs. Slightly more difficult is the retrieval of a record that can be recognized when encountered but whose location is unknown. In order to retrieve it the records must be traversed until the desired one is encountered.
When large collections of records are involved, traversing all the records to find one is not feasible. The problem is not so much that retrieving one desired record takes too long but that many retrievals in rapid succession cause too much delay for the later retrievals. Imagine 1,000 computer terminals linked to a central computer. The banking terminals known as automatic tellers are an example. Suppose 200 requests occur in rapid succession for the retrieval of records. If 1 million records need to be traversed, the retrieval of an individual record could easily take a second, so the last of the 200 requests to be processed would be honored only after more than 3 minutes of elapsed time. No one wants to wait at a terminal for 3 minutes before each request is answered. In the meantime, even more requests become backlogged.
The basic technique to avoid traversing all stored records is to focus the search on a smaller group of records known to contain the desired one. This is the essence of most faster retrieval algorithms. In this case study, lists will be used to organize the data so that the search may be localized in this way. In Chapters 8 and 9 the search problem is presented in a more general context for information stored in random access internal memory, and in Chapter 10 for information stored in external memory.
The central problem in this case study concerns information about a collection of individuals. The collection might represent everyone who graduated from a specific university, all registered voters in a given region, or all individuals known to have contracted a particular disease that is being researched.
The input information for each individual is given as a record with the individual's name, sex, birthdate, father's name, and mother's name as fields. Other relevant fields may be present but are ignored for our purposes here.
To simplify, assume that no duplicate records appear, no two individuals have exactly the same name, all siblings have the same parents, all parents are married, there are no divorces, and no one remarries. This is truly a noteworthy collection of people living in an idyllic world! The violation of these assumptions would create problems that could not be ignored. However, their consideration would detract from our immediate aims.
The task is to input a sequence of these records and represent the collection in memory so that questions involving certain relationships among individuals may be answered. Examples of possible questions are
How many children does John Smith have?
Who are the uncles of John Smith?
Who are the siblings of John Smith?
Perhaps the most straightforward approach to a solution for this information retrieval problem is to represent the collection of information by its image in memory as an array of records. To answer the question, "How many children does John Smith have?" requires a simple traversal of the records. Have a program look at the father's name field in each record and, whenever it comes to John Smith, increment a counter that represents the number of John Smith's children. When the traversal is complete, the program would print the counter value. To answer the question, "Who are the uncles of John Smith?", the program must first traverse, looking at the name field of each record, to find John Smith. It would note the father's name, which is in the fathersname field of that record. Then it would traverse again, looking at the fathersname fields. Each time John Smith's father's name appears, and "male" is listed as the corresponding sex field value, the program must print the name that appears in the corresponding name field. The same sequence would be repeated for John Smith's mother.
The execution time for these traversals can be proportional to the total number of records. This makes the solution time proportional to the amount of information represented in the system. For large systems, this would be impractical, as noted earlier.
What is the least amount of time that could be taken by any solution for these kinds of questions? Clearly, identifying the brothers of John Smith requires printing the names of the brothers. To display who the uncles of John Smith are, the program must print the names of each of his uncles. The least amount of time required for any solution would thus be proportional to the length of the answer to any given question. Length in the case of the uncles is the number of uncles. In the next section, you will see that a different way of representing the information allows a solution that is closer in execution time to this length. This is much better than having it proportional to the entire amount of information stored.
To find answers to relationship questions quickly, you must be able to localize the search and get to the relevant records without considering all of them. You can, if you somehow link records together in a meaningful way. The problem deals with family relationships. Suppose you set up a record in memory to correspond to each individual name in the system, each record having seven fields, five of the fields containing pointer information. The seven fields of each individual's record will be nameptr, fnameptr, mnameptr, siblingptr, childrenlist, sex, and birthdate.
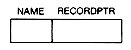
You will also have a table of names, called nametable. Each record of nametable will have a name and a recordptr field. The recordptr field contains a pointer to the individual record of the person whose name appears in the name field. By searching the nametable for a name, we get the pointer to the corresponding individual's record. Following the trails (pointers) from the record, we can retrieve the data needed to answer questions.
Figure 6.5 depicts the form of the two kinds of records. In memory the collection of nametable records will be stored separately from the collection of individual records.
The memory would appear as shown in Figure 6.6, after the data has been input. The childrenlist field of a record f contains a pointer to the first record on the list of children of the individual represented by f. The siblingptr field plays the role of a link field for records on the list of siblings of f. The different lists are intertwined as shown in Figure 6.7.
In Figure 6.7 records f and m are husband and wife, so their children-list pointers are identical. It might be convenient to keep the lists of children in order by birthdate or to make them circular, so that the null pointer signifying the last record would instead point to the first record of the list.
If the assumptions about an "ideal" world were violated, it would be possible to have shared records, and loops could even appear. With the assumptions, the lists are list-structures. The main list of any sublist consists of siblings. All records are complex, with sublist fields (childrenlist fields) pointing to sublists representing children of the individual represented by the complex record. Sublist sharing, however, does occur because the fathers and mothers share the lists of children.
How are the collections of individual records and of nametable records created originally? Suppose you have already dealt with the first hundred records and that the situation in memory accurately reflects all the information they contain. That is, the two collections are correct and as complete as possible, given this input. You now attempt to input the next record, the one hundred first. Recall that the
input consists of the individual's name, sex, birthdate, father's name, and mother's name. Input data for John Smith would appear as
The program should check the record for validity (input validation). If valid, the two collections in memory must be updated to reflect the new information. Then the program should read the next record, and so on until there are no more to enter. An important component of the solution is an update function, which will create and add new records to the collections when necessary and enter new values into the proper fields. It must function as follows.
It is possible that one or more of the three names in the name fields of the newly input record are already in the nametable, with individual records having been created for them. For instance, the father's name might have been dealt with earlier when it appeared in the name field of another record. Assume first that each distinct name appearing in any field of the previously processed records has been entered into the nametable and has had an individual record created for it. Thus the nametable entry for each of these distinct names has the correct name in its name field, and a pointer in its recordptr field to its corresponding individual record. This individual record also has a pointer in its name field back to the record in the nametable it represents. Some fields of the individual record may not yet have been filled with appropriate information.
We cannot, however, assume that any name in the new input record has been seen before. Suppose John Smith is in the name field of the new record. Search the nametable to see if there is an entry for John Smith. If there is, remember where it is by placing a pointer to it in nt_ptr and then copy the pointer in the recordptr field into a variable ir_nptr. Then ir_nptr reveals where the individual record is that corresponds to John Smith. Nt_ptr is a pointer to John Smith's nametable record, and ir_nptr is a pointer to John Smith's individual record. Ir_nptr will be used later when we have to update John Smith's individual record. If there is no entry for John Smith in the nametable, you know that there is not yet an individual record created for John Smith. Create such a record, and also create an entry in the nametable corresponding to it. Store John Smith's name and a pointer to his corresponding record in the recordptr field of the nametable entry. Also place a copy of the pointer to this entry in the nameptr field of the individual record. Then copy the pointer to the individual record into ir_nptr.
At this point, whether or not information on John Smith was already in the system, both an entry in the nametable and an individual record for him exist. The nametable record is completely filled in, and the individual record has at least its nameptr field filled in. Also, ir_nptr points to the individual record.
We would follow the same process for John Smith's father and mother, creating the following four pointers.
A pointer to the individual record representing John Smith's father
A pointer to the individual record representing John Smith's mother
A pointer to the nametable entry for John Smith's father
A pointer to the nametable entry for John Smith's mother
How do we now complete the update properly? That is, which individual records and nametable entries must be modified, and how are the modifications done?
Consider the individual record for John Smith. The sex and birthdate fields can easily be filled in, as well as the fnameptr field, copying nt_fptr into it.The same can be done for mnameptr.
Now the individual record for the father of John Smith must be updated. Fill in the sex field (you know he is male). There is no additional information on his birthdate. (It may already be known. Why?) John Smith's record must be added to the list of children of his father. Assuming that the children are not kept in any special order, add his record at the front of the list. This requires copying the childrenlist pointer of his father's record into the siblingptr of John Smith's record, and then copying the pointer in ir_nptr into the childrenlist field of his father. This implies that whenever individual records are created, they must have their childrenlist and siblingptr fields set to null.
The mother's record can be treated similarly, except we may simply copy the father's childrenlist pointer (or ir_nptr) into her childrenlist field. This completes the update, which consisted of a search of the nametable and the updating of pointers in nine fields after the nametable entries and individual records were created. These nine fields were
fnameptr, mnameptr, sex, birthdate, siblingptr--for the individual record of John Smith
sex, childrenlist--for the individual record of George Smith and Alice Rickard, the father and mother
Example 6.11
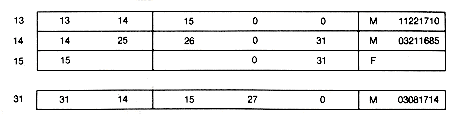
Let us now trace this process with some data and show how the records would appear. Suppose the input data so far consisted of the information shown in Table 6.1, and suppose that we use different arrays to hold the individual records and the nametable entries. (Later, in Chapters 8 and 9, more appropriate implementations for collections such as nametable are introduced.) The situation in memory will then be as shown in Table 6.2.
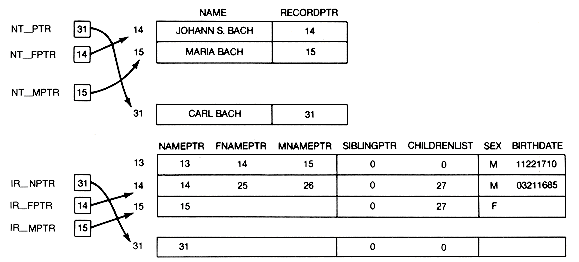
The next input is
Since none of these names appears in the nametable, an entry in the nametable and an individual record must be created for each of the names.
After this has been done, the new nametable entries, individual records, and saved pointers will appear as shown in Figure 6.8(a). Updating the nine fields of the individual records yields the result shown in Figure 6.8(b).
The next input is
Johann S. Bach and Maria Bach already appear in the nametable and have individual records. An entry in the nametable and an individual record must, however, be created for Carl Bach.
When this has been completed, the nametable entries, i`ndividual records, and saved pointers related to this input appear as in Figure 6.8(c). Updating the nine fields of the individual records yields the result shown in Figure 6.8(d). The time required to complete an update is the constant time for the pointer manipulations plus the time to search the nametable.
The following is an algorithm for updating the information base given another input record.
1. Search the nametable.
a. Create entries in the nametable and create individual records for any of the three input names not present in nametable.
b. Set their recordptr and nameptr fields.
c. Set their childrenlist and siblingptr fields to null.
d. Set nt_ptr, nt_fptr, nt_mptr, ir_nptr, ir_fptr, and ir_mptr.
2. Update the following fields of the individual record pointed to by ir_nptr:
sex to input sex
birthdate to input birthdate
fnameptr to nt_fptr
mnameptr to nt_mptr
3. Update:
sex.fptr (the sex field of the record pointed to by ir_fptr) to m
siblingptr.ir_nptr to childrenlist.ir_fptr
childrenlist.ir_fptr to ir_nptr
sex.ir_mptr to f
childrenlist.ir_mptr to ir_nptr
Now that we have built the collections, how do we answer questions about family relationships?
Example 6.12
How do we determine who the children of John Smith are? Search the nametable for John Smith. If the name is not there, print an appropriate message. If it is there, follow the pointer to John Smith's individual record. Traverse his list of children and count the number of records on it, or output the individual names. In any case, ignoring the search of nametable, the time required is proportional to the length of the answer--that is, it is proportional to the number of children of John Smith.
Example 6.13
How do we find all the uncles of John Smith? Search the nametable, and follow its pointer to the record for John Smith. Then, follow the fnameptr pointer to the entry in the nametable for his father and follow its recordptr back to the father's record. Do this again for the father to get to the grandfather's record. Once we have the grandfather's record we can traverse his children's list to find the uncles on John Smith's father's side. Repeat the process for John Smith's mother to find the uncles on her side.
Simply following the sibling pointer of the father's record doesn't work, because the traversal may have begun in the middle of this sibling list. To ensure starting at the beginning of the sibling list, it is best to use the children's list of the grandfather's record. If the sibling lists were circular, this would not be necessary; it would suffice to traverse the grandfather's list of children (John Smith's father's siblings) and then output the name of each male. The same processing must be done for John Smith's mother, to output all his uncles on his mother's side.
The total time, again ignoring the nametable search, is proportional to the answer, the number of uncles. Excluding the nametable search, this is certainly close to the minimal time that would be desirable. You will see in the chapters on searching and sorting how long it would take to search the nametable!
To complete design of the system, in addition to the nametable implementation and search function, components are needed for deletion of records. We will not pursue this topic here, but clearly the issues of storage reclamation and allocation would have to be considered.
Beyond this, there are some more basic unresolved problems. Exactly how are questions asked of the system?
One way is for anyone wanting answers to questions to bring them to the system's designers. The designers then write programs to output the solutions. This is feasible in certain situations; in fact, many organizations do information retrieval in this way. A related solution would be to give the data representation to questioners and have them write their own programs.
Another way is to design a simple "menu," or list, of questions that includes at least those most likely to be asked. Users could then "check off" their questions if they appear on the menu, and previously written programs could be run to answer them. This solution proves satisfactory as long as the questions people want answered are on the menu.
A more sophisticated scheme would be to design a general query language. Questioners could then ask their questions in this language. A built-in language translator would interpret the question and automatically produce a program to print the answer. Achieving this solution can be quite complex and might challenge the state of the art at the present time.
The issue of security has been ignored. It would be of major concern in any retrieval system. Users' access to specific information and ability to modify it would have to be limited.
This case study illustrates the use of many of the concepts this book has stressed. These include the basic concepts of top-down design, data abstraction, functional modularization, and the use of appropriate data structures to achieve clear, concise, and efficient programs.
It also shows the versatility of list-structures and the way in which pointers contribute to this versatility. List-structures provide a means of interconnecting data to cut retrieval time significantly. To do so, however, means that we have to organize the data to fit the desired retrievals. As usual, we are faced with higher costs to organize the data, that is, to build the links we will need, but gain reduced costs in search time for retrieving information. This is the classic trade-off.
1. Draw a picture like Figure 6.1(b), corresponding to Example 6.2 for an actual configuration of hands for the game of poker with four players.
2. Draw pictures, similar to p of Figure 6.1(d), for the polynomials
z2(y2(x(8))) + z(y(3x)) + y(x) + 18 and x3yz + 2xz + y2xz3
3. Give a recursive definition for a chain.
4. Why do the two definitions of list-structures not allow more than one pointer to a record, or loops, to occur in a list-structure?
5. Why does a null ptr and an empty stack indicate the end of the traversal of a list-structure?
6. What will be in the stack when record 20 of formula (Figure 6.4) is accessed?
7. Simulate the execution of the iterative implementation of traverse on p of Figure 6.1(d).
8. Simulate the execution of the recursive implementation of traverse on p of Figure 6.1(d).
9. Give an example of a list containing loops for which the traversal functions fail because they do not terminate.
10. a. Write a process function to turn the iterative traversal into a program that prints the number of sublists of a list-structure.
b. Will your solution also work for the recursive traversal?
11. a. Write a function to return a pointer to the record of a list-structure that has the maximum information field value.
b. Modify your solution to return a pointer to a list. The list should contain pointers to all records whose information field value coincides with the maximum value.
12. Give an algorithm to determine whether two list-structures whose records have the same format are identical.
13. Modify your solution to Exercise 12 so that the algorithm determines whether the two list-structures have the same "structure," independent of the information values stored.
14. Each complex record of a list-structure has a field pointing to the record's sublist. The sublist is composed of a main list (composed of the chain of records linked by their link fields). Suppose each complex record of a list-structure also has a field called number that contains the number of records on the complex records sublist. Write a process function to turn the traverse functions into a program to insert a record after the record whose information field value is value. The program must, of course, also correctly update the number field for the appropriate sublist.
15. Write a function to implement evaluate (Example 6.9).
16. Modify your solution to Exercise 15 so that it outputs the evaluation of each operation as it occurs.
17. Modify your solution to Exercise 16 so that it prints out an appropriate message, such as "too many operands for the operator PS of the sublist of record 7" or "missing operands for the operator PS of the sublist of record 7," whenever the list-structure does not represent a valid arithmetic expression.
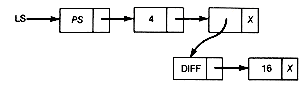
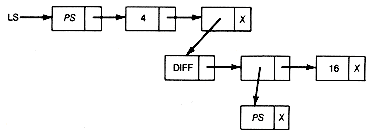
18. Assume that p points to a record of Example 6.9 containing an operator or operand. Suppose ptr points to a record of a sublist after which the record pointed to by p is to be inserted. It is to be inserted as the first record of a sublist if it is an operator, and as the next record on the sublist if it is an operand. Write an insertion function to accomplish this. For example, suppose the list-structure, ls, is currently:
If ptr points to DIFF, and the record pointed to by p contains PS, then after insertion ls will be
If the record pointed to by p contained 432.713, then after insertion ls would have been
19. Insertion and deletion of records in list-structures is similar to their insertion and deletion in chains. However, the deletion of a sublist has ramifications for the reclaim function of Chapter 3. Discuss these, and explain how they might be resolved by modifying the definition of reclaim or by increasing the responsibility of the programmer. In either case, the idea is to be sure all unused records are returned to availist.
20. Modify paragraphinsert (Example 6.8) so that all deleted records are returned to the availist.
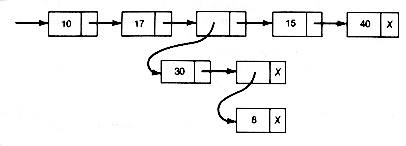
21. Let ptr and pv point, respectively, to a record of a list-structure and to its preceding record. Write a function to delete the record pointed to by ptr if it is simple, and to replace it with the list-structure to which it points if it is complex. For example, consider the following list-structure.
If ptr points to 17, then the function produces
If ptr points to the complex record following 17, then the function produces
22. Give an implementation of next and sublist of the function traverse (Section 6.2.1) for each declaration of the polynomial p.
23. Give a declaration for the records of Example 6.8 using dynamic memory and write implementations for all the functions of traverse and process that depend on this implementation.
24. Draw a picture, corresponding to Table 6.2, for the complete input data (31 names) of Example 6.11.
25. Modify the answer to Exercise 24 to reflect the lists of children being kept as circular lists.
26. Show the complete situation in the arrays of your solution to Exercise 24 after the input below is processed.
27. Show the complete situation after the input of Exercise 26 is processed, when circular lists are used for the lists of children.
28. Suppose the records of Example 6.11 were to be kept in alphabetical order by the name in the name field. What would the arrays look like after all the input data were processed?
29. How does the algorithm for updating the information base given another input record (p. 287) have to be modified if inputs are allowed for which one or more field values are unknown?
30. Write two functions for Example 6.11, children(person) and brothers(person). They should print out the names of all children and all brothers of person, respectively. Simulate the behavior of the functions on the data of the example.
31. Modify your solutions to Exercise 30 so that the functions will work on circular lists of children.
32. Suppose the nametable is implemented as a list. How will your solutions to Exercises 30 and 31 be modified?
33. Write an algorithm to print out the names of individuals who were born before 1900. How much time will your algorithm take?
34. Can you find a way to implement the information system so that a faster solution can be obtained for Exercise 33? If you find a faster solution, then determine how its update time will compare to that for Exercise 33.
35. Write a detailed description for a routine that will delete an individual record and its nametable entry from the system. This implies that all relevant pointers will be properly modified and that storage will be reclaimed.
Consider the following list-structure for a book. Book might represent the current structure of a textbook. Suppose we want to print this information as a table of contents. It would appear as follows:
This problem can be abstracted to the printing out of a "picture" of a list-structure. Assume all records are declared as
Write a function printlist that will print out a "picture" of the list-structure pointed to by ls. Consider, for example, the list-structure accounts of Section 6.1. The list-structure is
Your program should read in and echo print three list-structures. One should be null. It should then call on printlist to print out the "picture" for each of the three list-structures.
The input data for accounts might be
Notice that the input is given in traversal order.
The printlist function is to have almost exactly the same detailed refinement as either the iterative traverse (Section 6.2.1 ) or the recursive traverse (Section 6.2.2). You must write the proper process routine, say process2, to turn traverse into printlist. You may add parameters to process2 if necessary.
For extra credit, do the reading in and echo printing of the three list-structures in the program by calling a function readechoprint. It must also be obtained by writing the proper process routine, say process1, to turn traverse into a function for readechoprint.
Of course, it will be necessary for you also to write the stack operation routines setstack, push, pop, and empty, as well as next, sublist, and complex.
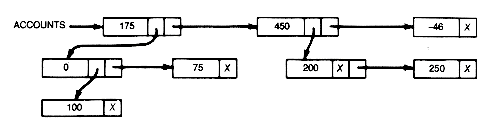
(a) ACCOUNTS List
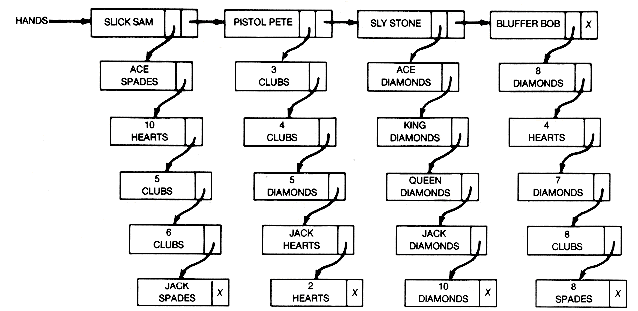
(b) Poker Hands for n = 4 Players
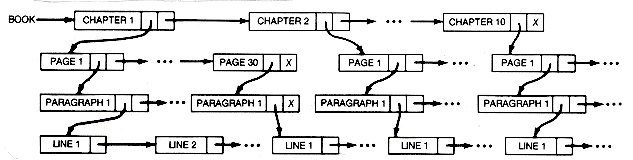
(c) BOOK List
Figure 6.1 More Complex Lists
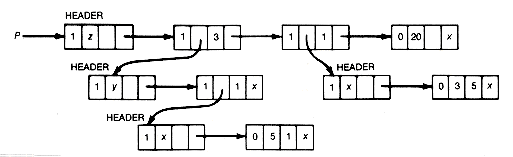
(d) List P, a Polynomial Expression

(e) Brokerage Data Base

(a) General Form of a Record
(b) Main-List Record

(c) Last Record on Main List
Figure 6.2 Records of the List-structure for a Polynomial
6.1.1 A Definition of List-structures
(a) List with Shared Sublists
(b) List with a Loop
Figure 6.3 Two Lists That Are Not List-structures
6.2: Traversal of List-structures

Figure 6.4 The List-structure FORMULA
6.2.1 An Iterative Function
traverse (pls)
/* Accesses and processes each record
of the list-structure ls.
*/
liststructurepointer *pls;
{liststructurepointer ptr,null,setnull(),next(),sublist();
stack s;
null = setnull();
ptr = *pls;
setstack(&s);
while((ptr ! = null) | | (!empty(&s)))
if(ptr ! = null)
{process (pls, ptr);
if (complex(ptr))
{push next(ptr),&s);
ptr = sublist(ptr);
}
else
ptr = next(ptr);
}
else
pop(&s,&ptr);
}
6.2.2 A Recursive Function
traverse (pls)
/* Accesses and processes each record
of the list-structure ls.
*/
liststructurepointer *pls;
{liststructurepointer ptr,nextsublist,null,
setnull(),next (),sublist();
null = setnull();
ptr = *pls;
while(ptr != null)
{process(pls,ptr);
if(complex(ptr))
{nextsublist = sublist(ptr);
traverse(&nextsublist);
}
ptr = next(ptr);
}
}
6.3: Using a Traverse Function for List-structures
process (pls, ptr)
/* Print the stock record of ls
pointed to by ptr if it was
bought prior to date
*/
liststructurepointer *pls, ptr;
{if(!complex(ptr) && prior(ptr,&date))
printinfo (ptr);
}
process(ptr)
/* If the current record points to a
client's portfolio record that client's
total portfolio value is updated.
If the record is the last record on
the client's portfolio list its total
value is printed.
*/
liststructurepointer null,setnull(),
sublist(),next();
float value();
static float total;
null = setnull();
if(complex(ptr))
if(sublist(ptr) != null)
if(!complex(sublist(ptr)))
{total = 0.0;
printname(ptr);
}
else
{total = total + value(ptr);
if(next(ptr) == null)
printf("\n Portfolio value is%12.2f \n",total);
}
}
#define CH 1
#define PAGE 2
#define PAR 3
#define TRUE 1
#define FALSE 0
paragraphinsert(book,newp,c,pg,p)
/* Replaces paragraph p of page pg
of chapter c of book by the
paragraph pointed to by newp.
Assumes the records of book contain
number fields.
*/
liststructurepointer book,newp;
int c,pg,p;
{int currentnumber,currentlist,found;
liststructurepointer null,ptr,setnull(),next(),sublist();
null = setnull();
ptr = book;
currentnumber = c;
currentlist = CH;
found = FALSE;
while(!found && (ptr != null))
{if(currentnumber != number(ptr))
ptr = next(ptr);
else
switch(currentlist)
{case CH:
currentlist = PAGE;
currentnumber = pg;
ptr = sublist(ptr);
break;
case PAGE:
currentlist = PAR;
currentnumber = p;
ptr = sublist(ptr);
break;
case PAR:
found = TRUE;
}
}
if(found)
setsublist(ptr,newp);
else
printf("\n Paragraph not found \n");1 print message
}
#define CH 1
#define PAGE 2
#define PAR 3
#define TRUE 1
#define FALSE 0
paragraphinsert(book,newp,c,pg,p)
/* Replaces paragraph p of page pg
of chapter c of book by the
paragraph pointed to by newp.
Assumes the sublists of book are
in order.
*/
liststructurepointer book,newp;
int c,pg,p;
{int currentnumber,count,currentlist,found;
liststructurepointer null,ptr,setnull(),next(),sublist();
null = setnull();
ptr = book;
currentnumber = c;
currentlist = CH;
found = FALSE;
count = 1;
while(!found && (ptr != null))
{if(currentnumber != count)
{count++;
ptr = next(ptr);
}
else
switch(currentlist)
{case CH:
currentlist = PAGE;
currentnumber = pg;
count = 1;
ptr = sublist(ptr);
break;
case PAGE:
currentlist = PAR:
currentnumber = p;
count = 1;
ptr = sublist(ptr);
break;
case PAR:
found = TRUE;
}
}
if(found)
setsublist(ptr,newp);
else
printf("\n Paragraph not found \n");}
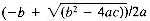 . This happens to be the root of the quadratic equation ax2 + bx + c = 0. In formula the symbols QT, PS, TS, MS, DIFF, and SQ stand for the operations of division, addition, multiplication, changing sign, taking the difference, and taking the square root, respectively. The square root and sign change operations apply to one operand. The others apply to two operands. The main list (and each sublist) represents an arithmetic expression. Their first records contain an arithmetic operator such as QT, PS, TS, MS, and DIFF. Their remaining list records represent the operand values of that arithmetic operator. The expression represented by such a list is to be evaluated by applying the operation to its operands. Thus sublist 4 would be evaluated by multiplying the operands in records 13 and 14 (b and b respectively), together.
. This happens to be the root of the quadratic equation ax2 + bx + c = 0. In formula the symbols QT, PS, TS, MS, DIFF, and SQ stand for the operations of division, addition, multiplication, changing sign, taking the difference, and taking the square root, respectively. The square root and sign change operations apply to one operand. The others apply to two operands. The main list (and each sublist) represents an arithmetic expression. Their first records contain an arithmetic operator such as QT, PS, TS, MS, and DIFF. Their remaining list records represent the operand values of that arithmetic operator. The expression represented by such a list is to be evaluated by applying the operation to its operands. Thus sublist 4 would be evaluated by multiplying the operands in records 13 and 14 (b and b respectively), together. 6.4: Implementing List-structures
typedef struct record
{int kind;
int info;
struct record *sublist;
struct record *link;
}listrecord, *liststructurepointer;
typedef struct record
{int kind;
int info;
int sublist;
int link;
}listrecord;
typedef int liststructurepointer;
typedef union
{char unknown;
polyrecord *sublist;
int value;
}varying;
typedef struct record
{int tag;
varying secondfield;
int exponent;
struct record *nextterm;
}polyrecord, *liststructurepointer;
typedef union
{char unknown;
int sublist;
int value;
}varying;
typedef struct
{int tag;
varying secondfield;
int exponent;
int nextterm;
}polyrecord;
typedef liststructurepointer;
1 -- indicates a nonnull list-structure
175 -- information field value
1 -- indicates record is complex
11 -- indicates the link and sublist fields are not null
0 -- information field value
1 -- indicates record is complex
11 -- indicates the link and sublist fields are not null
100 -- information field value
0 -- indicates record is simple
0 -- indicates the link field is null
75 -- information field value
0 -- indicates record is simple
0 -- indicates the link field is null
450 -- information field value
1 -- indicates record is complex
11 -- indicates the link and sublist fields are not null
200 -- information field value
1 -- indicates record is complex
10 -- indicates the link field is not null but the sublist field is
250 -- information field value
0 -- indicates record is simple
0 -- indicates the link field is null
-46 -- information field value
0 -- indicates record is simple
0 -- indicates the link field is null
Reads in list-structure records,
Creates the list-structure, and
Prints all its records.
#include <stdio.h>
typedef struct record
{int info;
int kind;
struct record *sublistptr;
struct record *link;
}examplerecord,*liststructurepointer;
#define NULL 0
liststructurepointer next(p)
/* Returns a copy of the link field
value of record pointed to by p.
*/
liststructurepointer p;
{return(p->link);
}
liststructurepointer sublist(p)
/* Returns a copy of the sublistpointer
field value of record pointed to by p.
*/
liststructurepointer p;
{return(p->sublistptr);
}
liststructurepointer setnull()
/* Returns a null pointer */
{return(NULL);
}
liststructurepointer avail()
/* Returns a pointer to storage allocated
for a liststructure record of type
examplerecord.
*/
{return(malloc(sizeof(examplerecord)));
}
complex(p)
/* Returns true only if the record pointed
to by p is complex.
*/
liststructurepointer p;
{return(p->kind == 1);
}
createrecord(l,ptr)
/* Reads in the data for the current record
and sets its fields appropriately.
*/
liststructurepointer 1,ptr;
{int link,subptr,value,kind;
liststructurepointer setnull(),avail();
printf("\n enter info \n");scanf("%d",&value);printf("\n enter 0 for simple 1for complex \n");
scanf("%d",&kind);if (kind == 0)
{printf("\n enter link \n");scanf("%d",&link);if (link == 0)
ptr->link = setnull();
else
ptr->link = avail();
}
else
{printf("\n enter link & subptr \n");scanf("%d %d",&link,&subptr);if (link == 0)
ptr->link = setnull();
else
ptr->link = avail();
if (subptr == 0)
ptr->sublistptr = setnull();
else
ptr->sublistptr = avail();
}
ptr->info = value;
ptr->kind = kind:
}
printrecord(pls,ptr)
/* Prints the contents of the info field
of the record pointed to by ptr.
*/
liststructurepointer *pls,ptr;
{printf("\n %d \n",ptr->info);}
main()
/* Reads in liststructure records, creates
the liststructure, and prints all its records.
*/
{int n;
liststructurepointer l,avail();
printf("\n enter liststructure: 0 for\null list 1 otherwise \n");
scanf("%d",&n);printf("\n remember - the data for the\records must be in traversal order\
\n");
if (n == 0)
l = NULL;
else
{l = avail()
create(1);
}
traverse(&l);
if (l == NULL)
printf("\n The list is null \n");}
#define LIMIT 50
typedef liststructurepointer whatever;
typedef struct
{whatever stackarray[LIMIT];
int top;
}stack;
setstack(ps)
/* Sets stack s to empty */
stack *ps;
{(*ps).top = -1;
}
empty(ps)
/* Returns true only if
stack s is empty.
*/
stack *ps;
{return((*ps).top == -1);
}
push(value,ps)
/* Inserts contents of value as
top entry of stack s.
*/
whatever value;
stack *ps;
{if ((*ps).top == (LIMIT - 1))
overflow(ps);
else
{(*ps).top = (*ps).top + 1;
(*ps).stackarray[(*ps).top] = value;
}
}
pop(ps,pvalue)
/* Removes the top entry of stack s
and places its contents in value.
*/
stack *ps;
whatever *pvalue;
{if (empty(ps))
underflow(ps);
else
{*pvalue = (*ps).stackarray[(*ps).top];
(*ps).top = (*ps).top - 1;
}
}
overflow(ps)
/* Prints a message when
the stack overflows.
*/
stack *ps;
{printf("\n stack overflow \n");}
underflow(ps)
/* Prints a message when
the stack underflows.
*/
stack *ps;
{printf("\n stack underflow \n");}
traverse(pls)
/* Prints the info fields of all
records of the liststructure l.
*/
liststructurepointer *pls;
{liststructurepointer ptr,null,setnull(),
next(),sublist();
stack s1;
null = setnull();
ptr = *pls;
setstack(&s1);
while ((ptr != null)||(!empty(&s1)))
if (ptr != null)
{printrecord(pls,ptr);
if (complex(ptr))
{push(next(ptr),&s1);
ptr = sublist(ptr);
}
else
ptr = next(ptr);
}
else
pop(&s1,&ptr);
}
create(l)
/* Inputs records and creates the list l */
liststructurepointer l;
{liststructurepointer ptr,null,setnull(),
next(),sublist();
stack s2;
null = setnull();
ptr = l;
setstack(&s2);
while ((ptr != null)||(!empty(&s2)))
if (ptr != null)
{createrecord(l,ptr);
if (complex(ptr))
{push(next(ptr),&s2);
ptr = sublist(ptr);
}
else
ptr = next(ptr);
}
else
pop(&s2,&ptr);
}
6.4.1 Sharing Storage
6.5: Case Study: Information Retrieval
6.5.1 Family Relationships
6.5.2 A First Solution
6.5.3 A Better Solution
(a) Nametable Record

(b) Individual's Record
Figure 6.5 Format of the Nametable and Individual Records
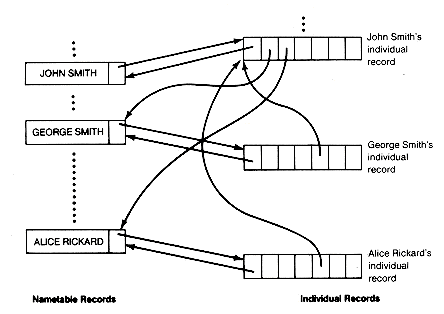
Figure 6.6 Memory in the Family Relationships Problem
6.5.4 Updating the System
JOHN SMITH M 1/2/79 GEORGE SMITH ALICE RICKARD
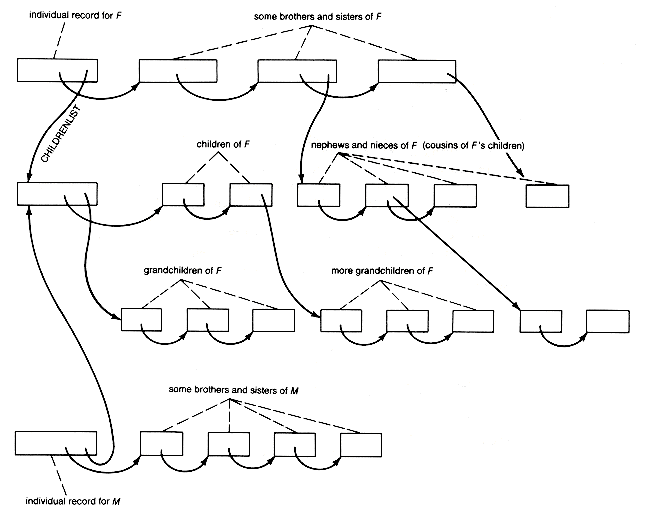
Figure 6.7 Typical Configuration of Individual Records
ir_fptr
ir_mptr
nt_fptr
nt_mptr
JOHN SMITH M 1/2/79 GEORGE SMITH ALICE RICKARD
Table 6.1 Input Data for Example 6.11
Name Sex Birthdate Fathersname Mothersname
-----------------------------------------------------------------------------
Albert Einstein M 3/14/1879 Hermann Einstein Paulina Koch
Leo Tolstoy M 9/9/1828 Nikolai Tolstoy Marie Volkronskii
George Eliot F 11/22/1819 Robert Evans Christina Pearson
Margaret Truman F 2/17/1924 Harry Truman Bess Truman
Wilhelm Bach M 11/22/1710 Johann S. Bach Maria Bach
Jimmy Carter M 10/1/1924 James Earl Carter Lillian Carter
Sir Isaac Newton M 12/25/1642 Isaac Newton Hannah Newton
Harry Truman M 5/8/1884 John Truman Martha Young
Billy Carter M 3/29/1937 James Earl Carter Lillian Carter
Johann S. Bach M 3/21/1685 Johann Ambrosius Bach Elizabeth Lämmerhirt
Johann Gottfried
Bach M 5/11/1715 Johann S. Bach Maria Bach
Table 6.2 The nametable and Individual Records (for Example 6.11) after Initial Input Data Are Processed
Nametable Individual
Records Records
Name Recordptr Nameptr Fnameptr Mnameptr Siblingptr Childrenlist Sex Birthdate
---------------------------------------------------------------------------------------------------------------
1 Albert Einstein 1 1 1 2 3 0 0 M 03141879
2 Hermann Einstein 2 2 2 0 1 M
3 Paulina Koch 3 3 3 0 1 F
4 Leo Tolstoy 4 4 4 5 6 0 0 M 09091828
5 Nikolai Tolstoy 5 5 5 0 4 M
6 Marie Volkronskii 6 6 6 0 4 F
7 George Eliot 7 7 7 8 9 0 0 F 11221819
8 Robert Evans 8 8 8 0 7 M
9 Christina Pearson 9 9 9 0 7 F
10 Margaret Truman 10 10 10 11 12 0 0 F 02171924
11 Harry Truman 11 11 11 0 10 M
12 Bess Truman 12 12 12 0 10 F
13 Wilhelm Bach 13 13 13 14 15 0 0 M 11221710
14 Johann S. Bach 14 14 14 25 26 0 27 M 03211685
15 Maria Bach 15 15 15 0 27 F
16 Jimmy Carter 16 16 16 17 18 0 0 M 10011924
17 James Earl Carter 17 17 17 0 16 M
18 Lilian Carter 18 18 18 0 16 F
19 Sir Isaac Newton 19 19 19 20 21 0 0 M 12251642
20 Isaac Newton 20 20 20 0 19 M
21 Hannah Newton 21 21 21 0 19 F
22 John Truman 22 22 22 11 M
23 Martha Young 23 23 23 11 F
24 Billy Carter 24 24 24 17 18 16 0 M 03291937
25 Johann Ambrosius Bach 25 25 25 0 14 M
26 Elizabeth Lämmerhirt 26 26 26 0 14 F
27 Johann Gottfried Bach 27 27 27 14 15 13 0 M 05111715

(a) With Three New Entries

(b) Updated
(c) With One Additional Entry
(d) Updated Again
Figure 6.8 Nametable and Individual Records with Saved Pointers
CARL BACH M 3/8/1714 JOHANN S. BACH MARIA BACH
6.5.5 Retrieving Information from the System
6.5.6 Other System Components
6.5.7 Case Study Overview
Exercises


JOHANN 0AMBROSIUS BACH M 2/22/1695 CHRISTOPH BACH
MARIA MAGDALENA GRABLER
Suggested Assignment
CHAPTER 1
1.1 ARRAYS
1.2 RECORDS
1.2.1 POINTERS
1.2.2 EXAMPLE
1.3 SUMMARY
CHAPTER 2
2.1 LISTS
2.2 USES
CHAPTER 3
3.1 APPLICATIONS
3.1.1 BACKGROUND
3.1.2 RANKINGS
3.1.2.1 FLOWCHART
typedef struct listrecord
{whatever info;
int recordtype;
struct listrecord *link,*sublist;
}bookrecord,*liststructurepointer;
INFO = 175
RECORDTYPE = COMPLEX
INFO = 0
RECORDTYPE = COMPLEX
INFO = 100
RECORDTYPE = SIMPLE
INFO = 75
RECORDTYPE = SIMPLE
INFO = 450
RECORDTYPE = COMPLEX
INFO = 200
RECORDTYPE = COMPLEX
INFO = 250
RECORDTYPE = SIMPLE
INFO = -46
RECORDTYPE = SIMPLE
1 indicates a nonnull list-structure; 0 would indicate a null list
structure
175 CMPLX
1 1 indicates the link and sublist fields of "175" are not null
0 CMPLX
1 1
100 SMPL
0 indicates the link field of "100" is null; it is thus the last record of
a sublist
75 SMPL
0
450 CMPLX
1 1
200 CMPLX
1 0 indicates the link field of "200" is not null, but its sublist
field is null
250 SMPL
0
-46 SMPL
0