


Number theory was once viewed as a beautiful but largely useless subject in pure mathematics. Today number-theoretic algorithms are used widely, due in part to the invention of cryptographic schemes based on large prime numbers. The feasibility of these schemes rests on our ability to find large primes easily, while their security rests on our inability to factor the product of large primes. This chapter presents some of the number theory and associated algorithms that underlie such applications.
Section 33.1 introduces basic concepts of number theory, such as divisibility, modular equivalence, and unique factorization. Section 33.2 studies one of the world's oldest algorithms: Euclid's algorithm for computing the greatest common divisor of two integers. Section 33.3 reviews concepts of modular arithmetic. Section 33.4 then studies the set of multiples of a given number a, modulo n, and shows how to find all solutions to the equation ax  b (mod n) by using Euclid's algorithm. The Chinese remainder theorem is presented in Section 33.5. Section 33.6 considers powers of a given number a, modulo n, and presents a repeated-squaring algorithm for efficiently computing ab mod n, given a, b, and n. This operation is at the heart of efficient primality testing. Section 33.7 then describes the RSA public-key cryptosystem. Section 33.8 describes a randomized primality test that can be used to find large primes efficiently, an essential task in creating keys for the RSA cryptosystem. Finally, Section 33.9 reviews a simple but effective heuristic for factoring small integers. It is a curious fact that factoring is one problem people may wish to be intractable, since the security of RSA depends on the difficulty of factoring large integers.
b (mod n) by using Euclid's algorithm. The Chinese remainder theorem is presented in Section 33.5. Section 33.6 considers powers of a given number a, modulo n, and presents a repeated-squaring algorithm for efficiently computing ab mod n, given a, b, and n. This operation is at the heart of efficient primality testing. Section 33.7 then describes the RSA public-key cryptosystem. Section 33.8 describes a randomized primality test that can be used to find large primes efficiently, an essential task in creating keys for the RSA cryptosystem. Finally, Section 33.9 reviews a simple but effective heuristic for factoring small integers. It is a curious fact that factoring is one problem people may wish to be intractable, since the security of RSA depends on the difficulty of factoring large integers.
Size of inputs and cost of arithmetic computations
Because we shall be working with large integers, we need to adjust how we think about the size of an input and about the cost of elementary arithmetic operations.
In this chapter, a "large input" typically means an input containing "large integers" rather than an input containing "many integers" (as for sorting). Thus, we shall measure the size of an input in terms of the number of bits required to represent that input, not just the number of integers in the input. An algorithm with integer inputs a1, a2, . . . , ak is a polynomial-time algorithm if it runs in time polynomial in lg a1, lg a2, . . . , lg ak, that is, polynomial in the lengths of its binary-encoded inputs.
In most of this book, we have found it convenient to think of the elementary arithmetic operations (multiplications, divisions, or computing remainders) as primitive operations that take one unit of time. By counting the number of such arithmetic operations an algorithm performs, we have a basis for making a reasonable estimate of the algorithm's actual running time on a computer. Elementary operations can be time-consuming, however, when their inputs are large. It thus becomes convenient to measure how many bit operations a number-theoretic algorithm requires. In this model, a multiplication of two
In this chapter, algorithms are generally analyzed in terms of both the number of arithmetic operations and the number of bit operations they require.
This section provides a brief review of notions from elementary number theory concerning the set Z = {. . . , -2, -1, 0, 1, 2, . . .} of integers and the set N = {0, 1, 2, . . .} of natural numbers.
The notion of one integer being divisible by another is a central one in the theory of numbers. The notation d | a (read "d divides a") means that a = kd for some integer k. Every integer divides 0. If a > 0 and d | a, then |d|
If d | a and d
Every integer a is divisible by the trivial divisors 1 and a. Nontrivial divisors of a are also called factors of a. For example, the factors of 20 are 2, 4, 5, and 10.
An integer a > 1 whose only divisors are the trivial divisors 1 and a is said to be a prime number (or, more simply, a prime). Primes have many special properties and play a critical role in number theory. The small primes, in order, are
Exercise 33.1-1 asks you to prove that there are infinitely many primes. An integer a > 1 that is not prime is said to be a composite number (or, more simply, a composite). For example, 39 is composite because 3 | 39. The integer 1 is said to be a unit and is neither prime nor composite. Similarly, the integer 0 and all negative integers are neither prime nor composite.
Given an integer n, the integers can be partitioned into those that are multiples of n and those that are not multiples of n. Much number theory is based upon a refinement of this partition obtained by classifying the nonmultiples of n according to their remainders when divided by n. The following theorem is the basis for this refinement. The proof of this theorem will not be given here (see, for example, Niven and Zuckerman [151]).
Theorem 33.1
For any integer a and any positive integer n, there are unique integers q and r such that 0
The value q =
or
Given a well-defined notion of the remainder of one integer when divided by another, it is convenient to provide special notation to indicate equality of remainders. If (a mod n) = (b mod n), we write a
The integers can be divided into n equivalence classes according to their remainders modulo n. The equivalence class modulo n containing an integer a is
For example, [3]7 = {. . . , -11, -4, 3, 10, 17, . . .}; other denotations for this set are [-4]7 and [10]7. Writing a
One often sees the definition
which should be read as equivalent to equation (33.3) with the understanding that 0 represents [0]n, 1 represents [1]n, and so on; each class is represented by its least nonnegative element. The underlying equivalence classes must be kept in mind, however. For example, a reference to - 1 as a member of Zn is a reference to [n - 1]n, since - 1
If d is a divisor of a and also a divisor of b, then d is a common divisor of a and b. For example, the divisors of 30 are 1, 2, 3, 5, 6, 10, 15, and 30, and so the common divisors of 24 and 30 are 1, 2, 3, and 6. Note that 1 is a common divisor of any two integers.
An important property of common divisors is that
More generally, we have that
for any integers x and y. Also, if a | b, then either |a|
The greatest common divisor of two integers a and b, not both zero, is the largest of the common divisors of a and b; it is denoted gcd(a, b). For example, gcd(24, 30) = 6, gcd(5, 7) = 1, and gcd(0, 9) = 9. If a and b are not both 0, then gcd(a, b) is an integer between 1 and min(|a|, |b|). We define gcd(0, 0) to be 0; this definition is necessary to make standard properties of the gcd function (such as equation (33.11) below) universally valid.
The following are elementary properties of the gcd function:
Theorem 33.2
If a and b are any integers, not both zero, then gcd(a, b) is the smallest positive element of the set {ax + by : x, y
Proof Let s be the smallest positive such linear combination of a and b, and let s = ax + by for some x, y
and thus a mod s is a linear combination of a and b as well. But, since a mod s < s, we have that a mod s = 0, because s is the smallest positive such linear combination. Therefore, s | a and, by analogous reasoning, s | b. Thus, s is a common divisor of a and b, and so gcd(a, b)
Corollary 33.3
For any integers a and b, if d | a and d | b then d | gcd(a, b) .
Proof This corollary follows from equation (33.6), because gcd(a, b) is a linear combination of a and b by Theorem 33.2.
Corollary 33.4
For all integers a and b and any nonnegative integer n,
Proof If n = 0, the corollary is trivial. If n > 0, then gcd(an, bn) is the smallest positive element of the set {anx + bny}, which is n times the smallest positive element of the set {ax + by}.
Corollary 33.5
For all positive integers n, a, and b, if n | ab and gcd(a, n) = 1, then n | b.
Proof The proof is left as Exercise 33.1-4.
Two integers a, b are said to be relatively prime if their only common divisor is 1, that is, if gcd(a, b) = 1. For example, 8 and 15 are relatively prime, since the divisors of 8 are 1, 2, 4, and 8, while the divisors of 15 are 1, 3, 5, and 15. The following theorem states that if two integers are each relatively prime to an integer p, then their product is relatively prime to p.
Theorem 33.6
For any integers a, b, and p, if gcd(a, p) = 1 and gcd(b, p) = 1, then gcd(ab, p) = 1.
Proof It follows from Theorem 33.2 that there exist integers x, y, x', and y' such that
Multiplying these equations and rearranging, we have
Since 1 is thus a positive linear combination of ab and p, an appeal to Theorem 33.2 completes the proof.
We say that integers n1, n2, . . ., nk are pairwise relatively prime if, whenever i
An elementary but important fact about divisibility by primes is the following.
Theorem 33.7
For all primes p and all integers a, b, if p | ab, then p | a or p | b.
Proof Assume for the purpose of contradiction that p | ab but that
A consequence of Theorem 33.7 is that an integer has a unique factorization into primes.
Theorem 33.8
A composite integer a can be written in exactly one way as a product of the form
where the pi are prime, p1 < p2 < . . . < pr, and the ei are positive integers.
Proof The proof is left Exercise 33.1-10.
As an example, the number 6000 can be uniquely factored as 24.3.53.
33.1-1
Prove that there are infinitely many primes. (Hint: Show that none of the primes p1, p2, . . . , pk divide (p1p2 . . . pk) + 1.)
33.1-2
Prove that if a | b and b | c, then a | c.
33.1-3
Prove that if p is prime and 0 < k < p, then gcd (k, p) = 1.
33.1-4
Prove Corollary 33.5.
33.1-5
Prove that if p is prime and 0 < k < p, then
33.1-6
Prove that if a and b are any integers such that a | b and b > 0, then
for any x. Prove, under the same assumptions, that
for any integers x and y.
33.1-7
For any integer k > 0, we say that an integer n is a kth power if there exists an integer a such that ak = n. We say that n > 1 is a nontrivial power if it is a kth power for some integer k > 1. Show how to determine if a given
33.1-8
Prove equations (33.8)--(33.12).
33.1-9
Show that the gcd operator is associative. That is, prove that for all integers a, b, and c,
33.1-10
Prove Theorem 33.8.
33.1-11
Give efficient algorithms for the operations of dividing a
33.1-12
Give an efficient algorithm to convert a given
In this section, we use Euclid's algorithm to compute the greatest common divisor of two integers efficiently. The analysis of running time brings up a surprising connection with the Fibonacci numbers, which yield a worst-case input for Euclid's algorithm.
We restrict ourselves in this section to nonnegative integers. This restriction is justified by equation (33.10), which states that gcd(a,b) = gcd(|a|, |b|).
In principle, we can compute gcd(a, b) for positive integers a and b from the prime factorizations of a and b. Indeed, if
with zero exponents being used to make the set of primes p1, p2, . . . , pr the same for both a and b, then
As we shall show in Section 33.9, the best algorithms to date for factoring do not run in polynomial time. Thus, this approach to computing greatest common divisors seems unlikely to yield an efficient algorithm.
Euclid's algorithm for computing greatest common divisors is based on the following theorem.
Theorem 33.9
For any nonnegative integer a and any positive integer b,
Proof We shall show that gcd (a, b) and gcd (b, a mod b) divide each other, so that by equation (33.7) they must be equal (since they are both nonnegative).
We first show that gcd (a, b) | gcd(b, a mod b). If we let d = gcd (a, b), then d | a and d | b. By equation (33.2), (a mod b) = a - qb, where q =
Showing that gcd (b, a mod b) | gcd(a, b) is almost the same. If we now let d = gcd(b, a mod b), then d | b and d | (a mod b). Since a = qb + (a mod b), where q =
Using equation (33.7) to combine equations (33.16) and (33.17) completes the proof.
The following gcd algorithm is described in the Elements of Euclid (circa 300 B.C.), although it may be of even earlier origin. It is written as a recursive program based directly on Theorem 33.9. The inputs a and b are arbitrary nonnegative integers.
As an example of the running of EUCLID, consider the computation of gcd (30,21):
In this computation, there are three recursive invocations of EUCLID.
The correctness of EUCLID follows from Theorem 33.9 and the fact that if the algorithm returns a in line 2, then b = 0, so equation (33.11) implies that gcd(a, b) = gcd(a, 0) = a. The algorithm cannot recurse indefinitely, since the second argument strictly decreases in each recursive call. Therefore, EUCLID always terminates with the correct answer.
We analyze the worst-case running time of EUCLID as a function of the size of a and b. We assume with little loss of generality that a > b
The overall running time of EUCLID is proportional to the number of recursive calls it makes. Our analysis makes use of the Fibonacci numbers Fk, defined by the recurrence (2.13).
Lemma 33.10
If a > b
Proof The proof is by induction on k. For the basis of the induction, let k = 1. Then, b
Assume inductively that the lemma is true if k - 1 recursive calls are made; we shall then prove that it is true for k recursive calls. Since k > 0, we have b > 0, and EUCLID (a, b) calls EUCLID (b, a mod b) recursively, which in turn makes k - 1 recursive calls. The inductive hypothesis then implies that b
since a > b > 0 implies
The following theorem is an immediate corollary of this lemma.
Theorem 33.11
For any integer k
We can show that the upper bound of Theorem 33.11 is the best possible. Consecutive Fibonacci numbers are a worst-case input for EUCLID. Since Euclid (F3, F2) makes exactly one recursive call, and since for k
Thus, Euclid(Fk+1,Fk) recurses exactly k - 1 times, meeting the upper bound of Theorem 33.11.
Since Fk is approximately
We now rewrite Euclid's algorithm to compute additional useful information. Specifically, we extend the algorithm to compute the integer coefficients x and y such that
Note that x and y may be zero or negative. We shall find these coefficients useful later for the computation of modular multiplicative inverses. The
procedure EXTENDED-EUCLID takes as input an arbitrary pair of integers and returns a triple of the form (d, x, y) that satisfies equation (33.18).
Figure 33.1 illustrates the execution of EXTENDED-EUCLID with the computation of gcd(99,78).
The EXTENDED-EUCLID procedure is a variation of the EUCLID procedure. Line 1 is equivalent to the test "b = 0" in line 1 of EUCLID. If b = 0, then EXTENDED-EUCLID returns not only d = a in line 2, but also the coefficients x = 1 and y = 0, so that a = ax + by. If b
As for EUCLID, we have in this case d = gcd(a, b) = d' = gcd(b, a mod b). To obtain x and y such that d = ax + by, we start by rewriting equation (33.19) using the equation d = d' and equation (33.2):
Thus, choosing x = y' and y = x' -
Since the number of recursive calls made in EUCLID is equal to the number of recursive calls made in EXTENDED-EUCLID, the running times of EUCLID and EXTENDED-EUCLID are the same, to within a constant factor. That is, for a > b > 0, the number of recursive calls is O(lg b).
33.2-1
Prove that equations (33.13)--(33.14) imply equation (33.15).
33.2-2
Compute the values (d, x, y) that are output by the invocation EXTENDED-EUCLID(899, 493).
33.2-3
Prove that for all integers a, k, and n,
33.2-4
Rewrite EUCLID in an iterative form that uses only a constant amount of memory (that is, stores only a constant number of integer values).
33.2-5
If a > b
33.2-6
What does EXTENDED-EUCLID(Fk + 1, Fk) return? Prove your answer correct.
33.2-7
Verify the output (d, x, y) of EXTENDED-EUCLID(a, b) by showing that if d | a, d | b, and d = ax + by, then d = gcd(a, b).
33.2-8
Define the gcd function for more than two arguments by the recursive equation gcd(a0, al, . . . , n) = gcd(a0, gcd(a1, . . . , an)). Show that gcd returns the same answer independent of the order in which its arguments are specified. Show how to find x0, x1, . . . . , xn such that gcd(a0, a1, . . . , an) = a0x0 + a1x1 + . . . + anxn. Show that the number of divisions performed by your algorithm is O(n + 1g(maxi, ai)).
33.2-9
Define lcm(a1, a2, . . . , an) to be the least common multiple of the integers a1, a2, . . . , an, that is, the least nonnegative integer that is a multiple of each ai. Show how to compute lcm(a1, a2, . . . , an) efficiently using the (two-argument) gcd operation as a subroutine.
33.2-10
Prove that n1, n2, n3, and n4 are pairwise relatively prime if and only if gcd(n1n2, n3n4) = gcd(n1n3, n2n4) = 1. Show more generally that n1, n2, . . . , nk are pairwise relatively prime if and only if a set of
Informally, we can think of modular arithmetic as arithmetic as usual over the integers, except that if we are working modulo n, then every result x is replaced by the element of {0, 1, . . . , n - 1} that is equivalent to x, modulo n (that is, x is replaced by x mod n). This informal model is sufficient if we stick to the operations of addition, subtraction, and multiplication. A more formal model for modular arithmetic, which we now give, is best described within the framework of group theory.
A group (S,
1. Closure: For all a, b
2. Identity: There is an element e
3. Associativity: For all a, b, c
4. Inverses: For each a
As an example, consider the familiar group (Z, +) of the integers Z under the operation of addition: 0 is the identity, and the inverse of a is -a. If a group (S,
We can form two finite abelian groups by using addition and multiplication modulo n, where n is a positive integer. These groups are based on the equivalence classes of the integers modulo n, defined in Section 33.1.
To define a group on Zn, we need to have suitable binary operations, which we obtain by redefining the ordinary operations of addition and multiplication. It is easy to define addition and multiplication operations for Zn, because the equivalence class of two integers uniquely determines the equivalence class of their sum or product. That is, if a
Thus, we define addition and multiplication modulo n, denoted +n and .n, as follows:
(Subtraction can be similarly defined on Zn by [a]n - n [b]n = [a - b]n, but division is more complicated, as we shall see.) These facts justify the common and convenient practice of using the least nonnegative element of each equivalence class as its representative when performing computations in Zn. Addition, subtraction, and multiplication are performed as usual on the representatives, but each result x is replaced by the representative of its class (that is, by x mod n).
Using this definition of addition modulo n, we define the additive group modulo n as (Zn, + n). This size of the additive group modulo n is |Zn| = n. Figure 33.2(a) gives the operation table for the group (Z6, + 6).
Theorem 33.12
The system (Zn, + n) is a finite abelian group.
Proof Associativity and commutativity of +n follow from the associativity and commutativity of +:
The identity element of (Zn,+n) is 0 (that is, [0]n). The (additive) inverse of an element a (that is, [a]n) is the element -a (that is, [-a]n or [n - a]n), since [a]n +n [-a]n=[a - a]n=[0]n.
Using the definition of multiplication modulo n, we define the multiplicative group modulo n as
To see that
where the group operation is multiplication modulo 15. (Here we denote an element [a]15 as a.) Figure 33.2(b) shows the group
Theorem 33.13
The system
Proof Theorem 33.6 implies that
or, equivalently,
Thus, [x]n is a multiplicative inverse of [a]n, modulo n. The proof that inverses are uniquely defined is deferred until Corollary 33.26.
When working with the groups (Zn,+n) and (Zn,
As a further convenience, we sometimes refer to a group (S,
The (multiplicative) inverse of an element a is denoted (a-1 mod n). Division in
The size of
where p runs over all the primes dividing n (including n itself, if n is prime). We shall not prove this formula here. Intuitively, we begin with a list of the n remainders {0, 1, . . . , n - 1 } and then, for each prime p that divides n, cross out every multiple of p in the list. For example, since the prime divisors of 45 are 3 and 5,
If p is prime, then
If n is composite, then
If (S,
Theorem 33.14
If (S,
Proof The proof is left as Exercise 33.3-2.
For example, the set {0, 2, 4, 6} forms a subgroup of Z8,since it is closed under the operation + (that is, it is closed under +8).
The following theorem provides an extremely useful constraint on the size of a subgroup.
Theorem 33.15
If (S,
A subgroup S' of a group S is said to be a proper subgroup if S'
Corollary 33.16
If S' is a proper subgroup of a finite group S, then |S'|
Theorem 33.14 provides an interesting way to produce a subgroup of a finite group (S,
For example, if we take a = 2 in the group Z6, the sequence a(1), a(2), . . . is
In the group Zn, we have a(k) = ka mod n, and in the group
We say that a generates the subgroup
Similarly, in
The order of a (in the group S), denoted ord(a), is defined as the least t > 0 such that a(t) = e.
Theorem 33.17
For any finite group (S,
Proof Let t = ord(a). Since a(t) = e and a(t+k) = a(t)
Corollary 33.18
The sequence a(1), a(2), . . . is periodic with period t = ord(a); that is, a(i) = a(j) if and only if i
It is consistent with the above corollary to define a(0) as e and a(i) as a(i mod t) for all integers i.
Corollary 33.19
If (S,
Proof Lagrange's theorem implies that ord(a) | |S|, and so |S|
33.3-1
Draw the group operation tables for the groups (Z4, +4) and
33.3-2
Prove Theorem 33.14.
33.3-3
Show that if p is prime and e is a positive integer, then
33.3-4
Show that for any n > 1 and for any
33.3-5
List all of the subgroups of Z9 and of
We now consider the problem of finding solutions to the equation
where n > 0, an important practical problem. We assume that a, b, and n are given, and we are to find the x's, modulo n, that satisfy equation (33.22). There may be zero, one, or more than one such solution.
Let
Theorem 33.20
For any positive integers a and n, if d = gcd(a, n), then
and thus
Proof We begin by showing that d
Since d
We now show that
Combining these results, we have that
Corollary 33.21
The equation ax
Corollary 33.22
The equation ax
Proof If ax
Theorem 33.23
Let d = gcd(a, n), and suppose that d = ax' + ny' for some integers x' and y' (for example, as computed by EXTENDED EUCLID). If d | b, then the equation ax
Proof Since ax'
and thus x0 is a solution to ax
Theorem 33.24
Suppose that the equation ax
Proof Since n/d > 0 and 0
We have now developed the mathematics needed to solve the equation ax
As an example of the operation of this procedure, consider the equation 14x
The procedure MODULAR-LINEAR-EQUATION-SOLVER works as follows. Line 1 computes d = gcd(a, n) as well as two values x'' and y'' such that d = ax' + ny', demonstrating that x'' is a solution to the equation ax'
The running time of MODULAR-LINEAR-EQUATION-SOLVER is O(lg n + gcd(a,n)) arithmetic operations, since EXTENDED-EUCLID takes O(lg n) arithmetic operations, and each iteration of the for loop of lines 4-5 takes a constant number of arithmetic operations.
The following corollaries of Theorem 33.24 give specializations of particular interest.
Corollary 33.25
For any n > 1, if gcd(a,n) = 1, then the equation ax
If b = 1, a common case of considerable interest, the x we are looking for is a multiplicative inverse of a, modulo n.
Corollary 33.26
For any n > 1, if gcd(a, n) = 1, then the equation
has a unique solution, modulo n. Otherwise, it has no solution.
Corollary 33.26 allows us to use the notation (a-1 mod n) to refer to the multiplicative inverse of a, modulo n, when a and n are relatively prime. If gcd(a, n) = 1, then one solution to the equation ax
implies ax
33.4-1
Find all solutions to the equation 35x
33.4-2
Prove that the equation ax
33.4-3
Consider the following change to line 3 of MODULAR-LINEAR-EQUATiON-SOLVER:
Will this work? Explain why or why not.
33.4-4
Let f(x)
Around A.D. 100, the Chinese mathematician
The Chinese remainder theorem has two major uses. Let the integer n = nl n2 . . . nk, where the factors ni are pairwise relatively prime. First, the Chinese remainder theorem is a descriptive "structure theorem" that describes the structure of Zn as identical to that of the Cartesian product Zn1 XZn2 X . . . X Znk with componentwise addition and multiplication modulo ni in the ith component. Second, this description can often be used to yield efficient algorithms, since working in each of the systems Zni can be more efficient (in terms of bit operations) than working modulo n.
Theorem 33.27
Let n = n1 n2 . . . nk, where the ni are pairwise relatively prime. Consider the correspondence
where a
for i = 1, 2, . . . , k. Then, mapping (33.25) is a one-to-one correspondence (bijection) between Zn and the Cartesian product ZniXZn2 X . . . X Znk. Operations performed on the elements of Zn can be equivalently performed on the corresponding k-tuples by performing the operations independently in each coordinate position in the appropriate system. That is, if
then
Proof Transforming between the two representations is quite straight-forward. Going from a to (al, a2, . . . , ak) requires only k divisions. Computing a from inputs (al, a2, . . . , ak) is almost as easy, using the following formula. Let mi = n/ni for i = 1,2, . . . , k. Note that mi = nln2 . . . ni-lni+l . . . nk, so that mi
for i = 1, 2, . . . , k, we have
Equation 33.29 is well defined, since mi and ni are relatively prime (by Theorem 33.6), and so Corollary 33.26 implies that (mi-l mod ni) is defined. To verify equation (33.30), note that cj
a vector that has 0's everywhere except in the ith coordinate, where it has a 1. The ci thus form a "basis" for the representation, in a certain sense. For each i, therefore, we have
Since we can transform in both directions, the correspondence is one-to-one. Equations (33.26)--(33.28) follow directly from Exercise 33.1-6, since x mod ni = (x mod n) mod ni for any x and i = 1, 2, . . . , k.
The following corollaries will be used later in this chapter.
Corollary 33.28
If n1, n2, . . . , nk are pairwise relatively prime and n = n1n2...nk, then for any integers a1, a2, . . . , ak, the set of simultaneous equations
for i = 1, 2, . . . , k, has a unique solution modulo n for the unknown x.
Corollary 33.29
If n1, n2, . . . , nk are pairwise relatively prime and n = n1 n2 . . . nk, then for all integers x and a,
for i = 1, 2, . . . , k if and only if
As an example of the Chinese remainder theorem, suppose we are given the two equations
so that a1 = 2, n1 = m2 = 5, a2 = 3, and n2 = m1 = 13, and we wish to compute a mod 65, since n = 65. Because 13-1
and
See Figure 33.3 for an illustration of the Chinese remainder theorem, modulo 65.
Thus, we can work modulo n by working modulo n directly or by working in the transformed representation using separate modulo ni computations, as convenient. The computations are entirely equivalent.
33.5-1
Find all solutions to the equations x
33.5-2
Find all integers x that leave remainders 1, 2, 3, 4, 5 when divided by 2, 3, 4, 5, 6, respectively.
33.5-3
Argue that, under the definitions of Theorem 33.27, if gcd(a, n) = 1, then
33.5-4
Under the definitions of Theorem 33.27, prove that the number of roots of the equation f(x)
Just as it is natural to consider the multiples of a given element a, modulo n, it is often natural to consider the sequence of powers of a, modulo n, where
modulo n. Indexing from 0, the 0th value in this sequence is a0 mod n = 1, and the ith value is ai mod n. For example, the powers of 3 modulo 7 are
whereas the powers of 2 modulo 7 are
In this section, let
Theorem 33.30
For any integer n > 1,
Theorem 33.31
If p is prime, then
Proof By equation (33.21),
This corollary applies to every element in Zp except 0, since
If
Theorem 33.32
The values of n > 1 for which
If g is a primitive root of
Theorem 33.33
If g is a primitive root of
Proof Suppose first that x
Conversely, suppose that gx
Taking discrete logarithms can sometimes simplify reasoning about a modular equation, as illustrated in the proof of the following theorem.
Theorem 33.34
If p is an odd prime and e
has only two solutions, namely x = 1 and x = - 1.
Proof Let n = pe. Theorem 33.32 implies that
After noting that indn,g(1) = 0, we observe that Theorem 33.33 implies that equation (33.35) is equivalent to
To solve this equation for the unknown indn,g(x), we apply the methods of Section 33.4. Letting d = gcd(2,
A number x is a nontrivial square root of 1, modulo n, if it satisfies the equation x2
Corollary 33.35
If there exists a nontrivial square root of 1, modulo n, then n is composite.
Proof This corollary is just the contrapositive to Theorem 33.34. If there exists a nontrivial square root of 1, modulo n, then n can't be a prime or a power of a prime.
A frequently occurring operation in number-theoretic computations is raising one number to a power modulo another number, also known as modular exponentiation. More precisely, we would like an efficient way to compute ab mod n, where a and b are nonnegative integers and n is a positive integer. Modular exponentiation is also an essential operation in many primality-testing routines and in the RSA public-key cryptosystem. The method of repeated squaring solves this problem efficiently using the binary representation of b.
Let
Each exponent computed in a sequence is either twice the previous exponent or one more than the previous exponent; the binary representation
of b is read from right to left to control which operations are performed. Each iteration of the loop uses one of the identities
depending on whether bi = 0 or 1, respectively. The essential use of squaring in each iteration explains the name "repeated squaring." Just after bit bi is read and processed, the value of c is the same as the prefix
The variable c is not really needed by the algorithm but is included for explanatory purposes: the algorithm preserves the invariant that d = ac mod n as it increases c by doublings and incrementations until c = b. If the inputs a, b, and n are
33.6-1
Draw a table showing the order of every element in
33.6-2
Give a modular exponentiation algorithm that examines the bits of b from right to left instead of left to right.
33.6-3
Explain how to compute a -1 mod n for any
A public-key cryptosystem can be used to encrypt messages sent between two communicating parties so that an eavesdropper who overhears the encrypted messages will not be able to decode them. A public-key cryptosystem also enables a party to append an unforgeable "digital signature" to the end of an electronic message. Such a signature is the electronic version of a handwritten signature on a paper document. It can be easily checked by anyone, forged by no one, yet loses its validity if any bit of the message is altered. It therefore provides authentication of both the identity of the signer and the contents of the signed message. It is the perfect tool for electronically signed business contracts, electronic checks, electronic purchase orders, and other electronic communications that must be authenticated.
The RSA public-key cryptosystem is based on the dramatic difference between the ease of finding large prime numbers and the difficulty of factoring the product of two large prime numbers. Section 33.8 describes an efficient procedure for finding large prime numbers, and Section 33.9 discusses the problem of factoring large integers.
In a public-key cryptosystem, each participant has both a public key and a secret key. Each key is a piece of information. For example, in the RSA cryptosystem, each key consists of a pair of integers. The participants "Alice" and "Bob" are traditionally used in cryptography examples; we denote their public and secret keys as PA, SA for Alice and PB, SB for Bob.
Each participant creates his own public and secret keys. Each keeps his secret key secret, but he can reveal his public key to anyone or even publish it. In fact, it is often convenient to assume that everyone's public key is available in a public directory, so that any participant can easily obtain the public key of any other participant.
The public and secret keys specify functions that can be applied to any message. Let 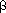 -bit integers by the ordinary method uses
-bit integers by the ordinary method uses 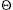 (2) bit operations. Similarly, the operation of dividing a -bit integer by a shorter integer, or the operation of taking the remainder of a -bit integer when divided by a shorter integer, can be performed in time (2) by simple algorithms. (See Exercise 33.1-11.) Faster methods are known. For example, a simple divide-and-conquer method for multiplying two -bit integers has a running time of (lg2 3), and the fastest known method has a running time of ( lg lg lg ). For practical purposes, however, the (2) algorithm is often best, and we shall use this bound as a basis for our analyses.
(2) bit operations. Similarly, the operation of dividing a -bit integer by a shorter integer, or the operation of taking the remainder of a -bit integer when divided by a shorter integer, can be performed in time (2) by simple algorithms. (See Exercise 33.1-11.) Faster methods are known. For example, a simple divide-and-conquer method for multiplying two -bit integers has a running time of (lg2 3), and the fastest known method has a running time of ( lg lg lg ). For practical purposes, however, the (2) algorithm is often best, and we shall use this bound as a basis for our analyses.33.1 Elementary number-theoretic notions
Divisibility and divisors
 |a|. If d | a, then we also say that a is a multiple of d. If d does not divide a, we write
|a|. If d | a, then we also say that a is a multiple of d. If d does not divide a, we write  .
. 0, we say that d is a divisor of a. Note that d | a if and only if -d | a, so that no generality is lost by defining the divisors to be nonnegative, with the understanding that the negative of any divisor of a also divides a. A divisor of an integer a is at least 1 but not greater than |a|. For example, the divisors of 24 are 1, 2, 3, 4, 6, 8, 12, and 24.
0, we say that d is a divisor of a. Note that d | a if and only if -d | a, so that no generality is lost by defining the divisors to be nonnegative, with the understanding that the negative of any divisor of a also divides a. A divisor of an integer a is at least 1 but not greater than |a|. For example, the divisors of 24 are 1, 2, 3, 4, 6, 8, 12, and 24.Prime and composite numbers
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59,... .
The division theorem, remainders, and modular equivalence
r < n and a = qn + r. 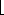 a/n
a/n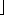 is the quotient of the division. The value r = a mod n is the remainder (or residue) of the division. We have that n | a if and only if a mod n = 0. It follows that
is the quotient of the division. The value r = a mod n is the remainder (or residue) of the division. We have that n | a if and only if a mod n = 0. It follows thata =
a/n n + (a mod n)(33.1)
a mod n = a -
a/n n .(33.2)
b (mod n) and say that a is equivalent to b, modulo n. In other words, a b (mod n) if a and b have the same remainder when divided by n. Equivalently, a b (mod n) if and only if n | (b - a). We write a  b (mod n) if a is not equivalent to b, modulo n. For example, 61 6 (mod 11). Also, -13 22 2 (mod 5).
b (mod n) if a is not equivalent to b, modulo n. For example, 61 6 (mod 11). Also, -13 22 2 (mod 5).[a]n = {a + kn : k  Z} . [b]n is the same as writing a b (mod n). The set of all such equivalence classes is
Z} . [b]n is the same as writing a b (mod n). The set of all such equivalence classes isZn = {[a]n : 0 a n - 1}.(33.3)
Zn = {0, 1,..., n - 1},(33.4)
n - 1 (mod n).Common divisors and greatest common divisors
d | a and d | b implies d | (a + b) and d | (a - b).
(33.5)
d | a and d | b implies d | (ax + by)
(33.6)
|b| or b = 0, which implies thata | b and b | a implies a =
 b.
b.(33.7)
gcd(a,b) = gcd(b,a),
(33.8)
gcd(a,b) = gcd(-a,b),
(33.9)
gcd(a,b) = gcd(|a| , |b|),
(33.10)
gcd(a,0) = |a|,
(33.11)
gcd(a,ka) = |a| for any k
Z.(33.12)
Z}of linear combinations of a and b. Z. Let q = a/s. Equation (33.2) then impliesa mod s = a - qs
= a - q(ax + by)
= a(1 - qx) + b(-qy),
s. Equation (33.6) implies that gcd(a, b) | s, since gcd(a, b) divides both a and b and s is a linear combination of a and b. But gcd(a, b) | s and s > 0 imply that gcd(a, b) s. Combining gcd(a, b) s and gcd(a, b) s yields gcd(a, b) = s; we conclude that s is the greatest common divisor of a and b. gcd(an, bn) = n gcd(a, b).
Relatively prime integers
ax + py = 1,
bx' + py' = 1.
ab(xx') + p(ybx' + y'ax + pyy') = 1.
 j, we have gcd(ni, nj) = 1.
j, we have gcd(ni, nj) = 1.Unique factorization
 . Thus, gcd(a, p) = 1 and gcd(b, p) = 1, since the only divisors of p are 1 and p, and by assumption p divides neither a nor b. Theorem 33.6 then implies that gcd(ab, p) = 1, contradicting our assumption that p | ab, since p | ab implies gcd(ab, p) = p. This contradiction completes the proof.
. Thus, gcd(a, p) = 1 and gcd(b, p) = 1, since the only divisors of p are 1 and p, and by assumption p divides neither a nor b. Theorem 33.6 then implies that gcd(ab, p) = 1, contradicting our assumption that p | ab, since p | ab implies gcd(ab, p) = p. This contradiction completes the proof. 
Exercises
 . Conclude that for all integers a, b, and primes p,
. Conclude that for all integers a, b, and primes p,(a + b)p
ap + bp (mod p).(x mod b) mod a = x mod a
x
y (mod b) implies x y (mod a)-bit integer n is a nontrivial power in time polynomial in .gcd(a, gcd(b, c)) = gcd(gcd(a, b), c) .
-bit integer by a shorter integer and of taking the remainder of a -bit integer when divided by a shorter integer. Your algorithms should run in time O(2).-bit (binary) integer to a decimal representation. Argue that if multiplication or division of integers whose length is at most takes time M(), then binary-to-decimal conversion can be performed in time (M() lg ). (Hint: Use a divide-and-conquer approach, obtaining the top and bottom halves of the result with separate recursions.)33.2 Greatest common divisor

(33.13)
(33.14)

(33.15)
gcd(a,b) = gcd(b,a mod b) .
a/b. Since (a mod b) is thus a linear combination of a and b, equation (33.6) implies that d | (a mod b). Therefore, since d | b and d | (a mod b), Corollary 33.3 implies that d | gcd(b, a mod b) or, equivalently, thatgcd(a, b) | gcd(b, a mod b).
(33.16)
a/b, we have that a is a linear combination of b and (a mod b). By equation (33.6), we conclude that d | a. Since d | b and d | a, we have that d | gcd(a, b) by Corollary 33.3 or, equivalently, thatgcd (b,a mod b) | gcd(a,b).
(33.17)
Euclid's algorithm
EUCLID (a, b)
1 if b = 0
2 then return a
3 else return EUCLID(b,a mod b)
EUCLID(30, 21) = EUCLID(21, 9)
= EUCLID(9, 3)
= EUCLID(3, 0)
= 3 .
The running time of Euclid's algorithm
0. This assumption can be justified by the observation that if b > a 0, then Euclid (a, b) immediately makes the recursive call EUCLID (b, a). That is, if the first argument is less than the second argument, EUCLID spends one recursive call swapping its arguments and then proceeds. Similarly, if b = a > 0, the procedure terminates after one recursive call, since a mod b = 0. 0 and the invocation Euclid(a, b) performs k 1 recursive calls, then a Fk+2 and b Fk+l. 1 = F2, and since a > b, we must have a 2 = F3. Since b > (a mod b), in each recursive call the first argument is strictly larger than the second; the assumption that a > b therefore holds for each recursive call. Fk+ 1 (thus proving part of the lemma), and (a mod b) Fk. We haveb + (a mod b) = b + (a -
a/b b) a,a/b 1. Thus,a
b + (a mod b) Fk + 1 + Fk= Fk+2 .
1, if a > b 0 and b < Fk+1, then the invocation EUCLID (a, b) makes fewer than k recursive calls. 2 we have Fk+1 mod Fk = Fk-1, we also havegcd(Fk+1,Fk) = gcd(Fk, (Fk+1 mod Fk))
= gcd(Fk, Fk-1) .
 , where
, where 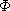 is the golden ratio
is the golden ratio  defined by equation (2.14), the number of recursive calls in EUCLID is O(lg b). (See Exercise 33.2-5 for a tighter bound.) It follows that if EUCLID is applied to two -bit numbers, then it will perform O() arithmetic operations and O(3) bit operations (assuming that multiplication and division of -bit numbers take O(2) bit operations). Problem 33-2 asks you to show an O(2) bound on the number of bit operations.
defined by equation (2.14), the number of recursive calls in EUCLID is O(lg b). (See Exercise 33.2-5 for a tighter bound.) It follows that if EUCLID is applied to two -bit numbers, then it will perform O() arithmetic operations and O(3) bit operations (assuming that multiplication and division of -bit numbers take O(2) bit operations). Problem 33-2 asks you to show an O(2) bound on the number of bit operations.The extended form of Euclid's algorithm
d = gcd(a,b) = ax + by .
(33.18)
a b
a/b d x y-------------------------
99 78 1 3 -11 14
78 21 3 3 3 -11
21 15 1 3 -2 3
15 6 2 3 1 -2
6 3 2 3 0 1
3 0 -- 3 1 0
Figure 33.1 An example of the operation of EXTENDED-EUCLID on the inputs 99 and 78. Each line shows for one level of the recursion: the values of the inputs a and b, the computed value
a/b, and the values d, x, and y returned. The triple (d,x,y) returned becomes the triple (d',x',y') used in the computation at the next higher level of recursion. The call EXTENDED-EUCLID(99, 78) returns (3, -11, 14), so gcd(99, 78) = 3 and gcd(99, 78) = 3 = 99 . (-11) + 78  14.
14.EXTENDED-EUCLID(a, b)
1 f b = 0
2 then return (a, 1, 0)
3 (d',x',y')
 EXTENDED-EUCLID(b, a mod b)
EXTENDED-EUCLID(b, a mod b)4 (d,x,y)
(d',y',x' - a/b y')5 return (d,x,y)
0, EXTENDED-EUCLID first computes (d', x', y') such that d' = gcd(b, a mod b) andd' = bx' + (a mod b)y' .
(33.19)
d = bx' + (a -
a/b b)y'= ay' + b(x' -
a/b y') .a/b y' satisfies the equation d = ax + by, proving the correctness of EXTENDED-EUCLID.Exercises
gcd(a, n) = gcd(a + kn, n).
0, show that the invocation EUCLID(a, b) makes at most 1 + logb recursive calls. Improve this bound to 1 +log(b/gcd(a, b)). lg k
lg k pairs of numbers derived from the ni are relatively prime.
pairs of numbers derived from the ni are relatively prime.33.3 Modular arithmetic
Finite groups
 ) is a set S together with a binary operation defined on S for which the following properties hold. S, we have a b S. S such that e a = a e = a for all a S. S, we have (a b) c = a (b c). S, there exists a unique element b S such that a b = b a = e.) satisfies the commutative law a b = b a for all a, b S, then it is an abelian group. If a group (S, ) satisfies |S| <
) is a set S together with a binary operation defined on S for which the following properties hold. S, we have a b S. S such that e a = a e = a for all a S. S, we have (a b) c = a (b c). S, there exists a unique element b S such that a b = b a = e.) satisfies the commutative law a b = b a for all a, b S, then it is an abelian group. If a group (S, ) satisfies |S| <  , then it is a finite group.
, then it is a finite group.The groups defined by modular addition and multiplication
a' (mod n) and b b' (mod n), thena + b
a' + b' (mod n) ,ab
a'b' (mod n) .+6 0 1 2 3 4 5
15 1 2 4 7 8 11 13 14-------------------- -------------------------------------
0 0 1 2 3 4 5 1 1 2 4 7 8 11 13 14
1 0 2 3 4 5 0 2 2 4 8 14 1 7 11 13
2 0 3 4 5 0 1 4 4 8 1 13 2 14 7 11
3 0 4 5 0 1 2 7 7 14 13 4 11 2 1 8
4 0 5 0 1 2 3 8 8 1 2 11 4 13 14 7
5 5 0 1 2 3 4 11 11 7 14 2 13 1 8 4
13 13 11 7 1 14 8 4 2
14 14 13 11 8 7 4 2 1
(a) (b)
Figure 33.2 Two finite groups. Equivalence classes are denoted by their representative elements. (a) The group (Z6, +6). (b) The group

[a]n + n [b]n = [a + b]n ,
[a]n
n[b]n = [ab]n .([a]n + n[b]n) +n[c]n = [(a + b) + c]n
= [a + (b + c)]n
= [a]n + n([b]n + n[c]n),
[a]n + n[b]n = [a + b]n
= [b + a]n
= [b]n + n[a]n .
 . The elements of this group are the set
. The elements of this group are the set  of elements in Zn that are relatively prime to n:
of elements in Zn that are relatively prime to n:
 is well defined, note that for 0 a < n, we have a (a+kn) (mod n) for all integers k. By Exercise 33.2-3, therefore, gcd(a, n) = 1 implies gcd(a+kn, n) = 1 for all integers k. Since [a]n = {a + kn : k Z}, the set
is well defined, note that for 0 a < n, we have a (a+kn) (mod n) for all integers k. By Exercise 33.2-3, therefore, gcd(a, n) = 1 implies gcd(a+kn, n) = 1 for all integers k. Since [a]n = {a + kn : k Z}, the set  is well defined. An example of such a group is
is well defined. An example of such a group is
 . For example, 8
. For example, 8  11 13 (mod 15), working in
11 13 (mod 15), working in  . The identity for this group is 1.
. The identity for this group is 1. is a finite abelian group.
is a finite abelian group. is closed. Associativity and commutativity can be proved for .n as they were for +n in the proof of Theorem 33.12. The identity element is [1]n. To show the existence of inverses, let a be an element of
is closed. Associativity and commutativity can be proved for .n as they were for +n in the proof of Theorem 33.12. The identity element is [1]n. To show the existence of inverses, let a be an element of  and let (d, x, y) be the output of EXTENDED-EUCLID(a, n). Then d = 1, since a
and let (d, x, y) be the output of EXTENDED-EUCLID(a, n). Then d = 1, since a  , and
, andax + ny = 1
ax
1 (mod n).n) in the remainder of this chapter, we follow the convenient practice of denoting equivalence classes by their representative elements and denoting the operations +n and .n by the usual arithmetic notations + and (or juxtaposition) respectively. Also, equivalences modulo n may also be interpreted as equations in Zn. For example, the following two statements are equivalent:ax
b (mod n) ,[a]n n [x]n = [b]n .
) merely as S when the operation is understood from context. We may thus refer to the groups (Zn, + n) and  as Zn and
as Zn and  respectively.
respectively. is defined by the equation a/b ab-1 (mod n). For example, in
is defined by the equation a/b ab-1 (mod n). For example, in  we have that 7-1 13 (mod 15), since 7 . 13 91 1 (mod 15), so that 4/7 4 . 13 7 (mod 15).
we have that 7-1 13 (mod 15), since 7 . 13 91 1 (mod 15), so that 4/7 4 . 13 7 (mod 15). is denoted (n). This function, known as Euler's phi function, satisfies the equation
is denoted (n). This function, known as Euler's phi function, satisfies the equation
(33.20)

 , and(p) = p - 1.
, and(p) = p - 1.(33.21)
(n) < n - 1.Subgroups
) is a group, S' 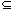 S, and (S', ) is also a group, then (S', ) is said to be a subgroup of (S, ). For example, the even integers form a subgroup of the integers under the operation of addition. The following theorem provides a useful tool for recognizing subgroups.) is a finite group and S' is any subset of S such that a b S' for all a, b S', then (S',) is a subgroup of (S, ).) is a finite group and (S, ) is a subgroup of (S, ), then |S'| is a divisor of |S|. S. The following corollary will be used in our analysis of the Miller-Rabin primality test procedure in Section 33.8. |S|/2.
S, and (S', ) is also a group, then (S', ) is said to be a subgroup of (S, ). For example, the even integers form a subgroup of the integers under the operation of addition. The following theorem provides a useful tool for recognizing subgroups.) is a finite group and S' is any subset of S such that a b S' for all a, b S', then (S',) is a subgroup of (S, ).) is a finite group and (S, ) is a subgroup of (S, ), then |S'| is a divisor of |S|. S. The following corollary will be used in our analysis of the Miller-Rabin primality test procedure in Section 33.8. |S|/2. Subgroups generated by an element
): choose an element a and take all elements that can be generated from a using the group operation. Specifically, define a(k) for k 1 by
2, 4, 0, 2, 4, 0, 2, 4, 0,... .
 , we have a(k) = ak mod n. The subgroup generated by a, denoted
, we have a(k) = ak mod n. The subgroup generated by a, denoted 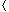 a
a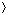 or (a, ), is defined bya = {a(k): k 1}.a or that a is a generator of a. Since S is finite, a is a finite subset of S, possibly including all of S. Since the associativity of implies
or (a, ), is defined bya = {a(k): k 1}.a or that a is a generator of a. Since S is finite, a is a finite subset of S, possibly including all of S. Since the associativity of impliesa(i)
a(j) = a(i+j),a is closed and therefore, by Theorem 33.14, a is a subgroup of S. For example, in Z6,we have0 = {0} ,1 = {0, 1, 2, 3, 4, 5} ,2 = {0, 2, 4} . , we have1 = {1} ,2 = {1, 2, 4} ,3 = {1, 2, 3, 4, 5, 6} .) and any a S, the order of an element is equal to the size of the subgroup it generates, or ord(a) = |a|. a(k) = a(k) for k 1, if i > t, then a(i) = a(j) for some j < i. Thus, no new elements are seen after a(t), and a = {a(1),a(2),...,a(t)}. To show that
, we have1 = {1} ,2 = {1, 2, 4} ,3 = {1, 2, 3, 4, 5, 6} .) and any a S, the order of an element is equal to the size of the subgroup it generates, or ord(a) = |a|. a(k) = a(k) for k 1, if i > t, then a(i) = a(j) for some j < i. Thus, no new elements are seen after a(t), and a = {a(1),a(2),...,a(t)}. To show that  a = t, suppose for the purpose of contradiction that a(i) = a(j) for some i, j satisfying 1 i < j t. Then, a(i+k) = a(j+k) for k 0. But this implies that a(i+(t-j)) = a(j+(t-j)) = e, a contradiction, since i + (t - j) < t but t is the least positive value such that a(t) = e. Therefore, each element of the sequence a(1),a(2), . . . , a(t) is distinct, and a = t. j (mod t). ) is a finite group with identity e, then for all a S,
a = t, suppose for the purpose of contradiction that a(i) = a(j) for some i, j satisfying 1 i < j t. Then, a(i+k) = a(j+k) for k 0. But this implies that a(i+(t-j)) = a(j+(t-j)) = e, a contradiction, since i + (t - j) < t but t is the least positive value such that a(t) = e. Therefore, each element of the sequence a(1),a(2), . . . , a(t) is distinct, and a = t. j (mod t). ) is a finite group with identity e, then for all a S,a(|S|) = e.
0 (mod t), where t = ord(a). Exercises
 . Show that these groups are isomorphic by exhibiting a one-to-one correspondence
. Show that these groups are isomorphic by exhibiting a one-to-one correspondence  between their elements such that a + b c (mod 4) if and only if (a). (b) (c) (mod 5).(pe) = pe-1(p - 1) .
between their elements such that a + b c (mod 4) if and only if (a). (b) (c) (mod 5).(pe) = pe-1(p - 1) . , the function fa:
, the function fa:  defined by fa(x) = ax mod n is a permutation of
defined by fa(x) = ax mod n is a permutation of  .
. .
.33.4 Solving modular linear equations
ax
b (mod n),(33.22)
a denote the subgroup of Zn generated by a. Since a = {a(x): x > 0} = {ax mod n: x > 0}, equation (33.22) has a solution if and only if b a. Lagrange's theorem (Theorem 33.15) tells us that |a| must be a divisor of n. The following theorem gives us a precise characterization of a.a = d = {0, d, 2d,..., ((n/d)- l)d},(33.23)
|
a| = n/d . a. Observe that EXTENDED EUCLID(a, n) produces integers x' and y' such that ax' + ny' = d. Thus, ax' d (mod n), so that d a. a, it follows that every multiple of d belongs to a, because a multiple of a multiple of a is a multiple of a. Thus, a contains every element in {0, d, 2d, . . . ,((n/d ) - l )d}. That is, d a .a d. If m a, then m = ax mod n for some integer x, and so m = ax + ny for some integer y. However, d | a and d | n, and so d | m by equation (33.6). Therefore, m d.a = d. To see that |(a| = n/d, observe that there are exactly n/d multiples of d between 0 and n - 1, inclusive. b (mod n) is solvable for the unknown x if and only if gcd(a, n) | b. b (mod n) either has d distinct solutions modulo n, where d = gcd(a, n), or it has no solutions. b (mod n) has a solution, then b a. The sequence ai mod n, for i = 0,1, . . . , is periodic with period |a| = n/d, by Corollary 33.18. If b a, then b appears exactly d times in the sequence ai mod n, for i = 0,1, . . . , n - 1, since the length-(n/d) block of values ( a) is repeated exactly d times as i increases from 0 to n - 1. The indices x of these d positions are the solutions of the equation ax b (mod n). b (mod n) has as one of its solutions the value x0, wherex0 = x'(b/d) mod n.
d (mod n), we haveax0
ax'(b/d) (mod n) d(b/d) (mod n) b (mod n) , b (mod n). b (mod n) is solvable (that is, d | b, where d = gcd(a, n)) and that x0 is any solution to this equation. Then, this equation has exactly d distinct solutions, modulo n, given by xi = x0 + i(n/d) for i = 1, 2, . . . , d - 1. i( n/d) < n for i = 0, 1, . . . , d - 1, the values x0,x1, . . . , xd-1 are all distinct, modulo n. By the periodicity of the sequence ai mod n (Corollary 33.18), if x0 is a solution of ax b (mod n), then every xi is a solution. By Corollary 33.22, there are exactly d solutions, so that x0,xl, . . . , xd-1 must be all of them. b (mod n); the following algorithm prints all solutions to this equation. The inputs a and b are arbitrary integers, and n is an arbitrary positive integer.MODULAR-LINEAR-EQUATION-SOLVER(a,b,n)
1 (d,x',y')
EXTENDED-EUCLID(a,n)2 if d | b
3 then x0
x'(b/d) mod n4 for i
0 to d - 15 do print (x0 + i(n/d)) mod n
6 else print "no solutions"
30 (mod 100) (here, a = 14, b = 30, and n = 100). Calling EXTENDED-EUCLID in line 1, we obtain (d, x, y) = (2,-7,1). Since 2 30, lines 3-5 are executed. In line 3, we compute x0 = (-7)(15) mod 100 = 95. The loop on lines 4-5 prints the two solutions: 95 and 45. d (mod n). If d does not divide b, then the equation ax b (mod n) has no solution, by Corollary 33.21. Line 2 checks if d b; if not, line 6 reports that there are no solutions. Otherwise, line 3 computes a solution x0 to equation (33.22), in accordance with Theorem 33.23. Given one solution, Theorem 33.24 states that the other d - 1 solutions can be obtained by adding multiples of (n/d), modulo n. The for loop of lines 4-5 prints out all d solutions, beginning with x0 and spaced (n/d) apart, modulo n. b (mod n) has a unique solution modulo n. ax
1 (mod n)(33.24)
1 (mod n) is the integer x returned by EXTENDED-EUCLID, since the equationgcd(a, n) = 1 = ax + ny
1 (mod n). Thus, (a-1 mod n) can be computed efficiently using EXTENDED-EUCLID.Exercises
10 (mod 50). ay (mod n) implies x y (mod n) whenever gcd(a, n) = 1. Show that the condition gcd(a, n) = 1 is necessary by supplying a counterexample with gcd(a, n) > 1.3 then x0
x'(b/d) mod (n/d) f0 + f1x + + ftx + . . . + ftxt (mod p) be a polynomial of degree t, with coefficients fi drawn from Zp, where p is prime. We say that a Zp is a zero of f if f(a) 0 (mod p). Prove that if a is a zero of f, then f (x) (x - a)g(x) (mod p) for some polynomial g(x) of degree t - 1. Prove by induction on t that a polynomial f (x) of degree t can have at most t distinct zeros modulo a prime p.33.5 The Chinese remainder theorem
 solved the problem of finding those integers x that leave remainders 2, 3, and 2 when divided by 3, 5, and 7 respectively. One such solution is x = 23; all solutions are of the form 23 + 105k for arbitrary integers k. The "Chinese remainder theorem" provides a correspondence between a system of equations modulo a set of pairwise relatively prime moduli (for example, 3, 5, and 7) and an equation modulo their product (for example, 105).
solved the problem of finding those integers x that leave remainders 2, 3, and 2 when divided by 3, 5, and 7 respectively. One such solution is x = 23; all solutions are of the form 23 + 105k for arbitrary integers k. The "Chinese remainder theorem" provides a correspondence between a system of equations modulo a set of pairwise relatively prime moduli (for example, 3, 5, and 7) and an equation modulo their product (for example, 105).a
 (al, a2, . . . , ak),
(al, a2, . . . , ak),(33.25)
Zn, ai Zni, andai = a mod ni
a
(al, a2, . . . , ak) ,b
(b1, b2, . . . , bk) ,(a + b) mod n
((al + bl) mod n1, . . . , (ak + bk) mod nk) ,(33.26)
(a - b) mod n
((al - bl) mod nl, . . . , (ak - bk) mod nk) ,(33.27)
(ab) mod n
(a1b1 mod nl, . . . , akbk mod nk) .(33.28)
0 (mod nj) for all j i. Then, lettingci = mi(mj-l mod ni)
(33.29)
a
(alc1 + a2c2 + . . . + akck) (mod n) .(33.30)
mj 0 (mod ni) if j i, and that ci 1 (mod ni). Thus, we have the correspondenceci
(0, 0, . . . , 0, 1, 0, . . . , 0) ,
x
ai (mod ni),x
a (mod ni)x
a (mod n) . a
2 (mod 5) ,a
3 (mod 13) , 2 (mod 5) and 5-1 8 (mod 13), we havec1 = 13(2 mod 5) = 26 ,
c2 = 5(8 mod 13) = 40 ,
a
2 . 26 + 3 40 (mod 65) 52 + 120 (mod 65) 42 (mod 65) . 0 1 2 3 4 5 6 7 8 9 10 11 12
------------------------------- ---------------------
0 0 40 15 55 30 5 45 20 60 35 10 50 25
1 26 1 41 16 56 31 6 46 21 61 36 11 51
2 52 27 2 42 17 57 32 7 47 22 62 37 12
3 13 53 28 3 43 18 58 33 8 48 23 63 38
4 39 14 54 29 4 44 19 59 34 9 49 24 64
Figure 33.3 An illustration of the Chinese remainder theorem for n1 = 5 and n2 = 13. For this example, c1 = 26 and c2 = 40. In row i, column j is shown the value of a, modulo 65, such that (a mod 5) = i and (a mod 13) = j. Note that row 0, column 0 contains a 0. Similarly, row 4, column 12 contains a 64 (equivalent to - 1). Since c1 = 26, moving down a row increases a by 26. Similarly, c2 = 40 means that moving right a column increases a by 40. Increasing a by 1 corresponds to moving diagonally downward and to the right, wrapping around from the bottom to the top and from the right to the left.
Exercises
4 (mod 5) and x 5 (mod 11). 0 (mod n) is equal to the product of the number of roots of each the equations f(x) 0 (mod n1), f(x) 0 (mod n2), . . . , f(x) 0 (mod nk).
0 (mod n) is equal to the product of the number of roots of each the equations f(x) 0 (mod n1), f(x) 0 (mod n2), . . . , f(x) 0 (mod nk).33.6 Powers of an element
 :
:a0,a1,a2,a3,... ,
(33.31)
i 0 1 2 3 4 5 6 7 8 9 10 11 ...
---------------------------------------------------
3i mod 7 1 3 2 6 4 5 1 3 2 6 4 5 ...
i 0 1 2 3 4 5 6 7 8 9 10 11 ...
---------------------------------------------------
2i mod 7 1 2 4 1 2 4 1 2 4 1 2 4 ...
a denote the subgroup of  generated by a, and let ordn (a) (the "order of a, modulo n") denote the order of a in
generated by a, and let ordn (a) (the "order of a, modulo n") denote the order of a in  . For example, 2 = {1, 2, 4} in
. For example, 2 = {1, 2, 4} in  , and ord7 (2) = 3. Using the definition of the Euler phi function (n) as the size of
, and ord7 (2) = 3. Using the definition of the Euler phi function (n) as the size of  (see Section 33.3), we now translate Corollary 33.19 into the notation of
(see Section 33.3), we now translate Corollary 33.19 into the notation of  to obtain Euler's theorem and specialize it to
to obtain Euler's theorem and specialize it to  , where p is prime, to obtain Fermat's theorem.
, where p is prime, to obtain Fermat's theorem.
(33.32)

(33.33)
(p) = p - 1 if p is prime.  . For all a Zp, however, we have ap a (mod p) if p is prime.
. For all a Zp, however, we have ap a (mod p) if p is prime. , then every element in
, then every element in  is a power of g, modulo n, and we say that g is a primitive root or a generator of
is a power of g, modulo n, and we say that g is a primitive root or a generator of  . For example, 3 is a primitive root, modulo 7. If
. For example, 3 is a primitive root, modulo 7. If  possesses a primitive root, we say that the group
possesses a primitive root, we say that the group  is cyclic. We omit the proof of the following theorem, which is proven by Niven and Zuckerman [151].
is cyclic. We omit the proof of the following theorem, which is proven by Niven and Zuckerman [151]. is cyclic are 2, 4, pe, and 2pe, for all odd primes p and all positive integers e.
is cyclic are 2, 4, pe, and 2pe, for all odd primes p and all positive integers e.  and a is any element of
and a is any element of  , then there exists a z such that gz a (mod n). This z is called the discrete logarithm or index of a, modulo n, to the base g; we denote this value as indn,g(a).
, then there exists a z such that gz a (mod n). This z is called the discrete logarithm or index of a, modulo n, to the base g; we denote this value as indn,g(a). , then the equation gx gy (mod n) holds if and only if the equation x y (mod (n)) holds. y (mod (n)). Then, x = y + k(n) for some integer k. Therefore,
, then the equation gx gy (mod n) holds if and only if the equation x y (mod (n)) holds. y (mod (n)). Then, x = y + k(n) for some integer k. Therefore,gx
gy+k(n) (mod n) gy (g(n))k (mod n) gy lk (mod n) gy (mod n). gy (mod n). Because the sequence of powers of g generates every element of g and |g| = (n), Corollary 33.18 implies that the sequence of powers of g is periodic with period (n). Therefore, if gx gy (mod n), then we must have x y (mod (n)). 1, then the equationx2
1 (mod pe)(33.34)
 has a primitive root g. Equation (33.34) can be written
has a primitive root g. Equation (33.34) can be written(gindn,g(x))2
gindn,g(l) (mod n) .(33.35)
2
indn,g (x) 0 (mod (n)) .(33.36)
(n)) = gcd(2, (p - 1)pe-1) = 2, and noting that d | 0, we find from Theorem 33.24 that equation (33.36) has exactly d = 2 solutions. Therefore, equation (33.34) has exactly 2 solutions, which are x = 1 and x = - 1 by inspection. 1 (mod n) but x is equivalent to neither of the two "trivial" square roots: 1 or -1, modulo n. For example, 6 is a nontrivial square root of 1, modulo 35. The following corollary to Theorem 33.34 will be used in the correctness proof for the Miller-Rabin primality-testing procedure in Section 33.8.Raising to powers with repeated squaring
bk, bk-1, . . . , b1,b0 be the binary representation of b. (That is, the binary representation is k + 1 bits long, bk is the most significant bit, and b0 is the least significant bit.) The following procedure computes ac mod n as c is increased by doublings and incrementations from 0 to b.MODULAR-EXPONENTIATION(a,b,n)
1 c
02 d
13 let
bk, bk-1, . . . , b0 be the binary representation of b4 for i
k downto 05 do c
2c6 d
(d d) mod n7 if bi = 1
8 then c
c + 19 d
(d a) mod n10 return d
i 9 8 7 6 5 4 3 2 1 0
-------------------------------------------------
bi 1 0 0 0 1 1 0 0 0 0
c 1 2 4 8 17 35 70 140 280 560
d 7 49 157 526 160 241 298 166 67 1
Figure 33.4 The results of MODULAR-EXPONENTIATION when computing ab (mod n), where a = 7, b = 560 =
1000110000, and n = 561. The values are shown after each execution of the for loop. The final result is 1.a2c mod n = (ac)2 mod n ,
a2c+l mod n = a . (ac)2 mod n ,
bk, bk-1, . . . , bi of the binary representation of b. As an example, for a = 7, b = 560, and n = 561, the algorithm computes the sequence of values modulo 561 shown in Figure 33.4; the sequence of exponents used is shown in row c of the table.-bit numbers, then the total number of arithmetic operations required is O() and the total number of bit operations required is O(3).Exercises
 . Pick the smallest primitive root g and compute a table giving ind11,g (x) for all x
. Pick the smallest primitive root g and compute a table giving ind11,g (x) for all x  .
. using the procedure MODULAR-EXPONENTIATION, assuming that you know (n).
using the procedure MODULAR-EXPONENTIATION, assuming that you know (n).33.7 The RSA public-key cryptosystem
Public-key cryptosystems
 denote the set of permissible messages. For example,
denote the set of permissible messages. For example,  might be the set of all finite-length bit sequences. We require that the public and secret keys specify one-to-one functions from
might be the set of all finite-length bit sequences. We require that the public and secret keys specify one-to-one functions from  to itself. The function corresponding to Alice's public key P
to itself. The function corresponding to Alice's public key P